✏️ 들어가기에 앞서
이 논문은 마이크로서비스 자동 식별 방식에 대해 토론하던 중에 떠올린 방식의 한 가지이다. 내 블로그의 이전 논문 중 재사용 기법과 유사한 방식으로 동작한다. 재사용 기법과 관련한 글은 아래의 링크를 참고하길 바란다. 다시 원문으로 되돌아오면 재사용 기법이 컴포넌트를 하나의 텍스트로 보고 단어를 추출한다면 이 기법은 컴포넌트의 문법을 고려하여 단어를 추출한다. 여기서 컴포넌트의 문법이 정확하게 의미하는 바는 소스 코드의 구조적인 면을 뜻한다. 컴포넌트는 수식 또는 포함 관계로 이루어져 있다. 예를 들어, 클래스 명 안에 필드 명과 메소드 명이 있다. 그리고 메소드 명 안에는 다시 지역 변수 명 등이 포함될 수 있다. 이러한 구조적인 면을 고려하여 단어들을 추출하여 트리 형태로 나타낸다. 이후, 생성된 트리에서 단어 간의 이웃 관계를 추출하여 단어 임베딩 모델을 학습시킨다. 임베딩 된 단어를 통해 컴포넌트를 임베딩하는데, 컴포넌트에 포함된 단어 벡터의 평균 벡터를 컴포넌트의 벡터로 본다. 이후, 임베딩이 완료되면, 이 정보를 기반으로 재사용 기법과 동일하게 기존 기법의 마이크로서비스 식별 기법의 결과와 분류기를 활용하여 기존 기법이 고려하지 않는 컴포넌트까지 마이크로서비스로 분류하게 된다.
재사용 기법: https://velog.io/@1876060677/마이크로서비스의-자동-식별을-위한-효과적인-재사용-기반-접근-방법-논문-소개
✏️ 제안하는 방식
제안하는 기법의 프로세스를 간단하게 나타내면 다음과 같다. 좀 더 구체적인 정보를 확인하려면 논문의 본문을 참고하면 된다.
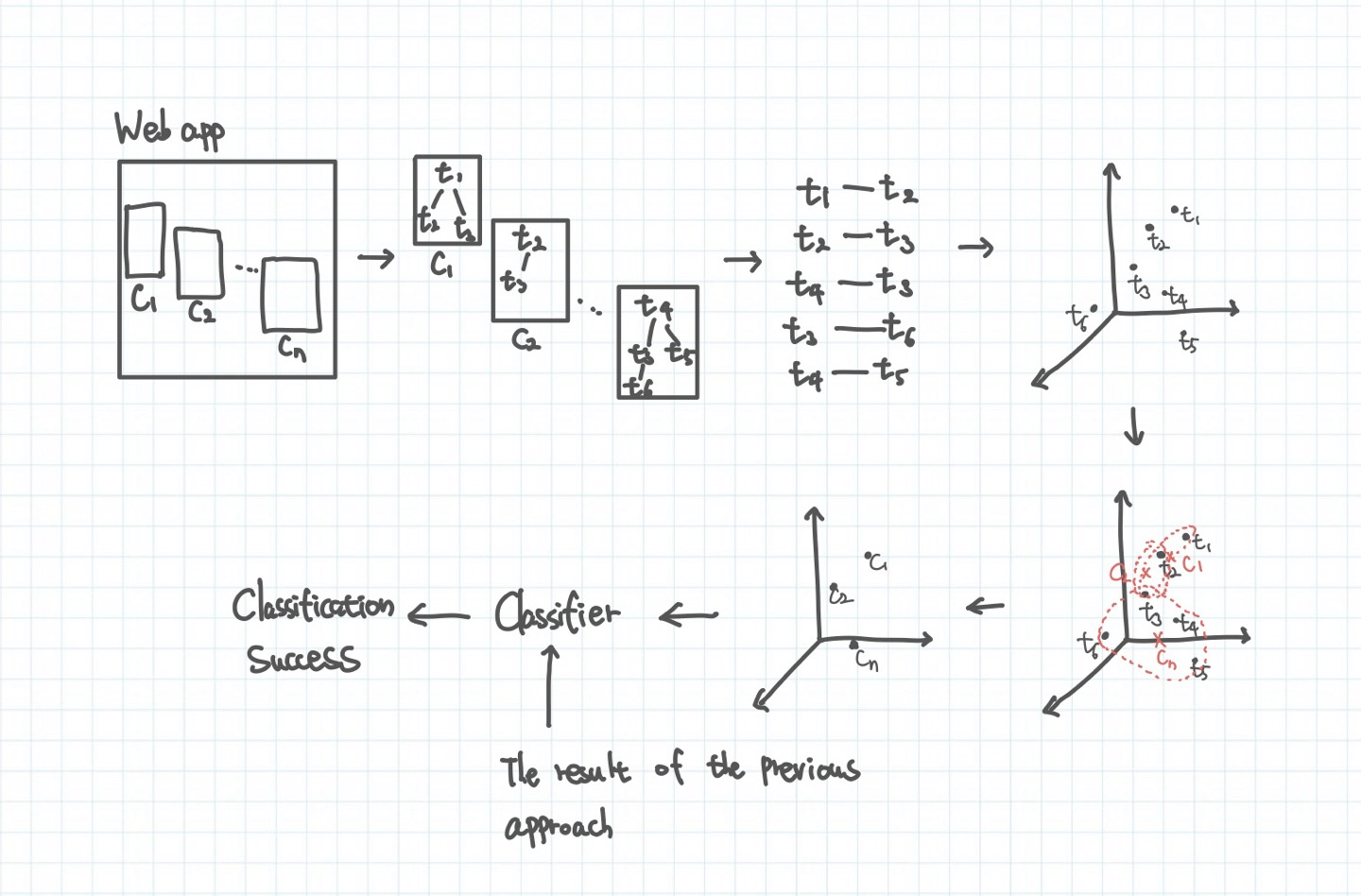
1) 컴포넌트 단어를 구조화 한다.
