NL 조인
- NL 조인은 인덱스를 이용한 조인
1. 기본 메커니즘
ex) 사원, 고객 테이블을 이용해 1996년 1월 1일 이후 입사한 사원이 관리하는 고객 데이터를 추출
select e.사원명, c.고객명, c.전화번호 from 사원 e, 고객 c
where e.입사일자 >= '19960101'
and c.관리사원번호 = e.사원번호 - 지금은 위와 같이 SQL문으로 쉽게 조인 결과를 추출할 수 있다
- 이전에는 사원테이블로부터 1996년 1월 1일 이후 입사한 사원을 찾아 건건이 고객 테이블에서 사원 번호가 일치하는 레코드를 찾았다
-> Nested Loop(NL) 조인이 사용하는 알고리즘
-> NL 조인은 중첩 루프문과 같은 수행 구조를 사용한다
begin
for outer in (select 사원번호, 사원명 from 사원 where 입사일자 >= '19960101')
loop --outer 루프
for inner in (select 고객명, 전화번호 from 고객
where 관리사원번호 = outer.사원번호)
loop --inner 루프
dbms_output.put_line(
outer.사원명 || ' : ' || inner.고객명 || ' : ' || inner.전화번호);
end loop;
end loop;
end;- 일반적으로 NL 조인은 Outer과 Inner 양쪽 테이블 모두 인덱스를 사용한다
- Outer 쪽 테이블(사원)은 사이즈가 크지 않으면 인덱스를 사용하지 않을 수 있다
-> Table Full Scan 을 하더라도 한 번 뿐이기 때문에 - Inner쪽 테이블(고객)은 인덱스를 사용해야 한다
-> 인덱스를 사용하지 않으면 Outer 루프에서 읽은 건수만큼 Table Full Scan을 반복하게 된다 - 아래 과정을 반복하게 된다
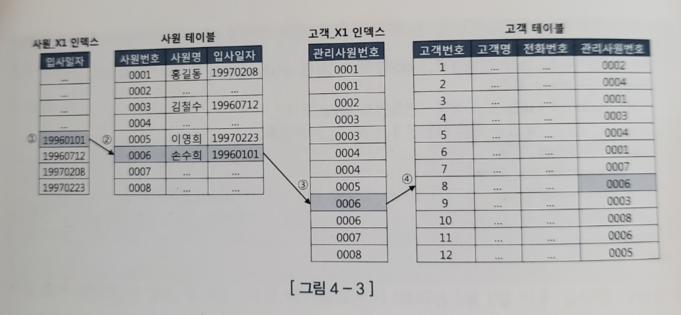
- 사원 X1 인덱스에서 입사일자 >= '19960101'인 첫번째 레코드 찾음
- 인덱스 ROWID로 사원 테이블 찾아감
- 사원 테이블에서 읽은 사원 번호로 고객_X1 인덱스를 탐색
- 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블 레코드를 찾아감
-> 해당 사원 번호보다 작을 때 까지 고객_X1 인덱스 스캔 진행 - 위 루프를 사원 X1 인덱스에서 입사일자 >= '19960101'인 데이터에 대해서 지속적으로 반복
2. NL 조인 실행계획 제어
- NL 조인을 제어할 때는 use_nl 힌트를 사용한다
- NL 방식으로 조인하라고 지시할 때 사용
select /*+ ordered use_nl(c) */ e.사원명, c.고객명, c.전화번호
from 사원 e, 고객 c
where e.입사일자 >= '19960101'
and c.관리사원번호 = e.사원번호 - ordered 힌트는 from 절에 기술한 순서대로 조인하라고 옵티마이저에 지시할 때 사용
- 사원테이블(driving/outer table) 기준으로 고객 테이블(inner 테이블)과 NL 방식으로 조인하라는 뜻
select /*+ ordered use_nl(B) use_nl(C) use_hash(D) */
from A, B, C, D
where ... -
세 개 이상은 위와 같이 조인
- A -> B -> C -> D 순서로 조인
- B, C 조인시는 NL 이용
- D와 조인할 때에는 hash 조인을 이용
select /*+ leading(C, A, D, B) use_nl(A) use_nl(D) use_hash(B) */
from A, B, C, D
where ... - order 대신 leading 절 이용
- FROM 절의 순서를 바꾸지 않고도 순서를 제어할 수 있다
select /*+ use_nl(A, B, C, D) */ *
from A, B, C, D
where ... - ordered/leading 힌트를 기술하지 않음
- 네 개 테이블을 NL 방식으로 조인하되 순서는 옵티마이저가 스스로 정하게 된다
3. NL 조인 수행 과정 분석
- ex) 조인 시 조건절 비교 순서는 어떻게 될지 확인해본다
select /*+ ordered use_nl(c) index(e) index(c) */
e.* c.*
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호 ------- 1)
and e.입사일자 >= '19960101' ------- 2)
and e.부서코드 = '2123' ------- 3)
