Attention Is All You Need
Problem
이전의 NLP 모델들은 거의 Recurrent 한 방법을 사용하여 자연어 문제들을 해결해왔다. 그러나 RNN 모델들은 벡터가 순차적으로 입력된다는 점에서 병렬 연산을 활용하기 매우 어려웠고, 학습과 Inference가 느릴 수밖에 없었다. 따라서 NLP 분야의 장점이라고 할 수 있는 많은 데이터를 충분히 활용하는 것 역시 어려웠다. 당시의 SOTA 방법론들은 LSTM, GRU 등의 방법으로 Long Term Dependency를 해결하려고 시도하였지만, Transformer는 RNN 자체가 갖는 한계에 집중하였다.
Task
Transformer가 NLP 모델이라는 사실보다 중요한 것은 어떤 Task를 했는지라고 생각한다. 입력값을 넣고 출력값을 뽑는 구조를 이해하는 데에 어떤 Task를 했는지가 중요하기 때문이다.
실제로 논문에서 학습시켜 본 Task는 Translation, English Constituency Parsing이 메인이라고 할 수 있다.
Translation은 말 그대로 번역이고, English Constituency Parsing은 영어에서 각 단어들이 문장의 구성 성분 중 어떤 것을 맡고 있는지 분석하는 Task이다.
Method
1) Attention
NLP 모델에서 단어들은 특정 차원의 임베딩으로 나타내게 된다. 이를 라고 하면, 길이가 인 문장은 () 크기의 행렬로 나타낼 수 있다.
Attention에서 , , 값은 이러한 크기의 행렬(문장)을 의미한다.
Attention에서 입력 문장 , , 는 각각 는 Query, 는 Key, 는 Value이다. 주어진 Query에 대해서 각각의 Key 값과의 유사도를 구하고, 유사도를 고려하여 Value에서 의미를 가져오게 된다.
그렇다면 우선 한 단어끼리의 유사도를 측정하려면 어떻게 해야할까? 여러 좋은 방법들이 있겠지만 Attention에서는 두 단어 , (길이가 인 벡터)의 유사도를 측정할 때 아래와 같이 단순히 내적을 통해 유사도를 구하고, 이를 Attention Score라고 한다.
직관적으로 A와 B가 비슷한 값들을 가지고 있을수록, 큰 Attention Score이 나온다고 이해하면 좋다.
여러 단어가 있는 문장 두 개 , () 에서 각 단어들 사이의 유사도는 아래와 같은 외적으로 얻을 수 있다. (일단 두 문장의 길이가 같다고 가정하지만, 달라도 상관이 없다.)
여기서 AttentionScore는 () 크기의 행렬이 된다. AttentionScore 행렬의 , 번째 값은 의 번째 행, 의 번째 열을 내적한 값이기 때문에 와 의 , 번째 단어들의 유사도를 의미하게 된다.
Q와 K 두 벡터 사이의 유사도를 구해 AttentionScore로 표현하는 과정은 지금까지 이해하였으니, 이를 고려하여 Value에서 단어들의 의미를 가져오기만 하면 되기 때문에 아래의 식과 같은 연산으로 구할 수 있다. 는 Key의 차원이며, 크기 조절을 통해 softmax를 통과한 값들의 분포가 너무 극단적으로 튀지 않도록 조절하는 역할을 한다.
식에서 가 와 의 Attention score(크기 )이고, 여기에 softmax 함수를 통과시킨 후 (크기 )를 곱하는 것이기 때문에, 최종 출력값은 ()의 크기를 갖는다. 결국 Attention의 출력값도 같은 개수의 단어들을 표현하기에 원래 입력값이랑 같은 크기이고, 각 단어들이 가지는 의미만 변화한다고 생각할 수 있다.
논문에서는 아래 그림으로 이러한 과정이 요약되어 있었다.
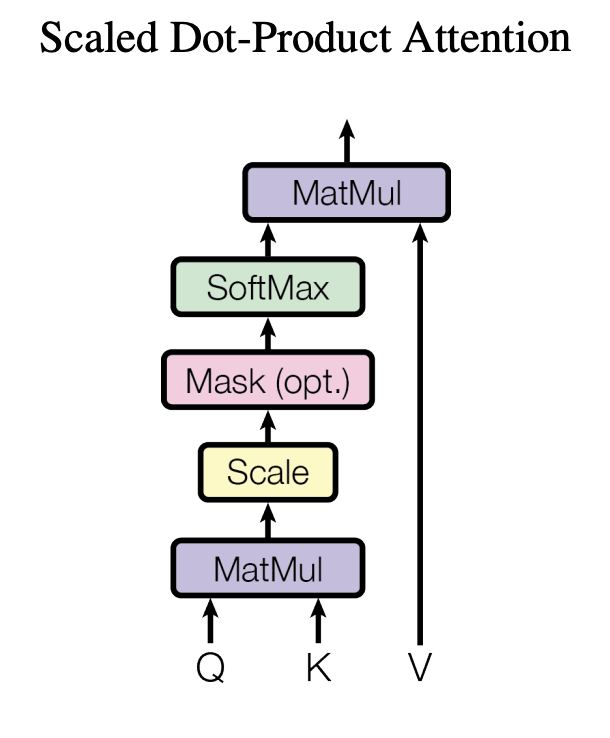
2) Multi-Head Attention
본 논문에서는 Attention의 성능을 더욱 끌어올리기 위해 아래와 같은 구조의 Multi-Head Attention을 제시하였다.
