
💻 본 포스팅은 [친절한 SQL 튜닝] 내용을 참고하여 작성하였습니다.
SQL 최적화
사용자가 입력한 SQL을 DB 엔진에서 최적화하는 과정을 세분화하면 다음과 같다.
1. SQL 파싱
가장 먼저 SQL parser가 파싱을 진행한다. SQL 파싱은 다음과 같이 일어난다.
- Parsing tree 생성: SQL 문을 이루는 개별 구성요소를 분석해서 파싱 트리 생성
- Syntax check: 문법적 오류가 없는지 확인, 예를 들어, 사용할 수 없는 키워드를 사용하거나 순서를 잘못 사용한 키워드를 확인
- Semantic check: 의미상 오류가 없는지 확인, 예를 들어 존재하지 않는 테이블 이름을 사용한다거나, 권한을 확인
2. SQL 최적화
그 다음은 SQL Optimizer가 SQL 최적화를 수행한다. SQL 옵티마이저는 미리 수집한 시스템과 통계정보를 바탕으로 다양한 실행 경로를 생성해서 비교한 후 가장 효율적인 하나를 선택한다. 데이터베이스의 성능을 결정하는 가장 핵심적인 엔진이다.
3. 로우 소스 생성
SQL Optimizer가 선택한 실행경로를 실제 실행 가능한 코드 또는 프로시저의 형태로 포매팅한다. 이는 Row-Source Generator가 수행한다.
SQL Optimizer
SQL 옵티마이저는 사용자가 원하는 작업을 가장 효율적으로 실행하게 해주는 DBMS의 핵심 엔진이다. 옵티마이저의 최적화 단계는 다음과 같다.
- 사용자로부터 전달받은 쿼리를 수행할 때 실행계획(쿼리 플랜) 후보군을 찾아낸다.
- 데이터 딕셔너리에 미리 수집해 둔 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
- 최저 비용을 나타내는 실행계획을 선택한다.
실행 계획 (쿼리 플랜)이란?
DBMS에서는 'SQL 실행경로 미리보기' 기능을 제공하는데, SQL 옵티마이저가 생성한 처리절차를 사용자가 확인할 수 있도록 하는 것이다. 예를 들어, 일상에 비유하자면 A에서 B 장소를 갈 때 어떤 도로를 이용했고 어떤 교통수단을 이용했는 지에 대한 정보를 보여준다.
자신이 작성한 SQL이 테이블을 스캔하는지, 인덱스를 스캔하는지, 인덱스를 스캔한다면 어떤 인덱스를 탔는지 등을 모두 볼 수 있다.
Optimizer hint
기본적으로 옵티마이저는 최소 비용으로 예상되는 실행 계획을 따르지만 어디까지나 추정치이므로 항상 최선의 방식으로 동작하지 않을 수 있다. 그래서 개발자가 생각한 실행계획을 따르도록 Optimizer에게 알려줄 수 있는데, 이것이 힌트(hint)이다.
예를 들어 어떤 고객 테이블이 있고, 여러 인덱스가 설정돼있다고 하자. DB 공부를 열심히 한 백엔드 개발자가 어플리케이션 코드 상에서 SELECT를 해올 때 특정 인덱스를 사용하면 좋을 것 같다는 생각을 했다. 그런데 실행계획을 보니 자신의 생각과는 달리 동작하였고, 힌트를 통해 자신의 생각대로 SELECT 하도록 하고 싶다. 그 때 hint를 사용할 수 있다.
힌트의 종류는 굉장히 많은데, 대략 테이블을 어떤 식으로 액세스할 지, 인덱스 스캔을 한다면 어떤 INDEX를 선택할 지, 테이블을 조인한다면 어떤 테이블 순서로 조인할 지, 어떤 조인을 사용할 지 등등 세부적인 조건을 모두 정해줄 수 있다.
SQL 공유 및 재사용
SQL을 짜다보면 우리가 짜는 코드와 크게 다른 점이 있다. 바로 각 쿼리에 이름이 없다는 점이다. 우리가 작성하는 메서드들은 이름을 가지고 있고, 파라미터를 달리하여 재사용할 수 있게 되어있다. 그런데 일반적으로 작성하는 SQL은 이름이 존재하지 않고, 매번 실행할 때마다 문법이 바뀐다거나 변수 이름을 달리 쓸 수 있다. 이런 경우에 이 SQL은 매번 새롭게 생성되는 것일까?
Soft parsing vs Hard parsing
이를 이해하려면 라이브러리 캐시라는 개념부터 알아야 한다. 라이브러리 캐시란 SQL parsing, Optimization, Row source 생성 과정을 거쳐 생성한 내부 프로시저를 (앞서 기술한 SQL 최적화 과정이다.) 캐싱해두는 메모리 공간이다.
