
지금 공부하는 것은 코딩 테스트를 준비하기 위해서 공부하는 것이다!
공부 방식
유튜브, 인프런 강의, 책, 프로그래머스로 문제 풀면서 공부하는 방식을 선택했습니다.
자료구조
자료 구조는 효율적으로 데이터를 관리하고, 수정, 삭제, 탐색, 저장할 수 있는 데이터 집합을 말합니다.
데이터 구조로 :
- 대규모 데이터들을 관리 및 활용에 용이하게 한다.
- 데이터베이스에서 원하는 데이터를 찾을 수 있게 한다.
- 사용자가 원하는 또는 프로그램이 필요한 맞춤 알고리즘을 설계 할 수 있다.
- 사용자들의 여러 요청을 한번에 처리 할 수 있다.
- 데이터 처리 과정을 단순화하면서 처리 속도를 향상 할 수 있다.
복잡도
알고리즘의 성능을 객관적으로 평가하는 기준
복잡도는 시간 복잡도와 공간 복잡도로 나뉩니다.
시간 복잡도와 공간 복잡도는 거래 관계(Trade-off)가 성립할 수 있다. 메모리를 많이 사용하고, 반복되는 연산을 생략하거나 더 많은 정보를 관리하면서 계산의 복잡도를 줄일 수 있다. 실제로 메모리를 더 많이 사용해서 시간을 비약적으로 줄이는 방법으로 메모이제이션 기법이 존재한다.
시간 복잡도
일반적으로 수행시간은 1억 번의 연산을 1초의 시간으로 간주하여 예측합니다.
유형
- 빅-오메가
최선일 때의 연산 횟수를 나타내는 표기법- 빅-세타
보통일 때의 연산 횟수를 나타내는 표기법- 빅-오
최악일 때의 연산 횟수를 나타내는 표기법
예제
0~99 사이의 무작윗 값을 찾아 출력하는 코드입니다. 빅-오메가 표기법의 시간 복잡도는 1번, 빅-세타 표기법의 시간 복잡도는 N/2번, 빅-오 표기법의 시간 복잡도는 N번입니다.
public class Main01 {
public static void main(String[] args) {
// 1~100 사이 값 랜덤 선택
int findNumber = (int) (Math.random() * 100);
for (int i = 0; i < 100; i++) {
if(i == findNumber) {
System.out.println(i);
break;
}
}
}
}코딩 테스트에서는 어떤 시간 복잡도를 사용해야할까?
코딩테스트에서는 빅-오 표기법을 기준으로 수행시간을 계산하는 것이 좋습니다.
활용하기
// 시간 복잡도 O(n)
int n = 100000;
int cnt = 0;
for (int i = 0; i < n; i++) {
System.out.println("연산 횟수 : " + cnt++);
}
int n = 100000;
int cnt = 0;
// 3개의 for문을 돌면 30만번이다.
// 그러면 3N이다.
// 근데 앞의 상수인 3을 제외하기 때문에 O(n)이다.
for (int i = 0; i < n; i++) {
System.out.println("연산 횟수 : " + cnt++);
}
for (int i = 0; i < n; i++) {
System.out.println("연산 횟수 : " + cnt++);
}
for (int i = 0; i < n; i++) {
System.out.println("연산 횟수 : " + cnt++);
}
int n = 100000;
int cnt = 0;
// 시간 복잡도는 가장 많이 중첩된 반복문을 기준으로 도출하므로 이 코드에서는 이중 for문이
// 전체 코드의 시간 복잡도 기준이 됩니다.
// 그렇기 때문에 O(n²)이다.
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
System.out.println("연산 횟수 : " + cnt++);
}
}- 알맞은 알고리즘을 선택
- 비효율적인 로직 찾아서 바꾸기
자바 개발을 할 때에 프로그램의 동작 시간을 알아야 하는 경우가 있다. 특히 알고리즘 문제를 풀 때에 제한시간 내에 동작해야 하는 것을 테스트 해야할 경우에 유용하다.

시간복잡도를 구하는 방법은 아래와 같이 크게 3가지이다.
- O(Big-O)
- Ω(Omega)
- Θ(Theta)
가장 많이 쓰이는 시간복잡도는 빅오(Big-O) 표기법이므로 해당 표기법에 대한 설명을 다뤄볼 것이다.
int sum = 0;
for (int i=0; i<N; i++){
sum +=i;
}int sum = (N+1)*N/2;n의 변수가 있다는 가정하에 두개의 코드를 보면 몇번 연산 및 계산이 되는지 생각을 해보면 된다.
먼저 첫번째 코드는 N 까지 가기까지 위해
sum = 0; // 1번
i = 0; // 1번
i++; // N번
sum = sum+i; // N번
이렇게 되서 총 2N +2 번의 연산이 필요하다.
아래 코드는 sum을 구하기 위해서는
N+1 // 1번
*N // 1번
/2 // 1번
이렇게 해서 총 3번의 연산이 들어간다.
bigO 표기법의 특성은 상수랑 차항 계수만 표시되기에 첫번째 함수는 O(n) 이고 두번째는 O(1) 이다.
즉 아래의 코드가 시간 복잡도 상에서는 더 유리하다는 뜻이다.
이걸 이중 반복문으로 보고자 한다.
int sum = 0;
for(int i = 0; i<N; i++){
for(int j = 0; j<i; j++){
sum += j;
}}int sum = 0;
for(int i =N; i>0; i/=2){
for(int j = 0; j<i; j++){
sum += j;
}}첫번째 코드를 보면 바깥 반복문에서 i는 0부터 N-1까지 변하며, 안쪽 반복문은 해당하는 i만큼 반복하므로, sum = sum+j 가 돌아가는 코드는 첫번째 반복분에서는 0번 두번째 i 일땐 1번 ,.... 즉, 0+1+2+…+(N-1) = N*(N-1)/2 번 반복합니다.
두번째 코드는 바깥쪽 반복문이 log N번 반복하고, 안쪽 반복문은 i의 값에 따라 반복 횟수가 다르다. i는 N부터 1까지 변하며, 안쪽 반복문은 해당하는 i만큼 반복하므로, N + N/2 + N/4 + … + 1 = 2N 번 반복하고, Big-O로 표기하면 2N = O(N)이 된다.
그럼 역시 bigO 표기법에 따라 첫번째는 O(n²) 이고 두번째는 O(N) 이 되어 두번째 코드가 더욱 효율적인 코드가 된다.

존재이유
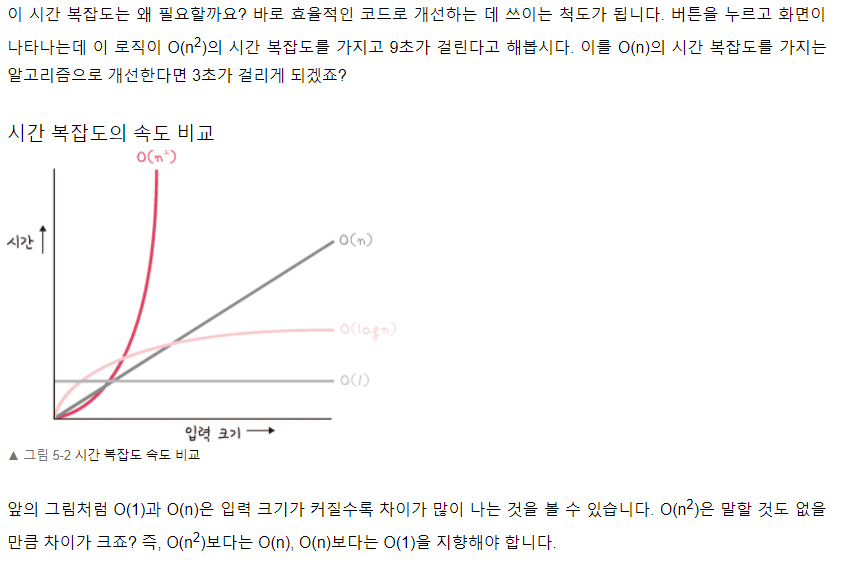
자바를 이용해서 알고리즘 문제를 풀거나 큰 사이즈의 데이터를 다룰 때, 컬렉션들의 정확한 시간복잡도(Big-O)를 알고 사용하는 것이 중요하다. 자칫 불필요하게 느린 컬렉션이나 메소드를 사용할 경우 예상치 못한 성능저하를 만날 수 있기 때문입니다.
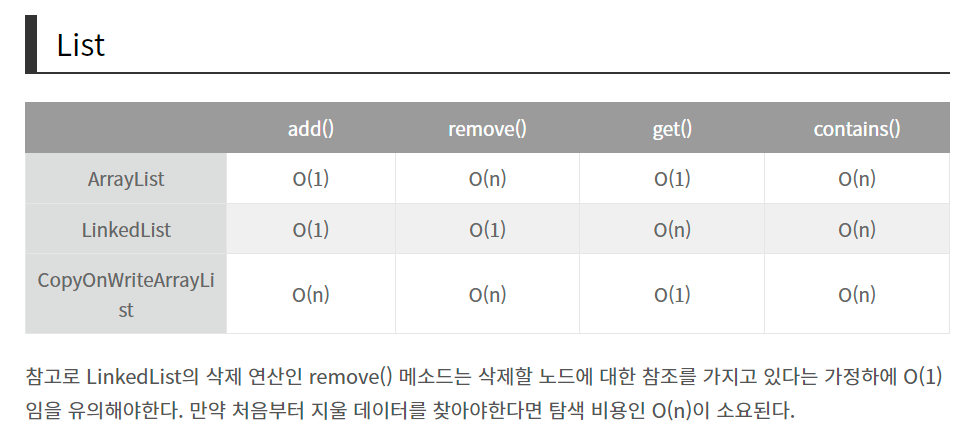
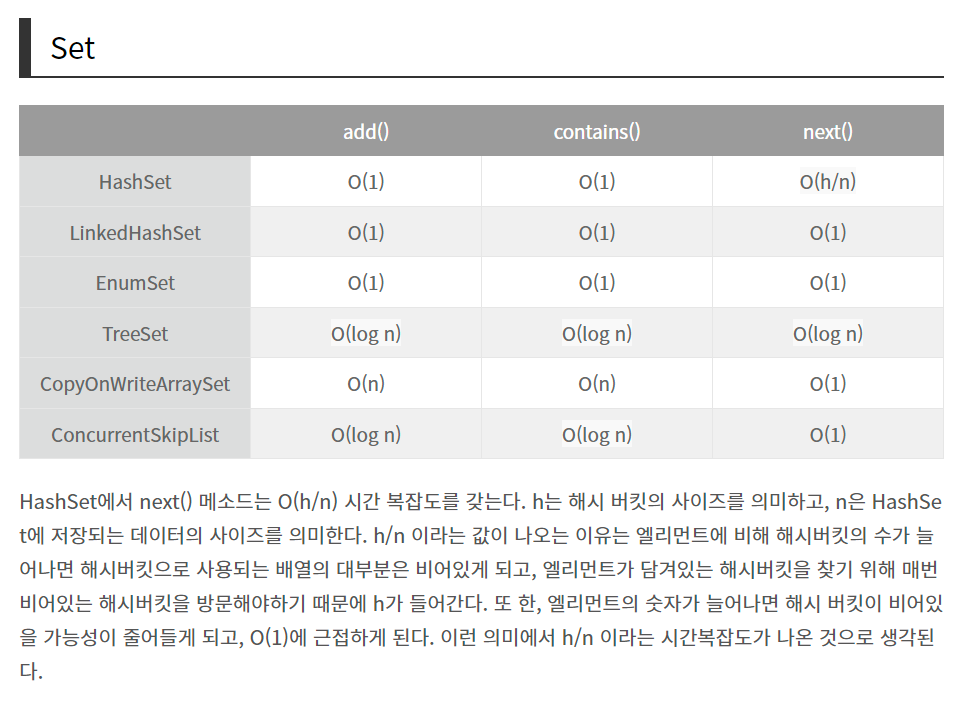
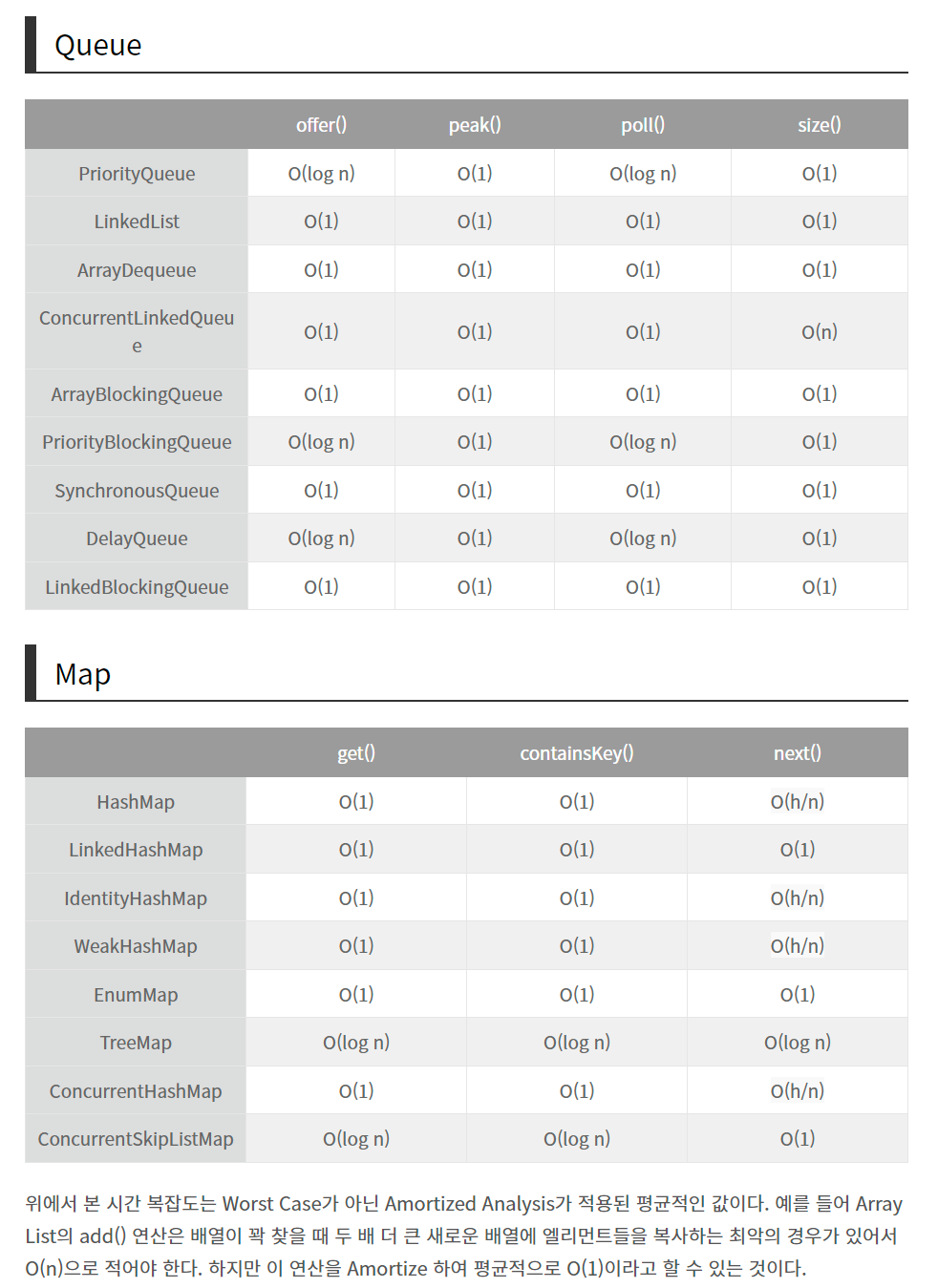
시간 복잡도 구하기
시간 복잡도는 일반적으로 빅오 표기법으로 나타낸다.
최고차항을 제외한 모든 항과 최고차항의 계수를 제외시켜 나타낸다.
최고차항의 성장률만 봐도 알 수 있기 때문
T(n) = n^2 + 2n + 1 -> n^2
시간 복잡도를 구할 때, 비교연산과 교환연산을 중심으로 구하면 쉽게 다가온다.

