DataBase
데이터베이스(DB)는 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터의 모음입니다. 해당 데이터베이스를 제어, 관리하는 통합 시스템을 DBMS(DataBase Management System)라고 하며, 데이터베이스 안에 있는 데이터들은 특정 DBMS마다 정의된 쿼리 언어를 통해 삽입, 삭제, 조회 등을 수행할 수 있습니다. 또한 데이터베이스는 실시간 접근과 동시 공유가 가능합니다.
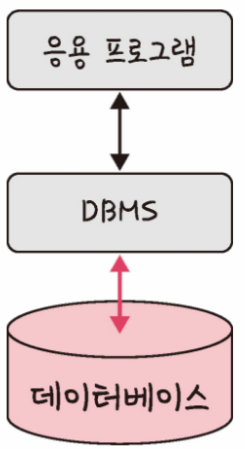
데이터베이스 위에 DBMS가 있고 그 위에 프로그램이 있으며 이러한 구조를 기반으로 데이터를 주고받습니다. 예를 들어, MySQL이라는 DBMS가 있습니다.
릴레이션
릴레이션은 데이터베이스에서 정보를 구분하여 저장하는 기본 단위입니다. 엔티티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리합니다.
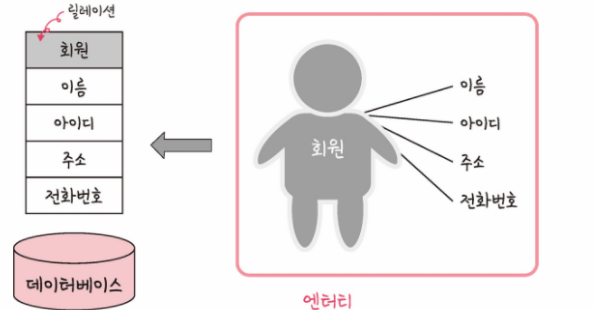
회원이라는 엔티티가 데이터베이스에서 관리될 때 릴레이션으로 변화된 것을 볼 수 있습니다. 릴레이션은 관계형 데이터베이스에서는 테이블이라고 하며, NoSQL 데이터베이스에서는 컬렉션이라고 합니다.
테이블과 컬렉션
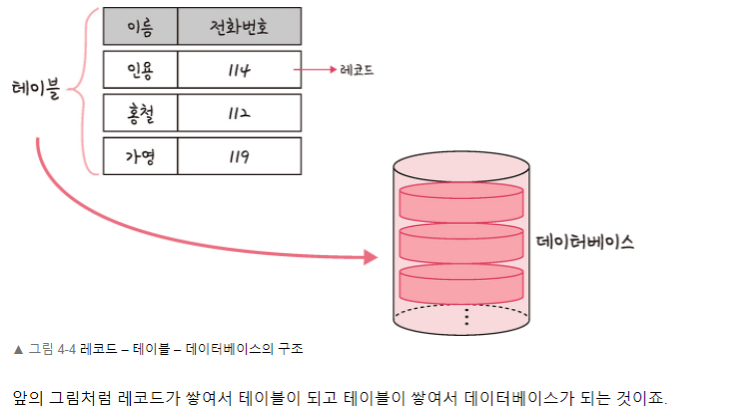
데이터베이스의 종류는 크게 관계형 데이터베이스와 NoSQL 데이터베이스로 나눌 수 있습니다. 이 중 대표적인 관계형 데이터베이스인 MySQL과 NoSQL인 데이터베이스인 MongoDB를 예를 들면, MySQL의 구조는 레코드-테이블-데이터베이스로 이루어져 있고 MongoDB 데이터베이스 구조는 도큐먼트-컬렉션-데이터베이스로 이루어져 있습니다.
속성
속성(attribute)는 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보입니다. 예를 들면, 차라는 엔티티의 속성을 뽑아보면 차 넘버, 바퀴 수, 차 색깔, 차종 등이 있다. 이 중에서 서비스의 요구 사항을 기반으로 관리해야할 필요가 있는 속성들만 엔티티의 속성이 됩니다.
도메인
도메인이란 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합을 말합니다. 예를 들면, 성별이라는 속성이 있다면 이 속성이 가질 수 있는 값은 남, 여라는 집합이 됩니다.