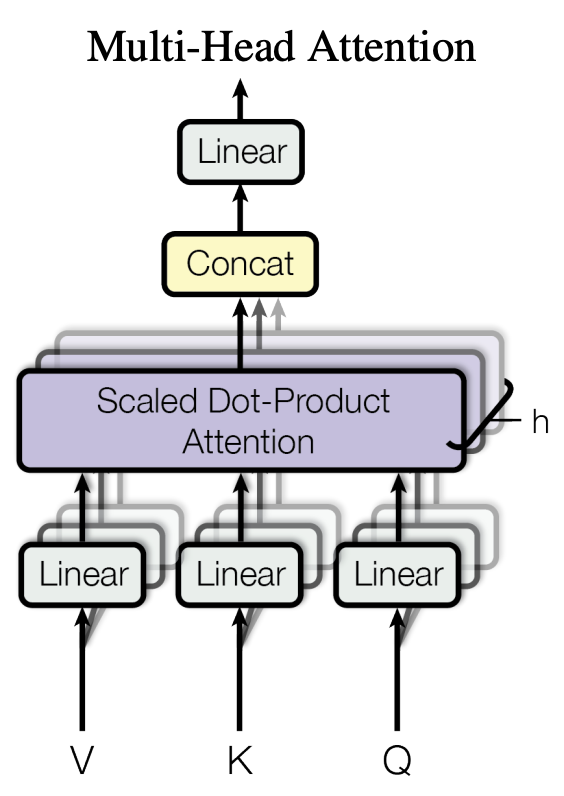
크기가 ()인 , , 를 여러 개의 Linear를 통과시키며 여러 개로 쪼개 계산하게 된다. , , 를 개의 Linear layer를 통과시켜 각각 (의 크기인 임베딩으로 만든다. 그렇게 개의 임베딩을 따로따로 Attention 시킨 후에 나온 출력값(크기 )들을 다시 연결시키고 Linear layer를 통과해 원래 크기와 같은 크기()로 되돌린다.
아래 식에서의 는 각각 , , 를 개로 쪼개기 위해 통과시키는 Linear layer들을 의미하고, 는 마지막에 원래 크기로 되돌리기 위해 통과시키는 Linear layer이다..
단어 임베딩을 서로 다른 개의 Linear 레이어로 통과한다는 것은 단어 임베딩을 해석할 관점들을 여러 갈래로 나누는 것으로 생각할 수 있는데, 다양한 관점의 정보들을 병렬적으로 뽑아올 수 있다는 점에서 장점이 있는 것 같다.
3) Position-Wise Feed-Forward
대단한 것이 아니고, Linear layer를 시퀀스 길이 차원이 아닌 임베딩 차원에 통과시킨다는 것이다. 보통의 MLP등에서 쓰는 Linear layer도 마지막 차원에 통과되도록 설계되어 있기 때문에 알아서 잘 적용이 된다. 그냥 평소에 쓰던 Linear layer 사용하면 된다.
논문에서는 Linear, ReLU, Linear 순서로 통과시켜서 Non-Linearity를 추가했다고 언급되어 있다. 식으로는 아래와 같이 표현할 수 있다.
Model Architecture
지금까지 설명한 내용들을 가지고 모델 구조를 이해해보도록 하겠다. 여기서 학습하는 Task는 번역이라고 우선 생각하고 모델 구조를 이해하면 좋을 것 같다.
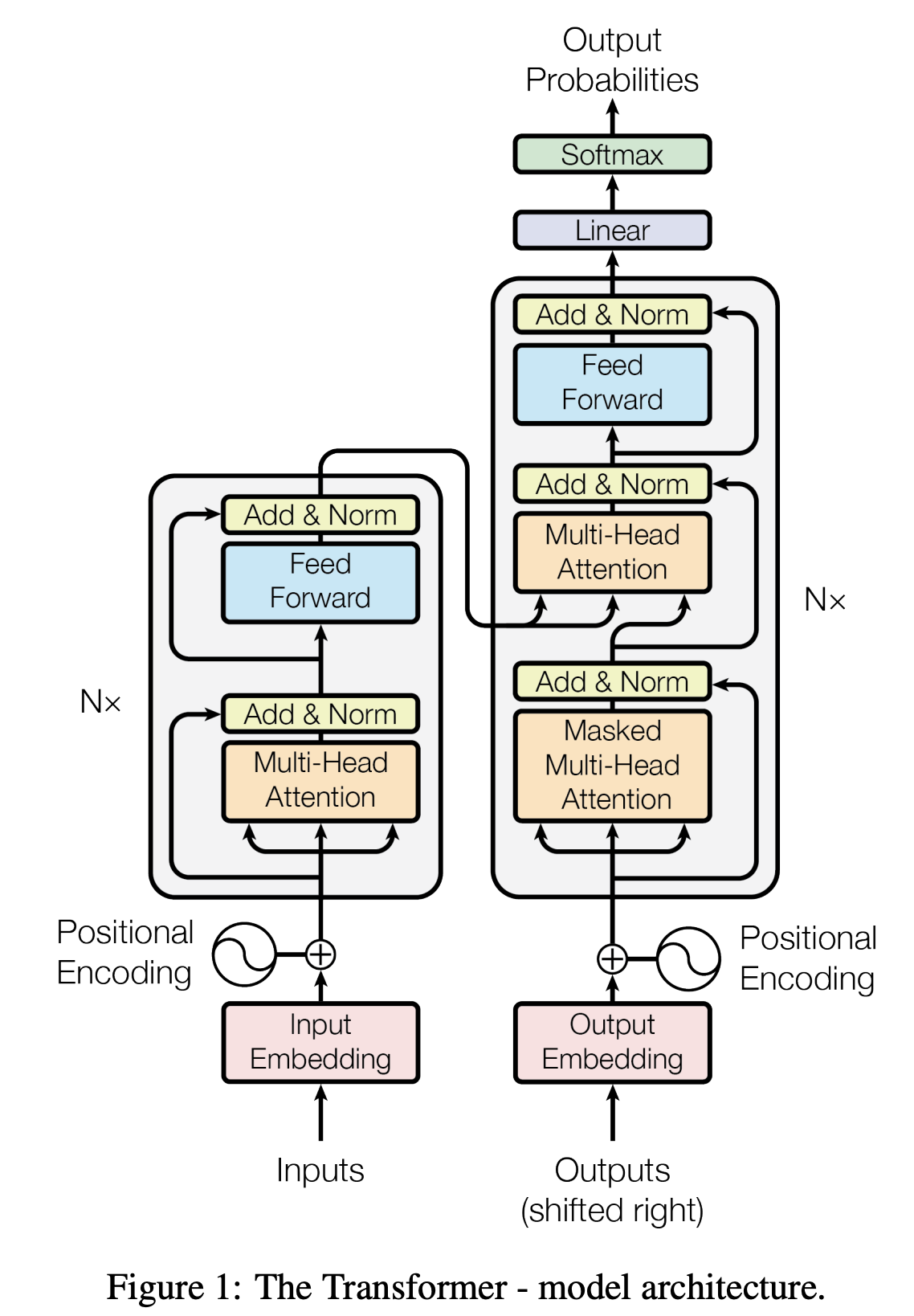
그림에서 왼쪽 절반이 Encoder, 나머지 오른쪽 절반이 Decoder이다.