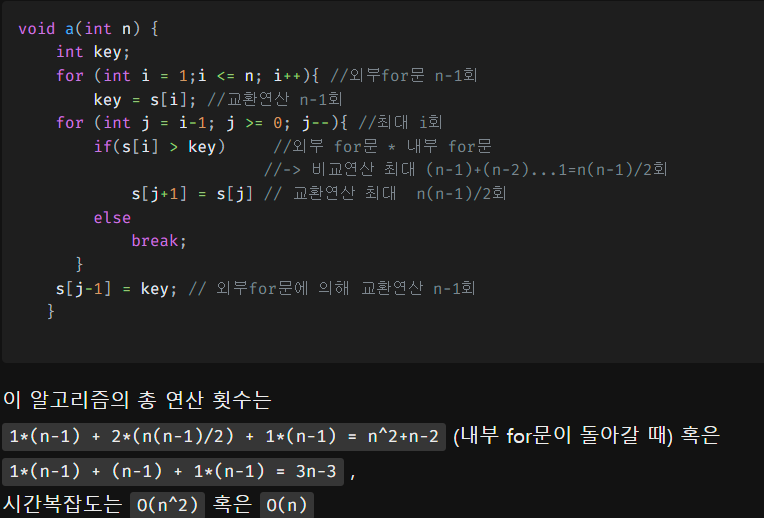

(시간 복잡도 표, 위쪽에 있을수록 빠르다)
시간 복잡도 기반으로 코딩 테스트 문제의 시간 제한을 유추할수 있다. 숙련자들은 문제를 해석하기 전에 조건을 먼저 보기도 한다. 문제의 조건부터 확인하면 문제를 풀기 위해 얼마나 효율적인 알고리즘을 작성해야 하는지 눈치 챌 수 있다.
예를 들어 데이터의 개수 N이 1,000만 개를 넘어가고 시간 제한이 1초라면, 대략 최악의 경우 O(N)의 시간 복잡도로 동작하는 알고리즘을 작성해야 할 것을 예상할 수 있다. 데이터의 크기나 탐색 범위가 100억을 넘어가면, 이진 탐색과 같이 O(logN)의 시간 복잡도를 갖는 알고리즘을 작성해야한다.
실제 코딩 테스트 문제의 시간 제한은 1~5초 가량이며, 보통 연산 횟수가 10억을 넘어가도록 작성하면 오답 판정 받을 수 있음을 주의하자.
시간 제한이 1초인 문제의 경우
- N의 범위가 500: 시간 복잡도가 O(N³) 알고리즘을 설계하면 문제를 풀 수 있다.
- N의 범위가 2,000: 시간 복잡도가 O(N²) 알고리즘을 설계하면 문제를 풀 수 있다.
- N의 범위가 100,000: 시간 복잡도가 O(NlogN) 알고리즘을 설계하면 문제를 풀 수 있다.
- N의 범위가 10,000,000: 시간 복잡도가 O(N) 알고리즘을 설계하면 문제를 풀 수 있다.
공간 복잡도
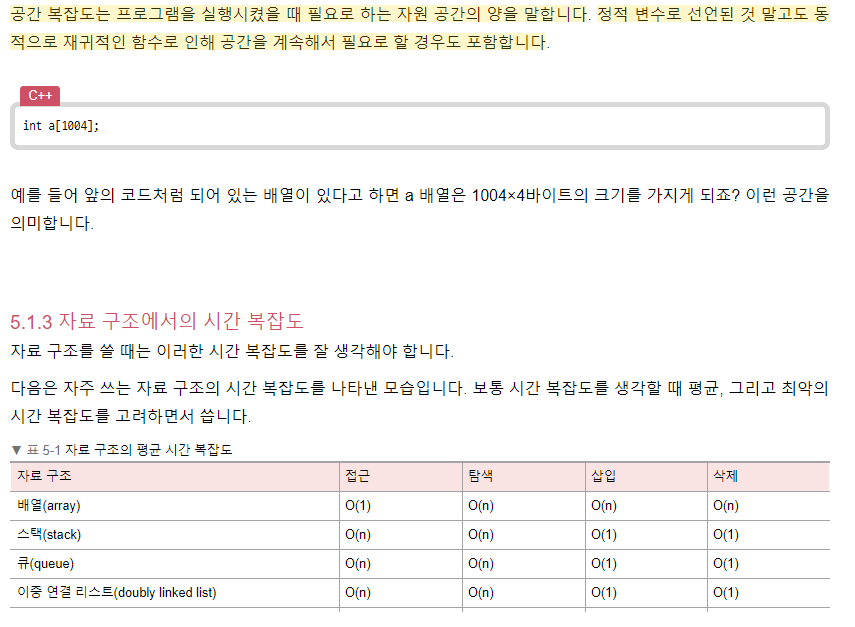
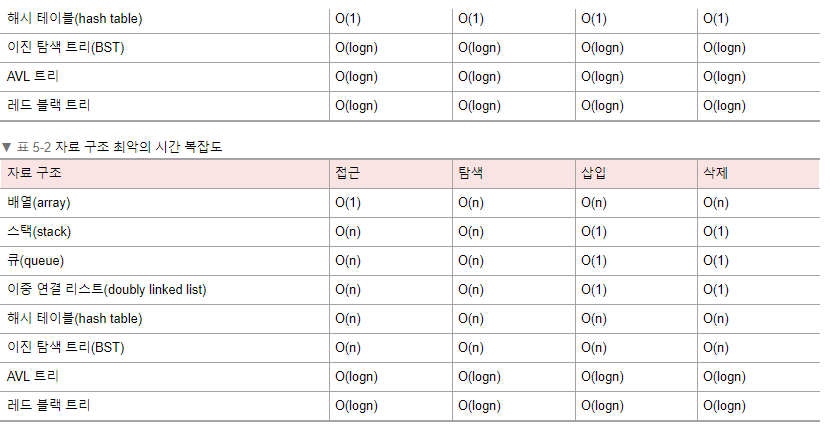
자바에서는 코드를 통해 수행 시간과 메모리 사용량을 측정할 수 있다. 다음은 자바의 기본 정렬 코드의 시간과 메모리를 측정하는 코드다. 자바의 기본 정렬 알고리즘은 ‘듀얼 피벗 퀵 알고리즘’을 사용하며, 평균 시간 복잡도 O(NlogN), 최악의 경우 시간 복잡도는 O(N2)이다.
선형 자료 구조
선형 자료구조란 요소가 일렬로 나열되어 있는 자료 구조를 말합니다.
★연결 리스트(LinkedList)
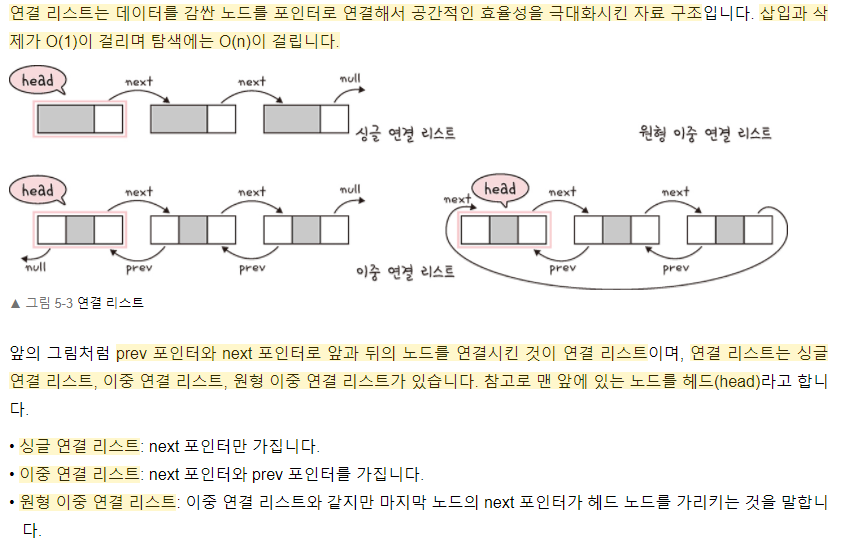
연결 리스트 구조는 앞에서 말한 세 가지 구조와 달리 메모리에 있는 데이터의 물리적 배치를 사용하지 않는 데이터 구조다. Index나 위치보다 참조 시스템을 사용한다. 각 요소는 노드라는 것에 저장되는데, 다음 노드 연결에 대한 포인터 또는 주소가 포함된 또 다른 노드에 저장된다. 모든 노드가 연결된 때까지 반복이 돼서 노드의 연결로 이루어진 자료 구조다. 그리고 이 구조는 데이터 추가 및 삭제 시 재구성이 필요 없어서 효율적이다. 선형으로 자료를 관리, 자료가 추가될 때마다 메모리를 할당 받고, 자료는 링크로 연결됨. 자료의 물리적 위치와 논리적 위치가 다를 수 있음
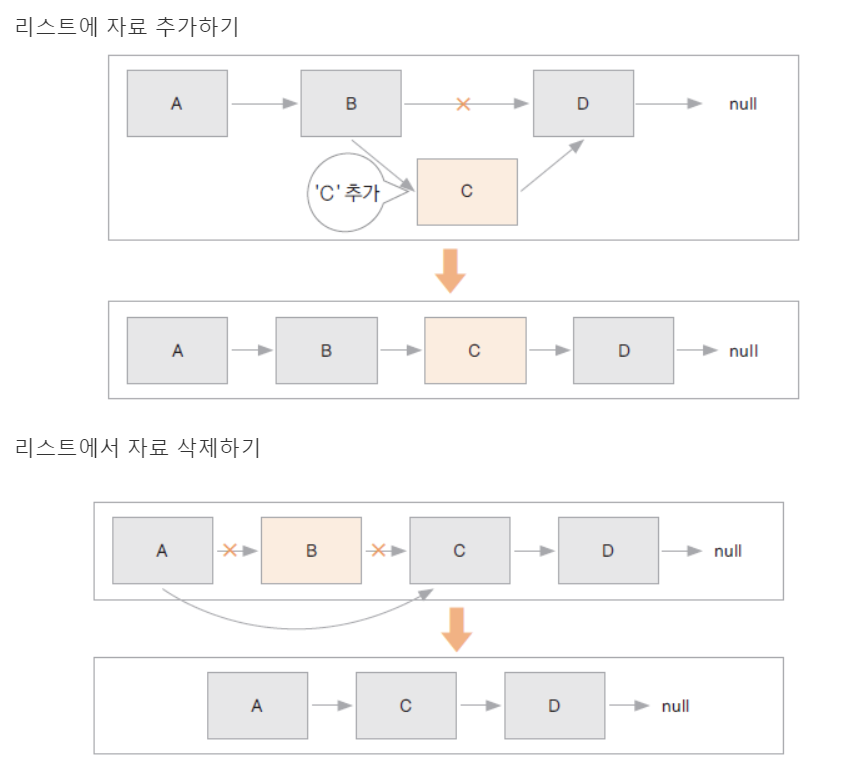
연결 리스트에는 단일 연결 리스트(Singly-Linked List), 이중 연결 리스트(Doubly-Linked List)등의 종류가 있다
시간복잡도

장점
- 새로운 요소들의 추가 및 삭제가 용이하고 효율적이다
- 배열처럼 메모리에 연속적으로 위치하지 않는다
- 배열처럼 구조의 재구성이 필요없다
- 동적인 메모리 크기
- 메모리를 더 효율적으로 쓸 수 있기 때문에 대용량 데이터 처리 적합
단점
- 배열보다 메모리를 더 사용한다
- 처음부터 끝까지 순회하기 때문에 원하는 값을 비효율적으로 검색/가져온다
- 노드를 반대 방향으로 검색할 때 비효율적이다 (이중 연결 리스트의 경우)
★배열(Array)

배열은 가장 기본적인 데이터 구조다. 배열은 생성시 설정된 셀의 수가 고정되고, 각 셀에는 인덱스 번호가 부여된다.배열을 활용 시 부여된 인덱스를 통해 해당 셀 안에 있는 데이터에 접근 할 수 있다.
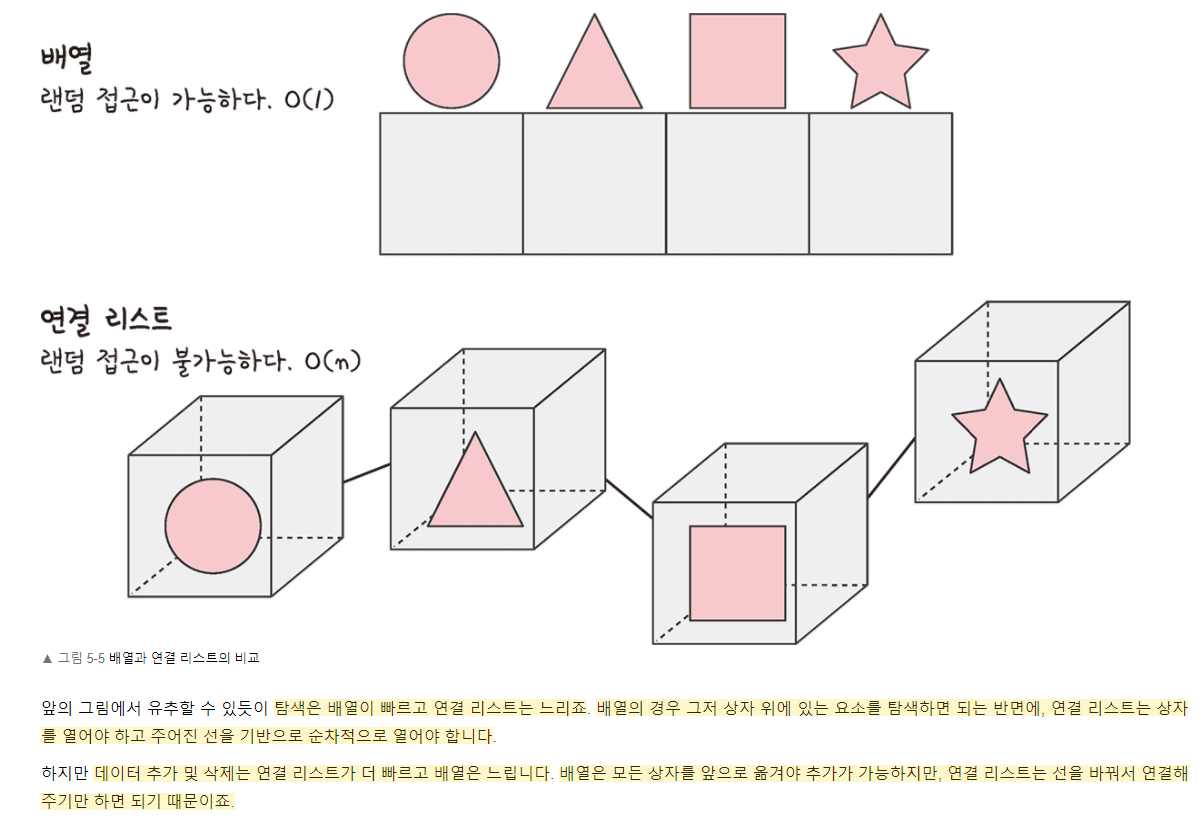
시간복잡도