and c.최종주문금액 >= 20000 -------- 4)- 인덱스는 아래와 같이 구성
사원_PK : 사원번호
사원_X1 : 입사일자
고객_PK : 고객번호
고객_X1 : 관리사원번호
고객_X2 : 최종주문금액-
두 테이블에 인덱스를 명시했으므로 둘 다 인덱스를 이용해서 액세스
-> 인덱스 명은 명시하지 않았기 때문에 어떤 인덱스를 사용할지는 옵티마이저가 결정
-> 실행 계획을 보면 사원_X1과 고객_X1을 사용하게 되는 것을 알 수 있다
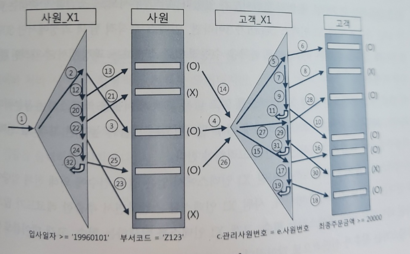
-
조건절 수행 순서는 다음과 같다(2 -> 3 -> 1 -> 4)
- 2) 입사일자 >= '19960101' 조건을 만족하는 레코드를 찾으려고 사원_X1 인덱스를 Range 스캔
- 3) 사원_X1 인덱스에서 읽은 ROWID로 사원 테이블을 액세스해서 부서코드 'Z123' 필터 조건을 만족하는지 확인
- 1) 사원 테이블에서 읽은 사원번호 값으로 조인 조건(c.관리사원번호 = e.사원번호)을 만족하는 고객 쪽 레코드를 찾으려고 고객_X1 인덱스를 Range 스캔한다
- 4) 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블을 액세스해서 최종주문금액 >= 20000 필터 조건을 만족하는지 확인한다
-
각 단계를 모두 완료하고 다음 단계로 넘어가는 것이 아니라 한 레코드씩 순차적으로 진행하게 된다
4. NL 조인 튜닝 포인트
- 사원_X1을 읽고나서 사원 테이블을 액세스 하는 부분
- 사원 테이블로 많은 랜덤 액세스가 발생했고, 부서코드 = 'Z123' 조건에 의해 필터링 되는 비율이 높을 경우
-> 사원_X1 인덱스에 부서코드 컬럼을 추가
- 사원 테이블로 많은 랜덤 액세스가 발생했고, 부서코드 = 'Z123' 조건에 의해 필터링 되는 비율이 높을 경우
- 고객_X1 인덱스를 탐색하는 부분
- 고객_X1 인덱스를 탐색하는 횟수 즉 조인 액세스 횟수가 많을수록 성능이 느려진다
- 조인 액세스 횟수는 Outer 테이블인 사원을 읽고 필터링한 결과 건수에 의해 결정된다
- 고객_X1 인덱스를 읽고 나서 고객 테이블을 액세스 하는 부분이다
- 최종주문금액 >= 20000 조건에 의해 필터링 되는 비율이 높다면 고객_X1 인덱스에 최종주문금액 칼럼을 추가하는 방안을 고려해야한다
- 맨 처음 액세스 하는 사원_X1 인덱스에서 얻은 결과 건수에 의해 전체 일량이 좌우된다
- 사원_X1에서 추출한 레코드 갯수 -> 사원테이블 랜덤 액세스 횟수 -> 고객_X1 인덱스 탐색 횟수 -> 고객 테이블 랜덤 액세스 횟수 등으로 영향을 미친다
올바른 조인 메소드 선택
- 온라인 트랜잭션 처리(OLTP) 시스템에서 튜닝할 때는 일차적으로 NL 조인부터 고려하는 것이 올바르다
- 성능이 느리다면 NL 조인 튜닝 포인트에 따라 각 단계의 수행 일량을 분석한다
-> 과도한 랜덤 액세스가 발생하는 지점 파악
-> 조인 순서를 변경해서 랜덤 액세스 발생량을 줄임
-> 더 효과적인 다른 인덱스가 있는지 등을 검토 -> 혹은 인덱스 추가/구성 변경 고려
-> NL 조인이 성능이 좋지 않다고 판단 -> 소트 머지 조인/해시 조인 선택
5. NL 조인 특징 요약
-
랜덤 액세스 위주의 조인 방식
- 레코드 하나를 읽으려고 블록을 통째로 읽는 랜덤 액세스 방식에서 비효율 존재
- 대량 데이터 조인 시 치명적인 한계 발생
-
조인을 한 레코드씩 순차적으로 진행
- 아무리 큰 테이블을 조인해도 부분범위 처리가 가능한 상황이면 매우 빠른 응답 속도
- 순차적이므로 먼저 액세스 되는 테이블 처리 범위에 의해 전체 일량이 결정되는 특징이 나타난다
-
인덱스 구성 전략이 특히 중요하다
- 조인 컬럼에 대한 인덱스가 유무/컬럼 구성 등에 따라 효율이 크게 달라짐
-
NL 조인은 소량 데이터를 주로 처리하거나 부분범위 처리가 가능한 온라인 트랜잭션 처리(OLTP) 시스템에 적합한 조인 방식이다
6. NL 조인 튜닝 실습

- 2780 건 중 필터링 결과는 3건에 그친다
- 테이블 액세스 후에 필터링 되는 비율이 높다면 인덱스에 테이블 필터 조건 컬럼을 추가하는 것이 좋다

- 사원_X1 인덱스에 부서코드 컬럼을 추가하니 불필요한 테이블 액세스 사라짐
- 테이블을 액세스하기 전 인덱스 스캔 단계에서의 일량은 확인하지 않아서 튜닝이 끝나지 않음

- 각 처리 단계별 논리적인 블록 요청 횟수(cr), 디스크에서 읽은 블록 수(pr), 디스크에서 쓴 블록 수(pw)를 확인