여기서 유추할 수 있는 점은 SQL을 캐싱한다는 점에서 분명 재사용이 가능은 할 것이다.라는 점을 알 수 있다. 라이브러리 캐시는 SGA(System Global Area) 구성요소인데, 이는 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간이다.
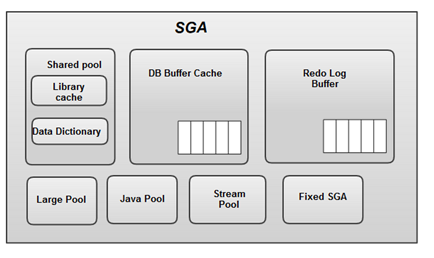
단, MySQL의 경우는 PostgreSQL와 MySQL은 Oracle처럼 SQL 관련 정보를 저장하기 위한 Global한 공유 메모리 영역이 존재하지 않습니다. 대신 Prepare Statement(Prepare ~ Execute) 기능을 통해 변수값만 변경되는 동일 패턴의 SQL은 비슷한 효과를 낼 순 있지만, 해당 정보가 Session 간 공유되지는 않습니다. 또한 Deprecate 된 Query Cache 기능의 경우 엄밀히 말하면 Parsing 단계를 단축하기 위한 목적이 아니므로 Oracle의 Result Cache 기능과 비교 가능합니다. 라고 한다.
캐싱 데이터를 이용하는 지점은 사용자가 SQL 문을 전달하고 나서 DBMS가 파싱한 후에 이 SQL이 라이브러리 캐시에 존재하는지 확인한다. 만약 존재하지 않는다면 앞서 기술한 나머지 단계를 수행하게 된다.
만약 SQL을 캐시에서 찾아 곧바로 실행했다면 소프트 파싱(Soft parsing), 찾는데 실패하여 모든 최적화 과정을 거쳐 실행했다면 하드 파싱(Hard parsing)이다.
SQL 최적화는 왜 어려운가?
- 당연하게도 같은 쿼리를 실행하더라도 경우의 수가 너무 많기 때문이다.
- 조인 순서, 스캔 방법 등 때문에 무수한 경우의 수를 다 검토해야 한다.
- 즉, 하드 파싱이 일어나면 이런 과정을 다 거치기 때문에 CPU를 많이 소비할 수 밖에 없다. 이 작업이 DB에서 CPU를 많이 사용하는 몇 안되는 작업이다.
- 그럼 당연하게도 이렇게 어려운 작업을 거쳐 만든 SQL을 한 번만 사용하고 버린다면 엄청난 비효율일 것이다. 그렇기 때문에 라이브러리 캐시가 존재한다.
SQL은 이름이 없다.
그럼 SQL을 어떻게 구별하고 재사용할 것인가? SQL은 텍스트 전체가 이름이다. 즉, 대/소문자, 변수, 심지어는 주석에 따라서도 모두 이름이 달라진다.
예를 들어 어떤 쇼핑몰에서 로그인 모듈 담당 개발자가 프로그램을 아래와 같이 작성했다고 하자.
public void login(String loginId) throws Exception {
String SQLStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID + '" + loginId + "'";
Statement st = con.createStatement();
ResultSet rs = st.executeQuery(SQLStmt);
if (rs.next()) {
// do anything
}
rs.close();
st.close();
}그리고 이벤트가 있어 동시에 백만 사용자가 로그인을 시도했다고 하자. 그럼 I/O는 적지만 하드 파싱으로 인해 CPU 사용률이 계속 올라가고 라이브러리 캐시에서는 여러 종류의 경합 때문에 로그인 처리가 제대로 되지 않을 것이다.
즉, loginId가 달라짐에 따라 계속 새로운 SQL을 만들어 적재하는 과정이 들어가기 때문에 CPU를 낭비하는 셈이 된다. (추가로 SQL injection에도 취약하다.)
하드 파싱을 피하고 효과적인 쿼리를 짜려면 아래와 같이 작성할 수 있다.
public void login(String loginId) throws Exception {
String SQLStmt = "SELECT * FROM CUSTOMER WHERE LOGIN_ID = ?";
PreparedStatement st = con.prepareStatement(SQLStmt);
st.setString(1, loginId);
ResultSet rs = st.executeQuery();
if (rs.next()) {
// do anything
}
rs.close();
st.close();
}이렇게 바인드 변수를 사용하는 경우에는 파라미터 Driven 방식으로, 우리가 작성하는 메서드와 같은 형태로 SQL을 작성할 수 있다.
예를 들어 create procedure LOGIN (login_id in varchar2) { ... } 와 같은 형태이다.
따라서, 파라미터가 달라지더라도 하나의 SQL을 캐싱하여 소프트 파싱만 일어나도록 수행할 수 있게 된다.
출처
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=geartec82&logNo=220330254534
https://blog.ex-em.com/m/1683/comments


Sql 최적화가 이렇게 이뤄지는군요. 다음 시리즈도 기대가 됩니다!! 🫵