장점
- 바로 만들어서 활용하기가 쉽다
- 더 복잡한 자료 구조의 기초가 될 수 있다
- 원하는 데이터를 효율적으로 탐색/가져올 수 있다
- 정렬에 용이하다
단점
- 데이터를 저장 할 수 있는 메모리 크기가 고정되어 있다.
- 데이터 추가 / 삭제 방법이 비효율적이다
- 구조 재구성 시 정렬하는 방식이 비효율적이다
예제
package Array;
public class Code01 {
public static void main(String[] args) {
String[] fruits = {"apple", "banana", "melon"};
String[] copyFruits = fruits.clone(); // fruits 배열을 복사
for (int i = 0; i < fruits.length; i++) {
System.out.println("fruits : " + fruits[i]);
System.out.println("copyFruits : " + copyFruits[i]);
}
}
}package Array;
public class Code02 {
public static void main(String[] args) {
String[] fruits = {"apple", "melon", "banana"};
String[] newFruits = new String[5];
// arraycopy(복사할 배열, 시작 위치, 새 배열, 새 배열 시작 위치, 복수 갯수) 4개의 인수를 받는다.
// 지정된 위치를 받기 떼문에 기존 존재하는 배열에 새로 복제하는 경우에 유용하게 사용된다.
System.arraycopy(fruits,0,newFruits,0, 3);
for (int i = 0; i < fruits.length; i++) {
System.out.println("copyFruits : " + newFruits[i]);
}
}
}💡Array와 ArrayList의 차이점에 대해 설명해주세요.
Array는 크기가 고정적이고, ArrayList는 크기가 가변적입니다.
Array는 초기화 시 메모리에 할당되어 ArrayList보다 속도가 빠르고, ArrayList는 데이터 추가 및 삭제 시 메모리를 재할당하기 때문에 속도가 Array보다 느립니다.
💡Array(List)의 가장 큰 특징과 그로 인해 발생하는 장점과 단점에 대해 설명해주세요.
Array의 가장 큰 특징은 순차적으로 데이터를 저장한다는 점입니다. 데이터에 순서가 있기 때문에 0부터 시작하는 index가 존재하며, index를 사용해 특정 요소를 찾고 조작이 가능하다는 것이 Array의 장점입니다.
순차적으로 존재하는 데이터의 중간에 요소가 삽입되거나 삭제되는 경우 그 뒤의 모든 요소들을 한 칸씩 뒤로 밀거나 당겨줘야 하는 단점도 있습니다. 이러한 이유로 Array는 정보가 자주 삭제되거나 추가되는 데이터를 담기에는 적절치 않습니다.
💡Array와 LinkedList의 차이
Array는 논리적 저장 순서와 물리적 저장 순서가 일치합니다. 즉, 데이터들이 실제로 인접해있으므로 주소값 계산이 쉬워 random access 가 가능하다는 장점이 있습니다. 그러나 데이터의 삽입 또는 삭제가 일어나는 경우 배열의 연속성을 유지하기 위한 shift 비용이 발생한다는 단점이 있습니다.
Linked List는 이러한 단점을 해결할 수 있는 자료구조로, 각 원소들이 다음 원소에 대한 주소값을 갖고 있다는 특징이 있습니다. 따라서 데이터의 삽입, 삭제시 인접한 원소들에 대해서만 변경하면 되므로 성능상의 이점이 있습니다. 그러나, 데이터 조회시 random access가 불가하여 배열에 비해 느리다는 단점도 있습니다.
💡ArrayList와 LinkedList의 차이
LinkedList와 ArrayList는 모두 Java에서 제공하는 List 인터페이스를 구현한 Collection 구현체입니다.
-
ArrayList
내부적으로 데이터를 배열로 관리하고 데이터 추가/삭제 시 임시 배열을 생성해 데이터를 복사합니다. 데이터별 인덱스가 있어 검색에는 유리
임시 배열을 사용하기 때문에 데이터 추가/삭제의 경우에는 불리 -
LinkedList
내부적으로노드 단위로 데이터를 관리합니다. 자신의 앞 뒤 노드만 인지하는 상태입니다. 인덱스가 따로 없기 때문에 검색 시 전 노드를 순회해야하여 검색시 불리하고 데이터 추가/삭제 시 불필요한 데이터 복사가 없어 유리💡Array와 LinkedList의 장/단점에 대해 설명해주세요.
Array는 인덱스(index)로 해당 원소(element)에 접근할 수 있어 찾고자 하는 원소의 인덱스 값을 알고 있으면 O(1)에 해당 원소로 접근할 수 있습니다. 즉, 속도가 빠르다는 장점이 있습니다. 하지만 삽입 또는 삭제의 과정에서 각 원소들을 shift 해줘야 하는 비용이 생겨 이 경우 시간 복잡도는 O(n)이 된다는 단점이 있습니다.
이 문제점을 해결하기 위한 자료구조가 linkedlist입니다. 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있기 때문에 이 부분만 다른 값으로 바꿔주면 삽입과 삭제를 O(1)로 해결할 수 있습니다. 하지만LinkedList는 원하는 위치에 한 번에 접근할 수 없다는 단점이 있습니다. 원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 합니다.
- Array는 검색이 빠르지만, 삽입, 삭제가 느리다.
- LinkedList는 삽입, 삭제가 빠르지만, 검색이 느리다.
💡Array를 적용시키면 좋을 데이터의 예를 구체적으로 들어주세요. 구체적 예시와 함께 Array를 적용하면 좋은 이유, 그리고 Array를 사용하지 않으면 어떻게 되는지 함께 설명해주세요.
Array를 적용시키면 좋은 예로 주식 차트가 있습니다.
주식 차트에 대한 데이터는 요소가 중간에 새롭게 추가되거나 삭제되는 정보가 아니며, 날짜별로 주식 가격이 차례대로 저장되어야 하는 데이터입니다.
즉, 순서가 굉장히 중요한 데이터이므로 Array 같이 순서를 보장해주는 자료구조를 사용하는 것이 좋습니다. Array를 사용하지 않고 순서가 없는 자료 구조를 사용하는 경우에는 날짜별 주식 가격을 확인하기 어려우며 매번 전체 자료를 읽어 들이고 비교해야 하는 번거로움이 발생합니다.
랜덤 접근과 순차적 접근
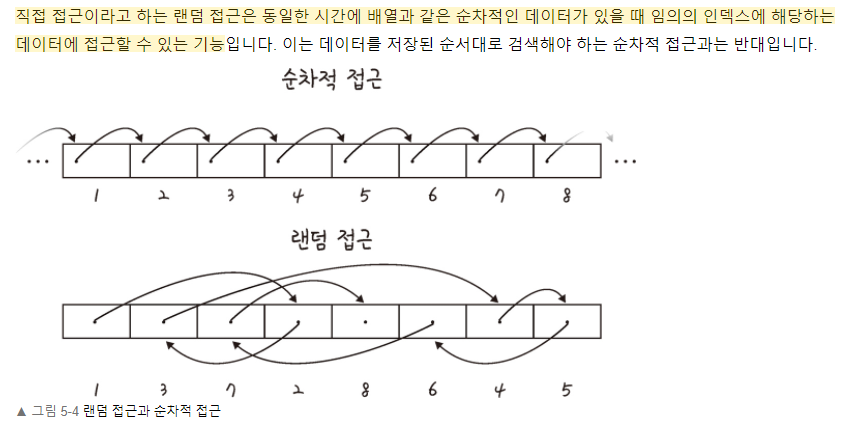
배열과 연결 리스트 비교

벡터
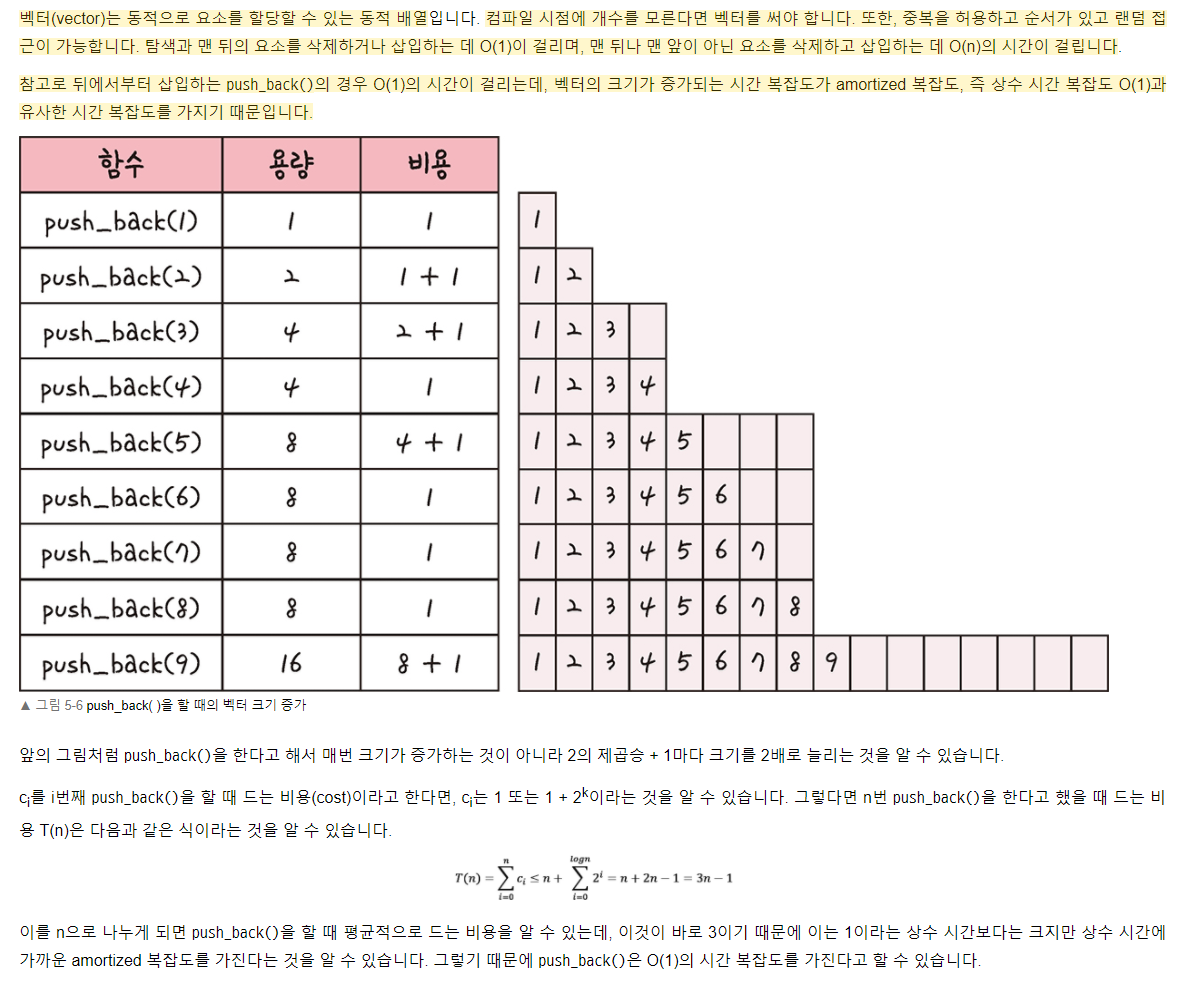
예제
package vector;
import java.util.Collections;
import java.util.List;
import java.util.Vector;
public class test01 {
public static void main(String[] args) {
String[] name = {"민주", "지은", "채원", "유진", "사쿠라"};
// vector 객체 생성
List<String> list = new Vector<String>(4,3);
System.out.println("벡터에 저장된 요소의 개수 : " + list.size()); // 0
System.out.println("벡터의 용량은 : " + ((Vector<String>)list).capacity()); // 4
for (int i = 0; i < name.length; i++) {
list.add(name[i]); // 객체 추가
}
System.out.println("벡터에 저장된 요소의 개수 : " + list.size()); // 5
System.out.println("벡터의 용량은 : " + ((Vector<String>)list).capacity()); // 7
System.out.println(list); // [민주, 지은, 채원, 유진, 사쿠라]
list.add(1, "은비");
System.out.println(list); // [민주, 은비, 지은, 채원, 유진, 사쿠라]
System.out.println(list.get(3)); // 채원
boolean ts = list.contains("채원");
System.out.println(ts); // true
boolean ts2 = list.contains("카즈하");
System.out.println(ts2); // false
list.set(2, "카즈하");
System.out.println(list);
list.remove(2);
list.remove("은비");
System.out.println(list);
// 오름차순 정렬
System.out.println("객체 오름 차순 정렬");
Collections.sort(list);
System.out.println(list);
// 내림차순 정렬
System.out.println("객체 내림 차순 정렬");
Collections.sort(list, Collections.reverseOrder());
System.out.println(list);
}
}★스택(stack)
스택은 순서가 보존되는 선형 데이터 구조 유형이다. 가장 마지막 요소 (가장 최근 요소)부터 처리하는 LIFO (Last In First Out) 메커니즘은 가지고 있다. 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰입니다. 스택은 쌓여있는 접시 더미와 같이 작동한다. 새로운 접시가 쌓일 때도 맨 위에서 쌓이고, 접시를 가져갈 때도 맨 위에서 가지고 가는 것과 같다.
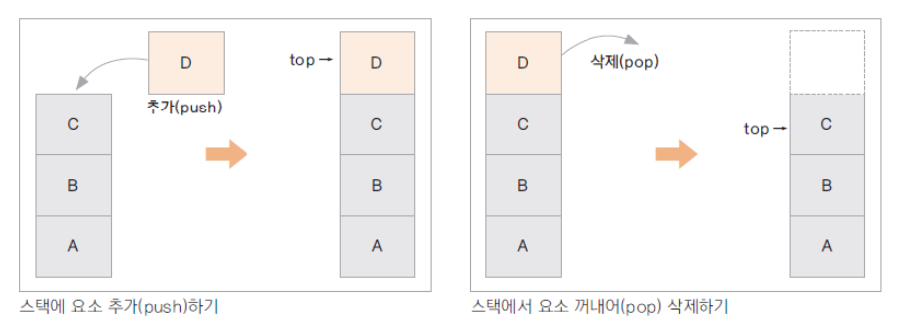
시간복잡도

장점
- 동적인 메모리 크기
- 데이터를 받는 순서대로 정렬된다
- 빠른 런타임 (runtime)
단점
- 가장 최신 요소만 가져온다
- 한번에 하나의 데이터만 처리 가능하다
★큐(Queue)
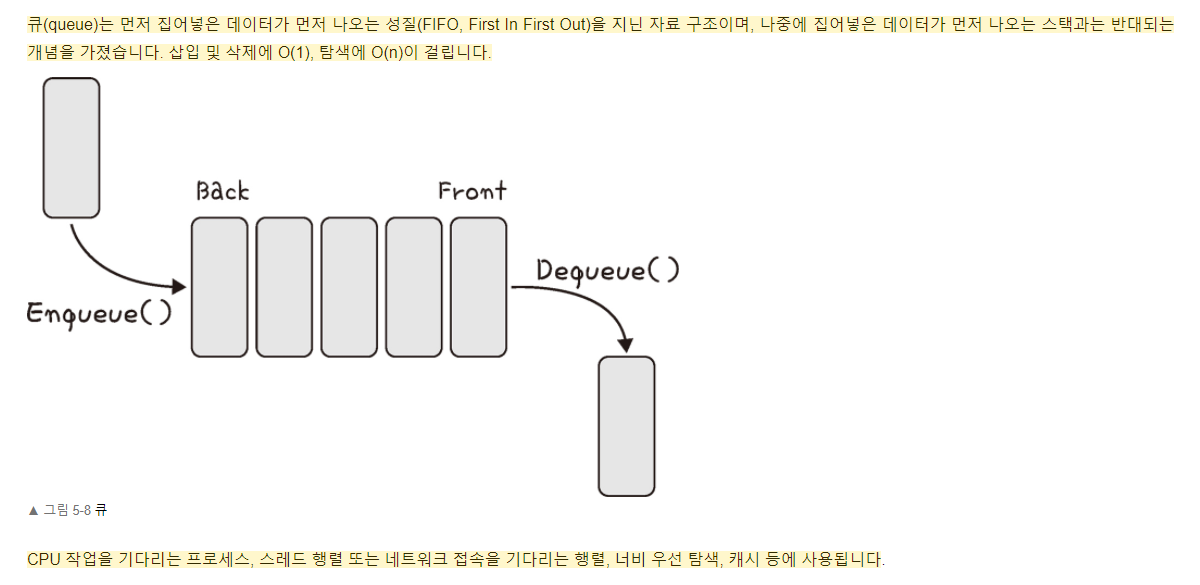
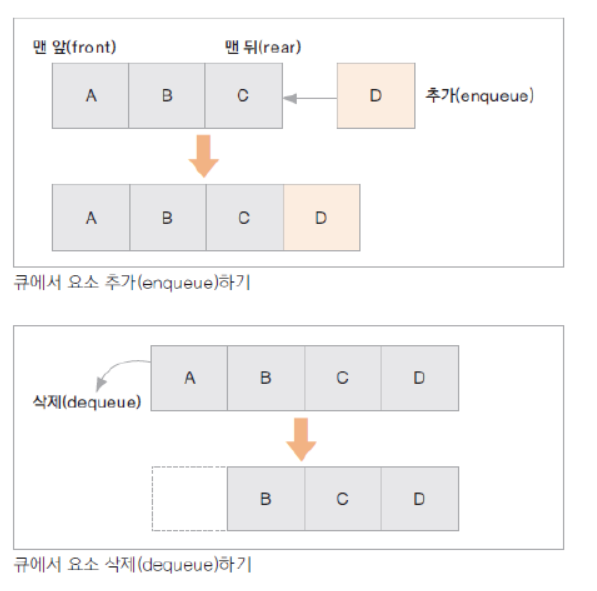
FIFO(First In First Out)의 선입선출 구조- enQueue();를 이용한 데이터 입력, deQueue();를 이용한 데이터 출력
- 예) 우선순위가 같은 작업 예약(인쇄 대기열), 선입선출이 필요한 대기열(티켓 카운터)
Linear Queue(선형큐)는 메모리 재사용이 불가능 이러한 문제점을 보완하여 Circular Queue(원형 큐)가 나옴
큐는 스택과 비슷하지만 가장 먼저 입력된 요소를 처리하는 FIFO (First In First Out) 메커니즘이다. 큐는 놀이공원에서 서는 줄과 같이 작동한다. 사람들이 맨 끝에 줄을 서고, 맨 앞에서부터 놀이기구에 탑승하는 것과 같다.
시간복잡도