- 사원_X1 인덱스로부터 읽은 블록이 102개임을 확인했음 -> 한 블록 평균 레코드 갯수(500) X 102 -> 50000여개의 레코드를 읽음
- 사원_X1 인덱스 컬럼 순서를 조정해 부서코드 + 입사일자 를 구성해주면 됨
-> 하지만 다른 쿼리에 미치는 영향도 분석이 선행되어야 한다

- 사원 테이블을 읽는 과정은 비효율이 없다
- 하지만 조인하는 횟수에 대해서 2780번 시도를 했지만 조인 성공 결과 집합은 5개밖에 없다
-> 조인 순서 변경을 고려해볼 수 있다
-> 조인 순서를 바꿔도 큰 소득이 없다면 소트 머지 조인/해시 조인을 검토해야 한다
7. NL 조인 확장 메커니즘
- NL 조인 성능을 높이기 위해 확장된 메커니즘들이 도입됨
- 테이블 Prefetch : 인덱스를 이용해 테이블을 액세스하다 디스크 I/O가 필요하면 곧 읽게 될 블록까지 미리 읽어서 버퍼캐시에 적재하는 기능
- 배치 I/O : 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리하는 기능
-> 읽는 블록마다 건건히 I/O Call을 발생시키는 비효율을 줄이기 위해 고안되었다 - 배치 I/O의 경우 정렬 기준이 달라질 수 있으므로 바깥쪽 메인쿼리에 ORDER BY를 함부로 제거하면 안된다
4.2 소트 머지 조인
- 조인 컬럼에 인덱스가 없을 때
- 대량 데이터 조인이여서 인덱스가 효과적이지 않을 때
-> 옵티마이저는 NL 조인 대신 소트 머지 조인이나 해시 조인을 사용한다
-> 해시 조인을 사용할 수 없는 상황에서 대량 데이터를 조인하고자 할 때 여전히 유용하다
1. SGA vs PGA
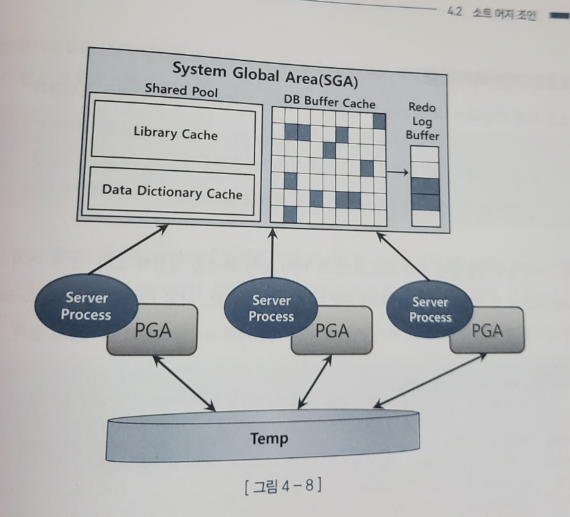
- SGA : 공유 메모리 영역
- SGA에 캐시된 데이터는 여러 프로세스가 공유할 수 있지만 동시에 엑세스 할 수는 없다
- 액세스를 직렬화하기 위한 Lock 메커니즘으로 래치(Latch)가 존재한다
- 데이터 블록과 인덱스 블록을 캐싱하는 DB 버퍼캐시는 SGA의 가장 핵심적인 구성요소이다
-> 여기서 블록을 읽으려면 버퍼 Lock도 얻어야 한다
- PGA
- 오라클 서버 프로세스는 SGA에 공유된 데이터를 읽고 쓰면서 자신만의 고유 메모리 영역을 갖는다
-> 각 오라클 서버 프로세스에 할당된 메모리 영역을 PGA라 한다 - 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용한다
- PGA 공간이 작아 데이터를 모두 저장할 수 없을 때는 Temp 테이블스페이스를 활용한다
- PGA는 독립적인 메모리 공간이다
-> 래치 메커니즘이 불필요하다
-> 같은 양의 데이터를 읽어도 SGA 버퍼캐시에서 읽을 때보다 빠르다
- 오라클 서버 프로세스는 SGA에 공유된 데이터를 읽고 쓰면서 자신만의 고유 메모리 영역을 갖는다
2. 기본 메커니즘
- 소트 머지 조인은 아래와 같이 진행된다
- 소트 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬
- 머지 단계 : 정렬한 양쪽 집합을 서로 머지(Merge) 한다
- use_merge 힌트로 유도한다
select /*+ orderd use_merge(c) */
e.*, c.* from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and c.부서코드 = 'z123'
and c.최종주문금액 >= 20000- 사원 테이블 기준으로 고객 테이블과 조인할 때 소트 머지 조인을 사용하라고 한다
- 위 sql 수행 과정은 아래와 같다
1) 아래 조건에 해당하는 사원 데이터를 읽어 조인컬럼인 사원번호 순으로 정렬
select 사원.* from 사원
where 입사일자 >= '19960101'
and 부서코드 = 'z123'
order by 사원번호 - 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장한다
- PGA에 담을 수 없을 정도로 크면 Temp 테이블 스페이스에 저장한다
2) 아래 조건에 해당하는 고객 데이터를 읽어 조인 컬럼인 관리사원번호 순으로 정렬한다
select c.*
from 고객 c
where 최종주문금액 >= 20000
order by 관리사원번호- 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장한다
- PGA에 담을 수 없을 정도로 크면 Temp 테이블 스페이스에 저장한다
