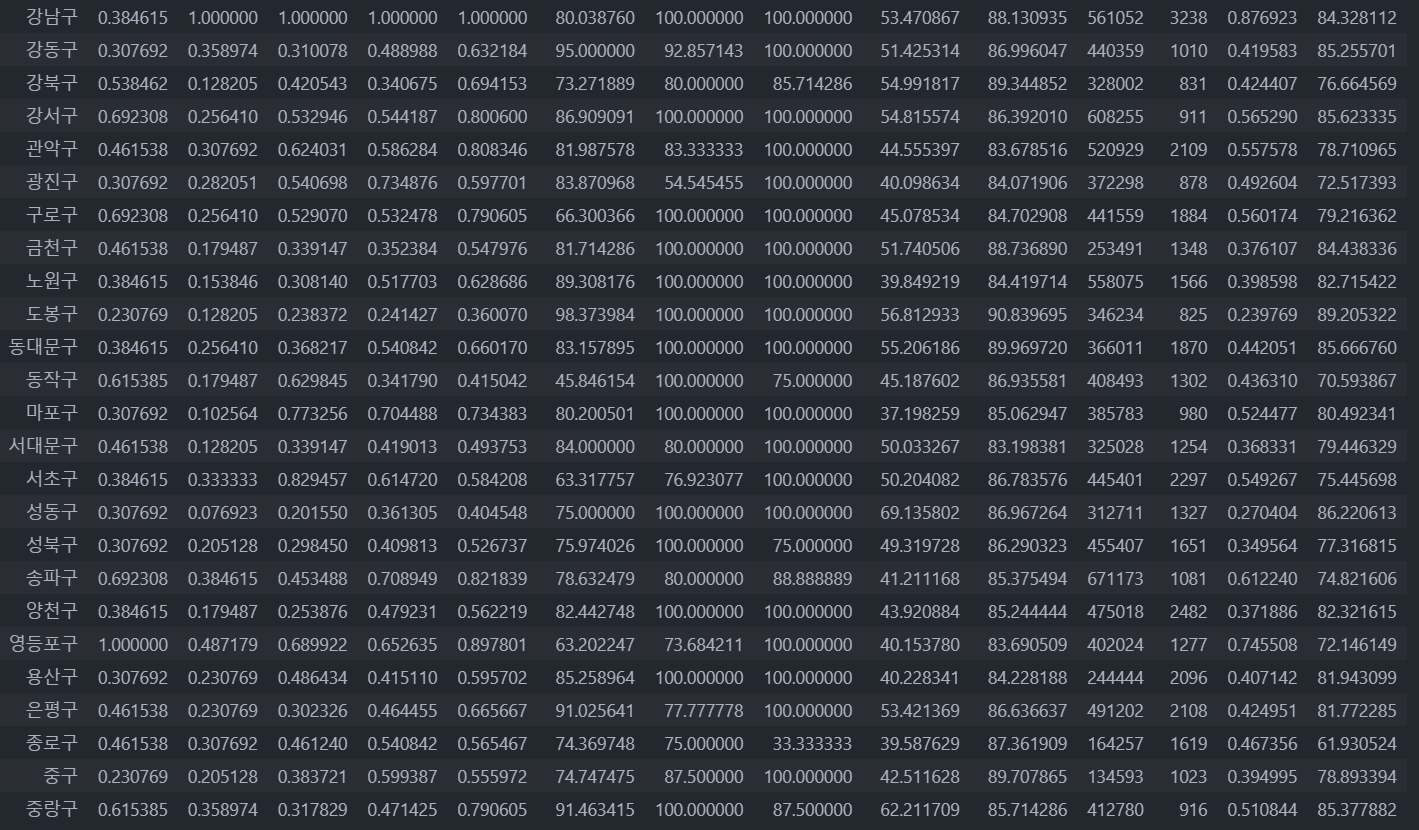
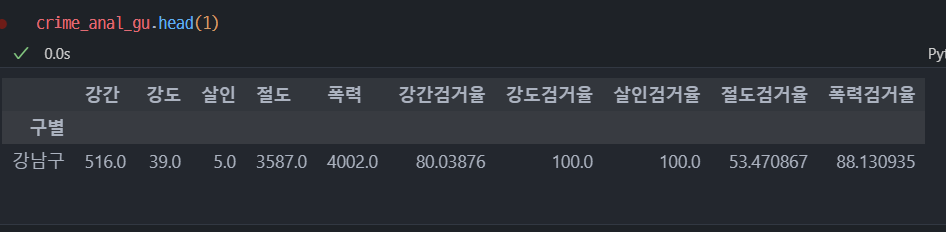
7. 구별 데이터로 정리
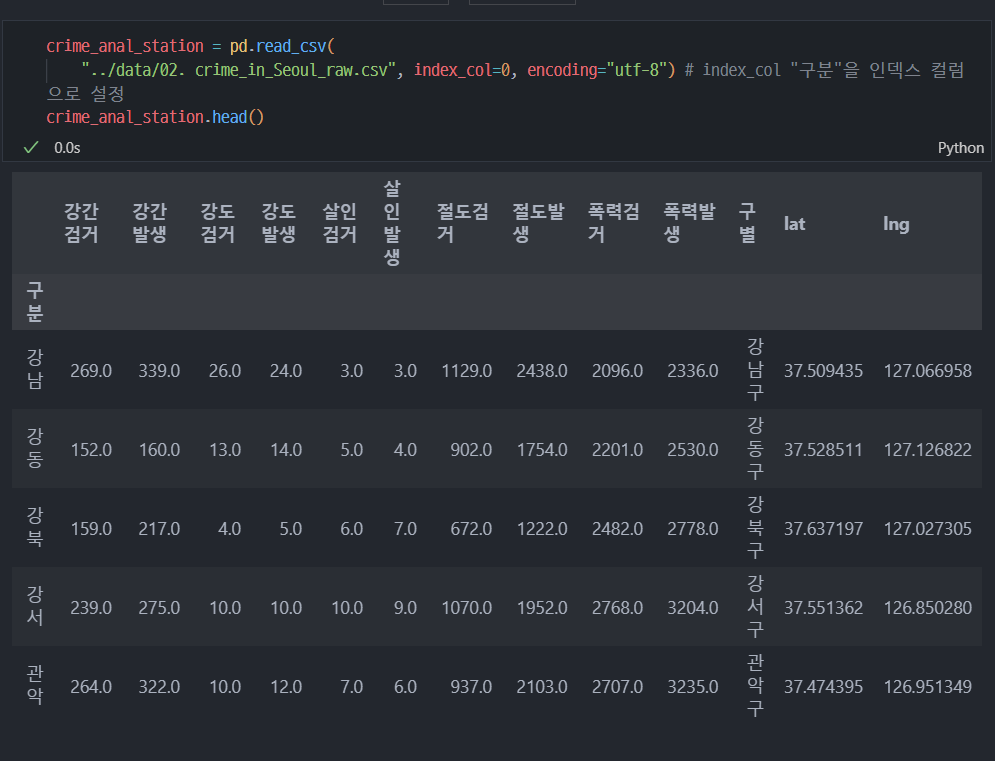
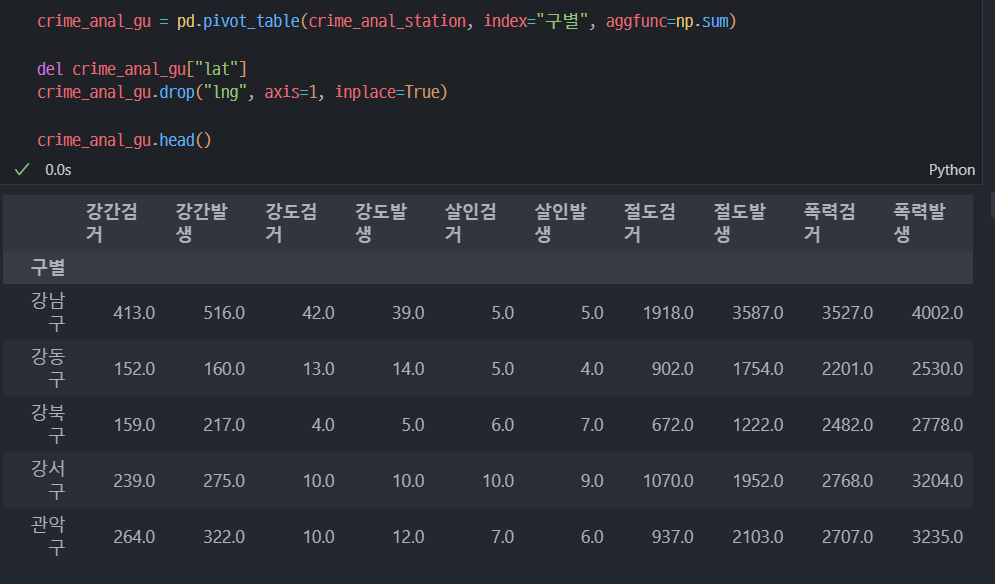
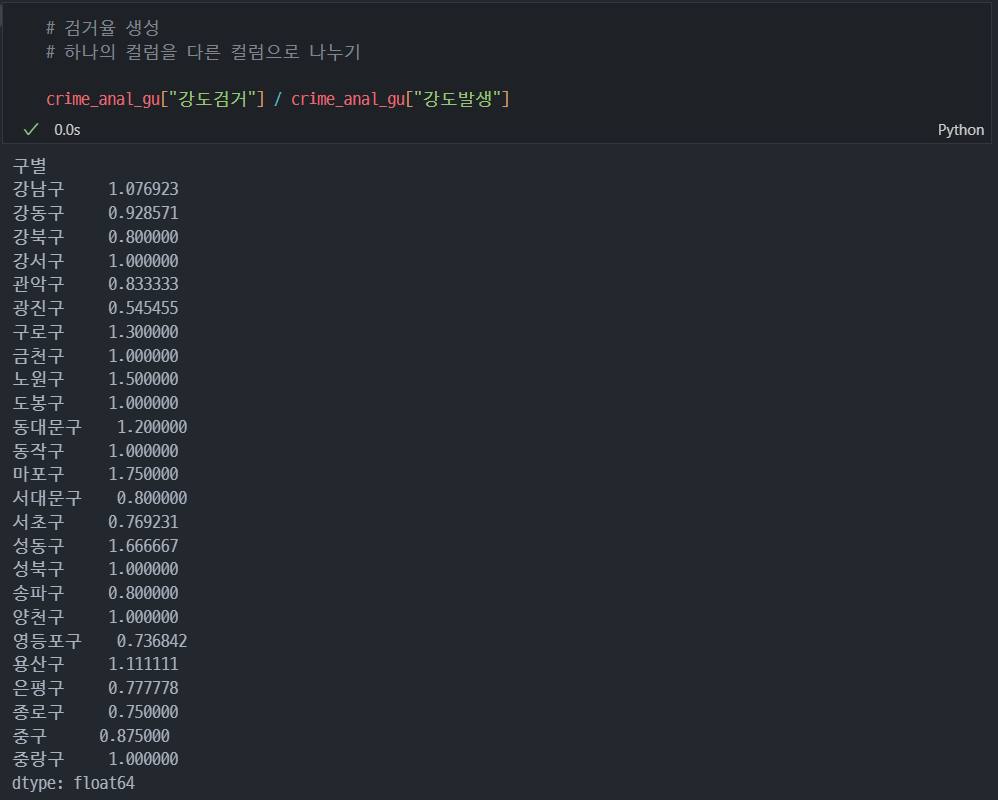