장점
- 동적인 메모리 크기
- 데이터를 받는 순서대로 정렬된다
- 빠른 런타임 (runtime)
단점
- 가장 오래된 요소만 가져온다
- 한번에 하나의 데이터만 처리 가능하다
💡스택과 큐를 비교하여 설명하시오
-
둘 다 선형 자료구조의 일종입니다.
-
큐는 FIFO 특징을 갖고 있으며 CPU 작업을 기다리는 프로세스를 위한 ReadyQueue, BFS 등에서 사용됩니다.
참고: 자바에서 큐는 인터페이스로 구현되어있다.
-
스택은 LIFO 특징을 갖고 있으며 웹브라우저의 방문 기록, 재귀함수 등에서 사용됩니다.
💡Stack과 Queue의 실사용 예를 들어 간단히 설명해주세요.
Stack - 자바의 Stack 메모리 영역
물류 센터에서 상품을 적재하고 저장할 때 사용될 수 있습니다. 새로운 상품이 도착하면 맨 위에 쌓아 올리고, 꺼낼 때는 맨 위에 있는 상품을 먼저 꺼냅니다. 이는 후입선출(LIFO, Last-In-First-Out) 방식으로 작동합니다.
Queue - OS의 스케쥴러
공항의 탑승 대기열은 큐의 좋은 예입니다. 비행기를 탑승하기 위해 대기하는 승객들은 먼저 도착한 승객부터 차례대로 탑승합니다. 이러한 대기열은 선입선출(FIFO, First-In-First-Out) 방식으로 작동합니다.
💡Priority Queue(우선순위 큐)에 대해 설명해주세요.
우선순위 큐는 들어간 순서에 상관없이 우선순위가 높은 데이터를 먼저 꺼내기 위해 고안된 자료구조입니다. 우선순위 큐 구현 방식에는 배열, 연결 리스트, 힙이 있고, 그중 힙 방식이 worst case라도 시간 복잡도 O(logN)을 보장하기 때문에 일반적으로 완전 이진트리 형태의 힙을 이용해 구현합니다.
💡Map에 대해 아는 대로 설명하시오.
맵은 키와 매핑된 값의 조합으로 형성된 자료 구조입니다. 해시 테이블을 구현할 때 사용되며, 정렬을 보장하지 않는 unoredered_map과 정렬을 보장하는 map 두 가지가 있습니다.
💡Set에 대해 아는 대로 설명하시오
중복되는 요소는 없고 오로지 유니크한 값만 저장하는 자료 구조입니다. 또한 데이터의 순서가 보장되지 않는 특징이 있습니다.
비선형 자료 구조
비선형 자료 구조란 일렬로 나열하지 않고 자료 순서나 관계가 복잡한 구조를 말합니다. 일반적으로 트리나 그래프를 말합니다.
그래프
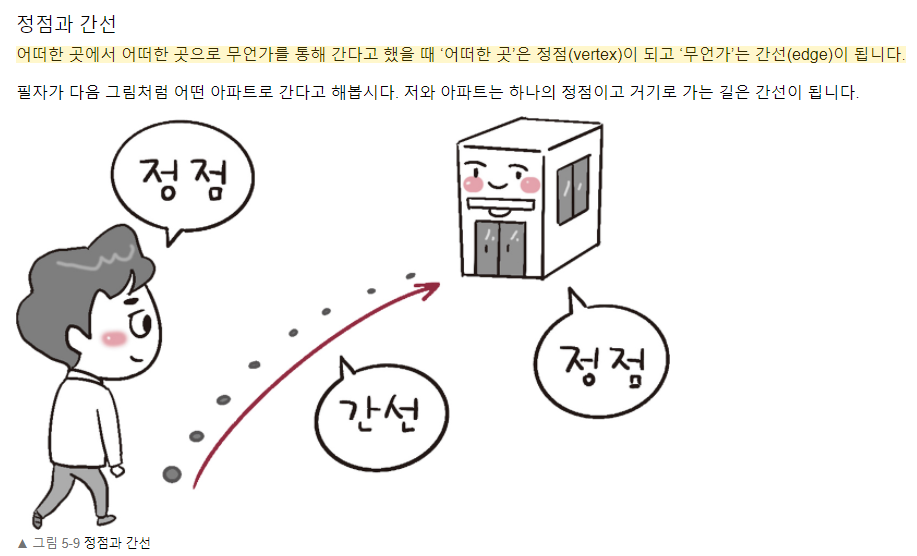
그래프는 단순히 nodes/vertices(노드) 사이에 edge(엣지)가 있는 collection이다. 그래프는 directed(방향) 또는 undirected(무방향)이 될 수 있다. Directed graph는 한쪽 방향 밖에 없어서 일방통행과 같고, undirected graph는 방향이 지정되지 않아서 양방향 도로와 같다. 하지만 그래프로 구성된 데이터 구성은 다양하다.
정점과 간선들의 유한 집합 G = (V,E)
-> 네비게이션, 구글맵 이런게 다 그래프에 기반해서 구현.
- 정점(vertex) : 여러 특성을 가지는 객체, 노드(node)
- 간선(edge) : 이 객체들을 연결 관계를 나타냄. 링크(link)
간선은 방향성이 있는 경우와 없는 경우가 있음(노드와 노드 연결하는걸 edge나 link라고 한다.)- 그래프를 구현하는 방법 : 인접 행렬(adjacency matrix), 인접 리스트(adjacency list)
- 그래프를 탐색하는 방법 : BFS(bread first search), DFS(depth first search)
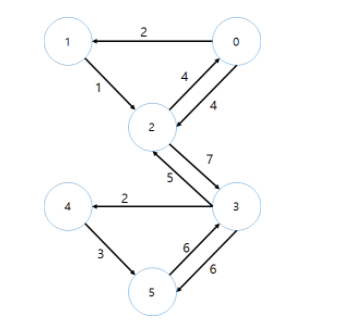

시간복잡도
그래프로 구조를 어떻게 설계 그리고 무엇을(검색, 추가, 삭제, 등) 하고 싶으냐에 따라 시간 복잡도가 달라진다. 그래프가 리스트 형태로 설계 되어 있는 경우: N = node, E = edge

장점
- 새로운 요소들의 추가/삭제가 용이하고 효율적이다
- 구조의 응용이 가능하다
단점
충돌이 일어날 수 있다 (입력된 키의 해시값이 이미 데이터가 저장된 버킷을 가리킬 수 있다)
트리(Tree)
트리는 그래프 중 하나로 그래프의 특징처럼 정점과 간선으로 이루어져 있고 트리 구조로 배열된 일종의 계층적 데이터의 집합니다. 루트 노드, 내부 노드, 리프 노드 등으로 구성됩니다. 즉, 노드로 구성된 계층적 자료구조다. 참고로 트리로 이루어진 집합을 숲이라고 합니다. 최상위 노드(루트)를 만들고, 루트 노드의 child를 추가하고, 그 child에 또 child를 추가하는 방식으로 트리 구조를 구현할 수 있다. 부모 노드와 자식 노드간의 연결로 이루어진 자료 구조
특징

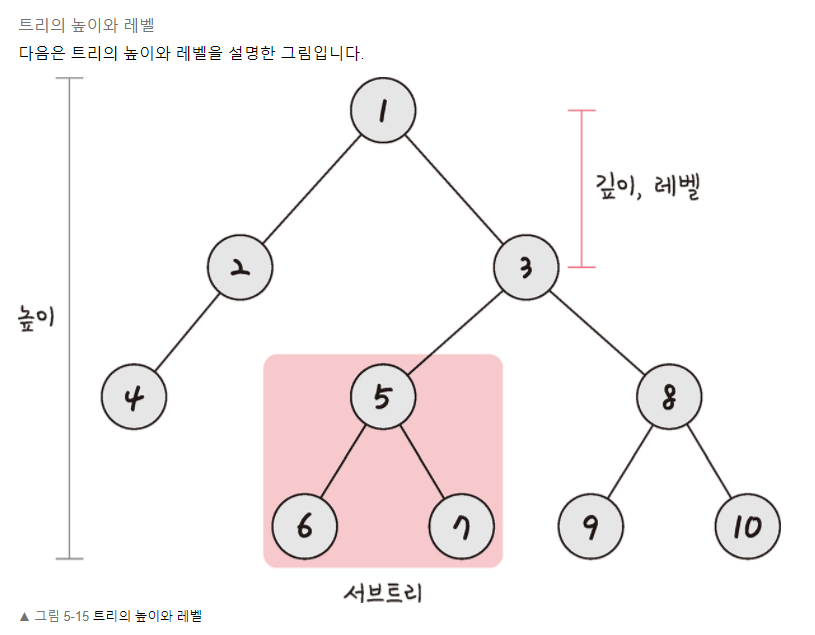
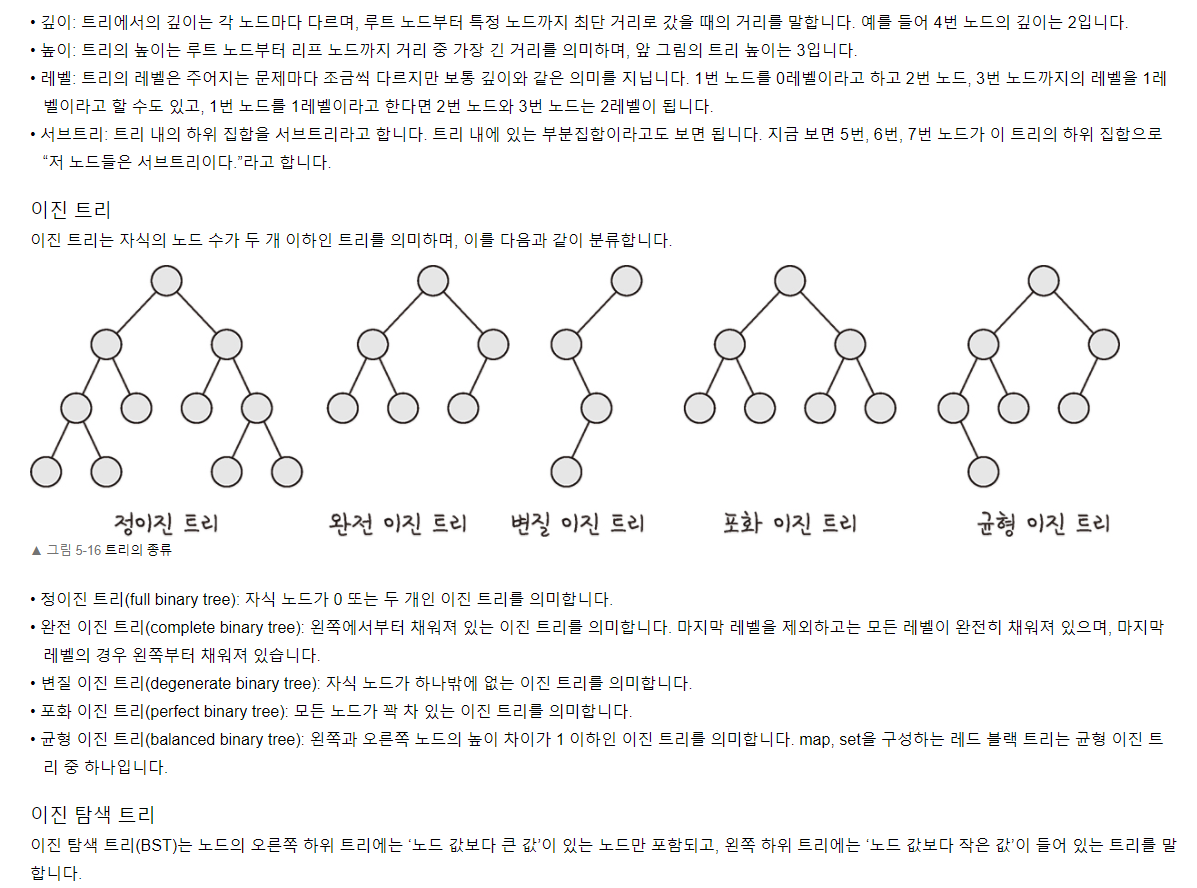

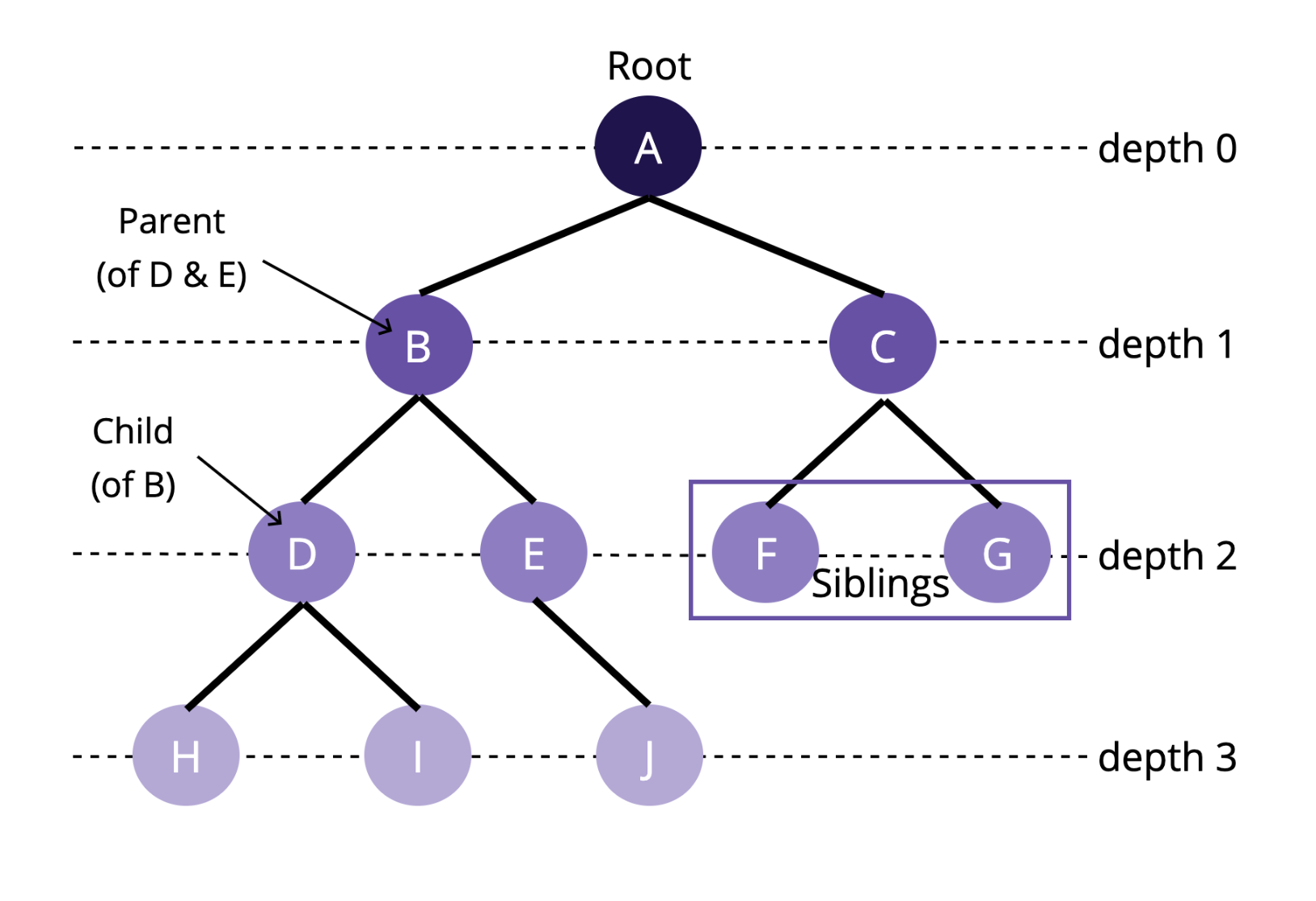
트리의 종류는 다양하다.
트리 구조와 관련하여 반드시 알아야 할 개념들:
- A, B, C, D 등 트리의 구성요소를 노드(node) 라고 한다.
- 위 그림의 A처럼, 트리 구조에서 최상위에 존재하는 노드를 root라고 한다.
- 루트를 기준으로, 다른 노드로의 접근하기 위한 거리를 depth 라고 한다.
- 같은 부모를 가지면서 같은 depth에 존재하는 노드들은 sibling 관계에 있다.
- 그림에서 A는 B와 C의 부모(parent) 이고, B와 C는 A의 자식(child)이다.
- 노드와 노드를 잇는 선을 edge 라고 한다.
- 자식이 없는 노드는 leaf 라고 한다.
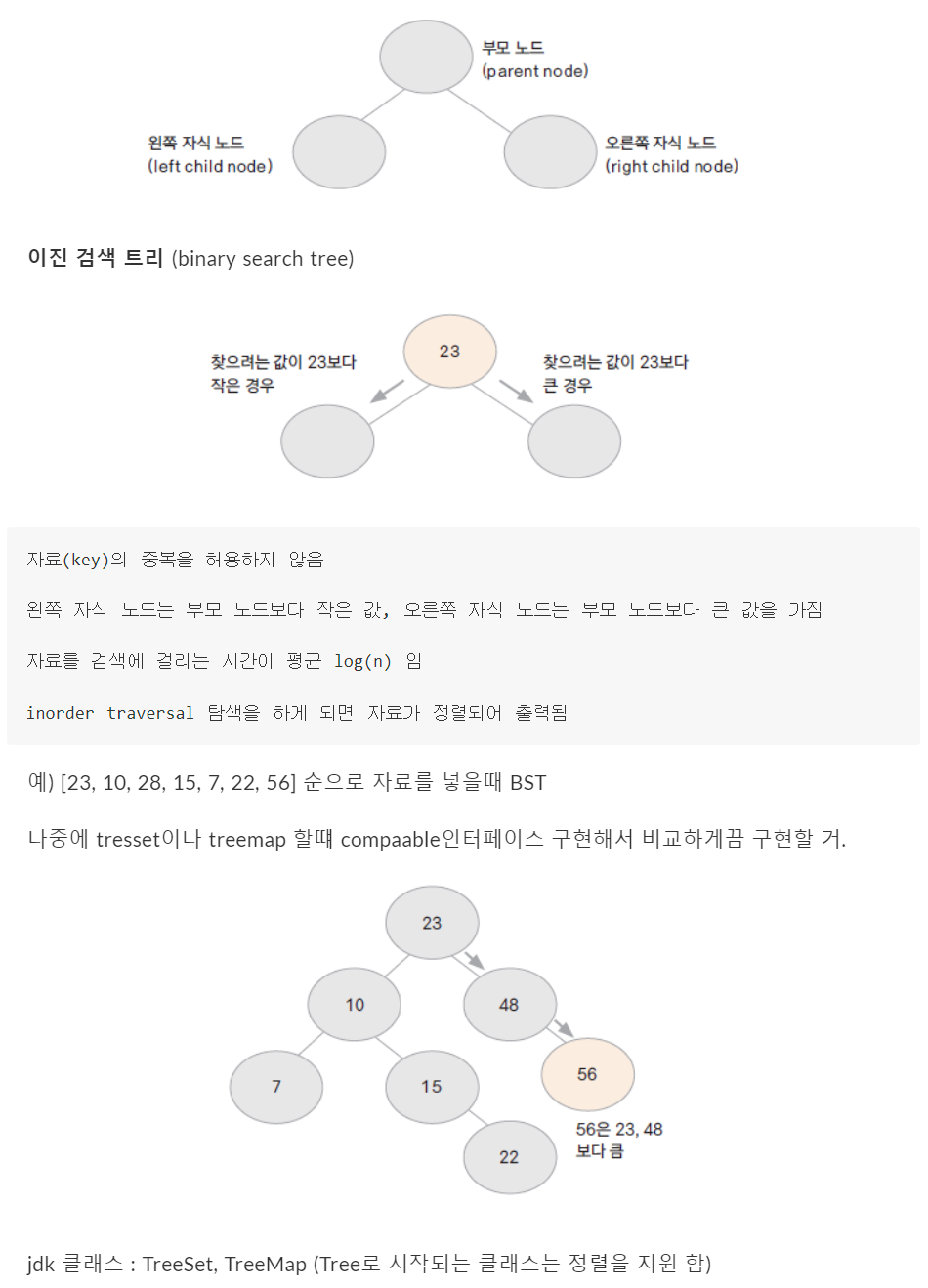
이진 트리(binary tree)
부모노드에 자식노드가 두 개 이하인 트리
★힙(heap)