3) PGA/Temp 테이블 스페이스에 저장한 사원 데이터를 스캔하면서 PGA/Temp 테이블 스페이스에 저장한 고객 데이터와 조인한다
begin
for outer in (select * from PGA에_정렬된_사원)
loop --outer 루프
for inner in (select * from PGA에_정렬된_고객 where 관리사원번호 = outer.사원번호)
loop -- inner 루프
dbms_output.put_line( ... );
end loop;
end loop;
end;- 1, 2 번이 소트 단계, 3번이 머지 단계이다
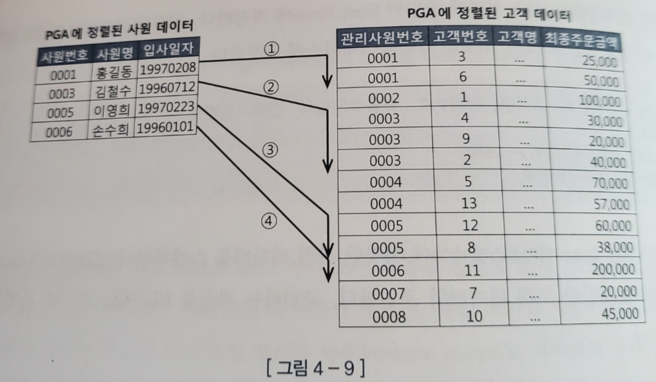
- 사원 데이터를 기준으로 고객 데이터를 매번 Full Scan 하지 않아도 된다
-> 고객 데이터가 정렬돼있기 때문에 조인 대상 레코드가 시작되는 지점을 쉽게 찾을 수 있다
-> 조인 실패 레코드를 만나는 순간 바로 멈출 수 있다 - Sort Area에 저장한 데이터 자체가 인덱스 역할을 함
-> 조인 컬럼에 인덱스가 없어도 사용할 수 있는 조인 방식
3. 소트 머지 조인이 빠른 이유
- NL 조인은 인덱스를 이용한 조인이다
-> 조인과정에서 액세스하는 모든 블록을 랜덤 액세스 방식으로 건건이 DB 버퍼캐시를 경유해서 읽는다
-> 인덱스/테이블에 대해서 모든 블록에 래치 획득 및 캐시버퍼 체인 스캔 과정을 거친다
-> 버퍼캐시에서 찾지 못한 블록은 건건이 디스크에서 읽어 들인다 - 소트 머지 조인은 양쪽 테이블로부터 조인 대상 집합을 일괄적으로 읽어 PGA에 저장한 후 조인한다
-> PGA는 독립적인 메모리이기 때문에 읽을 때 래치 획득 과정이 없다 - 소트 머지 조인도 양쪽 테이블로부터 조인 대상 집합을 읽을 때는 DB 버퍼캐시를 경유한다
- 이 때 인덱스를 이용하기도 한다
-> 버퍼 캐시 탐색 비용과 랜덤 액세스 부하가 역시 발생하게 된다
- 이 때 인덱스를 이용하기도 한다
4. 소트 머지 조인의 주 용도
- 해시조인이 소트 머지 조인보다 빠르지만, 조인 조건식이 등치 조건이 아니면 사용할 수 없다는 단점이 있다
- 따라서 소트 머지 조인은 아래 조건에서 사용된다
- 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인
- 조인 조건식이 아예 없는 조인(Cross 조인, 카테시안곱)
5. 소트 머지 조인 제어하기
select /*+ ordered use_merge(c) */ e.*, c.*
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호 - ordered, leading 힌트로 조인 순서를 알려줄 수 있다
- use_merge는 소트 머지 방식으로 조인하라고 지시하는 힌트이다
- 양쪽 테이블을 조인 컬럼 순으로 각각 정렬한 후 정렬된 사원 기준으로 정렬된 고객과 조인하라는 뜻
해시 조인
- 소트 머지 조인과 해시 조인은 조인 과정에서 인덱스를 이용 X
-> NL 조인보다 빠르고 일정한 성능을 보인다 - 소트 머지 조인은 양쪽 테이블을 정렬하는 부담이 있지만 해시 조인은 그런 부담이 없다
1. 기본 메커니즘
- 해시 조인은 두 단계로 진행된다
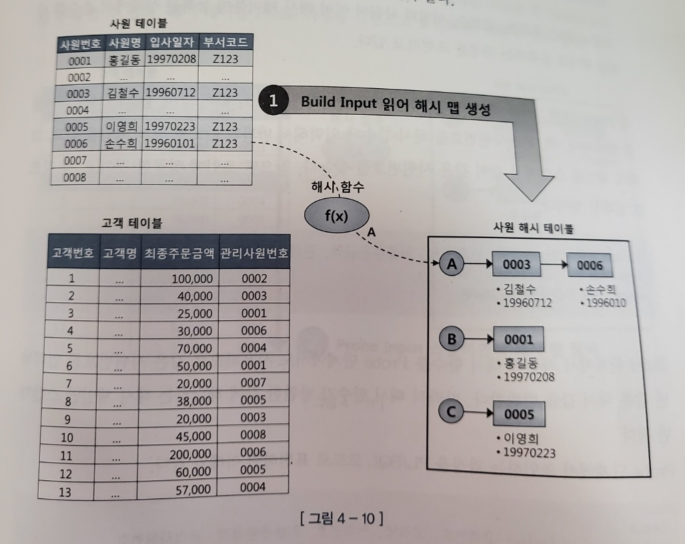
- Build 단계 : 작은 쪽 테이블(Build Input)을 읽어 해시 테이블(해시 맵)을 생성한다
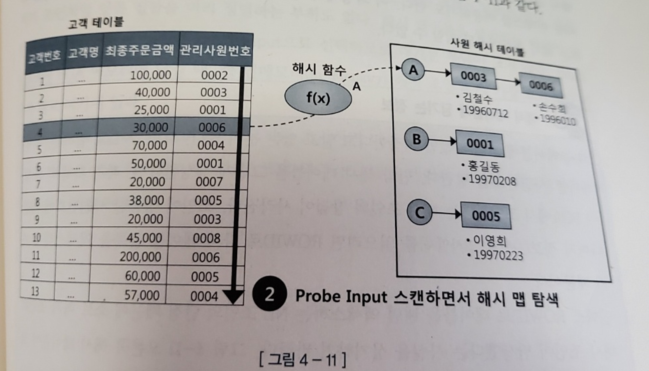
- Probe 단계 : 큰 쪽 테이블(Probe Input)을 읽어 해시 테이블을 탐색하면서 조인한다
- use_hash 힌트로 해시 조인을 유도할 수 있다
select /*+ ordered use_hash(c) */
e.*, c.* from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000- sql 수행 과정은 아래와 같다
1) build 단계
select 사원.* from 사원
where 입사일자 >= '19960101'
and 부서코드 = 'z123'
order by 사원번호 - 조건에 해당하는 사원 데이터를 읽어 해시 테이블을 생성한다
- 조인 컬럼인 사원 번호를 해시 테이블 키 값으로 사용한다
-> 사원 번호를 키 값으로 해서 반환된 값을오 해시 체인을 찾고 그 해시 체인에 데이터를 연결
-> 조인 키 값 뿐만 아니라 SQL에 사용할 컬럼을 모두 저장한다 - 해시 테이블은 PGA 영역에 할당된 Hash Area에 저장한다
- 해시 테이블이 너무 커 PGA에 담을 수 없으면 Temp 테이블스페이스에 저장한다