어떤 문장을 Encoder에 넣어주면, Encoder에서는 그 의미를 파악하고, 파악한 의미를 Decoder에서 전달받아 그 의미를 변역하고 싶은 언어로 바꿔준다.
Encoder
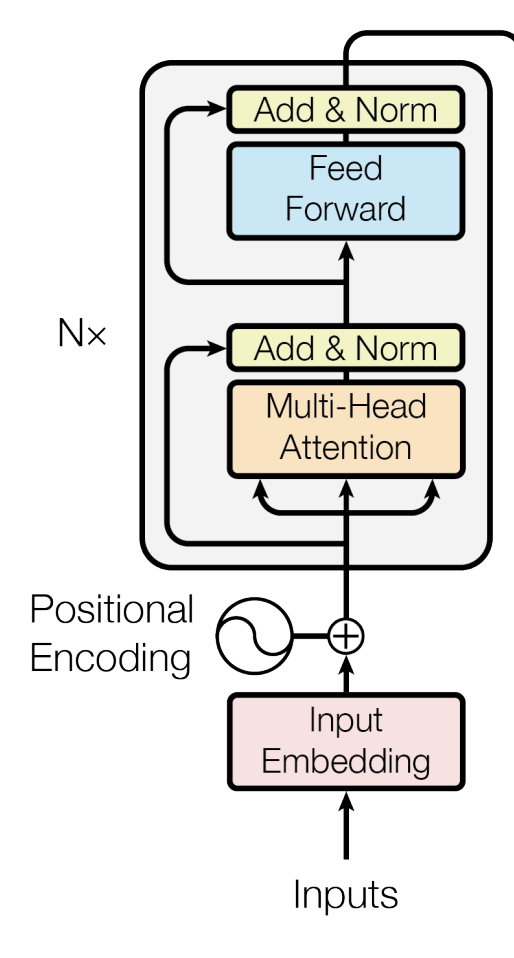
Encoder는 개의 Encoder Block으로 구성된다. Encoder Block 안에서 일어나는 일을 살펴보자.
입력값을 받아 Multi-Head Attention을 수행한다. 그런데 여기서 모두 같은 입력값에서 나온 값으로 Attention을 하는데, 이를 Self-Attention이라고 말한다. 문장 내에서 비슷한 의미, 맥락을 가진 단어들끼리의 관계를 파악하기 위해서 Self-Attention을 하는 것이다.
위의 Method의 Attention를 설명했듯이, Attention을 거치고 난 행렬은 원래 입력값과 같은 크기이기 때문에 Residual Connection을 쉽게 만들 수 있다. Add & Norm 부분에서 그러한 Residual Connection을 만들고 Layer Normalization까지 한다.
이후에 Position-Wise Feed-Forward를 하고, 다시 Add & Norm을 통과시키면 하나의 Encoder Block의 역할이 끝난다.
개의 Encoder Block을 통과시키면 Encoder에서 나온 출력값이 입력 문장의 의미를 잘 반영한 행렬이 된다.
Decoder
Encoder의 입력단에서 넣어주는 값은 당연히 번역하고 싶은 문장이었다. 그에 반해 Decoder에서의 입력단에서 넣어주는 값은 번역된 문장이다.
그렇다면 당연히 의문이 들 것이다.
엥? Inference 할 때는 번역된 문장이 뭔지 모르는데 그러면 Inference를 어떻게 하지?
이 질문에 대답하기 위해서 Decoder에서 수행하는 Task를 더 구체적으로 이해할 필요가 있다.
Decoder는 Autoregressive한 방식을 통해 Inference를 하는 것이 목표이다.
Autoregressive 하다는 것은
첫 번째 단어를 가지고 두 번째 단어를 예측한다는 것이고,
첫 번째 단어와 두 번째 단어를 가지고 세 번째 단어를 예측한다는 것이다.
그러니까, ~ 번째 단어를 가지고 번째 단어를 예측한다는 것이다.
모델이 잘 학습하여 이러한 예측이 가능하다면 이 방식은 단 하나의 Token만 있다면 (보통 Start Token) 자신이 예측해 낸 값을 다시 자신의 입력값으로 넣어 Inference가 가능하다.