💡힙에 대해 아는 대로 설명하시오.
-
힙은 완전 이진 트리 기반의 자료구조이며, 최소힙과 최대힙으로 구분됩니다.
-
최대힙은 루트 노드에 있는 키가 모든 자식에 있는 키 중에서 가장 큰 값이 되며, 해당 구조가 재귀적으로 반복되는 자료구조를 말합니다.
-
최소힙은 루트 노드에 있는 키가 모든 자식에 있는 키 중에서 가장 작은 값이 되며, 해당 구조가 재귀적으로 반복되는 자료구조를 말합니다.
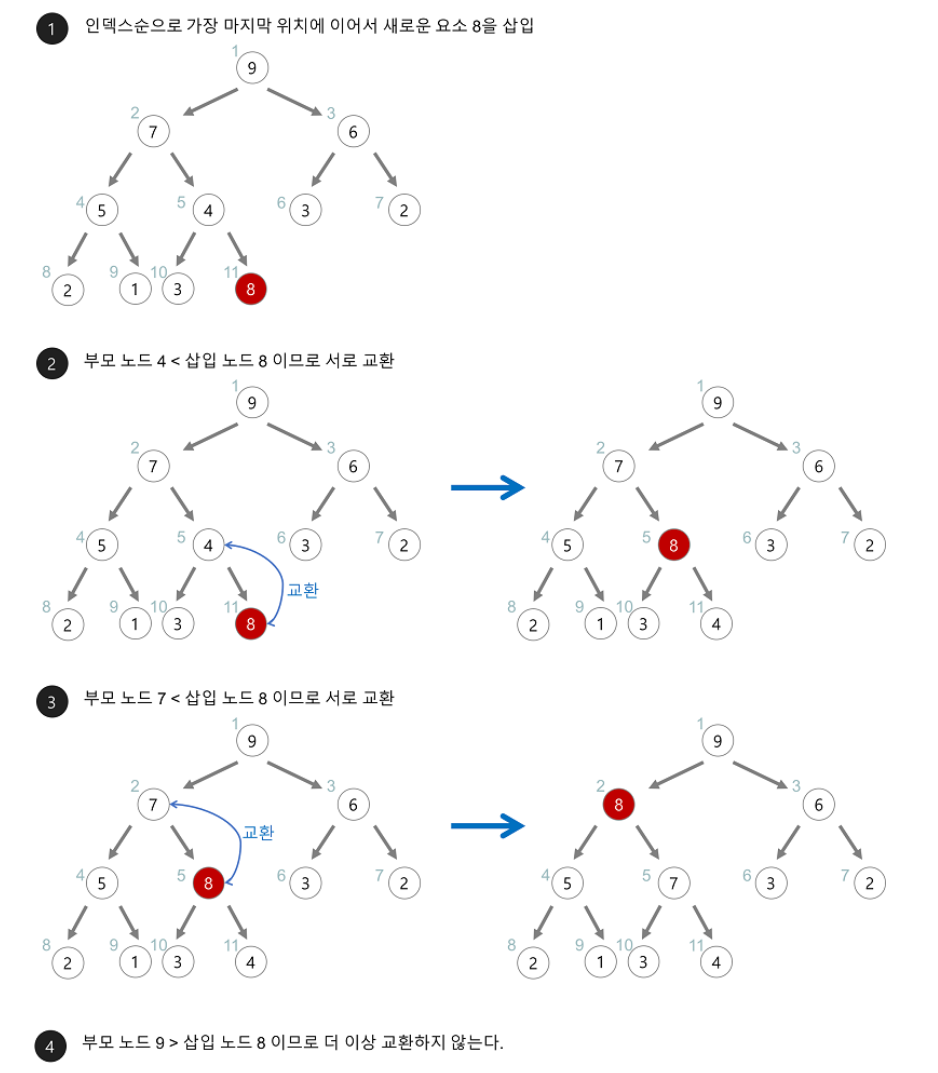
새로운 데이터가 들어오면 어떤 순서로 동작하나?
새로운 노드를 힙의 마지막 노드에 이어서 삽입합니다. 이후, 부모 노드들과 크기를 비교하며 교환해서 힙의 성질을 유지합니다.
데이터를 삭제하면 어떤 순서로 동작하나?
루트 노드를 삭제하고 마지막 노드를 루트 노드 자리에 놓습니다. 이후, 자식 노드들과 크기를 비교하며 교환해서 힙의 성질을 유지합니다.
💡Stack과 Queue, Tree와 Heap의 구조에 대해 설명해주세요.
Stack과 Queue는 선형 자료구조의 일종이며, Array와 LinkedList로 구현할 수 있습니다. Stack은 후입선출(LIFO)방식 즉, 나중에 들어간 원소가 먼저 나오는 구조이고 Queue는 선입선출(FIFO)방식 즉, 먼저 들어간 원소가 먼저 나오는 구조를 갖습니다.
Tree는 스택과 큐와 같은 선형 구조가 아닌 비선형 자료구조이며, 계층적 관계를 표현하기에 적합합니다. Heap은 최댓값 또는 최솟값을 찾아내는 연산을 쉽게 하기 위해 고안된 구조로, 각 노드의 키값이 자식의 키값보다 작지 않거나(최대힙) 그 자식의 키값보다 크지 않은(최소힙) 완전이진트리 입니다.
우선순위 큐

💡우선순위큐에 대해 아는 대로 설명하시오.
우선순위 큐는 대기열에서 우선순위가 높은 요소가 우선순위가 낮은 요소보다 먼저 제공되는 자료 구조입니다. 우선순위 큐는 배열, 연결리스트, 힙으로 구현할 수 있으나 힙이 enqueue와 dequeue에 대한 시간복잡도가 가장 낮아 선호됩니다.
-
각각의 상황에서 시간복잡도가 어떻게 되는지 아나?
배열과 연결리스트의 경우 enqueue는 O(1), dequeue는 O(n)이며, 만약 정렬된 배열 혹은 연결리스트라면 각각 O(n), O(1)이 됩니다. 힙의 경우 둘 모두 O(logn)이 됩니다.
-
enqueue와 dequeue 과정에 대해 설명해봐라
-
Enqueue는 큐에 데이터를 추가하는 작업을 의미합니다. 새로운 데이터를 큐의 끝에 추가하는 것으로 생각할 수 있습니다. 이 작업은 큐의 뒤쪽에서 이루어지며, 새로운 요소가 큐의 맨 뒤에 추가됩니다. 이 작업은 FIFO(First In First Out) 원칙을 따릅니다. 즉, 가장 먼저 추가된 요소가 가장 먼저 나가는 구조입니다.
-
Dequeue는 큐에서 데이터를 제거하는 작업을 의미합니다. 큐의 맨 앞에 있는 요소를 제거하는 것으로 생각할 수 있습니다. 이 작업은 큐의 앞쪽에서 이루어지며, 가장 먼저 추가된 요소가 가장 먼저 제거됩니다.
-
맵(Map)

셋
셋(set)은 특정 순서에 따라 고유한 요소를 저장하는 컨테이너이며, 중복되는 요소는 없고 오로지 희소한(unique) 값만 저장하는 자료 구조
★해시 테이블 (Hash tables / Hash map)
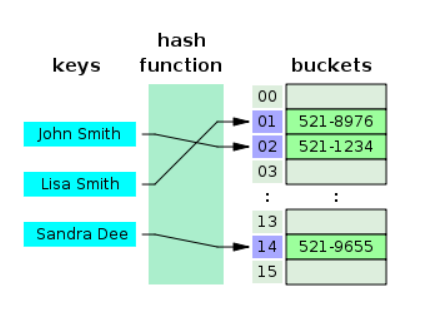
해시 테이블은 무한에 가까운 데이터들을 유한한 개수의 해시값으로 매핑한 테이블입니다. 해시 테이블은 대량의 정보를 저장하고 특정 요소를 효율적으로 검색할 수 있는 복잡한 데이터 구조다. 이 데이터 구조는 테이블 내에 더 작은 서브그룹인 버킷(bucket)에 키/값(key/value) 쌍(pair)을 저장한다. 해시 테이블은 키를 저장할 때에 메모리 공간을 덜 사용할 수 있도록, 키를 "해시 함수"(Hash function)라는 함수를 통해 해시(hash)라는 특정 숫자값으로 변환한다. 해시 테이블은 필요할 때에만 메모리 크기를 늘리고, 가능한 작은 크기를 유지한다.
키(key)는 검색 시 사용되는 문자열이고 값(value)은 해당 키와 쌍을 이룬 데이터다. 검색된 각 키는 미리 정의된 해시함수(hash function)를 통해 해시(hash)값을 받고 버킷(bucket)을 가리킨다. 즉, 해시 숫자는 버킷의 index라는 뜻이다. 그리고 버킷에서 검색할 때 입력된 키를 찾고 해당 키와 관련된 값을 반환한다. 순서를 유지하지 않는다. 순서를 유지하려면 LinkedHashMap을 써야 한다.
해쉬 테이블은 검색이 빠르다.
시간복잡도