2) Probe 단계
select c.*
from 고객 c
where 최종주문금액 >= 20000
order by 관리사원번호- 조건에 해당하는 고객 데이터를 하나씩 읽어 앞서 생성한 해시 테이블을 탐색함
- 관리사원번호를 해시 함수에 입력해서 반환된 값으로 해시 차인을 찾음
- 그 해시 체인을 스캔해서 값이 같은 사원 번호를 찾는다
-> 값이 같으면 조인에 성공한 것이고 못 찾으면 실패한 것이다 - build 단계에서 사용한 해시 함수 == Probe 단계에서 사용하는 해시 함수
-> 같은 사원번호를 입력하면 같은 해시 값을 반환한다
-> 해시 함수가 반환한 값에 해당하는 해시 체인만 스캔하면 된다 - probe 단계에서 조인하는 과정은 아래와 같다
begin
for outer in (select * from 고객 where 최종주문금액 >= 20000)
loop -- outer 루프
for inner in (select * from PGA에_생성한_사원_해시맵 where 사원번호 = outer.관리사원번호)
loop -- inner 루프
dbms_output.put_line( ... );
end loop;
end loop;
end;2. 해시 조인이 빠른 이유
- 해시 테이블이 빠른 이유는 해시 테이블을 PGA 영역에 할당하기 때문이다
- 해시 조인 역시 래치 획득 과정 없이 PGA에서 빠르게 데이터를 탐색하고 조인한다
- 해시 조인도 각 테이블을 읽을 때는 DB 버퍼 캐시를 경유하기 때문에 탐색 비용과 랜덤 액세스 부하는 해시 조인도 피할 수 없다
- 해시 조인과 소트 머지 조인의 속도 차이는 조인 오퍼레이션 시작 전 사전 준비 작업에서 기인한다
- PGA 데이터 탐색 알고리즘의 차이는 미미하다
- 소트 머지 조인은 양쪽 집합을 모두 정렬해서 PGA에 담는 작업이다
-> PGA는 큰 공간이 아니기 때문에 Temp 테이블스페이스 즉 디스크 쓰는 작업을 수반하게 된다 - 해시 조인의 사전준비 작업은 양쪽 집합 중 한쪽을 읽어 해시 맵을 만드는 작업이다
-> 해시 조인은 둘 중 작은 집합을 해시 맵 Build Input으로 선택하게 된다
-> 두 집합 모두 Hash Area에 담을 수 없을 정도로 큰 경우가 아니면 Temp 테이블 스페이스 즉 디스크 작업이 일어나지 않게 된다 - 대량 데이터 조인 시에는 일반적으로 해시 조인이 가장 빠르게 된다
3. 대용량 Build Input 처리
- T1, T2 테이블이 모두 대용량 테이블이여서 인메모리 해시 조인이 불가능한 상황이다
-> 분할/정복 방식으로 해시 조인 처리를 할 수 있다 - 분할 정복 방식은 아래와 같이 진행된다
- 파티션 단계
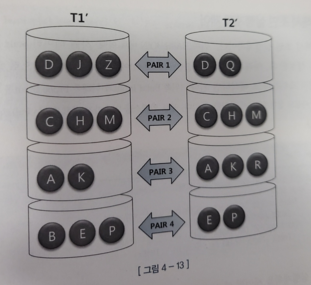
- 조인하는 양쪽 집합의 조인 컬럼에 해시 함수를 적용하고 반환된 해시 값에 따라 동적으로 파티셔닝한다
- 독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝을 생성하는 단계이다
-> 양쪽 집합을 얻어 디스트 Temp 공간에 저장해야 하므로 인메모리 해시 조인보다 성능이 떨어진다
- 조인 단계
- 파티션 단계를 완료하면 각 파티션 짝에 대해서 하나씩 조인을 수행한다
-> 이 때 Build Input과 Probe Input은 독립적으로 결정한다
-> 파티션하기 전 어느 쪽이 작은 테이블이었는지에 상관 없이 각 파티션 짝 별로 작은 쪽을 Build Input으로 선택하고 해시 테이블을 생성한다 - 해시 테이블 생성 후 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색한다
-> 모든 파티션 짝에 대한 처리를 마칠 때 까지 이 과정을 반복
- 파티션 단계
4. 해시 조인 실행계획 제어
- use_hash 힌트만 사용하면 옵티마이저가 build input을 선택한다
-> 일반적으로는 카디널리티가 작은 테이블을 선택한다 - 조인 테이블이 두개일 때 사용자가 build input을 선택하고 싶다면 leading or ordered 힌트를 사용하면 된다
-> 힌트 지시 순서에 따라 먼저 읽는 테이블을 build input으로 선택하게 된다 - swap_join_inputs 힌트로 build input을 직접 선택하는 방법도 있다
세 개 이상 테이블 해시 조인
- 세 테이블을 조인하는 경로는 단 한가지이다
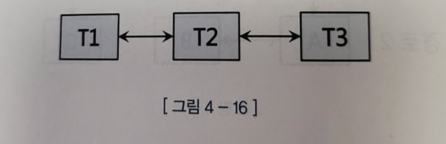
- 경로가 여러개라고 생각할 수 있지만 궁극적으로는 위의 형태를 띄게 된다
