컬렉션 프레임워크
컬렉션
: 데이터군, 데이터 군집, 자료
프레임워크
:표준화된 설계
참고)
프레임워크: 개발 방식의 틀을 정해 놓은것
예) 스프링 웹 MVC 프레임워크
라이브러리 : 편의 기능을 모은 것
컬렉션 프레임워크 핵심 인터페이스
1) List : 순차 자료 구조에 대한 설계
-순서가 있는 자료, 대표적인 예 - 배열
-특정 순서에 추가, 제거, 변경등의 매ㅔ개변수가 정의된 메서드가 많다
-
추가
-boolean add(E e) -boolean add(int index, E e) -boolean addAll(Collection<? extends E> ...) -boolean addAll(int index, Collection ...) -
조회
-E get(int index)
-int indexOf(Object e) : 특정 요소의 위치 번호(왼쪽 -> 오른쪽),없을때는 -1
-int lastIndexOf(Object e) : 특정 요소의 위치 번호(오른쪽 -> 왼쪽), 없을때는 -1
-boolean contains(Object e)
-boolean containsAll(Collection<?> ..)-
수정
-E set(int index, E e) : 특정 위치에 있는 요소를 변경 -
삭제
-E remove(int index) : 특정 순서 위치에 있는 요소 제거 (꺼낸다.) -boolean remove(Object e) -boolean removeAll(Collection..)
-
기타
-int size() : 요소의 갯수 -void clear : 집합 비우기 -retailAll(Collection ..) : 매개 변수에 있는 값만 유지하고 모두 제거(교집합) -
구현된 클래스
1. ArrayList
: 배열을 구현한 클래스
: 스택 구현시 활용 가능
: 쓰레드 안정성 확보 X
: 기본 생성 배열 갯수 10, 공간의 갯수가 부족하면 -> 배열이 2배 크기로 새로 생성
-> 데이터의 양을 충분히 예상 할 수 있는 경우는 충분한 크기를 만들어야 성능이 좋다.
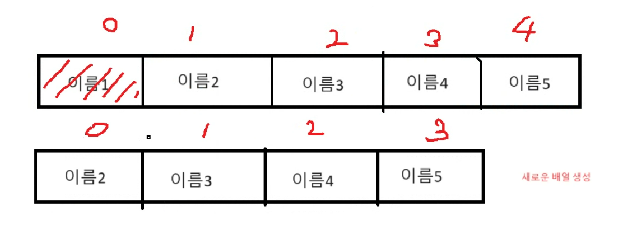
: 배열은 물리적으로 붙어 있는 나열 구조 -> 순차 조회는 매우 빠르다.
: 순서 위치가 바뀌는 수정, 삭제 -> 새로운 배열이 매번 생성 -> 성능 저하
: List 구현 클래스 중 가장 많이 사용
2. LinkedList
-다음 요소, 이전 요소 주소를 가지고 서로 연결 관계
-수정 삭제 등 순서 위치가 자주 변경되는 자료에서 유리
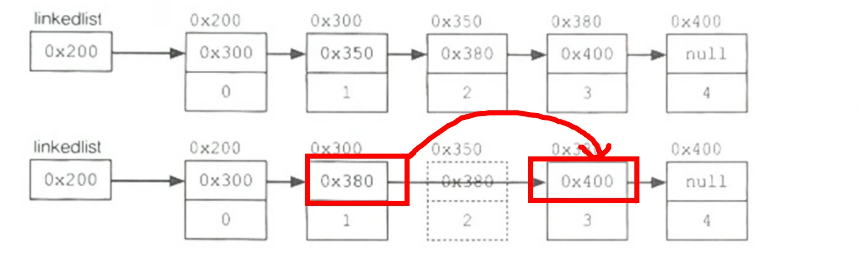
-주소만 변경하면 된다. (성능 저하 X)
-논리적 순서이므로 위치를 계산하는 일을 더 하므로 ArrayList보다는 조회에서 불리
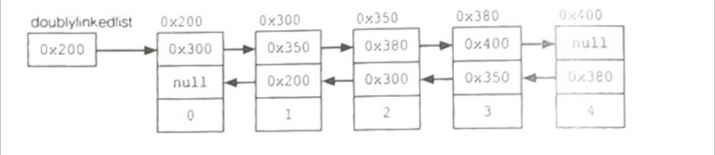
-자바는 DoublyLinkedList 형태로 구현되어 있음, 다음 요소, 이전 요소의 주소를 모두 가지고 있는 형태
-Queue 인터페이스의 구현체
boolean offer(E e) : 끝에 요소 추가
E poll() : 앞에서 요소 꺼내기
-Deque 인터페이스(스택 + 큐)
boolean offerFirst(E e) : 요소 앞에 추가
boolean offerLast(E e) : 요소 뒤에 추가
E pollFirst() : 가장 앞의 요소를 꺼내기
E pollLast() : 가장 뒤의 요소를 꺼내기
- Stack
E pop() : 끝 요소 꺼내기
E push(E e) : 끝에 추가 - Vector
: ArrayList 동일 / 배열을 구현한 클래스
: 쓰레드 안정성 확보
: 과거 기능의 호환성 유지를 위해 남겨둠
2) Set : 집합 자료 구조에 대한 설계
-중복이 없는 자료
: 중복 제거 기준 : 동등성 비교 - equals() and hashCode()
-순서 유지는 중요 X
-
추가
boolean add(E e) boolean addAll(Collection ..) -
삭제
boolean remove(Object e) boolean removeAll(Collection ..) -
기타
int size() : 요소의 갯수 void clear() : 전체 비우기 boolean contains(Object e) boolean containsAll(Collection<?> ..) boolean retainAll(Collection<?> ..) -
구현된 클래스
- HashSet
- TreeSet
HashSet + 정렬
컬렉션 프레임워크의 주요 작업
C(Create) : 데이터 추가
