
파일은 누구나 알고 모든 사람들이 쓰는 용어다. (적어도 데스크탑을 써본 사람이라면) 파일을 열고 읽고 쓰고 닫고 삭제할 줄 안다.
하지만 그 파일이 어떻게 '파일'로 존재할 수 있는지. 컴퓨터는 어떻게 수십만 개의 파일을 관리하는지. 우리가 파일 탐색기에서 본 것말고 또 어떤 파일들이 있는지. 이런 지식은 나도 잘 몰랐다.
이번 글에선 파일에 대해 좀 더 깊이 들어가 본다.
파일은 간단해보이지만, 운영체제의 원리를 이해하기 위한 필수 개념이다.
파일은 도서관에 꽂혀있는 책이다
파일이란 보조 저장 장치(ex. 디스크)에 정보를 저장하는 단위다.
파일이라는 이름은 종이로 된 서류 관리 시스템에서 왔다. 종이 문서는 하나의 '파일철'로 묶어 책처럼 저장할 수 있다.

'파일'을 하나의 책이라고 생각해보자.
그리고 파일이 저장되는 디스크 공간은, 수많은 책이 꽂힌 큰 하나의 도서관이라고 생각해보자.

이 도서관은 굉장히 많은 정보를 담고 있다. 도서관 정보는 '책'의 형태로 묶여서 저장된다. (아니면 서류철이라고 해도 되고.)
책이 관련된 텍스트를 묶은 것처럼, 디스크에 저장 연관 정보를 묶으면 파일이 된다.
운영체제는 정보를 파일 형태로 쓴 뒤 저장하고, 찾아서 읽는다.
파일에 체계를 잡아주는 파일 시스템
아직 파일이 들어오지 않은 도서관을 상상해보자.
도서관은 지금 비어있다. 이제부터 끊임없이 새로운 책들이 들어오고 나갈 것이다.
그런데 책을 그냥 마구잡이로 쌓아두거나, 어떤 책이 있는지 기록해두지 않거나, 책을 다루는 어떤 규칙을 만들지 않으면 어떻게 될까?
계속해서 새로운 파일이 들어온다.
도서관은 금방 정신없는 아수라장이 된다. 아무도 원하는 책을 제대로 찾을 수가 없다.

하지만 실제 도서관은 훨씬 체계적이다.
책에 관리 번호를 붙인다. 주제별로 분류한다. 어떤 책이 있는지 기록한다. 어떤 위치에 꽂을지 결정하는 규칙을 만든다.
이런 체계가 있기 때문에 수많은 책을 저장하고도 편리하게 정보를 꺼내 쓸 수 있다.

파일도 마찬가지다. 저장공간에 무질서하게 넣어둘 수는 없다. 파일을 관리하는 체계가 필요하다. 이걸 '파일 시스템'이라고 한다.
파일 시스템은 파일 이름과 파일 정보, 저장 공간을 관리하고 파일을 효율적으로 찾을 수 있도록 도와준다.
어떤 컴퓨터든 보조 저장 장치가 필요하다. 그래서 파일 시스템은 운영체제에서 빼놓을 수 없는 부분이다.
우리가 컴퓨터에서 파일을 열고 쓸 때마다, 운영체제는 파일 시스템을 사용한다.
우리가 책이 필요하거나 새로운 책을 보관할 때, 도서관 시스템을 사용하는 것과 마찬가지다. 파일에 읽고 쓸 일이 있을 때마다 운영체제는 파일 시스템을 사용해 디스크에 데이터를 읽고 쓴다.
파일 시스템은 어떤 운영체제든 필수로 포함되어있지만, 종류는 다 다르다. 도서관마다 책을 관리하는 방법이 다 다르듯이, 저장공간도 각자 쓰는 파일 시스템이 다를 수 있다.
대표적으로 윈도우는 FAT(12/16/32, exFAT), NTFS, 리눅스는 ext(2/3/4), 맥OS는 HFS+, APFS 등의 파일 시스템을 사용한다.
파일 시스템이 하는 일을 조금 더 구체적으로 알아보자.
1. 파일의 메타데이터 관리
도서관 관리 시스템을 생각해보자. 기본적으로, 저장된 책에 대한 정보를 저장하는 시스템이 있다. 책의 이름, 저자, 최근 빌려간 날짜, 반납된 날짜, 대분류/소분류, 서가 위치 등. 이 책 정보가 있어야, 책을 가져갈 수 있는지, 어디에 있는지 등을 알 수 있다.
마찬가지로 파일 시스템의 중요한 역할은, 파일의 메타 데이터 관리다.
파일 메타데이터는 파일에 대한 데이터를 저장한다.
- 파일 크기
- 만들어진 시각
- 마지막 접근 시각
- 변경된 시각
- 파일 소유자
- 파일 접근 모드
- 어떤 블록에 저장되어있는지
파일 시스템은 파일의 내용과 파일 메타 데이터를 따로 나눠서 저장한다.
유닉스 계열에서는 이 메타데이터를 저장하는 자료 구조를 i-node라고 부른다. i-node는 파일이 정확히 어떤 위치에 저장돼있는지를 포함한다.
도서관의 책 정보가 책을 대출하고 찾기 위한 정보인 것처럼, i-node는 파일에 접근하기 위한 열쇠가 되는 정보다.
모든 파일은 i-node를 가지고 있다. i-node에는 고유한 정수 번호가 매겨져있다. 이 번호를 가지고 i-node 객체에 접근할 수 있다.