- 위 경우 세 테이블에 대한 해시 조인을 제어할 때 순서에 따라 leading 형태를 주면 된다
select /*+ leading(T1, T2, T3) use_hash(T2) use_hash(T3) */ *
from T1, T2, T3
where T1.key = T2.key
and T2.key = T3.key - 해시 조인에서 leading 힌트 첫 번째 파라미터로 지정한 테이블은 무조건 Build Input으로 선택된다
- 이 때 실행 계획 패턴은 다음과 같이 나오게 된다

- 패턴 1, 2 모두 T1을 Build Input으로 선택한 상황에서 T1과 T2 순서를 서로 바꾸고 싶다면 swap_join_inputs 힌트를 사용하면 된다
select /*+ leading(T1, T2, T3) swap_join_inputs(T2) */ ... - 패턴 1을 패턴 2로 바꾸고 싶은 상황
-> T3를 Build Input으로 선택하려는 것
-> swap_join_inputs 힌트를 사용하면 된다
select /*+ leading(T1, T2, T3) swap_join_inputs(T3) */ ... - 패턴 2를 패턴 1로 바꾸고 싶은 상황
-> T1과 T2를 조인한 결과 집합을 Build Input으로 선택하고 싶음
-> 이 때 조인 결과를 swap_join_inputs 힌트에 지정해야 한다
-> no_swap_join_inputs 힌트를 사용하면 된다
-> T1, T2 조인 결과 집합을 Build Input으로 선택해주는 것이 아니라 T3를 Probe Input으로 선택해주는 방식
select /*+ leading(T1, T2, T3) no_swap_join_inputs(T3) */ ...- 조인 테이블이 늘어날 경우에는 조인 연결고리를 따라 순방향 또는 역방향으로 leading 힌트에 기술
-> 이후 build input으로 선택하고 싶은 테이블을 swap_join_inputs 힌트에 지정해주면 된다
-> 혹은 no_swap_join_inputs 힌트로 반대쪽 probe input을 선택해주면 된다
5. 조인 메소드 선택 기준
- 소량 데이터 조인 시 -> NL 조인
- 대량 데이터 조인 시 -> 해시 조인
- 대량 데이터 조인인데 해시 조인으로 처리할 수 없을 때
- 즉 조인 조건식이 등치 조건이 아닐 때
-> 소트 머지 조인
- 즉 조인 조건식이 등치 조건이 아닐 때
- 여기서 소량/대량은 데이터의 많고 적음이 아니다
-> NL 조인 기준으로 최적화했는데도 랜덤 액세스가 많아 만족할만한 성능을 낼 수 없다면 대량 데이터 조인에 해당한다 - 수행 빈도가 높은 쿼리에 대해서는 아래 기준도 제시할 수 있다
- 최적회된 NL 조인과 해시 조인 성능이 같으면 NL 조인
- 해시 조인이 약간 더 빨라도 NL 조인
- NL 조인보다 해시 조인이 매우 빠른 경우 해시 조인
-> 이 경우 대량 데이터 조인일 가능성이 높다
- 왜 NL 조인을 사용하는 것을 가장 먼저 고려하는가
- 인덱스는 공유 및 재사용 하는 구조이다
- 반면 해시 테이블은 단 하나의 쿼리를 위해서 생성하고 조인이 끝나면 바로 소멸하는 도구이다
-> CPU와 메모리 사용량이 증가하고 래치 경합도 발생한다
- 해시 조인은 아래 조건에서 주로 사용한다
- 수행 빈도가 낮음
- 쿼리 수행이 오래 걸릴 때
- 대량 데이터를 조인할 때
-> 배치 프로그램, DW, OLAP성 쿼리의 특징이기도 하다
4. 서브 쿼리 조인
- 옵티마이저가 서브쿼리를 어떻게 처리하는지에 대해서 이해해야 하고 원하는 방식으로 실행 계획을 제어할 수 있어야 한다
1. 서브쿼리 변환이 필요한 이유
- 서브쿼리는 하나의 SQL문 안에 괄호로 묶은 별도의 쿼리 블록을 말한다
-> 쿼리에 내장된 또 다른 쿼리로 이를 세가지로 분류할 수 있다

- 인라인 뷰
- FROM 절에 사용된 서브쿼리
- 중첩된 서브쿼리
- 결과 집합을 한정하기 위해 WHERE 절에 사용한 서브쿼리
- 상관관계 있는 서브쿼리 : 서브 쿼리가 메인쿼리 컬럼을 참조하는 형태
- 스칼라 서브쿼리
- 한 레코드 당 하나의 값을 반환하는 서브쿼리
- 주로 SELECT-LIST에서 사용을 한다
- 옵티마이저는 쿼리 블록 단위로 최적화를 수행한다 -> 그것이 전체 쿼리 최적화라고 할 수는 없다
2. 서브쿼리와 조인
- 메인쿼리와 서브쿼리는 종속적이고 계층적인 관계가 존재한다
-> 단독으로 실행될 수 없으며 메인쿼리 건수만큼 값을 받아 반복적으로 필터링하는 방식으로 실행해야 한다