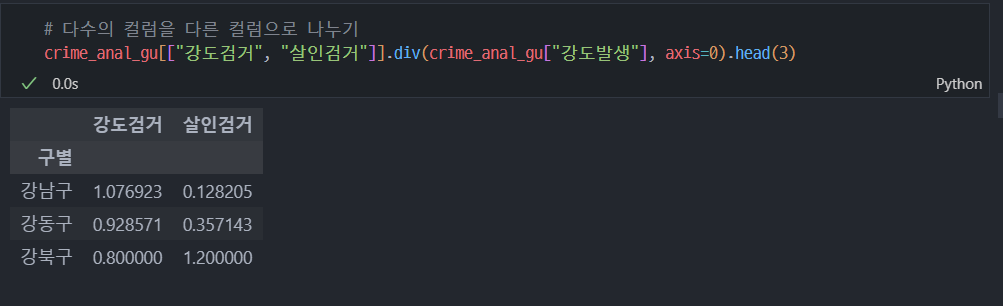
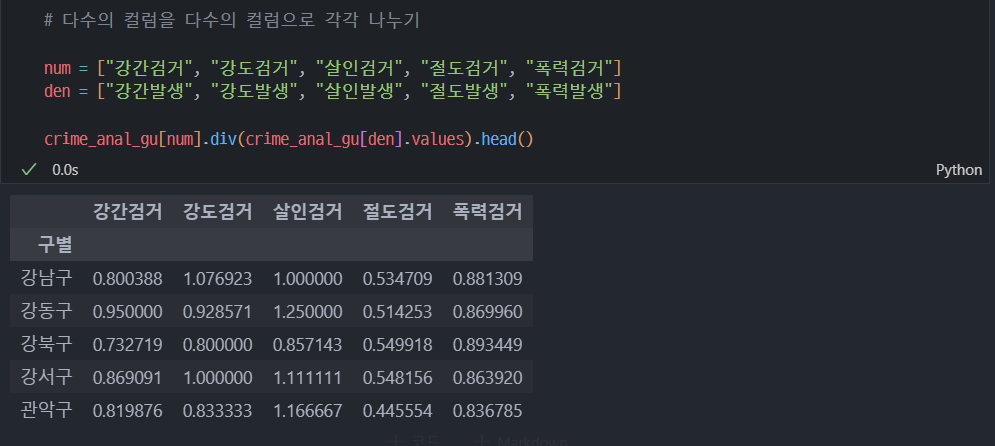
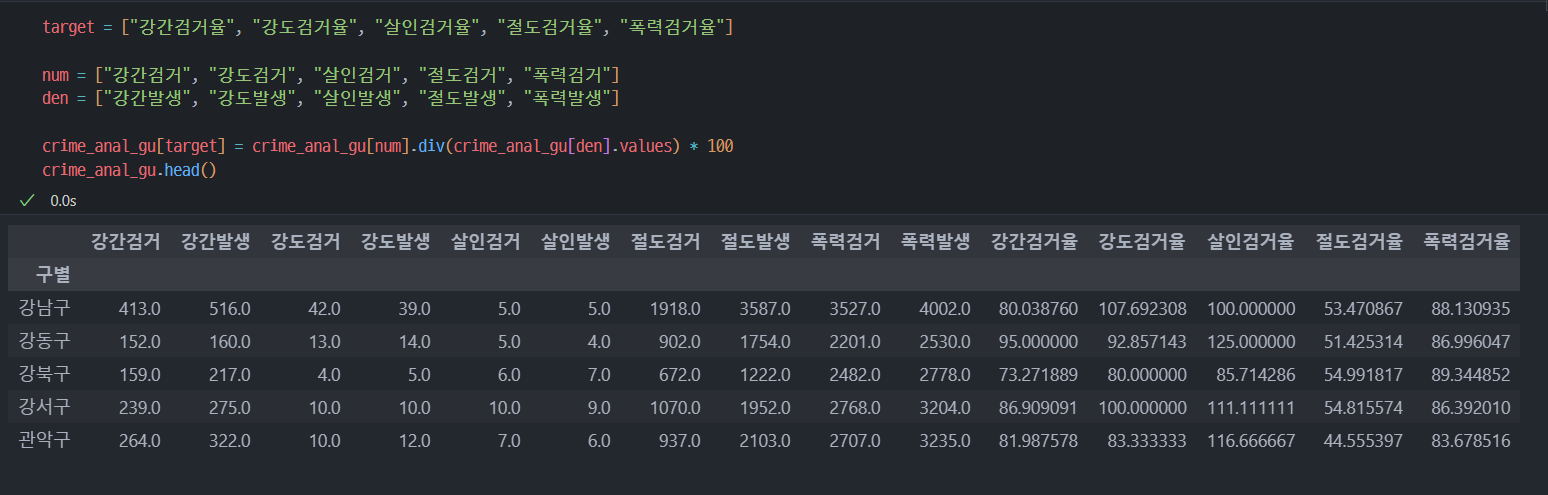
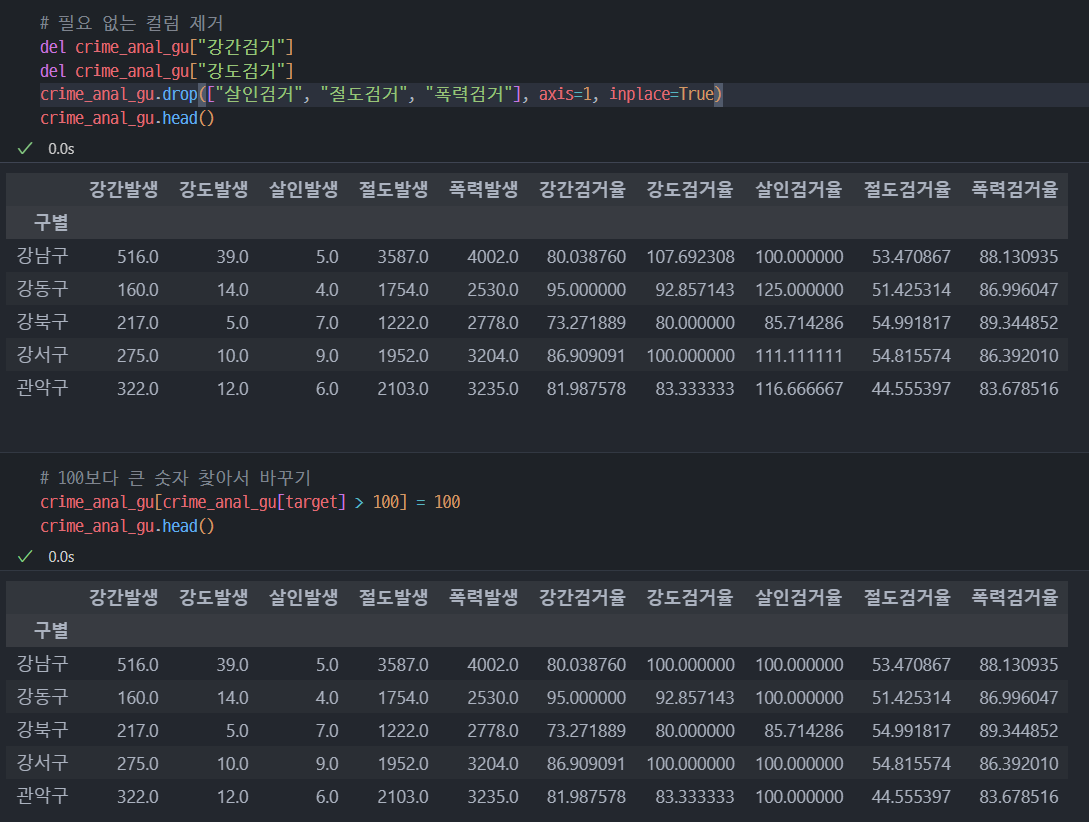
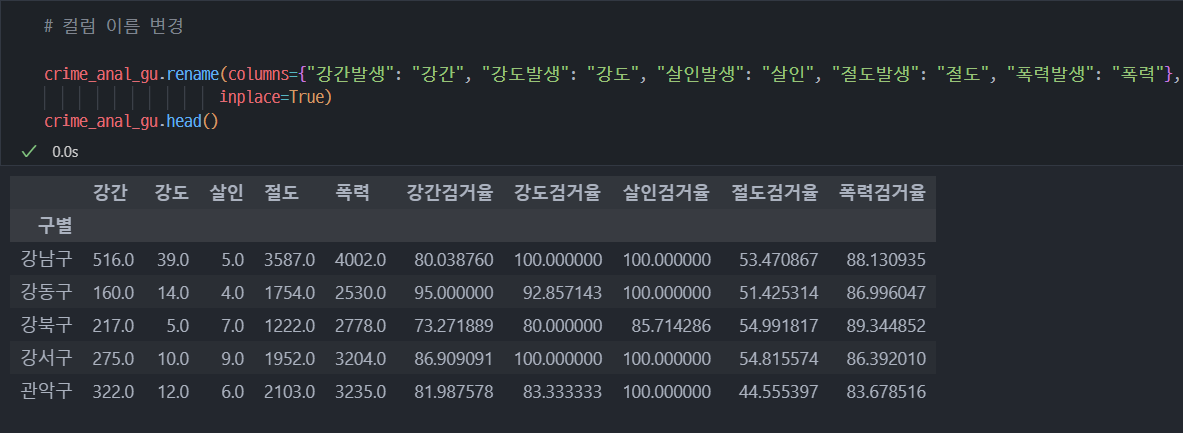
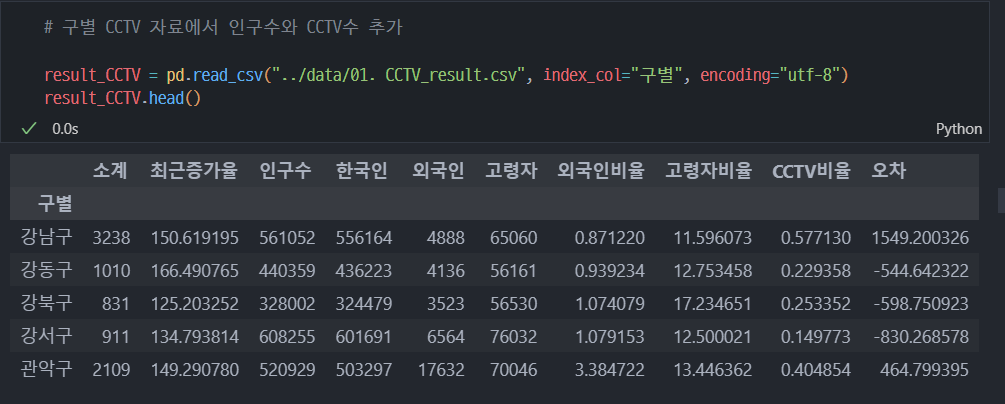