Transformer Decoder는 그러한 Autoregressive 한 Inference 과정에 번역해야 할 문장의 의미(Encoder 에서 온 정보)를 추가적으로 넣어주기 때문에 그냥 그럴싸한 아무런 말을 만들어내는 것이 아니고, 원본 문장을 원하는 언어로 번역한 문장이 되는 것이다.
Encoder에서 온 정보는 당연하게도 번역하고 싶은 문장(입력값)만 있으면 만들어 낼 수 있기 때문에, 실제 Inference 과정은 이렇다.
1, 입력값을 Encoder를 통과시킨다.
2, Decoder 에서 Start Token과 Encoder의 출력값을 사용해 첫 번째 단어를 예측한다.
3, Decoder 에서 Start Token, 지금까지 예측한 단어들과 Encoder의 출력값을 사용해 다음 단어를 예측한다. (반복)
따라서 Inference 때와 같은 상황을 만들어 주기 위해서 굳이 번역된 문장을 훈련 때 입력값으로 함께 넣어주는 것이다.
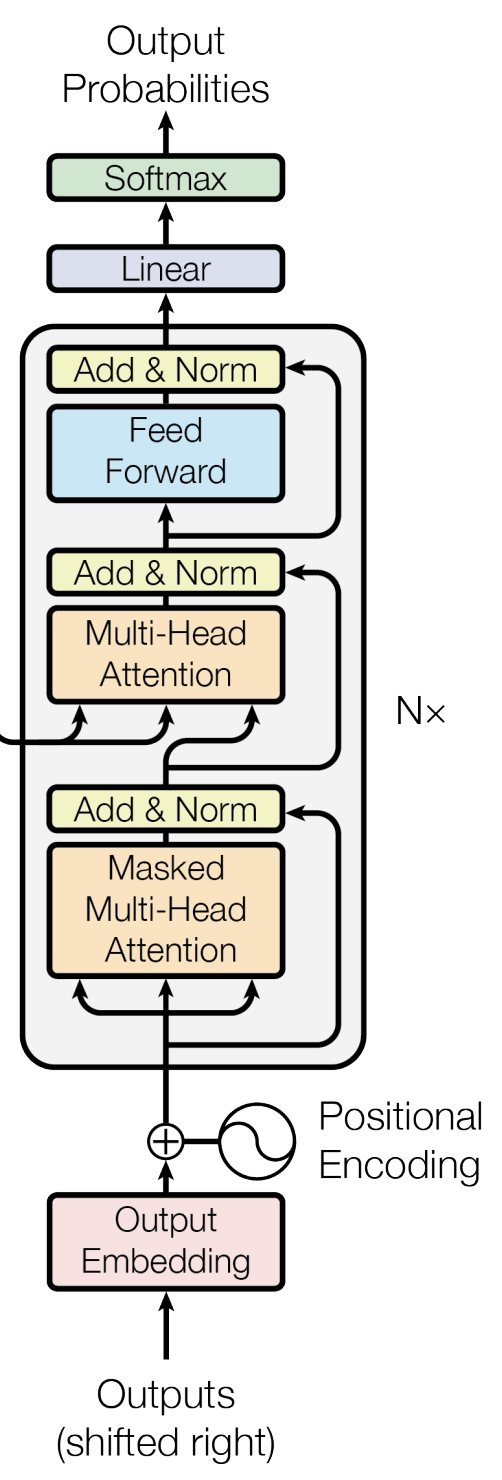
이제 진짜 Decoder 구조를 살펴보도록 하겠다.
우선 Decoder도 개의 Decoder Block으로 구성되어 있고, 각 Decoder Block은 세 부분으로 나뉜다.
제일 처음 거치는 layer는 Masked Multi-Head Attention이다. Mask는 Attention Score 중에서 봐도 될 부분과 보지 않아야 할 부분을 구분하기 위해 존재한다.
