1장에서는 아래와 같은 내용들을 다룬다
왜 반응성이 필요한가
리액티브 시스템의 기본 원리
리액티브 시스템 설계에 완벽하게 일치하는 비즈니스 사례
리액티브 시스템에 좀 더 적합한 프로그래밍 기술
스프링 -> 리액티브 전환 이유 왜 리액티브인가
legacy : 1000명 사용자, 500개 스레드(톰캣) -> 초당 1000건의 부하 버틸 수 있음
-> 부하가 예상보다 더 많을 경우 버틸 수 없다 이러한 경우 아래 두가지를 고려해야한다
- 탄력성을 이용해 일차적인 목표 달성
- 평적/수직적 확장을 통한 탄력성 달성
- 하지만 분산 시스템에서 시스템 병목 지점/동기화 지점을 확장하는 것에 그치는 것이 일반적
- 암달의 법칙,보편적 확장성 모델(건터)로 설명 가능
- 장애 발생과 상관없이 응답성을 유지하는 능력을 갖춰야 한다
(응답성, 시스템 복원력 유지)
- 시스템의 기능 요소를 격리해 모든 내부 장애를 격리하고 독립성 확보
탄력성과 복원력은 밀접하게 결합되어 있고 이 두개를 이용해 시스템의 진정한 응답성 달성 가능
- 확장성을 통해 다수의 복제본을 가질 수 있으므로 장애 발생 시 해당 노드를 다른 복제본으로 전환해 시스템 나머지 부분에 영향을 최소화 할 수 있다
메시지 기반 통신
- 리퀘스트 핸들러를 통해 HTTP 요청을 발생시키고, 그 요청 속에서 RestTemplate을 이용해 외부 API를 요청하는 코드를 예시를 들어보자
- 처리시간 일부만 CPU가 할당되고 나머지 시간동안 스레드는 I/O에 의해 차단되고 다른 요청을 처리할 수 없다(
순수 자바 경우) - I/O 측면에서 리소스 활용도를 높이기 위해서는 비동기 논블로킹 모델을 사용해야한다
- 메시지 브로커를 이용하여 메시지 기반 통신 수행 가능
- 대기열을 모니터링해 시스템 부하/탄력성 관리 가능
- 메시지 통신은 명확한 흐름 제어를 제공하고 전체 설계를 단순화한다
리액티브 통신은 다음과 같다고 말할 수 있습니다
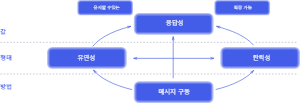
- 비즈니스의 핵심 가치는 응답성
- 응답성은 높은 탄력성, 복원력에서 나온다
- 높은 탄력성, 복원력을 가지게 하는 방법은 메시지 기반 통신을 이용하는 것
- 모든 구성 요소가 독립적이고 적절하게 격리되어있기 때문에 유지보수 및 확장이 용이하다
반응성에 대한 유스케이스
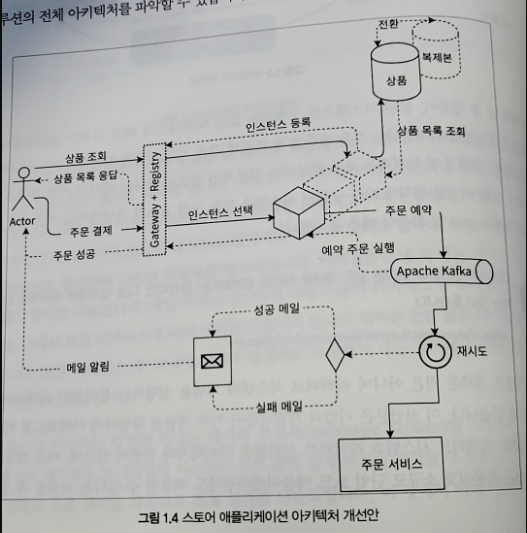
- API 게이트웨이 패턴 + 서비스 레지스트리 패턴 + 클라이언트 디스커버리 패턴
- 게이트웨이와 레지스트리가 동일 시스템에 구현되어있어 소규모에 적합
- 서비스 일부에 복제본을 구성해 높은 응답성을 얻을 수 있음
- 장애 복원력은 카프카를 이용한 메시지 기반 통신과 독립적인 결제 서비스에 의해 이루어진다
-> 외부 요청 실패 시 재시도 가능 - DB는 복제본을 만들어 복원력 유지
- 응답성 유지를 위해 주문 요청을 받자마자 우선 응답
- 결제 처리는 비동기적으로 처리해 사용자 결제 요청을 결제 서비스로 보냄
스트리밍 아키텍처
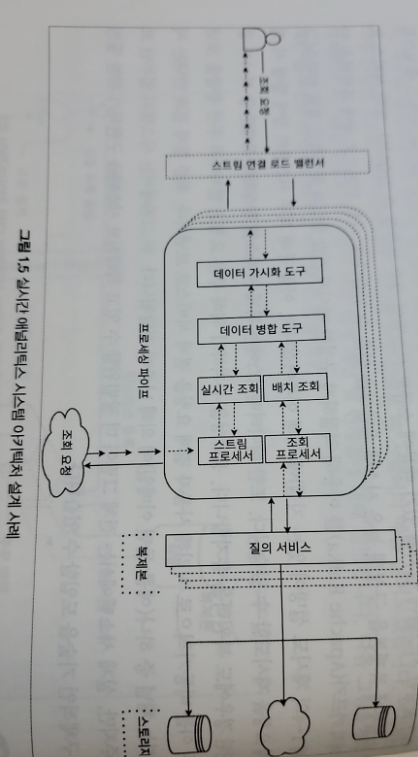
- 스트리밍 아키텍처는 데이터 처리 및 변환 흐름을 만드는 것
-> 짧은 지연 시간과 높은 처리량 - 가용성을 높이기 위해 리액티브 선언문에서 언급한 기본 원칙에 의존해야 한다
- 복원성 확보를 위해 배압 지원을 활성화 해야한다