장점
- 새로운 요소들의 추가/삭제가 용이하고 효율적이다
- 원하는 값의 검색/가져오기가 빠르고 효율적이다
- 동적인 메모리 크기 (그러나 직접 크기를 늘리거나 줄여야 한다)
단점
- 충돌이 일어날 수 있다 (입력된 키의 해시값이 이미 데이터가 저장된 버킷을 가리킬 수 있다)
- 충돌이 자주 일어날 수 있으며 해시함수의 정비가 필요한 경우가 많다.
예시
package map;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Code02 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
map.put("4", null);
map.put(null, "50");
// 지정된 키에 대한 값을 받는다.
String value = map.get("3");
System.out.println("Key :3, Value : " + value);
// 지정된 키에 대한 값이 없으면 기본 값을 반환
value = map.getOrDefault("5", "0");
System.out.println("Key : 5, Value : " + value );
// 키의 존재 여부 확인
System.out.println("2번 키의 존재 여부 : " +map.containsKey("2"));
System.out.println("3번 값의 존재 여부 : " +map.containsValue("3"));
// Map에 저장된 전체 항목을 얻어온다.
Set<Map.Entry<String, String>> entrySet = map.entrySet();
System.out.println(entrySet);
// 키의 전체 목록을 얻어온다.
Set<String> keySet = map.keySet();
for (String key: keySet
) {
System.out.println(key + " : " + map.get(key));
}
// 지정된 키의 항목을 지운다.
value = map.remove(null);
System.out.println("삭제된 값 : " + value);
// 삭제된 후 출력
for (String key : keySet
) {
System.out.println(key + " : " + map.get(key));
}
}
}
package map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Code03 {
static HashMap phoneBook = new HashMap();
static void addPhoneNo(String groupName, String name, String tel) {
addGroup(groupName);
HashMap group = (HashMap) phoneBook.get(groupName);
group.put(tel, name);
}
static void addGroup(String groupName) {
if(!phoneBook.containsKey(groupName)) {
phoneBook.put(groupName, new HashMap<>());
}
}
static void printList() {
Set set = phoneBook.entrySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Map.Entry e = (Map.Entry) iterator.next();
Set entrySet = ((HashMap) e.getValue()).entrySet();
Iterator groupIterator = entrySet.iterator();
System.out.println(e.getKey() + " [ " + entrySet.size() + " ] ");
while (groupIterator.hasNext()) {
Map.Entry e2 = (Map.Entry) groupIterator.next();
System.out.println("이름 : " + e2.getValue() + " 번호 : " + e2.getKey());
}
}
}
public static void main(String[] args) {
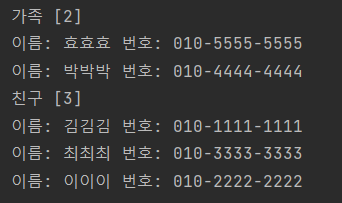
addPhoneNo("친구", "김김김", "010-1111-1111");
addPhoneNo("친구", "이이이", "010-2222-2222");
addPhoneNo("친구", "최최최", "010-3333-3333");
addPhoneNo("가족", "박박박", "010-4444-4444");
addPhoneNo("가족", "효효효", "010-5555-5555");
printList();
}
}
💡해시 테이블(Hash Table)과 시간 복잡도에 대해 설명해주세요.
해시 테이블은(Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조입니다. 빠른 검색 속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문입니다. 각 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균 O(1)의 시간 복잡도로 데이터를 조회합니다. 하지만 index값이 충돌이 발생한 경우 Chanining에 연결된 리스트들까지 검색해야 하므로 O(N)까지 증가할 수 있습니다.
-
해시 함수는 1:1 대응이 되는가?
그럴 수도 있고 아닐 수도 있습니다.다만, 해시 함수를 1:1 대응이 되도록 구현하게 되면 결과적으로 배열과 다를 바가 없고 메모리만 과도하게 차지합니다. 따라서 어느 정도의 충돌이 있으면서도 효율적인 충돌 해결법을 적용하는 것이 이상적입니다.
-
충돌 해결법에는 어떤 것들이 있을까?
- 개방주소법과 분리연결법이 있습니다.
- 개방주소법은 삽입하려는 해시 버킷이 이미 사용중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식을 말합니다.
- 선형 탐사법, 제곱 탐사법, 이중 해싱이 있습니다.
- 분리연결법은 삽입하려는 해시 버킷이 이미 사용중인 경우 다른 해시 버킷을 찾는 것이 아니라 연결리스트 형태로 해당 버킷에 값을 추가하는 방식을 말합니다.
- 일반적으로 개방주소법이 분리연결법보다 캐시효율이 좋다.
-
해시 테이블이 가득차면 어떻게 되나?
재해싱을 해야합니다. 2배 이상의 새로운 해시테이블을 만들고 새로운 해시함수를 만들어 기존 해시테이블의 키값을 새로운 해시테이블에 할당합니다.
💡Hash Map과 Hash Table의 차이점에 대해 설명해주세요.
동기화 지원 여부와 null 값 허용 여부의 차이가 있습니다.
-
해시 테이블(Hash Table)
- 병렬 처리를 할 때 (동기화를 고려해야 하는 상황) Thread-safe 하다.
- Null 값을 허용하지 않는다.
-
해시 맵(Hash Map)
- 병렬 처리를 하지 않을 때 (동기화를 고려하지 않는 상황) Thread-safe하지 않는다.
- Null 값을 허용한다.
String
String은 리터럴로 표기가 가능하지만 primitive 자료형은 아니다. String은 리터럴 표현식을 사용할 수 있도록 자바에서 특별 대우 해 주는 자료형이다.
String a = "happy java" 와 String a = new String("happy java") 는 같은 값을 갖게 되지만 완전히 동일하지는 않다. 첫번째 방식을 리터럴(literal) 표기라고 하는데 객체 생성없이 고정된 값을 그대로 대입하는 방법을 말한다. 위 예에서 리터럴 표기법은 "happy java" 라는 문자열을 intern pool 이라는 곳에 저장하고 다음에 다시 동일한 문자열이 선언될때는 cache 된 문자열을 리턴한다. 두번째 방식은 항상 새로운 String 객체를 만든다.
문자열의 값을 비교할때는 반드시 equals 를 사용해야 한다.
String + String + String ...
-
각각의 String 주소값이 Stack에 쌓이고,
Garbage Collector가 호출되기 전까지 생성된 String 객체들은 Heap에 쌓이기 때문에 메모리 관리에 치명적이다. -
String을 직접 더하는 것보다는
StringBuffer나StringBuilder를 사용하는 것이 좋다.
StringBuilder, StringBuffer
- memory에
append하는 방식으로, 클래스에 대한 객체를 직접 생성하지 않는다.
StringBuilder
- 변경가능한 문자열
- 비동기 처리
StringBuffer
- 변경가능한 문자열
- 동기 처리
- multiple thred 환경에서 안전한 클래스 (thread safe)
insert 메소드는 특정 위치에 원하는 문자열을 삽입할 수 있다.
package String;
public class Code01 {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
>
sb.append("study java");
sb.insert(0, "Good ");
>
System.out.println(sb.toString());
}
}
StringBuffer.append vs String + String
아래의 두 예시 모두 hello jump to java를 출력하지만 내부적으로 객체가 생성되고 메모리가 사용되는 과정은 다르다.
첫번 째 예제의 경우 StringBuffer 객체는 한번만 생성된다. 두번 째 예제는 String 자료형에 + 연산이 있을 때마다 새로운 String 객체가 생성된다(문자열 간 + 연산이 있는 경우 자바는 자동으로 새로운 String 객체를 만들어 낸다). 두번 째 예제에서는 총 4개의 String 자료형 객체가 만들어지게 된다.
package String;
public class Code02 {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
sb.append("hello");
sb.append(" ");
sb.append("jump to java");
String result = sb.toString();
System.out.println(result);
String result2 = "";
result2 += "hello";
result2 += " ";
result2 += "jump to java";
System.out.println(result2);
}
}해싱(Hashing)
- 자료를 검색하기 위한 자료 구조
- 키(key)에 대한 자료를 검색하기 위한 사전(dictionary) 개념의 자료 구조
- key는 유일하고 이에 대한 value를 쌍으로 저장
- index = h(key) : 해시 함수가 key에 대한 인덱스를 반환해줌 해당 인덱스 위치에 자료를 저장하거나 검색하게 됨
- 해시 함수에 의해 인덱스 연산이 산술적으로 가능 O(1)
- 저장되는 메모리 구조를 해시테이블이라 함
키는 중복 되지 않음. 나머지를 구하는게 해시함수(123%100해서 23번쨰 자리에 저장) 해시테이블

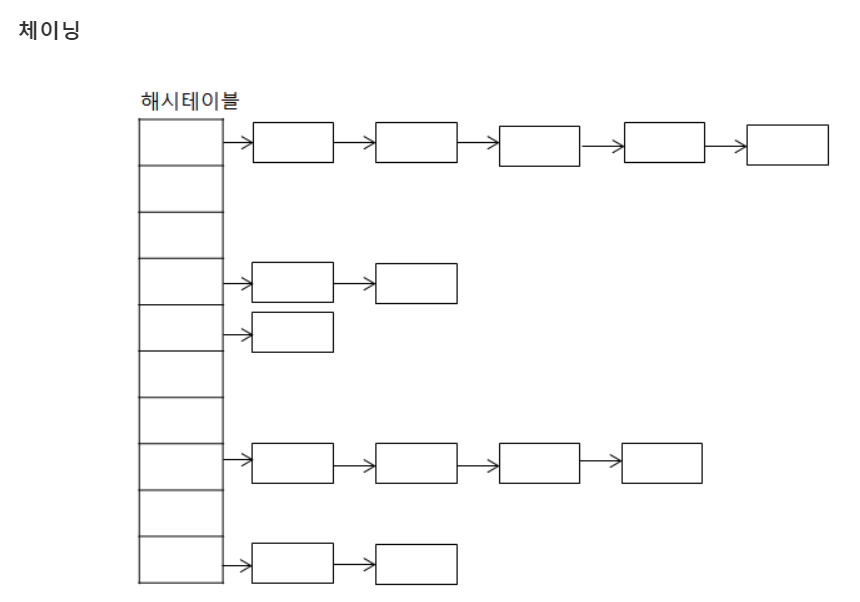
해시는 키에대한 밸류가 있다.
키는 유해서 키는 중복될 수 없다. 키만 알면 밸류를 꺼낼 수 없다. 해시는 들어가는 순서와 상관이 없다. 배열과 비슷하게 생겨서 많이 오해. 해시펑션에 의해 정해져서 순서랑은 무관하다.
예상 질문
💡해시 테이블을 설명하세요
해시 테이블은 무한에 가까운 데이터(키)들을 유한한 개수의 해시 값으로 매핑한 테이블입니다. 이를 통해 작은 크기의 캐시 메모리로도 프로세스를 관리하도록 할 수 있습니다.
💡그래프 구현하는 방법엔 어떤 것들이 있나?
-
인접 행렬과 인접 리스트 방식이 있다.
-
인접 행렬은 2차원 배열로 각 정점간의 연결관계를 표현하며 O(1) 시간복잡도로 연결관계를 파악할 수 있다는 특징이 있다.
-
인접 리스트는 각 정점이 연결되어 있는 정점을 연결리스트로 표현하는 방식을 말하며, 리스트의 요소들을 순차적으로 확인해봐야 하므로 인접 행렬에 비해 탐색 속도가 느리다는 단점이 있습니다. 다만, 인접 행렬에 비해 공간복잡도는 적다는 장점이 있습니다.
각각의 공간복잡도 : 인접 행렬은 O(V^2), 인접 리스트는O(E+V)
💡그래프와 트리의 차이점은?
그래프는 정점과 간선으로 이루어진 자료구조이며 트리는 그래프 중 하나로 그래프의 특징처럼 정점과 간선으로 이루어져 있고 트리 구조로 배열된 일종의 계층적 데이터의 집합입니다. 루트 노드, 내부 노드, 리프 노드 등으로 구성되며 V -1 = E 등의 특징이 있습니다.
💡이진 탐색 트리는 어떤 문제점이 있고 이를 해결하기 위한 트리 중 한 가지를 설명하세요
이진 탐색 트리는 선형적으로 구성될 때 시간 복잡도가 O(n)으로 커지는 문제점이 있습니다. 선형적으로 구성하지 않고 균형 잡힌 트리로 AVL 트리와 레드 블랙 트리가 있다.
AVL 트리(Adeison-Velsky and Landis tree)는 스스로 균형을 잡는 이진 탐색 트리입니다. 두 자식 서브트리의 높이는 항상 최대 1만큼 차이 난다는 특징이 있습니다. 탐색, 삽입, 삭제 모두 시간 복잡도가 O(logn)이며 삽입, 삭제를 할 때마다 균형이 맞지 않는 것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로 회전시키며 균형을 잡습니다.
알고리즘
★브루트 포스
brute: 무식한, force: 힘
무식한 힘으로 해석할 수 있다.
완전탐색 알고리즘. 즉, 가능한 모든 경우의 수를 모두 탐색하면서 요구조건에 충족되는 결과만을 가져온다. 이 알고리즘의 강력한 점은 예외 없이 100%의 확률로 정답만을 출력한다.
-
일반적 방법으로 문제를 해결하기 위해서는 모든 자료를 탐색해야 하기 때문에 특정한 구조를 전체적으로 탐색할 수 있는 방법을 필요로 한다.
-
알고리즘 설계의 가장 기본적인 접근 방법은 해가 존재할 것으로 예상되는 모든 영역을 전체 탐색하는 방법이다.
-
선형 구조를 전체적으로 탐색하는 순차 탐색, 비선형 구조를 전체적으로 탐색하는 깊이 우선 탐색(DFS, Depth First Search)과 너비 우선 탐색(BFS, breadth first search)이 가장 기본적인 도구이다.
브루트포스 알고리즘 방법으로 for문을 이용한 탐색, 백트래킹(재귀)을 이용한 탐색, DFS & BFS 탐색 등이 있다.
알고리즘을 풀땐, 이 문제가 브루트포스로 가능한지 확인 후, 불가능하다면 어떤 알고리즘을 적용해서 시간복잡도를 줄일지 확인해야한다.(DP,누적합,이분탐색 등등)
연습
N개의 숫자를 입력받아 이 중 임의의 R개의 수를 골랐을 때, 고른
R개의 합이 S인 모든 경우의 수를 구하여라. 입력은 첫째줄에 공백을 기준으로 순서대로 N, R, S가 주어진다. (R ≤ N ≤ 20, lSl ≤ 1,000,000. 2 ≤ R ≤ 7) 두번째줄에는 N개의 정수가 공백을 기준으로 주어지며, 각 정수의 절대값은 1,000,000을 넘지 않는다.(제한시간1초)
public class sty05 {
private static int resultCnt = 0;
private static int[] input;
private static int n, r, s;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
r = sc.nextInt();
s = sc.nextInt();
input = new int[n];
for (int i = 0; i < input.length; i++) {
input[i] = sc.nextInt();
}
solve(-1, 0, 0);
System.out.println(resultCnt);
}
private static void solve(int index, int sum, int cnt) {
if(cnt == r) {
if(sum == s) {
resultCnt++;
}
return;
}
for (int i = 0; i < n; i++) {
sum += input[i];
solve(i, sum, cnt+1);
sum -= input[i];
}
}
}-
우선 base case를 살펴봅니다. 처음 cnt는 0이고, r은 최소 2이니 base case에 들어가지 않습니다.
-
맨 처음 main함수에서 solve 함수를 호출할 때 idx가 -1로 들어오고, i는 idx+1에서 시작하니 0부터 시작합니다.
-
0이었던 sum에 input배열의 0번 idx 값을 더합니다.
-
solve함수에 현재 idx인 i를 넣고, '2'에서 합친 sum을 넣고, cnt를 1 증가시켜줍니다.
-
다시 solve 함수가 실행되고 현재 cnt는 1 입니다. 역시 base case에 충족되지 않으니 다음으로 넘어갑니다.
-
이번엔 i가 1부터 시작됩니다. (이전 복잡했던 반복문에서 i=0, j=i+1, ...로 진행한것과 마찬가지 동작) sum에 input[1]을 더해주고 다시 solve 함수로 들어갑니다.
-
...... 진행하다보니 base case를 충족하는 경우가 발생했습니다. 즉, 문제에서 제시된 R번만큼 숫자를 더했습니다. 그렇다면 이제 현재까지의 sum을 보고 S와 비교합니다. 같다면 resultCnt를 1 증가하고 종료합니다. 같지 않더라도 종료합니다. (이와 같이 재귀 함수에는 어떠한 경우에도 재귀함수가 무한으로 호출되지 않도록 종료시켜주는 base case가 반드시 필요합니다. 이걸 제대로 설정하지 못하면 메모리 누수. 스택 오버플로우 등의 문제가 발생하게 됩니다.)
-
'7'에 해당하는 solve 함수를 호출했던 solve함수의 for문으로 다시 돌아옵니다. 그럼 '7'에 해당하는 solve함수로 들어가기 전 더해뒀던 input[어딘가]의 값을 다시 빼줍니다. for문의 다음 loop에 영향을 끼치면 안되니까요.
-
... 반복
연습2

public class sty06 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String[] NM = sc.nextLine().split(" ");
int n = Integer.parseInt(NM[0]);
int m = Integer.parseInt(NM[1]);
String[] cardValueList = sc.nextLine().split(" ");
ArrayList<Integer> card = new ArrayList<>();
for (String num : cardValueList) {
card.add(Integer.parseInt(num));
}
int max = 0;
// 첫 번째 카드 순회는 n-2가지 진행
for (int i = 0; i < n-2; i++) {
// 두 번째 카드 순회는 첫번째 이후부터 n-1까지 순회
for (int j = 0; j < n-1; j++) {
// 세번째 카드는 두번째 이후부터 n까지 순회
for (int k = 0; k < n; k++) {
int sum =card.get(i) + card.get(j) + card.get(k);
// 3장의 카드의 합이 m보다 작을 경우 max 값을 계산한다.
// max 와 sum 의 값을 비교하면서 점점 max 값은 m 의 값에 근접한다.
if(sum <= m) {
max = Math.max(max, sum);
}
// max 값이 m 과 같으면 가장 가까운 값이기 때문에 즉시 Loop 를 종료한다.
if(max == m) {
System.out.println(max);
return;
}
}
}
}
System.out.println(max);
}
}
순열
순열은 임의의 수열에 대하여 다른 순서로 연산하는 방법을 의미합니다. 즉, 순서가 중요한 것으로 만약, 수열에서 숫자 {1, 2, 3}이 있다면 이것을 보는 순서에 따라 {1, 2, 3}과 {3, 2, 1}는 서로 순서에 차이가 있기 때문에 서로 다른 수열로 보는 것을 의미합니다. 그래서 만약 n개의 서로 다른 데이터가 있고 이를 순열로 나타낸다 하면 전체 순열의 가지 수는 n! 개 가 되는 것이다.