(유닉스 계열 운영체제에서 ls -i 명령어를 입력한 결과. 현재 디렉토리 내 파일의 i-node 번호를 볼 수 있다.)
디렉토리와 계층 구조
'디렉토리'는 여러 파일을 묶어놓은 단위다. 컴퓨터를 쓰다보면 파일의 개수가 많아진다. 디렉터리로 분류하면 잘 정리된 형태로 파일을 찾을 수 있다.
/computer_science/operating_system/file_system/directory.txt 이런 식으로 대분류부터 소분류까지 파일 경로로 표현할 수가 있다.
디렉터리 안에 또 디렉터리를 넣을 수 있고, 하위 디렉터리에 파일을 넣어 구조화하는 방식을 '계층적 파일 시스템'이라고 한다.
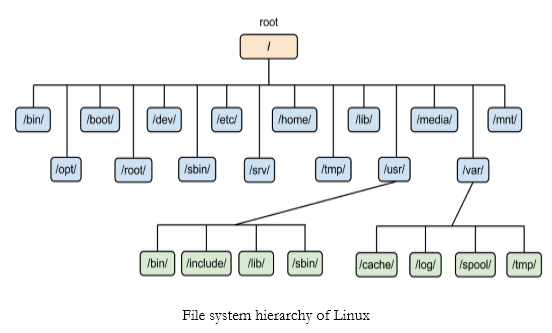
뭐, 사실 너무나 익숙해서 굳이 설명이 필요한가 싶다. 하지만 이것도 유닉스가 만들어지던 당시에는 꽤나 참신한 방법이었다고 한다. 유닉스 이전에는 파일 시스템에 규칙성이 부족했고, 계층적 파일 시스템이 별로 없었다.
우리가 잘 모르고 있는 부분은 디렉터리도 결국 파일이라는 점이다. 디렉터리는 하위 파일의 '링크'를 담고 있는 특수한 형태의 파일이다.
링크
앞서 파일 시스템은 i-node 번호를 가지고 파일의 메타데이터를 찾고, 그 메타데이터로 파일을 열고 읽고 쓸 수 있다고 했다.
하지만 i-node 번호는 그냥 숫자다. 사람은 숫자를 잘 기억 못한다. 대신 사람은 '파일 이름'으로 파일을 찾는다.
(도서관의 비유에서도 마찬가지다. 도서관에는 책의 일련번호가 매겨져있고, 그걸로 시스템을 관리한다. 하지만 사람은 일련번호가 아닌 이해하기 쉬운 책 이름으로 책을 찾는다.)
그렇다면 특정 파일 이름이 어떤 i-node 번호를 가리키는지 알아야겠지?
이걸 '링크'라고 한다. 링크는 파일 이름과 i-node를 저장한다. 이름만 입력하면 실제 파일을 찾을 수 있게 해준다.
링크를 모아놓은 디렉터리
디렉터리도 파일이다. 다만 디렉터리는 '자신에게 속한 파일 링크'를 저장하는 파일이다. 디렉터리 파일엔 다른 내용은 읽거나 쓸 수 없다. 오직 링크를 추가하거나 삭제할 수만 있다.
디렉터리를 열어 내용을 읽으면 링크들이 있고, 이 링크들은 실제 파일을 찾아갈 수 있도록 정보를 저장하는 '포인터' 역할을 한다.