아래의 Attention Score Matrix가 표현된 표를 보며 Attention Score가 ()의 크기이고, 가 의미하는 바는 의 번째 단어와 의 번째 단어의 유사도라는 사실을 다시 한 번 떠올려 보자.
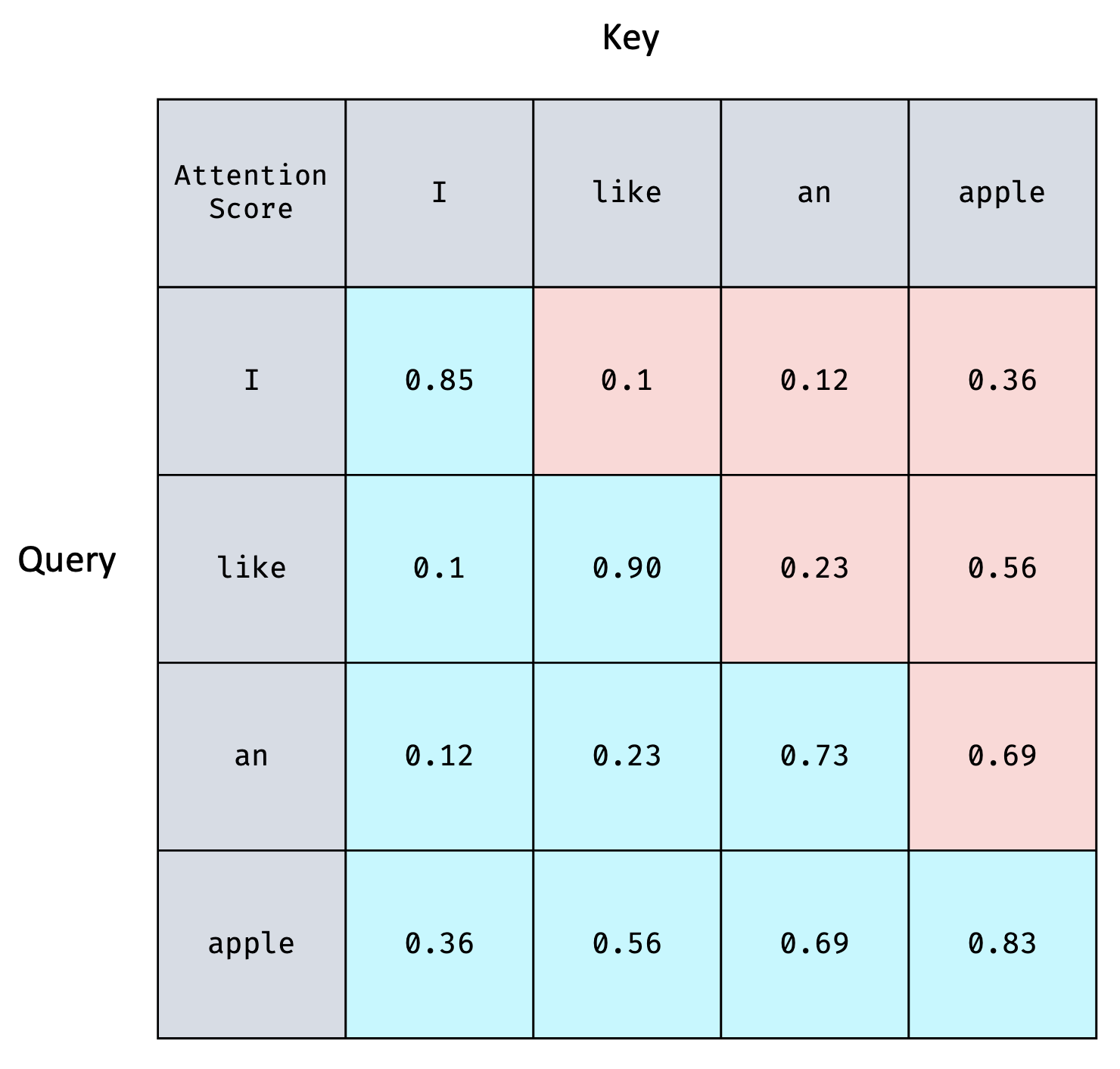
I like an apple의 문장에서 Autoregressive한 Transformer Decoder가 제대로 학습하기 위해서는
I 까지만 보고 like를 예측하는 연습을 해야하고,
I like 까지만 보고 an을 예측하는 연습을 해야하고,
I like an 까지만 보고 apple을 예측하는 연습을 해야한다.
가령 like를 에측해야하는 시점이라고 하면, 그 시점에 like 이후에 나오는 정보를 예측에 활용하면 안된다는 이야기이다. 그것을 위해 존재하는 것이 바로 Mask이다.
위의 표에서 Attention Score의 첫 번째 row에서는 I와 I의 점수만 사용하는 것이고 두 번째 row에서는 like와 I, like와 like까지 사용하는 것이다. 같은 방법으로 반복하면, 표에서 푸른 부분만 활용하고, 빨간 부분은 활용하지 않는다.
따라서 Attention Score를 아래와 같이 참고하지 않을 부분을 -Inf로 치환해 준다.
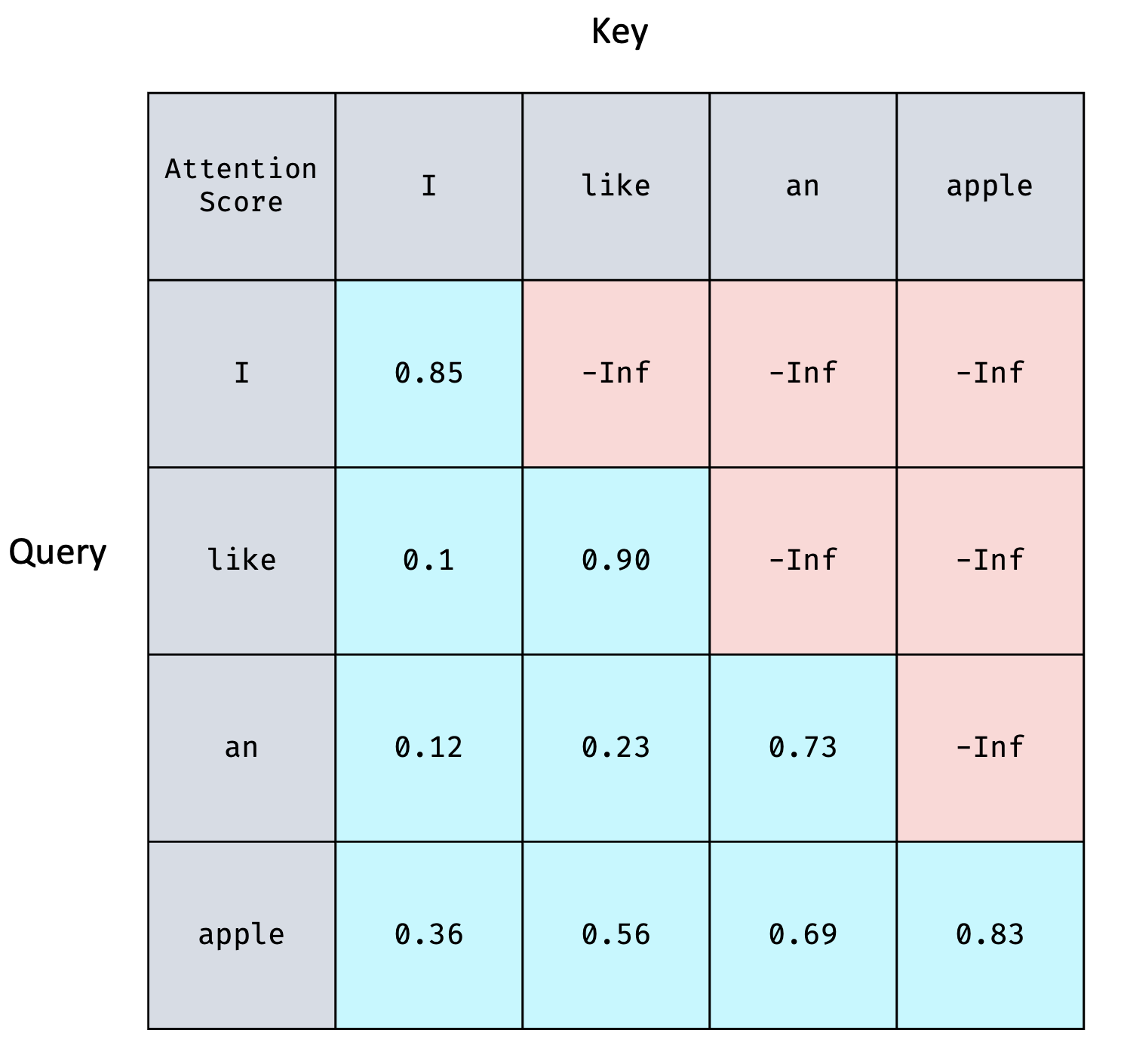
이렇게 하고 Attention을 진행하면 Autoregressive한 특성을 잘 반영해 학습할 수 있을 것이다.