R(Read) : 데이터 조회
U(Update) : 데이터 변경
D(Delete) : 데이터 삭제
Iterator, ListIterator, Enumeration
Iterator : 반복자 패턴 인터페이스
-참고) Enumeration 동일한 반복자 패턴 인터페이스, Iterator보다 먼저 등장
Collection
Iterator<E> iterator()
Iterator
boolean hasNext() : 다음 요소가 있는지 체크
E next() : 다음 커서로 이동 요소를 조회
- ListIterator
:List에 특화되어 있는 Iterator / List 인터페이스에 정의
-순서에 대한 메서드가 정의
-순방향 조회 : hasNext(), next(), nextIndex()
-역방향 조회 : hasPrevious(), previous(), previousIndex()
-> 반복은 처음부터 끝까지 조회가 가장 많음
-> 향상된 for문
for (Book book: books) {
System.out.println(book);
}TreeSet
Comparable
-java.lang.Comparable
-기본 정렬 기준 : Natural Ordering
-int compareTo(T o)
-반환값이 양수 : 현재 객체 뒤로 배치, T o를 앞에 배치
-반환값이 0 : 배치 X
-반환값이 음수 : 현재 객체를 앞으로 배치, T o는 뒤에 배치현재 객체의 정수 - 비교 객체의 정수 : 오름차순
비교 객체의 정수 - 현재 객체의 정수 : 내림차순
@Override
public int compareTo(Book o) {
return o.isbn - isbn;
}Comparator
: 대안적인 정렬 기준 인터페이스
-java.util.Comparator
int compare(T o1, To2)
-o1 정수 -o2 정수 : 오름차순
-o2 정수 -o2 정수 : 내림차순-naturalOrder() : 기본 정렬 기준 사용한 정렬 (java.lang.Comparable, int compareTO(..))
-reversedOrder() : 기본 정렬 기준의 반대
3) Map : 사전 자료 구조에 대한 설계
-키와 값의 쌍
-키 : 값을 찾기 위한 값
-> 중복 허용 X (집합 자료)
-값 : 중복 허용 O
- 추가
V put(K key, V value) : key가 없을땐 추가, 있을땐 value값 수정
void putAll(Map...) : Map 객체로 전체 추가시
V putIfAbsent(K key, V value) : key가 없을때만 value값 추가
- 조회
V get(Object key) : key를 가지고 값을 조회, 없을땐 null
V getOrDefault(Object key, V defaultValue) : key를 가지고 조회, 없을땐 defaultValue로 대체
Set<Map.Entry<K,V>>entrySet() : 전체 키, 값의 쌍(Map.Entry) 조회
- 수정
V put(K key, V value)
V replace(K key, V value)
boolean replace(K key, V oldValue, V newValue) : 기존 값이 oldValue로 일치하는 경우만 newValue로 변경
- 삭제
V remove(Object key) : key를 가지고 제거
boolean remove(Object key, Object value) : key와 value가 일치하는 요소만 삭제
- 기타
int size() : 요소의 갯수
Set<K> keySet() : Map에 포함되어 있는 키 값만 추출
Collection<V> values() : Map에 포함되어 있는 값만 추출
boolean containsKey(Object key) : Map key가 포함되어 있는지 여부
boolean containsValue(Object value) : Map에 value가 포함되어 있는지 여부
- 구현된 클래스
-
HashMap
-
TreeMap
-> 키값의 정렬
-> 기본 정렬 기준 : java.lang.Comparable / int compareTo(...)
-> 대안 기준 : java.util.Comparator/ int compare(...)
Arrays
-java.util.Arrays
-배열의 편의 기능 모음
Collections
-java.util.Collections
-컬렉션의 편의 기능 모음
참고)
Unsigned : 양수
byte: -128~127
Unsigned Byte: 0 ~ 255