-> 배압은 처리 단계 사이에서 작업 부하를 관리하는 정교한 프로세스를 뜻하며, 자신의 부하가 다른 프로세스로 파급되는 것을 방지한다 - 메시지 브로커를 통한 통신을 통해 작업 부하 관리 가능
- 또한 메시지를 내부 저장소에 보관하고 요청 시 전송 가능하게 한다
- 물론 실제 환경에서는 데이터 스트림이 일괄처리로 DB에 저장되거나 윈도우잉, 머신러닝 등으로 실시간에 가깝게 처리될 수 있지만 리액티브 선언문의 기본 원칙은 모든 도메인에 적용될 수 있다
리액티브 스프링
- 스프링 클라우드로 분산 시스템 구축을 단순화 할 수 있게 되었고 스프링 생태계는 리액티브 시스템을 구축하기 적합해질 수 있었다
- 설계는 작은 구성 요소로 이루어지기 때문에 구성 요소의 리액티브 특성이 중요하다
명령형 프로그래밍(imperative programming)
interface ShoppingCardService(){
Output calculate(Input value);
}
class OrderService{
private final ShoppingCardService service;
void process(){
Input input = ...;
Output output = service.calculate(input);
}
}
- 위 경우 ShoppingCardService를 동기적으로 호출하기 때문에 로직 수행 동안 스레드가 차단된다
- 추가 스레드를 할당하는 방법도 있지만 리액티브 시스템 관점에서는 그러한 동작은 허용되지 않는다
이러한 경우 컴포넌트 사이의 통신을 콜백 기법을 적용해 해결할 수 있다
콜백 함수
interface ShoppingCardService{
void calculate(Input value, Consumer<Output> c);
}
class OrderService{
private final ShoppingCardService service;
void process(){
Input input = ...;
service.calculate(input, output -> {
...
});
}
}- 설계 관점에서 calculate는 두개의 인자를 받고 void를 반환한다
- 호출하는 인스턴스가 즉시 대기 상태에서 해제될 수 있으며 그 결과가 나중에 Consumer<> 콜백으로 전달된다는 뜻이다
- OrderService는 작업 완료 후 반응할 콜백 함수를 전달한다
- OrderService는 ShoppingCardService로부터 분리되어있다
OrderService로 결과를 전달할 때 함수형 콜백 호출을 위해 동기 또는 비동기적 방식으로 ShoppingCardService#calculate를 구현할 수 있다
class SyncShoppingCardService implements ShoppingService{
public void calculate(Input value, Consumer<Output> c){
Output result = new Output();
c.accept(result);
}
}
class AsyncShoppingCardService implements ShoppingCardService{
public void calculate(Input value, Consumer<Output> c){
new Thread(() -> {
Output result = template.getForObject(...);
...