디렉터리 안에 또 다른 디렉터리에 대한 링크가 있을 수 있다. 이렇게 파일 이름과 i-node를 가진 디렉터리가 계속 중첩된다. 이 중첩 구조가 트리를 이룬다.
이 트리 구조가 방금 말했던 '계층적 트리 구조'다. 우리가 잘 알고 있는 '파일 경로'가 여기서 나온다.
경로로 파일을 찾아내는 법
사용자는 시스템에 파일 경로를 주고 파일을 찾도록 할 때가 많다. 다음과 같은 경로를 주면서 커널에게 파일을 열어달라고 요청했다고 하자.
/home/black/bird.png
루트 디렉터리는 보통 이미 커널에서 알고 있다. 루트 디렉터리를 열어본 커널은 home이라는 이름의 파일 링크를 찾는다. home은 디렉터리이면서 파일이기 때문에 i-node를 갖고 있다.
home의 i-node를 가지고 커널은 home의 내용을 읽어낸다. 그 안에는 또 여러 링크가 들어있다. 그 중 black이라는 디렉터리를 찾는다.
black이라는 디렉터리를 읽어낸 커널은 bird.png라는 파일을 찾는다. 링크에서 i-node를 알아내고, 최종적으로 bird.png의 내용에 접근한다.
절대 경로와 상대 경로
파일 경로에는 '절대 경로'와 '상대 경로'가 있다.
루트 디렉터리에서 시작하는 경로 이름은 누락이 없는 완전한 형태라서 '절대 경로'라고 한다.
반대로 현재 디렉터리에서 본 상대적 위치로 나타내면 상대 경로라고 한다.
디렉터리에는 기본적으로 자기 자신을 뜻하는 .와 부모 디렉터리를 뜻하는 '..' 항목이 있다.
따라서 상대 경로는 흔히 .으로 시작한다. ./download/text.txt 이런 식이다.
현재 경로와 상대 경로를 합치면 절대 경로가 된다.
디스크 주소와 블록 매칭
도서관을 다시 떠올려보자. 책을 직접 꺼내오려면 책이 어디 꽂혀있는지 알아야 한다. 이 때 책의 위치는 어떻게 표현할까?
'3층 5번째 책꽂이로 가서 왼쪽에서 두번째, 위에서 세번째 선반을 보시면, 11번째에 꽂혀 있습니다'
실제 물리적인 위치를 표현한다면 이게 가장 정확할 것이다. 책꽂이는 여러개가 연속되어있고, 위에서부터 몇 개의 층으로 이뤄져있고, 또 그 안에서 순서대로 책이 꽂혀있을 테니까.