Masked Multi-Head Attention 에서 , , 에 넣어주기 때문에 Masked Self-Attention이라고도 이야기할 수 있다.
다음으로 Add & Norm을 거치고, Masked-Head Attention을 또 거친다. 이 부분에서는 지금까지의 Attention과는 다르게 에 지금까지의 입력값, , 에 Encoder의 출력값을 넣는다는 점에서 차이가 있다.
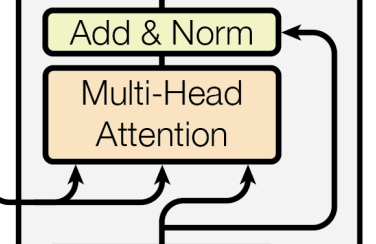
처음 살펴보았던 Attention의 의미를 잘 생각해보면 왜 이렇게 값을 넣는지 알 수 있다. Query에서 물어본 내용과 Key의 유사도를 판별한 다음, Value에서 그 실제 값을 가져오는 것이다. Key와 Value가 Encoder에서 온 정보이기 때문에 Attention의 출력값으로는 그 의미가 Encoder에서 온 정보를 기반으로 구성된다는 것을 알 수 있다.
이러한 방식의 Attention을 Cross Attention라고도 한다.
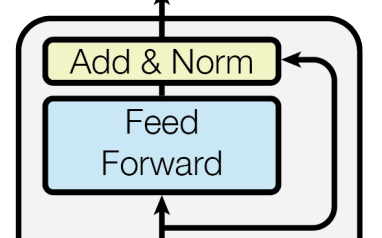
마지막으로 Encoder에서와 마찬가지로 Position-Wise Feed-Forward를 통과하면 하나의 Decoder Block에서의 계산이 끝난 것이다.
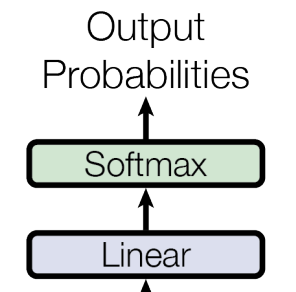
그리고 Decoder에서 나온 값들은 ()의 크기이기 때문에 각 단어들의 확률을 계산해주기 위해서 Linear layer로 채널 수를 변경시킨다. 이 Linear layer를 지나면 ()의 크기를 가지게 된다. 각 단어가 나올 확률이 계산된다.
논문에 언급되어 있는 부분은 아니지만, 이러한 언어 모델들을 학습시킬 때 사용하는 Loss는 보통 CrossEntropyLoss 이다. 각 시퀀스 자리마다 단어들을 Classification 한다고 생각할 수 있기 때문이다.
Experiments
사실 정말 유명하고 성능이 널리 입증된 논문 경우 실험 결과를 보는 것에 너무 큰 의미를 둘 필요는 없다고 생각한다. 어떤 이유로 성능이 잘 나왔는가에 대한 이미 많은 고찰들이 있었고, 수많은 사람들의 그러한 고찰 끝에 유명해진 논문인 것이 보통이기 때문이다.
아래는 영어와 독일어 사이의 번역 Task에 대한 성능이다.