c.accept(result);
}).start();
}
}- SyncShoppingCardService의 경우 I/O 블로킹이 없다고 가정하며 결과를 바로 콜백함수에 전달해 반환할 수 있다
- AsyncShoppingCardService 에서는 I/O를 차단할 때 별도의 스레드로 래핑할 수 있고, 결과를 받으면 콜백 함수를 호출해 결과를 전달한다
- OrderService는 실행 프로세스와 분리돼 콜백으로 결과를 받을 수 있다
- 컴포넌트가 콜백 함수와 분리되어 scService.calculate 메서드를 호출한 후 ShoppingCardService 응답을 기다리지 않고 즉시 다른 작업을 할 수 있다
- 하지만 공유 데이터 변경, 콜백 지옥을 피하기 위해 멀티스레드를 잘 이해해야 한다
콜백 옵션 외에도 java.util.concurrent.Future 을 이용할 수 있다
Future
이 클래스는 실행 동작을 어느정도 숨기고 구성 요소를 분리할 수 있게 한다
interface ShoppingCardService{
Future<Output> calculate(Input value);
}
class OrderService{
private final ShoppingCardService scService;
void process(){
Input input = ...;
Future<Output> future = scService.calculate(input);
...
Output output = future.get();
}
}- Future은 클래스 래퍼를 사용해 사용 가능한 결과가 있는지를 확인한다
- ShoppingCardService를 호출하고 Future 인스턴스를 반환받으면 결과가 비동기적으로 처리되는 동안 다른 처리를 할 수 있다
- 결과에 대해서는 블로킹 방식으로 결과를 기다리거나 즉시 결과를 반환할 수 있다
- Future을 통해 콜백 지옥을 피하고 멀티스레드의 복잡성을 숨길 수 있다
- 하지만 필요한 결과를 얻기 위해서는 현재 스레드를 차단하고 확장성을 현저히 저하시키는 외부 실행과 동기화 해야한다
-> java8에서는 이를 개선해 CompletionStage 및 CompletionStage를 직접 구현한 CompletableFuture을 제공한다
CompletableFuture
interface ShoppingCardService{
Completionstage<Output> calculate(Input value);
}
class OrderService{
private final ShoppingCardService scService;
void process(){
Input input = ...;
scService.calculate(input)
.thenApply(out1 -> {...})
.thenCombine(out2 -> {...})
.thenAccept(out3 -> {...});
}
}- CompletionStage는 Future과 비슷한 클래스 래퍼이지만 반환된 결과를 기능적 선언 방식으로 처리할 수 있게 한다
- thenAccept, thenCombine과 같은 메서드를 이용해 결과에 대한 변형 연산을 정의할 수 있고 thenAccept 등을 통해 최종 컨슈머를 정의할 수 있다
- 하지만 스프링 4에서는 구 자바 버전과의 호환성을 목표로 하기 때문에 이 대신 ListenableFuture이라는 것을 구현해놓았다(CompletionFuture은 사용 불가)
ListenableFuture
AsyncRestTemplate template = new AsyncRestTemplate();
SuccessCallback onSuccess = r -> {...};
FailureCallback onFailure = e -> {...};
ListenableFuture<?> response = template.getForEntity(
url,
Collections.class
);
reseponse.addCallback(onSuccess, onFailure);- AsyncRestTemplate과 ListenableFuture을 이용해 작성함
- 비동기 호출을 위한 콜백 스타일(지저분)
- 스프링 프레임워크는 블로킹 네트워크 호출을 별도의 스레드로 래핑한다
- 스프링 MVC는 모든 구현체가 각각의 요청에 별도의 스레드를 할당하는 서블릿 API를 이용한다
- 서블릿 API(3.0, 3.1)은 논블로킹 I/O쓰기를 허용하나 스프링 MVC가 비동기 논블로킹 클라이언트를 제공하지 않는다
- 멀티스레딩을 사용할 때 스레드 간 메모리 엑세스, 동기화, 오류처리, CPU 등에 대해 생각해야한다
- CPU 시간이 스레드간에 공유된다는 사실은 컨텍스트 스위칭 비용에 대해서 생각해야한다는 뜻이므로 적은 수의 CPU에 동시에 많은 스레드 수를 활성화 시키는 응용프로그램은 비효율적이다
- 자바 스레드는 메모리 소비에 오버헤드가 있기 때문에(64 비트 기준 약 1024 KB) 제한된 크기의 스레드 풀을 사용하는 기존 모델과 대기열을 사용할 경우 응용프로그램이 응답하지 않을 수 있다
- 리액티브 선언문은 논블로킹 작업을 사용하도록 권장했으나 스프링 생태계에서는 누락돼있었고, 컨텍스트 스위칭 문제 해결을 위한 네티와 같은 리액티브 서버와는 통합을 잘 지원하지 않았다
기타 비동기 처리
- 비동기 처리는 일반적인 요청-응답 패턴에서만 국한되지 않고 스트림/배압 지원이 있는 정렬된 변환 흐름에서 처리해야할 때가 있다
- 이럴 때는 비동기 이벤트 처리 내부에서 변형 단계 연결을 포함하면 된다

나는야 누워있는 개발머신