하지만 저 대사만 봐도 알 수 있듯이 이건 너무 번거롭다. 도서관에서는 별도로 서가 번호를 매긴다. 왼쪽 첫번째 서가부터 차례대로 번호를 매기는 거다.
43번 서가에 가면 있습니다.
이제 한 마디로 빠르게 책이 꽂힌 위치를 찾을 수 있다. 이것도 역시 도서관에 '체계'가 있기 때문에 가능한 일이다.
섹터와 블록
마찬가지로 디스크도 물리적인 주소 공간을 나타내는 단위가 있고, 논리적인 단위가 따로 있다.
디스크를 물리적으로 나눠놓은 최소 단위는 '섹터'다. 섹터는 디스크 공간의 한 조각이다.
섹터는 대부분 512 byte 크기다. 512byte보다 더 큰 파일은 여러 섹터에 나눠서 담긴다.
그런데 GB를 넘어가는 큰 파일들은, 천만 개가 넘는 섹터에 나눠서 담아야 한다.
이렇게 많은 섹터를 하나씩 읽어서 파일을 읽고 쓰려면 굉장히 느릴 수밖에 없다.
그래서 파일 시스템은 물리적 섹터를 몇 개씩 묶어서 '블록'이라는 단위와 매칭한다.
덕분에 파일 시스템은 한 블록에 있는 섹터 여러개를 한꺼번에 읽고 쓸 수 있다. 데이터를 더 빠르게 읽고 쓸 수 있다.
블록은 물리적으로 존재하는 주소는 아니지만, 파일 시스템이 어떤 블록에 어떤 물리 주소가 대응되는지 정보를 관리하기 때문에 사용할 수 있다.
커널에서는 '블록' 단위로 파일의 위치를 지정하고 내용을 저장한다. '블록' 단위를 전달받은 파일 시스템은 실제 기기를 읽을 때 물리적 주소인 섹터 단위로 변환해서 접근한다.
(파일 제어 블록, 프로세스 제어 블록 등 커널에서 관리하고 디스크에 저장되는 정보에 '블록'이라는 단어가 들어가는 이유다. 블록 단위로 저장되기 때문.)
디스크 파편화
기존에 저장해둔 파일 os.txt가 있다. 이 파일은 블록 0-4번에 저장했다. 그리고 os.txt에 새로운 내용을 추가했다. 어? 그런데 블록 5번에 이미 다른 파일이 들어 있다.
어떻게 하지? 뭘 어떻게 해. 비어있는 다른 블록에 저장한다. 11번 블록이 비었으니 저기 저장하자.
이번에는 내용을 삭제한다. 프로세스에서 os.txt의 중간 내용을 삭제해서, 블록 3,4번에 있는 데이터를 지웠다. 중간에 빈 블록이 생긴다.
이렇게 파일을 쓰고 지우고 하다보면, 하나의 파일이지만 물리적으로는 이곳 저곳에 흩어져있고, 중간에 비어있는 곳도 생기게 된다.
이걸 '디스크 파편화'라고 한다. 공간을 효율적으로 쓰면 주기적으로 파편화를 정리해줘야 한다.
예전 윈도우즈 운영체제를 써봤다면, '디스크 조각 모음'을 해봤을 것이다. 이 조각 모음이 파편화를 정리해주는 기능이다.
'조각 모음'은 파일 시스템이 하는 중요한 일 중 하나다. 한 쪽으로 관련된 데이터를 모으고, 빈 공간은 없애준다.
다행히 현대 운영체제의 파일 시스템에선 '조각 모음'을 수동으로 할 필요가 없다. 파일 시스템이 알아서 공간을 효율적으로 정리한다. (게다가 SSD에선 조각 모음이 의미가 없다.)
그 외 파일 시스템이 하는 일
그 외에 파일 시스템이 하는 일은 정말 많다.
파일 크기나 이름에 대한 규칙.
파일에 대한 접근 권한 관리.
디스크를 용도에 따라 나누는 파티션,
파일 탐색용 소프트웨어 등등.
하지만 워낙 방대한 내용이니까 일단은 넘어간다. '파일'이 무엇이고, '파일 시스템'이 어떻게 파일을 저장하고 관리하는지 정도에 대한 감만 잡자.
모든 것이 파일이다
유닉스 계열 OS에서 특히 파일은 더 중요한 개념이다.
책의 챕터 순서만 봐도 알 수 있다. 보통 윈도우즈 계열이나 운영체제 전반을 다루는 책을 보면, 순서가 프로세스(스레드) - 메모리 - 파일이다.
하지만 유닉스/리눅스를 다루는 시스템 프로그래밍 책을 보자. 파일 - 프로세스(스레드) - 메모리 순이다. 가장 앞에서 다룬다. 파일이 가장 중요하기 때문이다.
유닉스 시스템이 거의 모든 자원과 서비스를 파일 형태로 표현하고, 파일을 사용하는 방식으로 시스템 자원을 쓴다. 그러니 중요할 수밖에.
언뜻 들으면 이해가 안 갈 수 있다.
다시 도서관의 비유를 떠올려보자.
이번엔 도서관을 보유한 대학교로 스케일을 키워보자.
A 대학교는 책과 DVD 정도 '파일'로 취급해 도서관에서 보관하고 일련번호를 붙여서 관리하는 시스템을 갖고 있다. 여태까지 우리가 말했던 그런 시스템이다.
그런데 U 대학교에서 갑자기 이런 아이디어를 낸 것이다.
아니, 대학교 안에 있는 모든 장비나 비품도 다 '책'처럼 관리하면 안 되나?
이 대학교는 의자, 책상, 복사기, 전화기, 컴퓨터 등등 시설 내의 다양한 장비들도 마치 '책(파일)'과 똑같은 시스템을 써서 관리하기 시작한다.