필터 오퍼레이션
- 서브 쿼리를 필터 방식으로 처리하기 위해서 no_unnest 힌트를 사용할 수 있다
-> 서브 쿼리를 풀어내지 말고 그대로 수행하라고 옵티마이저에 힌트를 주는 것
-> 동일한 결과를 보장하는 조인문으로 변환하고 나서 최적화 - 필터 오퍼레이션은 기본적으로 NL 조인과 처리 루틴이 같다
-> 부분 범위 처리도 가능하다 - postgesql에서는 offset 0을 이용하면 이를 유도할 수 있다
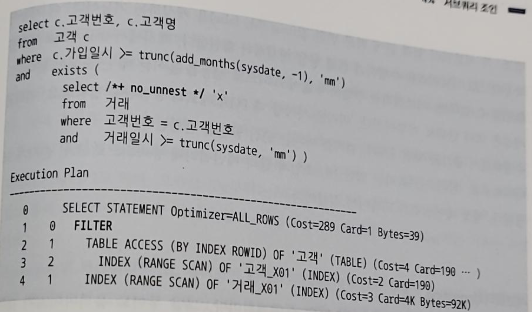
- NL조인과의 차이는 아래와 같다
- 필터는 메인 쿼리의 한 로우가 서브쿼리의 한 로우와 조인에 성공하는 순간 진행을 멈추고 메인 쿼리의 다음 로우를 계속 처리한다
-> 메인 쿼리의 결과 집합이 서브쿼리 M쪽 집합(거래) 수준으로 확장되는 현상(고객번호 중복)을 막을 수 있다 - 필터는 캐싱 기능을 갖는다
- 필터 처리한 결과값을 캐싱한다
-> 서브쿼리 입력 값에 따른 반환값(true/false)를 캐싱한다
-> 서브쿼리 수행 전 항상 캐시부터 확인하게 된다
-> 캐시에서 true/false 여부를 확인할 수 있다면 서브쿼리를 수행하지 않아도 되므로 성능을 높이는 것에 도움이 된다
- 캐싱은 쿼리 단위로 이루어진다
-> 쿼리를 시작할 때 PGA 메모리에 공간을 할당하고 쿼리를 수행하면서 공간을 채워나가며 쿼리를 마치는 순간 공간을 반환한다 - 조인 순서가 고정된다
- 필터 서브쿼리는 일반 NL조인과 달리 메인 쿼리에 종속되기 때문에
-> 항상 메인 쿼리가 드라이빙 집합이다
- 필터는 메인 쿼리의 한 로우가 서브쿼리의 한 로우와 조인에 성공하는 순간 진행을 멈추고 메인 쿼리의 다음 로우를 계속 처리한다
- NL 세미 조인과 비슷한 방식이다
서브쿼리 Unnesting
- 메인과 서브쿼리간의 계층구조를 풀어 서로 같은 레벨(flat한 구조)로 만들어준다는 의미(=서브쿼리 flatting)
- 서브쿼리를 그대로 두면 필터 방식을 사용해야만 한다
-> Unnesting 하면 일반 조인문처럼 다양한 최적화 방법을 사용할 수 있다
-> ex) 필터 방식은 항상 메인 쿼리가 드라이빙 집합이지만 Unnesting 된 서브쿼리는 메인 쿼리 집합보다 먼저 처리될 수 있다 - 옵티마이저는 많은 조인 테크닉을 가지기 때문에 조인 형태로 변환했을 때 필터 오퍼레이션보다 더 좋은 실행경로를 찾을 가능성이 높아진다
ROWNUM
- ROWNUM을 잘 사용하면 쿼리 성능을 높일수도 있고 잘못 사용하면 쿼리 성능을 떨어뜨릴 수 있다
ex) 병렬 쿼리나 서브쿼리에 ROWNUM을 사용하는 경우

- exists : 매칭되는 데이터 존재 여부를 확인하는 연산자이므로 조건절을 만족하는 레코드를 만나는 순간 멈추는 기능을 이미 갖고 있다
-> exsists 서브쿼리에 rownum 조건까지 사용하면 의미의 중복이다 - 서브쿼리를 unnesting 하면 필터 오퍼레이션보다 좋은 실행 경로를 찾을 가능성이 커진다
-> 서브쿼리에 rownum을 쓰면 unnesting을 방지하게 된다
-> no_unnest보다 rownum을 자주 쓰는 것을 볼 수 있는데 그만큼 강력하기 때문
서브쿼리 Pushing
- Unnesting 되지 않은 서브쿼리는 항상 필터 방식으로 처리된다
-> 대개 실행계획 상에서 맨 마지막 단계에 처리된다 - 서브쿼리 필터링을 먼저 처리함으로써 조인 단계로 넘어가는 로우 수를 크게 줄일 수 있다면 성능은 크게 향상된다
-> 서브 쿼리 필터링을 먼저 처리하게 하려고 push_subq 힌트를 사용할 수 있다

- pushing 서브쿼리는 서브쿼리 필터링을 가능한 앞 단계에서 처리하도록 강제하는 기능이다
-> push_subq/no_push_subq 힌트로 제어한다 - unnesting 되지 않은 서브쿼리에서만 작동한다
-> push_subq 힌트는 항상 no_unnest 힌트와 같이 기술하는 것이 올바른 방법이다 - 서브쿼리 필터링을 가능한 나중에 처리하도록 하기 위해서는 no_unnest와 no_push_subq를 같이 사용하면 된다
3. 뷰(View) 조인
- 최적화 단위는 쿼리 블록
-> 옵티마이저가 뷰 쿼리를 변환하지 않으면 뷰 쿼리 블록을 독립적으로 최적화한다

- 뷰 단위 최적화이다보니 당월 거래 전체를 읽어 고객번호 수준으로 Group By 하는 실행계획을 세운다
-> 고객 테이블과의 조인은 나중에 처리
-> 문제는 고객 테이블에서 전월 이후 가입한 고객을 필터링하는 조건이 인라인 뷰 바깥에 있음
-> 낭비!