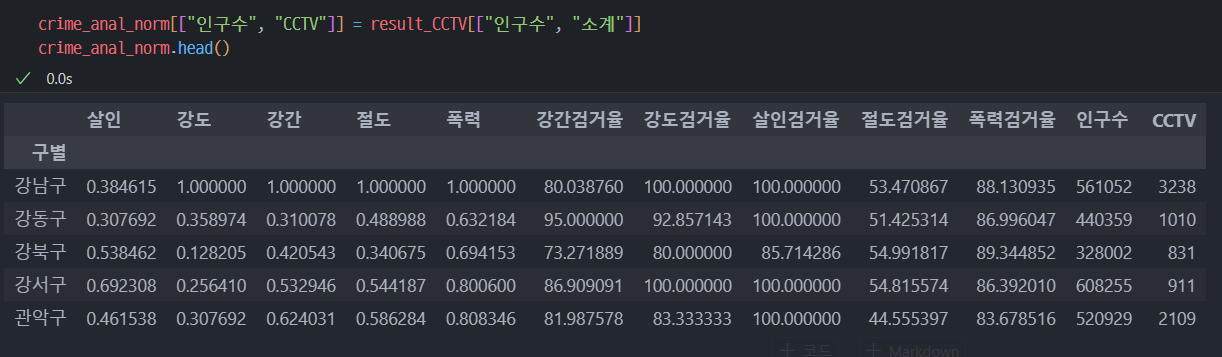
8. 범죄 데이터 정렬을 위한 데이터 정리
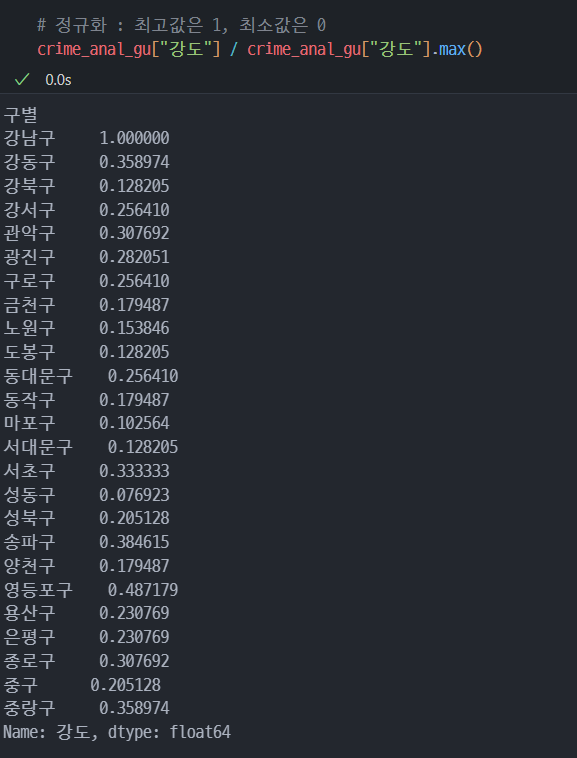
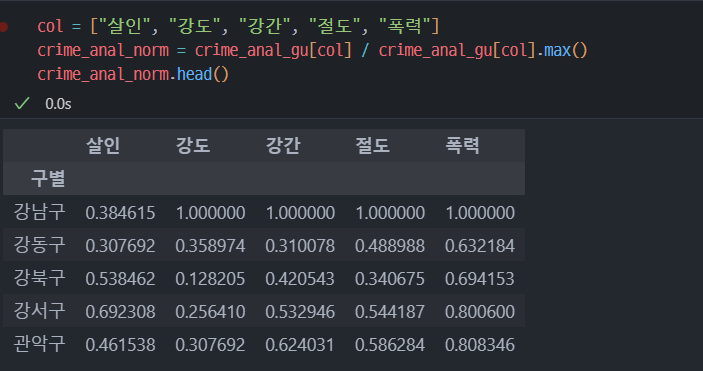
np.mean()
-
import numpy as np
-
np.array([0.357143, 1.000000, 1.000000, 0.977118, 0.733773])