(출처: 바이인터랙티브)
언제 누가 샀고, 현재 누가 사용중이고, 위치가 어디에 있고 등등. 이걸 도서관과 똑같은 시스템에서 관리한다.
그랬더니 두 개의 각각 다른 시스템을 쓸 필요도 없었다. (물론 약간 차이가 있는 부분은 기능을 만들어줘야겠지만)
결과적으로 '한 시스템 사용법만 알면 책을 포함한 모든 자산을 관리할 수 있으니 참 편하더라~' 하는 얘기다.
유닉스가 낸 게 바로 이 아이디어였다.
일반적으로 파일은 '실행 프로그램'이나 '데이터'를 저장한다.
하지만 유닉스에선 '저장 장치', '입출력 장치', '네트워크 통신'도 모두 파일이다. 즉, 키보드, 마우스, 디스크, 디스플레이, 인터넷 소켓, 파이프... 다 파일이다.
파일의 내용을 읽을 때도 read()로 하고, 사용자가 키보드에서 입력한 글자를 받아올 때도 read()로 한다.
이렇게 하면 뭐가 좋을까? 인터페이스가 통일된다.
파일을 다루는 툴과 인터페이스로 다양한 시스템 자원을 다룰 수 있다.
예전 운영체제에서는 입출력 장치를 사용할 때 실제 장치의 복잡한 세부사항을 알아야 했다.
하지만 유닉스는 이런 부분을 파일로 최대한 추상화하고, 그냥 파일을 저장하고 읽어오는 인터페이스로 장치를 다룰 수 있게 만들었다.
(이런 장치 파일은 일반 파일과 다르게 중간에 또다른 소프트웨어가 있다. '디바이스 드라이버'다. 장치를 조작할 수 있는 단순한 인터페이스를 제공한다.)
'모든 것이 파일'은 유닉스가 중요시한 철학이었다. 리눅스를 비롯한 유닉스 계열 운영체제도 다 이런 접근법을 물려받았다.
리눅스의 특수 파일 4가지
리눅스에는 3가지 파일 종류가 있다.
- 데이터/프로그램을 담는 일반 파일
- 파일 링크를 저장하는 디렉터리 파일
- 특수 파일.
이 특수 파일이 아까 말했던 다양한 시스템 자원을 파일로 표현한다.
리눅스를 기준으로 특수 파일은 4가지가 있는데, 간단하게 뭐가 있는지 알아보자.
1. 블록 디바이스 파일
디바이스 파일은 무엇을 표현하는 파일일까? 당연히 '장치'를 표현하는 파일이다.
디바이스 파일은 2개로 나뉜다. '블록 디바이스 파일'과 '캐릭터 디바이스 파일'.
블록 디바이스 파일은 '블록' 단위로 데이터를 입출력할 수 있다. 블록? 어디선가 들어본 단어이지 않은가? 맞다. 파일 시스템이 디스크에서 데이터를 읽고 쓸 때였다.
블록 디바이스는 안의 내용이 배열 형태로, 순차적으로 읽을 필요 없이 랜덤 액세싱이 가능하다. 그리고 읽을 때는 특정한 고정된 크기(블록)으로 읽고 쓴다.
하드 디스크, CD-ROM 같은 저장 장치들이 블록 디바이스 파일이다. (온갖 파일을 다 저장하는 디스크도 그 자체로 '파일'이라니 신기하지 않은가?)
2. 캐릭터 디바이스 파일
블록 디바이스는 배열 형태인 반면, 캐릭터 디바이스 파일은 큐(Queue)다. 데이터가 쌓인 순서대로 앞에서부터 데이터가 쓰고 읽혀진다. 키보드, 마우스, 모니터, 프린터 등이 여기 속한다.