회원이라는 릴레이션에 이름, 아이디, 주소, 전화번호, 성별이라는 속성이 있고 성별은 {남, 여}라는 도메인을 가지는 것을 알 수 있습니다.
필드와 레코드
필드와 레코드로 구성된 테이블을 만들 수 있습니다.

회원이란 엔티티는 member라는 테이블로 속성인 이름, 아이디 등을 가지고 있고 이 테이블에 쌓이는 행(row) 단위의 데이터를 레코드라고 합니다. 또한 레코드를 튜플이라고도 합니다.
필드 타입
필드는 타입을 갖습니다. 예를 들어, 이름은 무자열이고 전화번호는 숫자인데 이러한 타입들은 DBMS마다 다릅니다.
숫자 타입
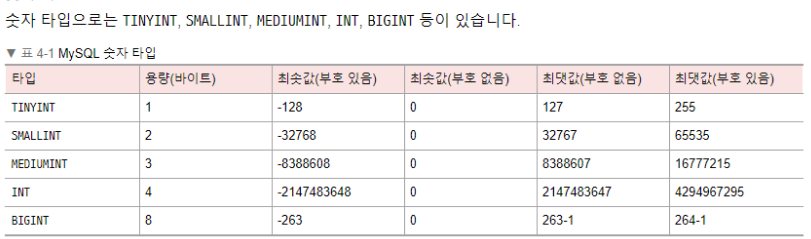
날짜 타입
DATE, DATETIME, TIMESTAMP 등이 있습니다.
-
DATE
날짜 부분은 있지만 시간 부분은 없는 값에 사용합니다. -
DATETIME
날짜 및 시간 부분을 모두 포함하는 값에 사용합니다. -
TIMESTAMP
날짜 및 시간 부분을 모두 포함하는 값에 사용합니다.
문자 타입
문자 타입으로는 CHAR, VARCHAR, TEXT, BLOB, ENUM, SET이 있습니다.
-
CHAR 또는 VARCHAR 모두 그 안에 수를 입력해서 몇 자까지 입력할지 정합니다. CHAR는 고정 길이 문자열이며 길이는 0에서 255 사의 값을 가집니다.
-
VARCHAR는 가변 길이 문자열입니다. 길이는 0에서 65,535 사이의 값으로 지정할 수 있고 입력된 데이터에 따라 용량을 가변시켜 저장합니다.
-
TEXT, BLOB는 큰 데이터를 저장할 때 쓰는 타입입니다.
TEXT는 큰 문자열 저장에 쓰며 주로 게시판 본문을 저장할 때 사용합니다. BLOB은 이미지, 동영상 등 큰 데이터 저장에 씁니다. 그러나 보통 S3를 이용하는 등 서버에 파일을 올리고 파일에 대한 경로를 VARCHAR로 저장합니다.
-
ENUM과 SET 모두 문자열을 열거한 타입

관계
데이터베이스에 테이블은 하나만 있는 것이 아닙니다. 여러개의 테이블이 있고 이러한 테이블은 서로의 관계가 정의되어 있습니다.