선택 순서가 결과에 영향을 미치는 경우
{1, 2, 3, 4} 숫자가 주어진 경우 만들 수 있는 가장 큰 두 자리 수를 구하라 같은 문제는 순열로 구함
// 순차 탐색
public class study01 {
static int n = 4;
static int[] nums = {1, 2, 3, 4};
// 갯수, 사용된 숫자, 중간 값
static int solve(int cnt, int used, int val) {
// 선택한 숫자가 2개면 종료하고 지금까지의 계산 결과를 반환
if(cnt == 2) return val;
int ret = 0;
for (int i = 0; i < n; i++) {
if((used & 1 << i) != 0) continue;
ret = Math.max(ret, solve(cnt +1, used | 1 << i, val * 10 + nums[i]));
}
return ret;
}
public static void main(String[] args) {
System.out.println(solve(0,0,0));
}
}
1이 들어가면 나머지 값에 하나씩 합쳐지고 최대값인 14가 되고 나머지 숫자들도 하나씩 들어가면서 조합해보고 Math.max에서 최대값인 43이 ret에 담기고 그걸 리턴해준다.
조합
선택 순서가 결과에 영향을 주지 않는 경우
{1, 2, 3, 4} 숫자가 주어진 경우 두 수를 더했을 때 가장 큰 합을 구하라 같은 문제는 조합으로 구함
// 조합 예제
public class study02 {
static int n = 4;
static int[] nums = {1,2,3,4};
// pos : 현재 위치
// cnt : 갯수
// val : 중간 값
static int solve(int pos, int cnt, int val) {
if(cnt == 2) return val;
if(pos == n) return -1;
int ret = 0;
ret = Math.max(ret, solve(pos + 1, cnt +1, val + nums[pos]));
// 선택 안함
// 선택을 안했기 때문에 cnt, val이 변화가 없다
ret = Math.max(ret, solve(pos +1, cnt, val));
return ret;
}
public static void main(String[] args) {
System.out.println(solve(0,0,0));
}
}
★ 시뮬레이션
- 각 조건에 맞는 상황을 구현하는 문제
- 지도상에서 이동하면서 탐험하는 문제
- 배열안에서 이동하면서 탐험하는 문제
- 별도의 알고리즘 없이 풀 수 있으나 구현력 중요
★ 그리디
★ DFS
★ BFS
★ 백트래킹
★ 분할정복
★ 다익스트라
★ SPFA
💡 동적 계획법(DP, Dynamic Programming)에 대해 설명해주세요.
주어진 문제를 풀기 위해, 문제를 여러 개의 하위 문제로 나누어 푸는 방법을 말합니다. 동적 계획법에서는 어떤 부분 문제가 다른 문제들을 해결하는데 사용될 수 있어, 답을 여러 번 계산하는 대신 한 번만 계산하고 그 결과를 재활용하는 메모이제이션(Memoization)기법으로 속도를 향상시킬 수 있습니다.
메모이제이션
동일한 계산을 반복해야 할 때, 이전에 계산한 값을 재사용함으로써 동일한 계산의 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술
💡 동적 계획법(DP, Dynamic Programming)이 갖는 2가지 조건은 무엇인가요?
-
중복되는 부분(작은) 문제
중복되는 부분 문제는 나눠진 부분 문제가 중복되는 경우로, 메모이제이션 기법을 사용해 중복 계산을 없앱니다. -
최적 부분 구조
최적 부분 구조를 가진다는 것은 전체 문제의 최적해가 부분 문제의 최적해들로써 구성된다는 것입니다.
💡버블 정렬(Bubble Sort)에 대해 설명해주세요.
버블 정렬는 첫 인덱스부터 두 값씩 순차적으로 비교하는 정렬방법입니다. 한 단계에 하나의 숫자만 정확한 자리에 위치하는 것이 보장되므로 단순하지만 효율적이지 않은 알고리즘입니다. 시간 복잡도는 O(n^2)입니다.
단계별로 하나의 숫자씩 정확한 위치가 확정되므로 비교하는 횟수가 1씩 줄어듭니다. 차례대로 n + (n-1) + (n-2) … 0번의 비교를 하게 되며 이를 계산하면 (N - 1) x N / 2 이므로 가장 큰 수를 기준으로
O(n^2)이 되는 것입니다.항상 기존 상태와 관계 없이 항상 O(n^2)입니다. 최악, 최선의 경우랄 것이 없습니다.
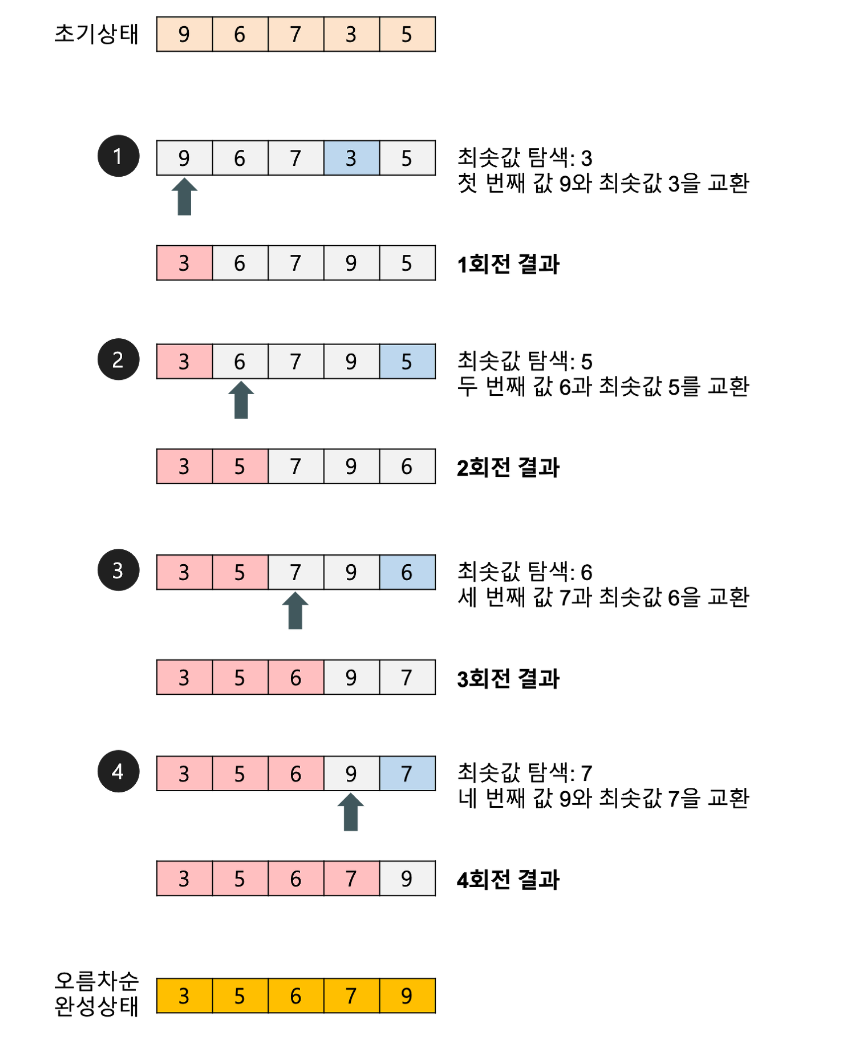
💡선택 정렬(Selection Sort)에 대해 설명해주세요.
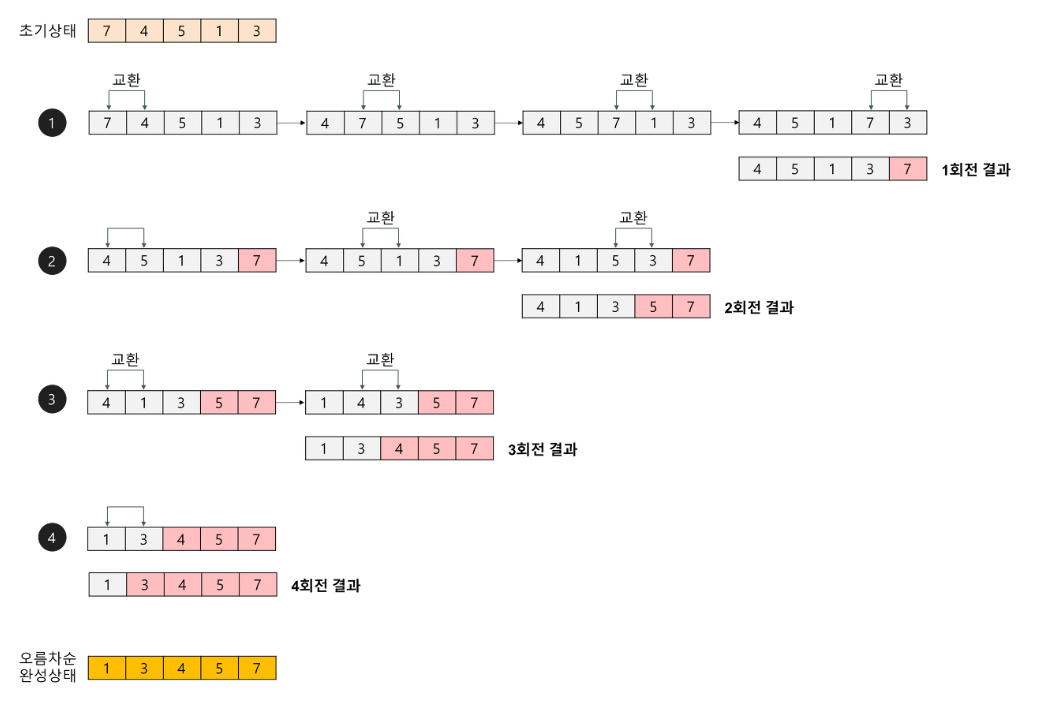
선택 정렬은 첫 번째 값을 두번째 부터 마지막 값까지 차례대로 비교하여 최솟값을 찾아 첫 번째에 놓고 두 번째 값을 세 번째 부터 마지막 값까지 비교하여 최솟값을 찾아 두 번째 위치에 놓는 과정을 반복하며 정렬하는 알고리즘입니다. 최선, 최악이 없고 단계별로 하나의 숫자씩 정확한 위치가 확정되므로 비교하는 횟수가 1씩 줄어듭니다. 차례대로 n + (n-1) + (n-2) … 0번의 비교를 하게 되며 이를 계산하면 (N - 1) x N / 2 이므로 가장 큰 수를 기준으로 시간복잡도는 O(n^2)이 되는 것입니다.
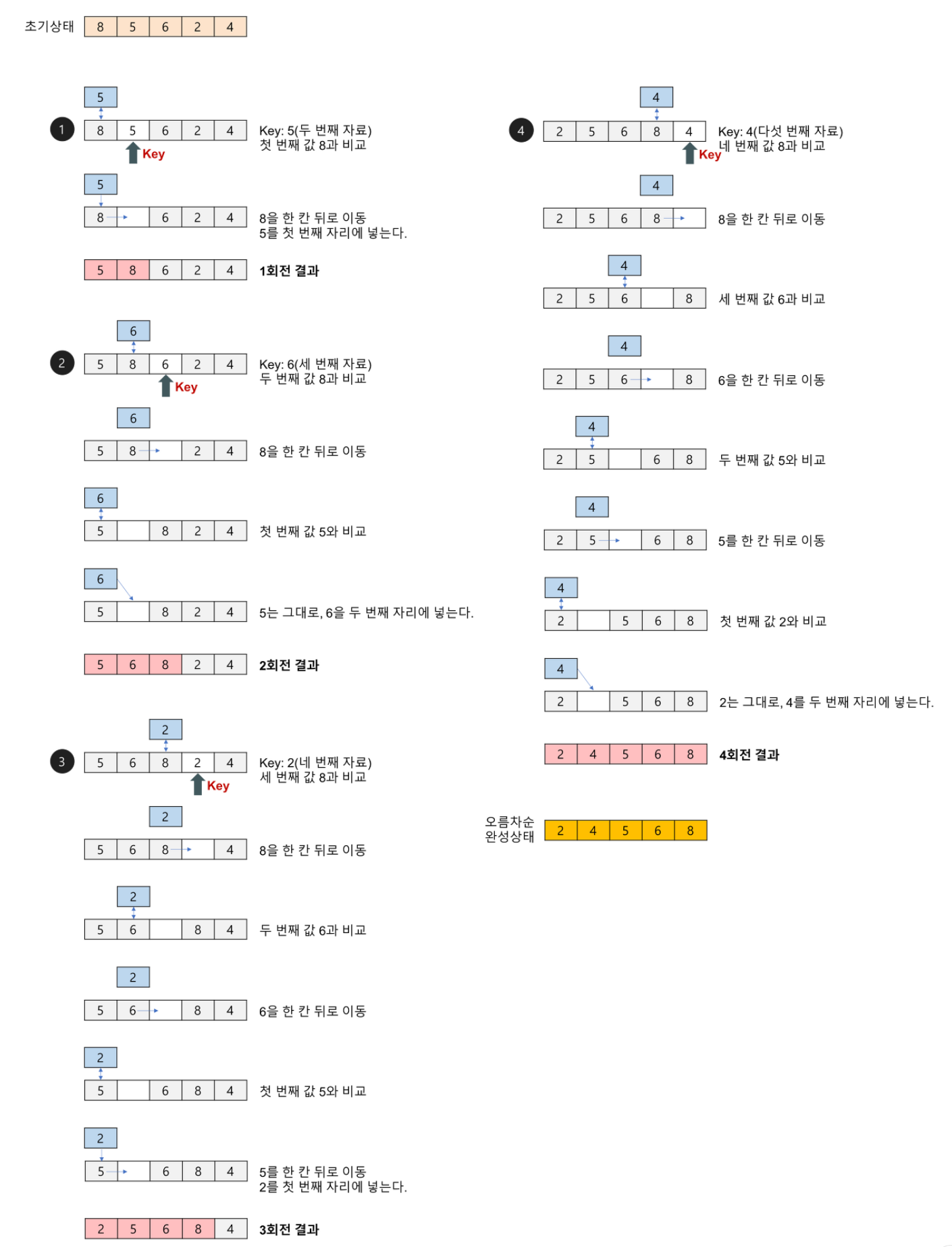
💡삽입 정렬(Injection Sort)에 대해 설명해주세요.
앞의 데이터를 정렬해가며 삽입 위치를 찾아 정렬하는 방식입니다. 첫 인덱스부터 시작해서 다음 인덱스의 값과 현재 값을 비교합니다. 만약 다음 인덱스의 값이 더 크다면 그대로 두고, 더 작다면 현재 값과 스왑합니다. 스왑이 일어났을 때는 해당 숫자와 이전 값들에 대한 비교도 같은 방식으로 이뤄집니다.
평균 시간복잡도는 O(n^2)이며, Best Case 의 경우 O(n)까지 높아질 수 있습니다.
💡힙 정렬(Heap Sort)에 대해 설명해주세요.
힙 정렬은 주어진 데이터를 힙 자료구조로 만들어 최댓값 또는 최솟값부터 하나씩 꺼내서 정렬하는 알고리즘입니다. 힙 정렬이 가장 유용한 경우는 전체를 정렬하는 것이 아니라 가장 큰 값 몇개만을 필요로 하는 경우입니다. 시간 복잡도는 O(nlogn)입니다.
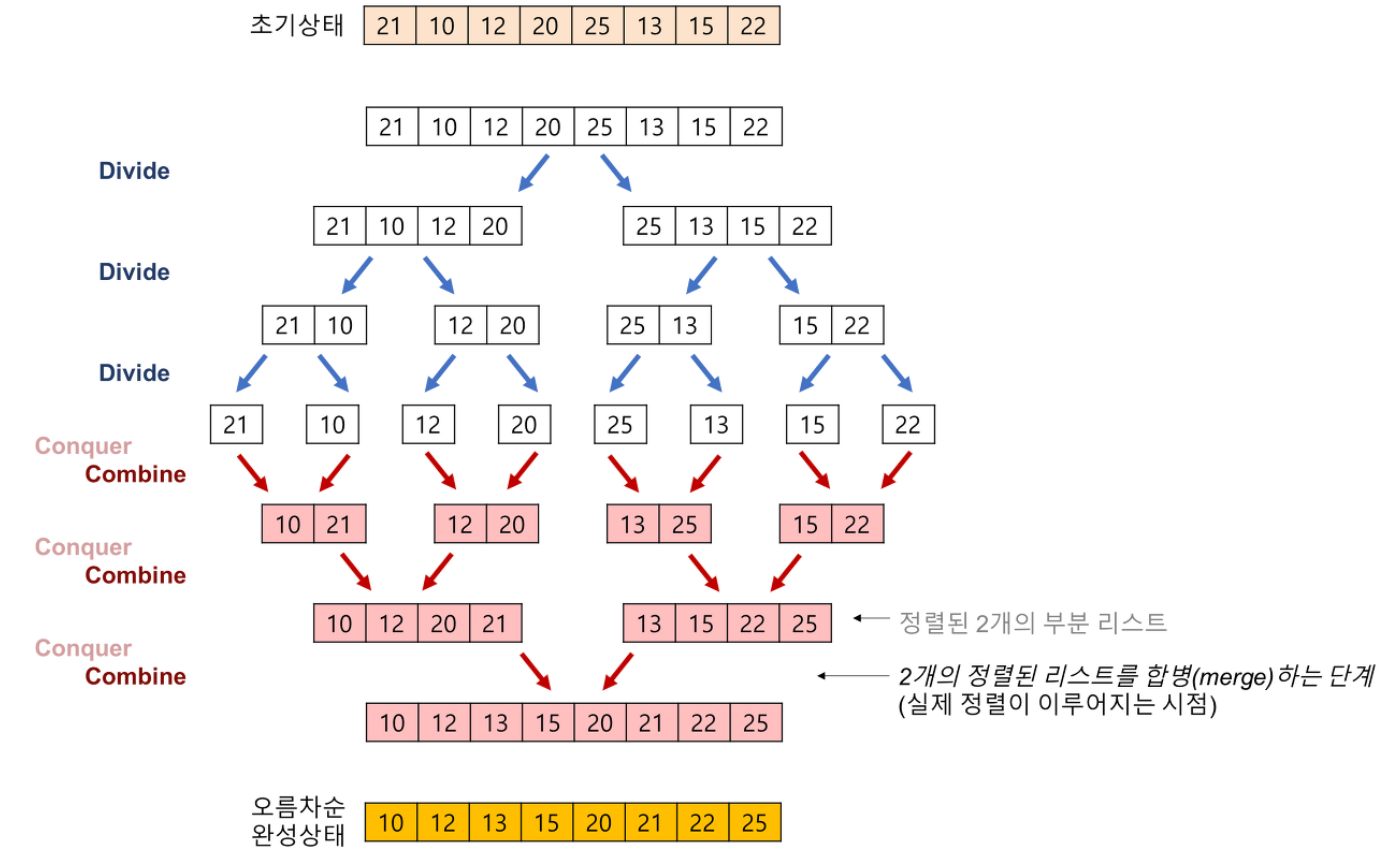
💡병합 정렬(Merge Sort)에 대해 설명해주세요.
-
배열을 계속 분할해서 길이가 1이 되도록 만들고, 인접한 부분끼리 정렬하면서 합병하는 방식입니다.
-
트리 자료구조를 이용합니다.
-
비교하는 두 개의 배열에 인덱스값을 2개 놓고 값을 비교하면서 병합합니다.
-
Linked List를 이용하면 제자리 정렬이 가능하며, 배열을 사용하면 기존 배열의 크기만큼의 메모리가 추가적으로 소모됩니다.
-
배열의 현재 상태에 영향을 받지 않고 최선, 최악의 상황이 따로 없습니다. 시간 복잡도는 O(nlogn)입니다.
💡퀵 정렬(Quick Sort)에 대해 설명해주세요.
퀵 정렬은 빠른 정렬 속도를 자랑하는 분할 정복 알고리즘 중 하나로 피봇을 설정하고 피봇보다 큰 값과 작은 값으로 분할하여 정렬 합니다. 병합정렬과 달리 리스트를 비균등하게 분할합니다.
시간 복잡도는 O(nlogn)이며 worst case 경우 O(n^2)까지 나빠질 수 있습니다.