array([0.357143, 1. , 1. , 0.977118, 0.733773])
- np.mean(np.array([0.357143, 1.000000, 1.000000, 0.977118, 0.733773]))
0.8136068
-
np.array(
[[0.357143, 1.000000, 1.000000, 0.977118, 0.733773],
[0.285714, 0.358974, 0.310078, 0.477799, 0.463880]]
)array([[0.357143, 1. , 1. , 0.977118, 0.733773],
[0.285714, 0.358974, 0.310078, 0.477799, 0.46388 ]]) -
np.mean(np.array(
[[0.357143, 1.000000, 1.000000, 0.977118, 0.733773],
[0.285714, 0.358974, 0.310078, 0.477799, 0.463880]]
), axis=1) # axis=1 행, axis=0 열array([0.8136068, 0.379289 ])
-
np.mean(np.array(
[[0.357143, 1.000000, 1.000000, 0.977118, 0.733773],
[0.285714, 0.358974, 0.310078, 0.477799, 0.463880]]
), axis=0) # axis=1 행, axis=0 열array([0.3214285, 0.679487 , 0.655039 , 0.7274585, 0.5988265])
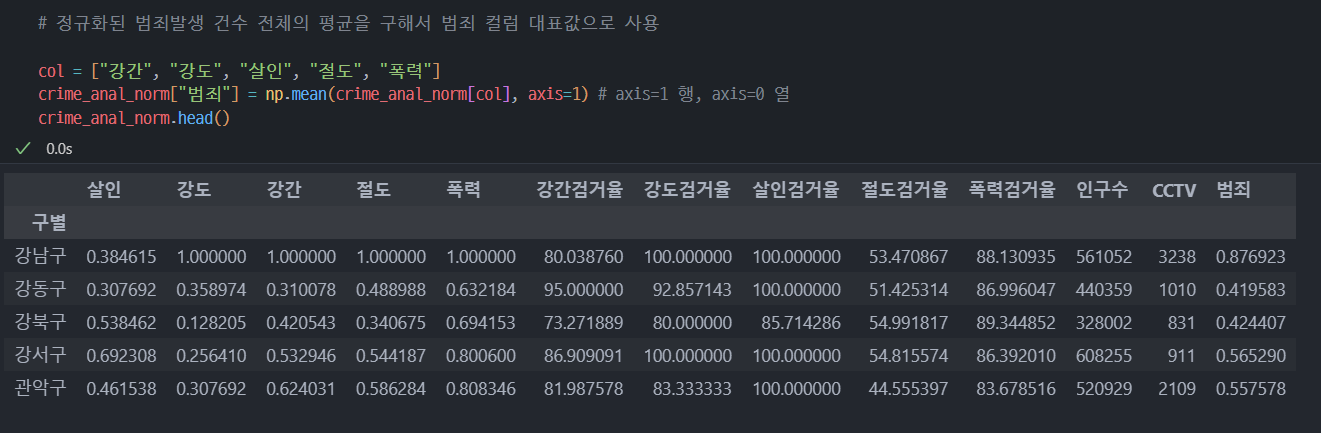
검거율의 평균을 구해서 검거 컬럼의 대표값으로 사용
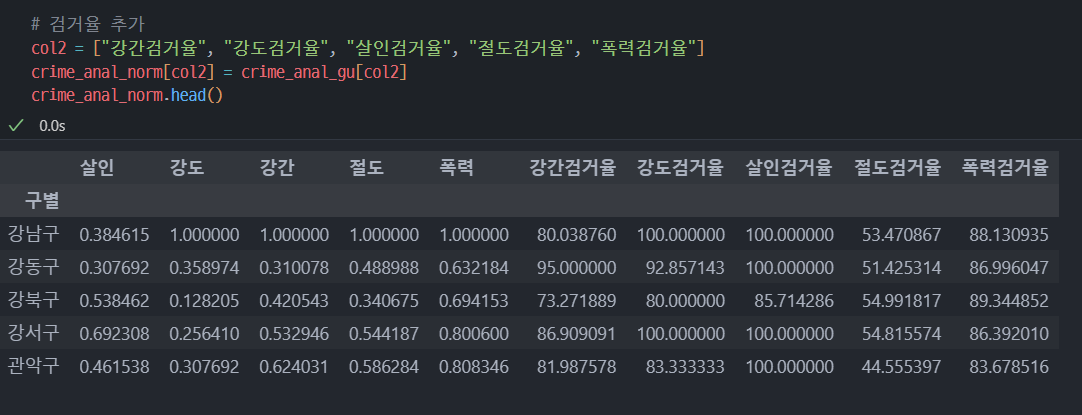
col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col], axis=1) # axis=1 행을 따라서 연산하는 옵션
crime_anal_norm.head()

{kind=link}
- crime_anal_norm = pd.read_csv("../data/02. crime_in_Seoul_final.csv", index_col=0, encoding="utf-8")
crime_anal_norm