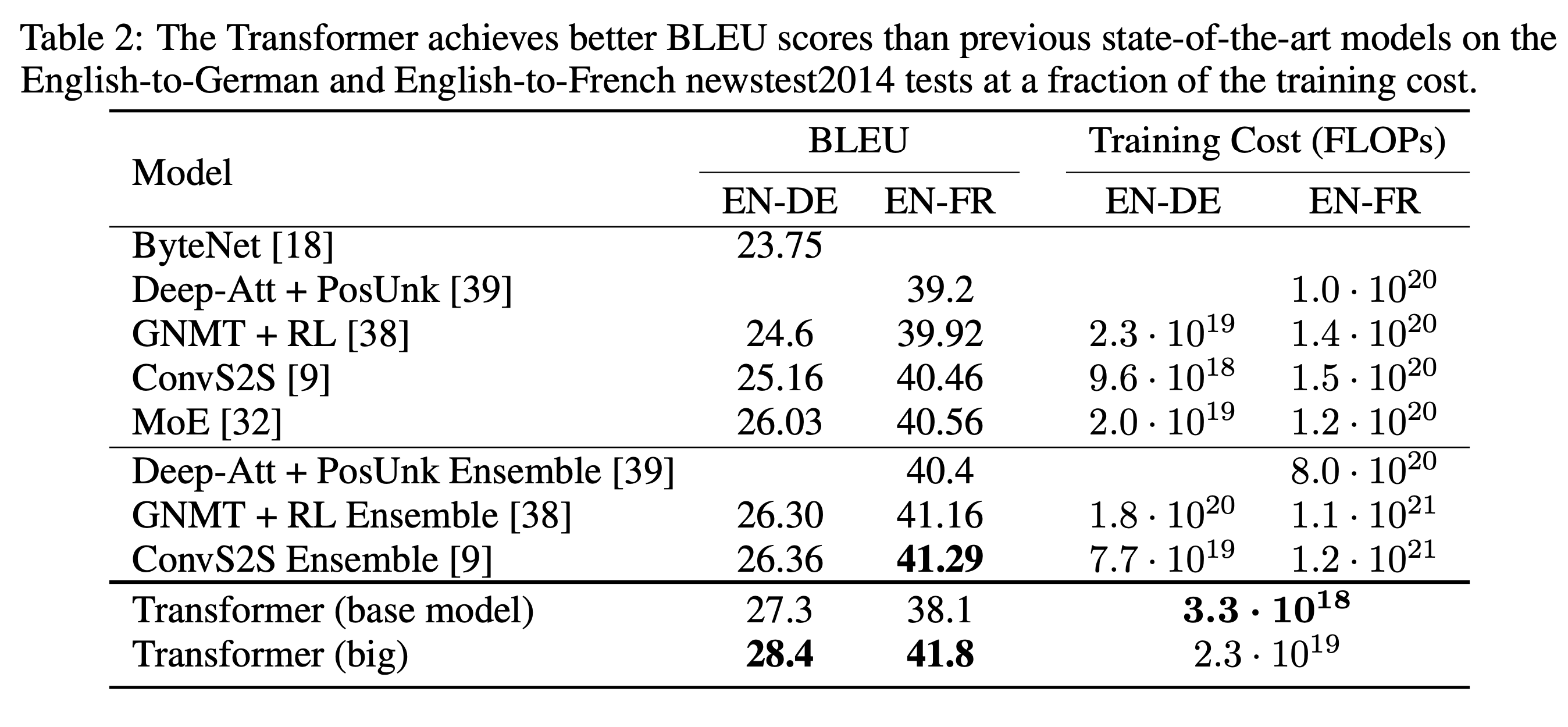
SOTA를 달성하였고, 거기에 Training Cost까지 엄청나게 줄였음을 알 수 있다. 원래 의도였던 RNN의 문제점을 어느 정도 해결하였다고 볼 수 있을 것 같다.
아래는 English Constituency Parsing Task를 진행한 것이다.
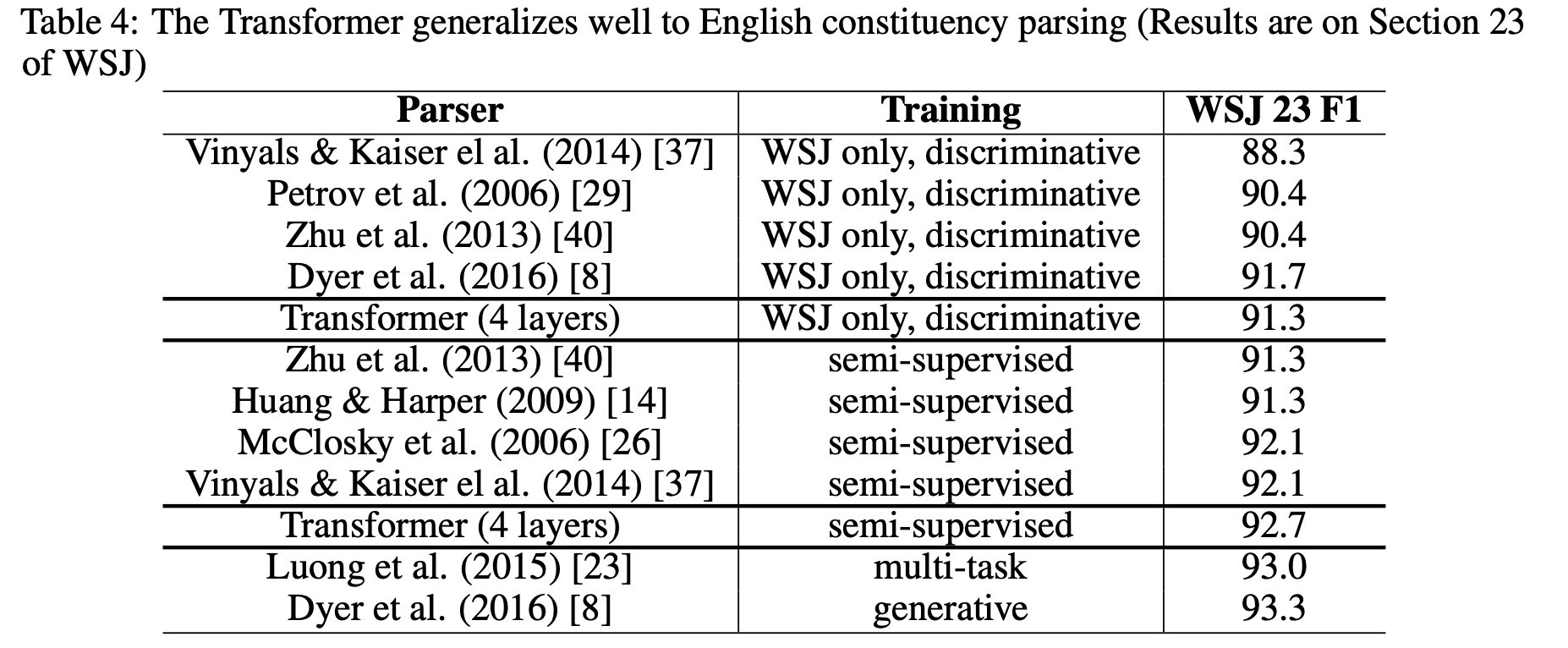
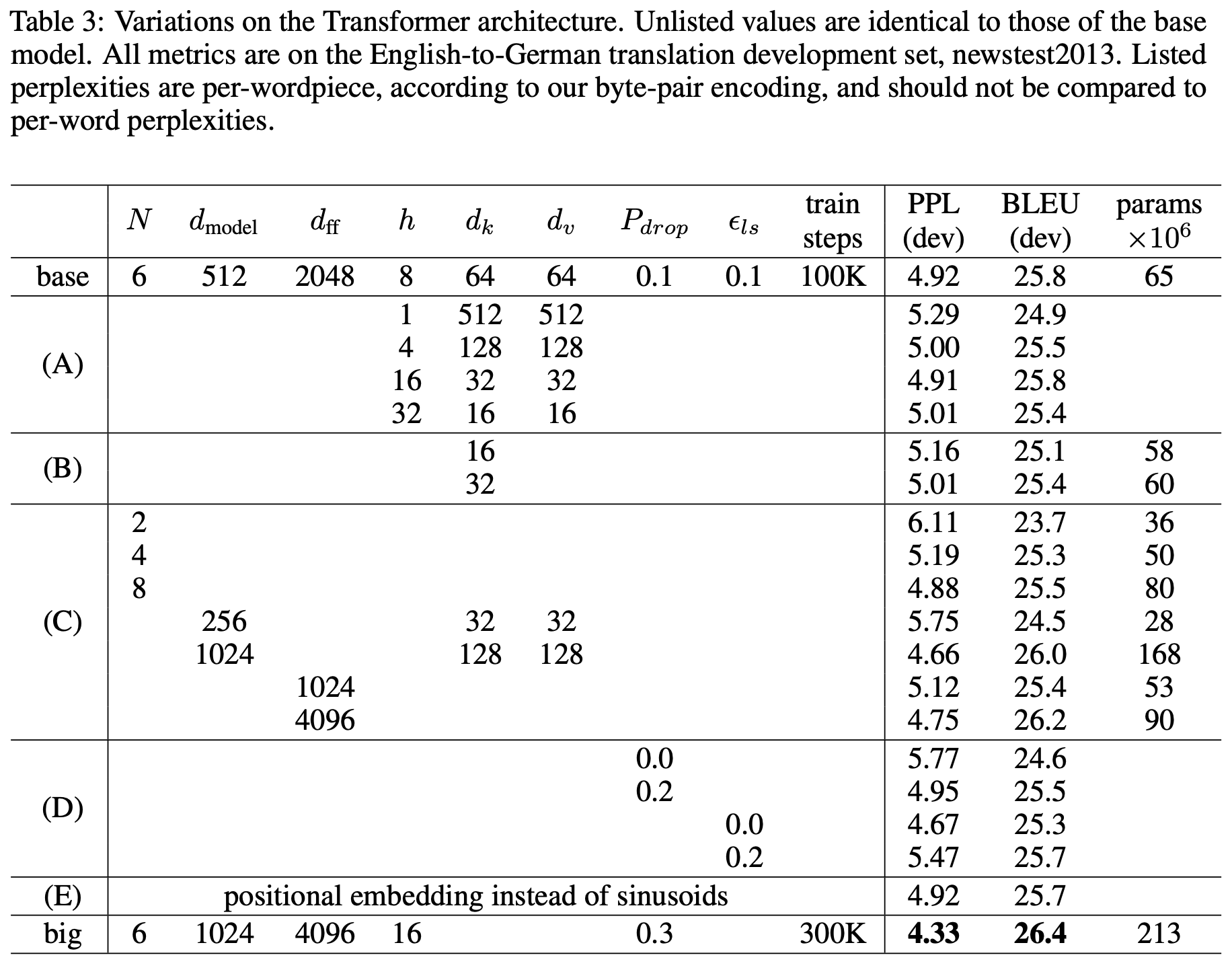
Ablation Study와 비슷하게 구성된 실험도 있는데, 이 내용은 정확하게 이해하고 싶다면 논문 8 ~ 9페이지를 직접 읽어보는 편이 좋을 것 같다.
마무리
행렬들의 크기 정리에 많은 노력을 했었는데, 나중에 가서 실제 모델에서 batch로 묶어서 계산하면 정말정말 너무너무 헷갈린다,, 특히나 batch가 들어가는 차원 순서가 구현마다 다르기 때문에 Attention이 구현된 방법도 조금씩 다르다. Transformer나 Attention을 사용한 NLP 모델을 만들거나 수정해야 한다면 각 행렬들의 차원이 어떤 의미인지 잘 생각하고 할 수 있으면 좋겠다.
아래는 필자가 Transformer 구현 연습해 본 Github이다. 겪은 시행착오들 중에서 가장 힘들었던 부분이 모델이 자꾸 NaN/Inf 값을 만들어 내는 것이었는데, LayerNorm이 없으면 NaN/Inf 값을 만들어 낸다. 아마 모델 안에서 값들이 너무 커지기 때문에 것 같다. Pytorch Github에 있는 구현 참고하는 것도 argument들이 너무 많아서 약간 헷갈리기는 하지만 정말 좋다고 생각한다.

멋져요