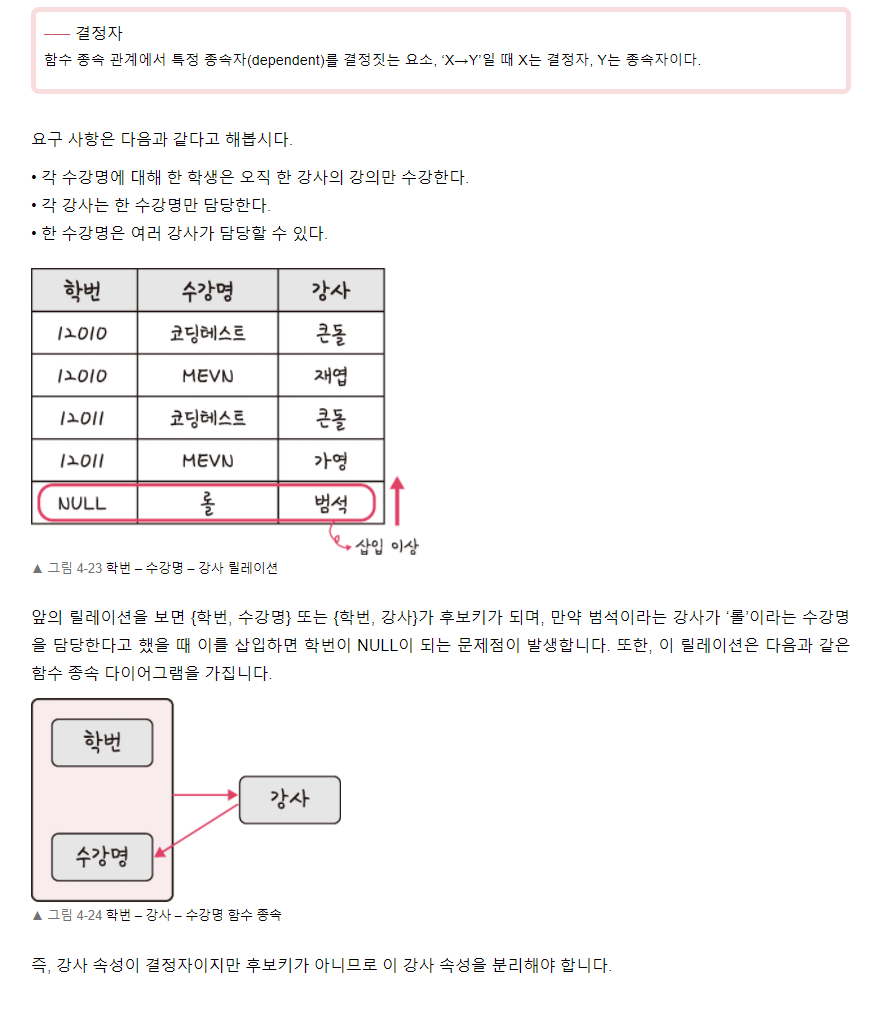

행(Row, 레코드, 튜플, ...)
- 하나의 대상에 대한 데이터
- 그 줄에 모든 데이터는
같은 대상에 대한 데이터들이다.
열(Column, 속성, 필드, ...)
-
공통된 값들의 주제 -
그 열의 모든 데이터는 모두
같은 속성의 데이터들이다.
테이블 간의 관계
테이블 간의 관계는
1:1,1:N,N:M(여러개랑 여러개)의 관계들이 있다.
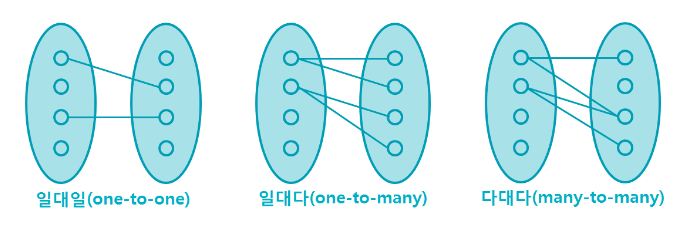

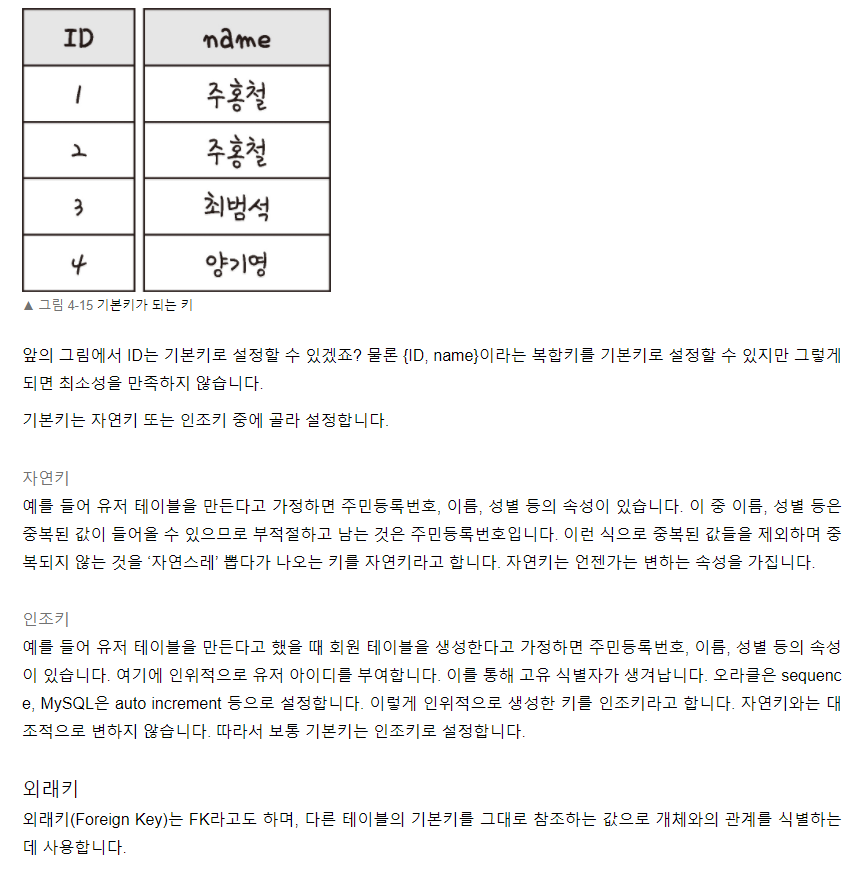
위 그림처럼 여러명의 학생과 여러개의 수업을 테이블로 나타내면 경우의 수가 엄청 많아져서 찾을 때 매우 어려워지게 된다. 따라서, 각 테이블에는 해당 테이블에 필요한 정보를 나타내도록 하고 테이블 행을 식별할 수 있는 것만 뽑아내서 두 테이블의 관계를 표현하는 아래 그림과 같이 관계를 나타내주는 새 테이블을 만들어 1:N관계로 나눠준다.