- 뷰 단위 최적화이다보니 당월 거래 전체를 읽어 고객번호 수준으로 Group By 하는 실행계획을 세운다
- merge 힌트를 이용해 뷰를 메인 쿼리와 머징(Merging)한다
- 뷰 머징을 방지하고자 할때는 no_merge 힌트를 사용한다


- 실행 계획을 보면 아래와 같이 쿼리가 변환된 것을 알 수 있다
- 고객_X01 인덱스는 가입일시가 선두컬럼이다
-> 인덱스 Range Scan을 함 - 거래_X02 인덱스는 고객번호 + 거래일시 순으로 구성돼있다고 하자
- 실행 계획을 보면 고객 테이블을 먼저 읽는다
-> 인덱스를 이용해 전월 이후 가입한 고객만 읽는다
-> 거래 테이블과 조인할 때는 해당 고객들에 대한 당월 거래만 읽는다
-> 거래 테이블을 고객번호 + 거래일시 순으로 구성된 인덱스를 이용해 NL 방식으로 조인하기 때문에 - 부분 범위 처리가 불가하다는 단점이 있다
-> 조인에 성공한 전체 집합을 Group By 하고나서야 출력할 수 있다(데이터가 많으면 NL 조인이 좋은 선택이 아니다)
-> 그러한 상황에서는 해시 조인이 빠르다
조인조건 Pushdown
- 메인 쿼리를 실행하면서 조인 조건절 값을 건건이 뷰 안으로 넣는 기능
- View Pushed Predicate 오퍼레이션을 통해 기능 작동 여부를 알 수 있다

- 실행계획을 보면 아래와 같다
 -> 이는 문법적으로 허용되지 않지만 옵티마이저가 아래와 같이 처리한 것이라고 생각할 수 있다
-> 이는 문법적으로 허용되지 않지만 옵티마이저가 아래와 같이 처리한 것이라고 생각할 수 있다

- 전월 이후 가입한 고객을 대상으로 건건이 당월 거래 데이터만 읽어서 조인하고 Group By를 수행한다
-> 부분 범위 처리도 가능하다 - push_pred 힌트로 이를 작동할 수 있으며 no_merge 힌트를 함께 사용해줘야 한다
Lateral 인라인 뷰, Cross/Outer Apply 조인
- 인라인 뷰 안에서 메인 쿼리 테이블을 참조하면 에러가 발생한다
-> 인라인 뷰를 Lateral로 선언하면 인라인 뷰 안에서 메인쿼리 테이블의 컬럼을 참조할 수 있다
-> Cross Apply 조인도 같은 역할을 한다 - 하지만 조인 조건 pushdown 기능을 사용하는 것이 더 좋다
- 매우 복잡한 SQL 조건에서 조인조건 pushdown 기능이 잘 작동하지 않을 때 사용하면 된다
4. 스칼라 서브쿼리 조인
- 스칼라 서브 쿼리의 특징
- 함수와 비슷한 역할을 하지만 재귀적으로 실행되는 구조가 아니다
- 컨텍스트 스위칭 없이 메인쿼리와 서브쿼리를 한번에 실행한다
- outer 조인문처럼 하나의 문장으로 이해하면 된다
-> 스칼라 서브쿼리는 NL 조인 방식으로 실행된다
-> 처리 과정에서 캐싱이 일어난다는 점이 다르다
- 스칼라 서브쿼리 캐싱 효과
- 조인 횟수 최소화를 위해 입력 값과 출력 값을 내부 캐시에 저장해둔다
- 캐시에서 찾지 못할 때 조인을 수행
- 캐싱은 쿼리 단위로 이루어진다
select *,
(select 함수(e.deptno) from dual) dname
from emp e
where sal >= 20000- select-list에 사용한 함수 위에 스칼라 서브쿼리를 덧씌우면 호출 횟수를 최소화 할 수 있다
-> 함수에 내장된 select 쿼리도 그만큼 덜 수행 된다
- 스칼라 서브쿼리 캐싱 부작용
- 스칼라 서브쿼리 캐싱 효과는 입력 값의 종류가 소수여서 해시 충돌 가능성이 작을 때 효과가 있다
-> 오히려 크면 캐시 확인 비용 때문에 성능이 나빠지고 CPU/메모리 사용률만 올라가게 된다 - 메인 쿼리 집합이 작을 경우에도 성능에 도움을 주지 못한다
-> 캐시 사용률이 높아야 재사용성이 높아져 성능에 도움을 준다
- 두 개 이상의 값 반환
- 스칼라 서브쿼리는 부분 범위 처리는 가능하지만 하나 이상의 값을 전달할 수 없다

- 이 때 위와 같은 방법을 사용한다
-> 구하는 값들을 문자열로 결합하고 바깥쪽에서 다시 substr 함수로 분리하는 방식 - 오브젝트 TYPE을 사용하는 경우도 있으나 미리 선언해야 한다는 불편함이 있어 잘 사용 X
- 인라인 뷰를 사용하도 되나 부분 범위 처리 때문에 잘 사용하지 않는 때가 있었다
-> 조인 조건 Pushdown 기능이 작동하므로 인라인 뷰를 선택하는 것도 좋은 방안이 되었다
- 스칼라 서브쿼리 Unnesting
- 스칼라 서브쿼리도 NL 방식으로 조인하므로 랜덤 I/O 부담이 있다
- 대용량 데이터를 다루는 병렬 쿼리는 해시 조인으로 처리해야 효과적이므로 스칼라 서브쿼리를 사용하지 않는 것이 좋다
-> 스칼라 서브 쿼리를 일반 조인문으로 변환하고자 할 때가 있다
-> 스칼라 서브쿼리도 unnesting이 가능해졌다 - optimizer_unnest_scalar_sq 파라미터를 false로 설정해 문제를 해결할 수 있다
- 혹은 no_unnest 힌트를 이용해 부분적으로 문제를 해결할 수 있다

나는야 누워있는 개발머신