- 변수 : 신경망에서 학습 대상
- ,
- 하이퍼 파라미터 : 학습 알고리즘에게 우리가 정해줘야 하는 것
- learning rate
- 반복 iteration 횟수
- 은닉층 hidden layer 개수
- 은닉유닛 hidden units 개수
- 활성화 함수 선택
- 모멘텀 항 momentum term
- 미니배치 크기 mini batch size
파라미터(변수) 초기화
- 학습 전 파라미터를 초기화한다.
- w = np.random.rand(
shape) * 0.01
→ 랜덤 초기화.- b = np.zeros(
shape)
→ 0으로 초기화
- 이유
- w를 모두 0으로 초기화하면 안 됨. 같은 층의 모든 유닛이 언제나 같은 값을 계산하기 때문에. → 랜덤하게 초기화.
- 0.01을 곱해서 아주 작은 수로 만들어줌. (0.01 말고 다른 수여도 괜찮음.)
← w가 크면 가 너무 크거나 작고, 그러면 sigmoid, tanh 활성함수를 거쳤을 때 도함수가 거의 0이라 학습 속도가 너무 느려지기 때문.
- b는 모두 0으로 초기화해도 이런 문제가 생기지 않음. → 그냥 0으로 초기화.
하이퍼 파라미터(매개변수) 초기화
- 방법
- 매우 경험적임
- 하나로 정하고 → 여러 번 시도 → 비용함수 값 보면서 조정
- 조언
- 몇 년씩 하는 장기 프로젝트라면 → 몇 달마다 점검하기.
- 왜냐면 지금 최적인 걸로 정했어도, 나중에 최적인 값이 바뀔 수도 있음.
CPU, GPU, 네트워크, 데이터가 달라지니까.
learning rate
- learning rate 정하기
- 일단 0.01로 시작 (?)
활성화 함수
활성화 함수 정하기
- 데이터 값의 범위가 (거의) 양수일 때 → ReLU
- 대체로 sigmoid냐 tanh냐 중에선 → tanh
- Binary classification의 출력층 → sigmoid
-
비선형이어야 함.
-
종류 (4가지)
sigmoid
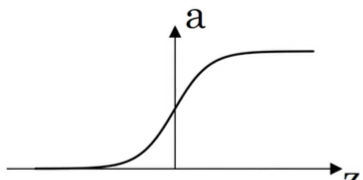
[장점]
출력값 : 0~1 → binary classification의 출력층에 적합.
왜냐하면 그 출력층은 y=1일 확률을 나타내는데, 확률은 0~1 사이 값이니까.tanh
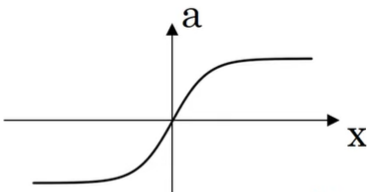
[장점]
평균이 0
→ 데이터를 원점으로 이동하는 효과 有.
→ 평균이 0.5인 Sigmoid보다 효율적.ReLU
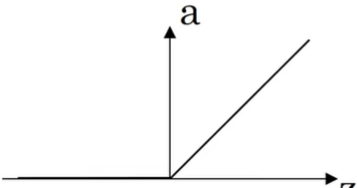
[장점]
sigmoid, tanh는 x가 너무 크거나 작을 때 도함수가 거의 0
→ 학습 속도 저하
반면 ReLU는 x 절반(x>0)은 도함수가 1으로, 0에 가깝지 X
→ 학습 빠름.leaky ReLU
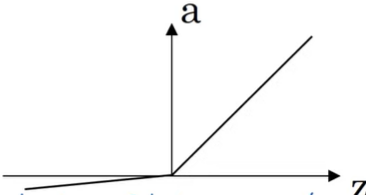
[장점]
남은 x 절반(x<0)도 도함수가 0이 아님. → 학습 더 빠름.