💡정렬 알고리즘 시간 복잡도 비교 표
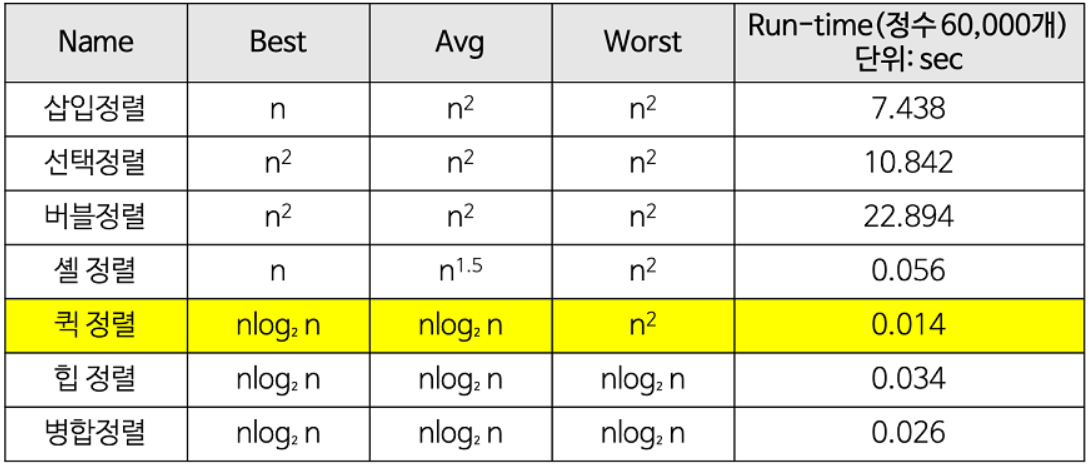
💡Big-O 표기법의 시간 복잡도 크기 순서를 말해주세요.
O(1) < O(log N) < O(N) < O(N log N) < O(N^2) < O(2^N) < O(N!)
💡허프만 코딩에 대해 설명해주세요.
허프만 코딩은 문자의 빈도 수를 가지고 압축하는 과정을 말하며, 접두부 코드와 최적 코드를 사용합니다.
-
접두부 코드 : 각 문자에 부여된 이진 코드가 다른 이진 코드의 접두부가 되지 않는 코드 (즉, 겹치지 않도록 이진 코드를 만드는 것)
-
최적 코드 : 인코딩된 메시지의 길이가 가장 짧은 코드
💡재귀 알고리즘에 대해 설명해주세요.
재귀 알고리즘이란 함수 내부에서 함수가 자기 자신을 또 다시 호출하여 문제를 해결하는 알고리즘입니다. 자기자신을 계속해서 호출하여 끝없이 반복되게 되므로 반복을 중단할 조건이 반드시 필요합니다.
💡피보나치 수열의 N번째 값을 구하는 메소드에 대해 각각 재귀와 반복문으로 손코딩(또는 수도코딩) 해주세요.
private static int recursiveFibonacci(int index) {
if (index <= 2){
return 1;
}
return recursiveFibonacci(index - 1) + recursiveFibonacci(index - 2);
}
private static int loopFibonacci(int index) {
int answer = 1;
int before = 1;
int temp;
for (int i = 2; i < index; i++) {
temp = answer;
answer += before;
before = temp;
}
return answer;
}💡팩토리얼의 N번째 값을 구하는 메소드에 대해 각각 재귀와 반복문으로 손코딩(또는 수도코딩) 해주세요.
private static int recursiveFactorial(int num) {
if(num > 1) {
return recursiveFactorial(num -1) * num;
}
return 1;
}
private static int loopFactorial(int num) {
int answer = 1;
for(int i = 2; i <= num; i++) {
answer *= i;
}
return answer;
}💡이진탐색트리(BST)에 대해 아는 대로 설명하시오
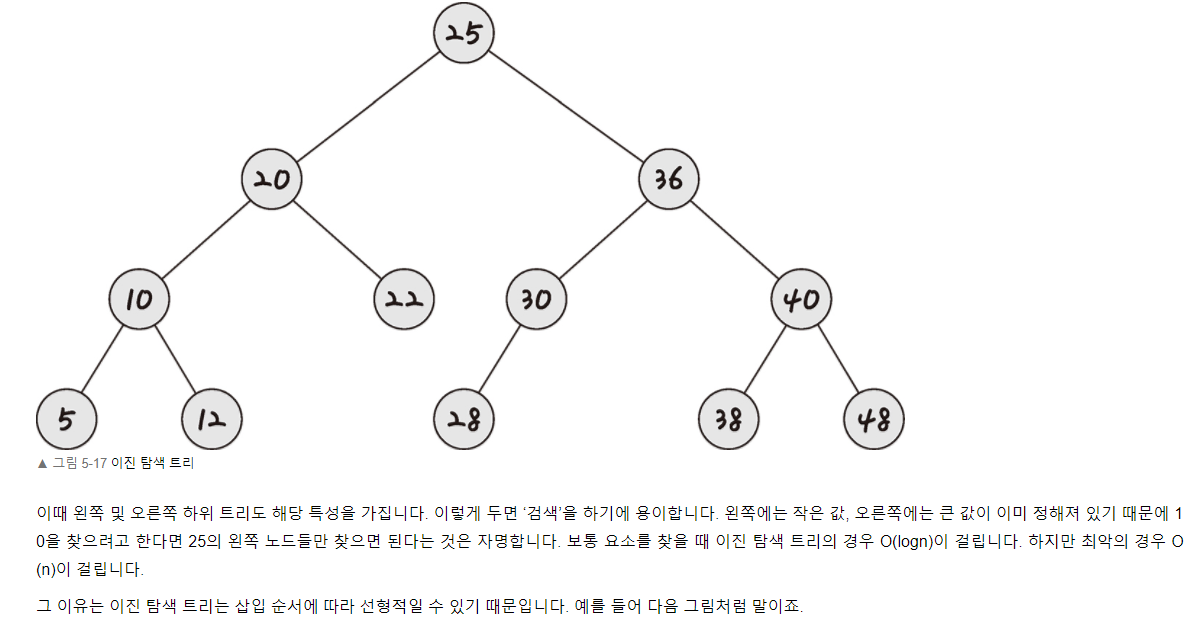
이진탐색트리는 노드의 오른쪽 하위 트리에는 노드 값보다 큰 값이, 왼쪽 하위 노드 트리에는 노드 값보다 작은 값이 들어있는 이진트리를 말합니다. 빠른 검색에 적합한 자료구조로, 시간복잡도는 평균적으로 O(logn)이며, 최악의 경우 O(n)입니다.
-
최악의 경우는 언제 발생하나?
- 데이터의 삽입 순서에 따라 이진탐색트리의 데이터가 선형적으로 저장될 수 있습니다(편향트리). 이런 상황에서는 O(n)의 시간복잡도가 발생할 수 있습니다.
- 이런 한계를 극복하기 위한 자료구조도 존재하며, AVL 트리와 레드블랙트리가 대표적입니다.
-
AVL 트리에 대해 간략히 설명해봐라
스스로 균형을 잡는 이진 탐색 트리입니다. 두 자식 서브트리의 높이는 항상 최대 1만큼 차이난다는 특징이 있습니다. 탐색, 삽입, 삭제 모두 시간 복잡도가 O(logn)입니다.
-
레드블랙트리에 대해 간략히 설명해보세요
레드블랙트리도 균형 이진탐색트리입니다. 각 노드의 색은 Red 또는 Black으로 구성되며, 루트노드의 부모와 리프노드의 자식들은 다 NIL노드로 구성됩니다. 루트노드와 리프노드, NIL노드는 모두 Black이고, Red노드의 자식들은 Black입니다. 루트노드에서 리프노드 까지의 모든 경로에는 동일한 개수의 Black노드가 존재합니다.
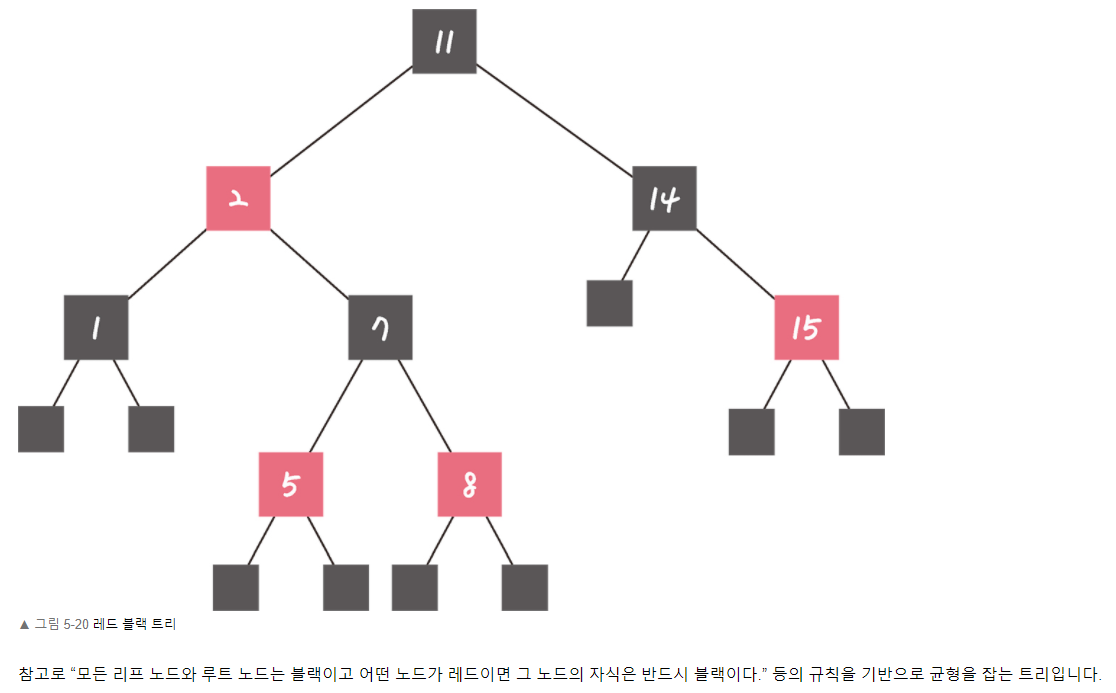
💡레드블랙트리에 대해 아는 대로 설명하시오.
-
BST를 기반으로 하는 자료구조로, AVL 트리와 마찬가지로 스스로 밸런스를 잡는 자료구조입니다. 그렇기 때문에 BST와 같이 최악의 경우가 발생하지 않으며 시간복잡도는 언제나 O(logn)입니다.
-
각 노드는 Red 또는 Black의 색을 갖습니다. 루트 노드와 리프노드는 언제나 블랙이며 어떤 노드의 색이 레드라면 그 노드의 자식노드는 블랙입니다. 또한, 특정 노드로부터 리프 노드까지의 블랙 노드 개수는 동일합니다.
💡기수 정렬(Radix Sort)에 대해 설명하시오.
- 0-9까지의 숫자를 나타내는 버킷에 특정 자릿수를 기준으로 값을 넣었다 빼며 정렬하는 방식입니다.
- 0-9까지의 버킷을 만듭니다. Queue 자료구조.
- 1의 자리숫자 기준으로 숫자에 해당하는 버킷에 집어넣습니다.
- 0-9까지의 버킷에서 모든 숫자를 빼냅니다.
- 10의 자리숫자 기준으로 숫자에 해당하는 버킷에 집어넣습니다.
- 0-9까지의 버킷에서 모든 숫자를 빼냅니다.
- 이를 마지막 자릿수까지 반복합니다.
시간복잡도는 O(dn)입니다.
💡크루스칼 알고리즘에 대해 아는 대로 설명하시오.
-
최소 신장 트리를 구하기 위한 알고리즘입니다. 최소 신장 트리는 모든 노드를 연결하면서도 가장 가중치가 작은 간선만을 포함하는 트리를 말합니다.
-
크루스칼 알고리즘에서는 첫째로 노드의 가중치가 낮은 순서로 정렬을 합니다. 그리고 노드를 하나씩 검사하며 추가해줍니다. 이 때, union, find를 사용해서 사이클이 발생하는지 확인하고 만약 발생하지 않는다면 추가하는 방식으로 동작합니다.
💡BST(Binary Search Tree)와 Binary Tree에 대해 설명해주세요.
이진트리(Binary Tree)는 자식 노드가 최대 두 개인 노드들로 구성된 트리이고, 이진 탐색 트리(BST)는 이진 탐색과 연결 리스트를 결합한 자료구조입니다. 이진 탐색의 효율적인 탐색 능력을 유지하면서, 빈번한 자료 입력과 삭제가 가능하다는 장점이 있습니다. 이진 탐색 트리는 왼쪽 트리의 모든 값은 반드시 부모 노드보다 작아야 하고, 오른쪽 트리의 값은 부모 노드보다 커야 하는 특징이 있습니다. 이진 탐색 트리의 탐색 연산은 트리의 높이에 영향을 받아 높이가 h일 때 시간 복잡도는 O(h)이며, 트리의 균형이 한쪽으로 치우쳐진 경우 worst case가 되고 O(n)의 시간 복잡도를 가집니다. 이런 worst case를 막기 위해 나온 기법이 RBT(Red-Black Tree)입니다.
💡RBT(Red-Black Tree)에 대해 설명해주세요.
RBT(Red-Black Tree)는 BST를 기반으로 하는 트리 형식 자료구조이며, RBT는 BST의 삽입, 삭제 연산 과정에서 발생할 수 있는 문제점을 해결하기 위해 만들어졌습니다. BST를 기반으로 하기 때문에 당연히 BST의 특징을 모두 갖습니다. 노드의 child가 없을 경우 child를 가리키는 포인터는 NIL 값을 저장합니다. 이러한 NIL들을 leaf node로 간주합니다. 모든 노드를 빨간색 또는 검은색으로 색칠하며, 연결된 노드들은 색이 중복되지 않습니다.