이렇게 하면 학생들의 정보와 수업들의 정보를 담은 두 테이블과 학생_수업과의 관계를 나타내는 테이블이 만들어 지며 학생테이블과 학생-수업테이블 / 수업테이블과 학생-수업 테이블은 각각 1:N관계를 가지게 된다.
위 그림에서 이러한 관계를 표현하는 과정에서 눈에 띄는 것이 PK, FK이다. 그림에서 학생-수업 테이블은 학생테이블과 수업테이블의 관계를 1:N 관계로 나타내기위한 테이블이므로 학생테이블과 수업테이블을 참조하여 만들어야 한다. 그러기 위해서 학생정보를 식별하는 학생코드(PK), 수업정보를 식별하는 수업코드(PK)로 테이블이 구성되며 이렇게 다른 테이블의 정보를 참조하기위한 학생코드와 수업코드는 학생_수업테이블 내에서 FK(외래키)가 된다.
학생과 수업 테이블의 PK가 학생-수업 테이블에서는 FK가 되며이는 학생-수업테이블은 학생과 수업테이블을 참조하는 테이블이라는 의미를 표현하며 동시에 학생과 수업테이블은 학생-수업테이블에 의해 참조되는 테이블로 서로의 관계를 알 수 있게 된다.
트랜잭션과 무결성