블록보다 훨씬 작은 1바이트 단위로 입출력을 한다.
키보드 입출력이 대표적이다. 키보드에 'q', 'w', 'e'를 입력하면, 커널은 'q', 'w', 'e'를 차례대로 읽어서 각각 애플리케이션에 전달한다.
3. 네임드 파이프
파이프는 프로세스 간 데이터를 주고받는 방법이다. (파이프 또한 유닉스의 중요한 혁신 중 하나인데, 길어질 수 있으므로 패스한다.)
파이프는 실제로 디스크에 어떤 것도 저장하지 않는다. 하지만 여러 실행 중인 프로그램이 일반 파일처럼 읽고 쓸 수가 있다.
A 프로세스에서 파이프 파일에 "hello"라고 쓰면, B 프로세스에서 파이프 파일을 읽었을 때 "hello"가 나온다.
데이터가 FIFO(First In First Out) 큐 형식으로 전달되어서 'FIFO'라고 부르기도 한다.
4. 소켓
소켓도 다른 프로세스와 통신할 수 있는 방법 중 하나다.
소켓은 2가지 종류가 있다.
같은 기기 내의 프로세스가 통신할 때 사용하는 유닉스 도메인 소켓.
인터넷을 통해 다른 호스트와 통신할 때 쓰는 인터넷 소켓.
인터넷 소켓은 TCP나 UDP에 대한 세부 지식을 몰라도 다른 프로세스와 통신할 수 있게 해주는데, 네트워크와 인터넷을 구성하는 근본적인 메커니즘이기도 하다.
아무튼 이 소켓 또한 리눅스에서는 파일처럼 취급한다.
요약 정리
-
파일은 저장 장치에 정보를 저장하는 단위로, 운영체제는 파일 단위로 정보를 읽고 쓴다.
-
도서관에 책만 꽂아둔다고 끝이 아니라 체계가 필요하듯이, 파일을 읽고 쓰려면 파일 체계(File system)가 있어야 한다.
-
파일 시스템은 파일의 메타데이터를 관리한다. 유닉스 계열에서는 i-node로 메타데이터를 표현한다.
-
파일 시스템은 파일을 디렉토리 계층으로 구조화한다. 디렉토리는 파일의 링크를 저장한 특수한 파일이다. 파일 경로를 통해서 파일을 쉽게 찾을 수 있다.
-
파일 시스템은 물리 섹터와 논리 블록을 매칭한다. 덕분에 더 빠르게 데이터를 읽고 쓸 수 있다.
-
파일 시스템은 디스크 파편화를 자동으로 정리한다.
-
유닉스에서는 모든 것이 파일이다. 대부분의 시스템 자원을 파일 형태로 표현하기 때문이다. 파일을 다루는 인터페이스 하나로 다양한 자원을 다룰 수 있다.
-
리눅스에는 시스템 자원을 나타내는 특수 파일 4가지가 있다. 블록 디바이스 파일, 캐릭터 디바이스 파일, 네임드 파이프, 소켓이다.

7개의 댓글

머릿속에 파편화되있던 개념들을 한번에 정리할 수 있었네요, 파일시스템에대해 모르는게 정말 많았는데 이번 기회에 싹 정리할 수 있었던 것 같습니다

I want you know that my favorite game basketball stars is one that you can have a lot of fun with.


와우.. 넘 재밌게 정독했습니당 다음 이야기가 궁금해져요! 특히 파이프에 대해 패스한 부분 더더더 궁금합니다. 시간되시면 알려주세요! 좋은글 감사합니다 :)