서론 부분에서 설명하였듯이 컴포넌트의 구조에 따라 단어를 트리 형태로 나타낸다.
2) 트리로부터 이웃 관계를 추출한다.
그림과 같이 서로 직접적으로 연결된 단어들이 이웃 관계로 판단되어 추출될 수 있다. 본 논문에서는 이웃 관계의 범위를 하이퍼 파라미터로 사용할 수 있다. 따라서 그림과 같이 거리가 1인 거리 내에 있는 단어들을 이웃 관계로 정의할 수도 있고, 상황에 따라 2, 3, 4까지도 사용할 수 있다. 이웃 관계의 범위가 커지면 하나의 컴포넌트 내에서 등장하는 단어들 사이의 이웃 관계가 더 많이 추출될 것이고 이는 하나의 컴포넌트 내에 등장하는 단어들을 더욱 밀접한 관계로 간주한다고 볼 수 있다.
3) 단어를 임베딩한다.
논문에서는 이웃 관계를 이용하여 임베딩한다. 이를 위해 word2vec을 사용한다. word2vec은 단어들 사이의 이웃 관계를 학습하여 이웃 관계로 등장한 단어들은 가깝게 이웃이 아닌 단어들은 서로 멀어지도록 임베딩한다.
4) 컴포넌트를 임베딩한다.
단어 임베딩이 완료되면 컴포넌트를 임베딩한다. 컴포넌트는 컴포넌트가 갖는 단어들의 임베딩 벡터의 평균 값으로 임베딩된다. 이로써 마이크로서비스 식별을 위해 준비가 거의 완료되었다고 볼 수 있다.
5) 재사용 기법과 동일하게 컴포넌트들을 분류한다.
컴포넌트 임베딩 벡터를 그대로 클러스터링과 같은 기술을 사용할 수 있다. 그러나 본 논문에서는 재사용 기법과 동일한 방식으로 분류를 진행한다. 기존 기법의 마이크로서비스 식별 기법을 이용하는 방식이다. 먼저 기존 기법의 결과에서 어떤 컴포넌트가 어떤 마이크로서비스에 속하는지에 대한 정보를 가져온다. 그리고 해당 컴포넌트의 임베딩 벡터와 마이크로서비스 정보를 학습 데이터로 사용하여 KNN 분류기에 학습시킨다. 이후 기존 기법의 결과에 속하지 않는 컴포넌트들의 임베딩 벡터를 분류기에 넣어서 어떤 마이크로서비스에 속하는지 예측할 수 있다.
✏️ 평가
재사용 기법과 동일한 평가 프로세스를 지닌다. 오픈 소스 웹 앱 5개를 대상으로 정확도를 측정하며, 정확도를 재사용 기법과 비교한다. 비교 결과를 요약하면 재사용 기법보다 모든 경우에 더 좋은 성능을 보인다.
✏️ 한계
평가를 살펴보면 아는 사람들은 한계가 무엇인지 바로 알 수 있다. 이 논문의 평가에는 Shopping App이라는 웹 앱에 대해 평가를 진행하지 않는다. 이 웹 앱은 베트남 언어 기반의 쇼핑몰 앱이다. 제안하는 기법에서는 변수 명과 클래스 명 등이 식별자로 사용되기 때문에 파싱이 잘 되어야 한다. 그러나 이러한 언어가 영어가 아니다보니 베트남 언어를 이해하고 파싱을 하는 것에 어려움이 있다는 것을 알 수 있다. 즉, 재사용 기법에서는 언어의 문법을 별로 고려하지 않아도 되는 반면, 제안하는 기법에서는 이러한 부분에 있어 조금 민감할 수 있다.
✏️ 소감
이 논문은 숏 페이퍼로 작성되었다. 오히려 분량의 한계로 인해 레귤러 페이퍼보다 작성하기가 더 어려웠다. 특히, 리뷰 과정에서 굉장히 많은 코멘트가 있었고 그것을 일일히 답변하는 것 역시 어려웠다. 그러나 큰 수정을 거쳐서 게제가 되었고, 리뷰어의 코멘트에 답변하기 위해서 문제를 하나씩 하나씩 해결해가는 과정이 꽤 재미있게 느껴졌던 것 같다. 지금까지는 정적인 분석을 활용하여 마이크로서비스를 식별하고 있는데, 다음 작성 논문은 동적인 분석을 활용할 것 같다.
원문 링크: https://doi.org/10.6109/jkiice.2023.27.7.892