무결성
데이터베이스의 종류
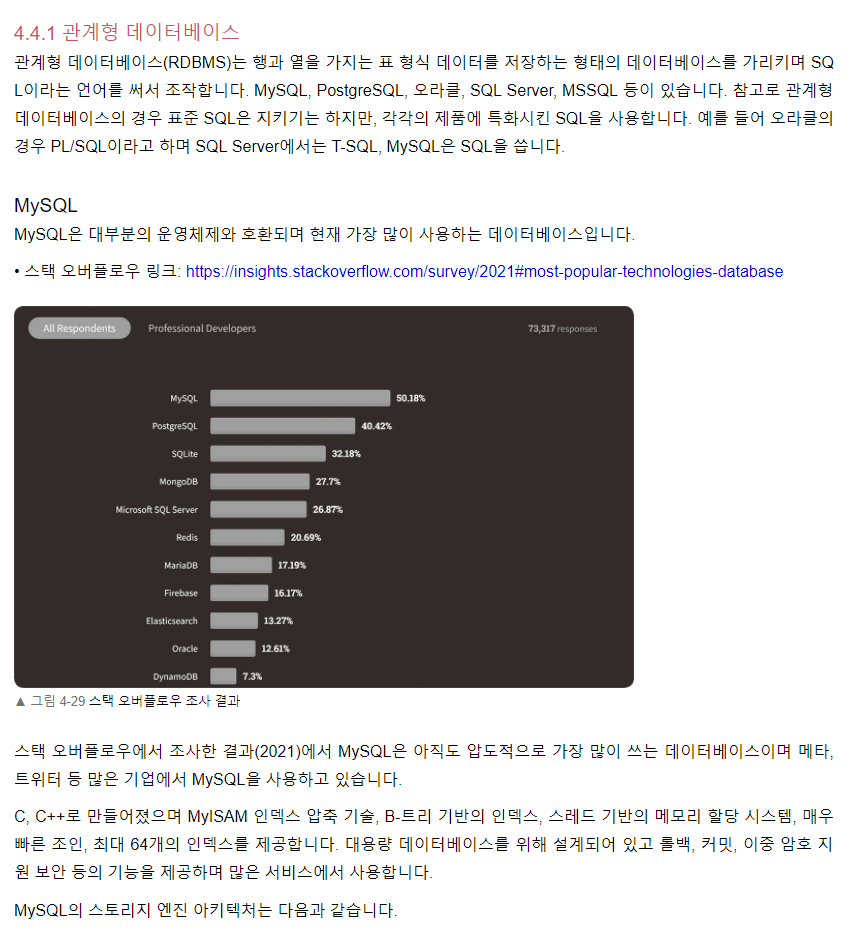

인덱스


조인의 종류
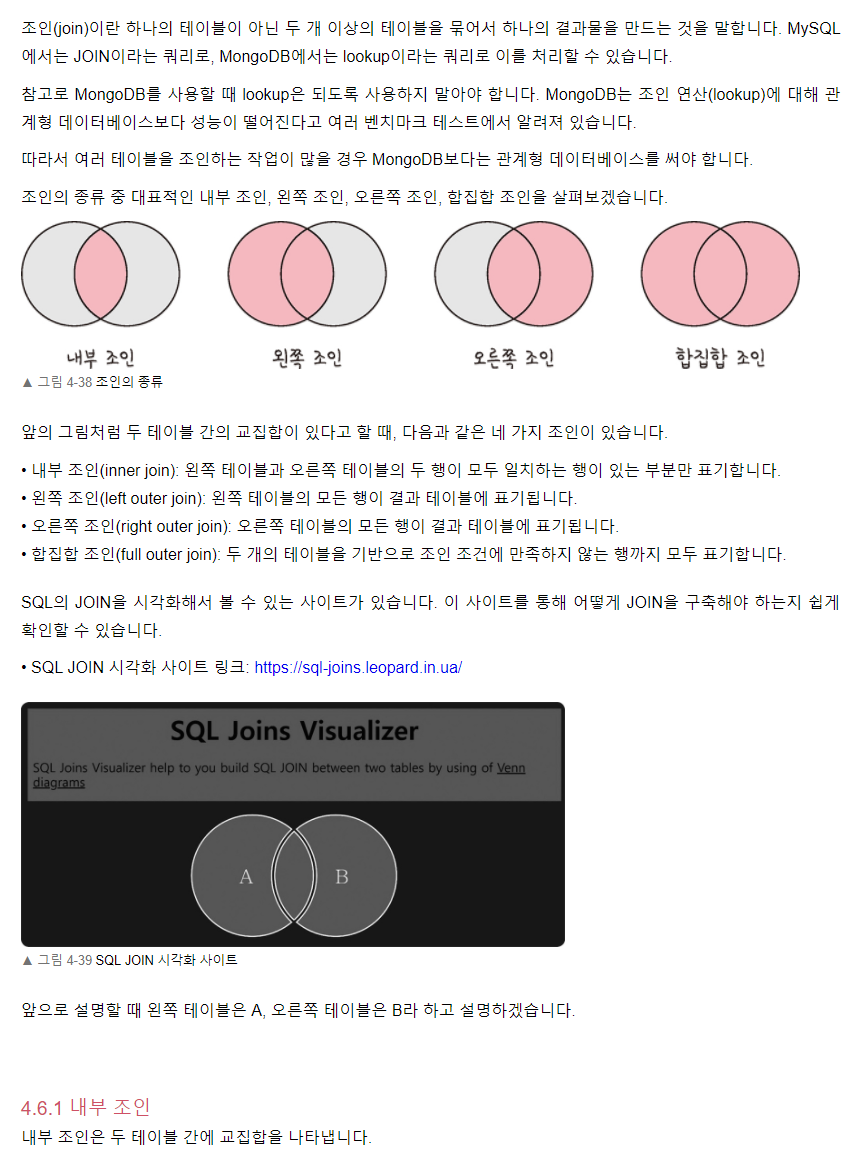
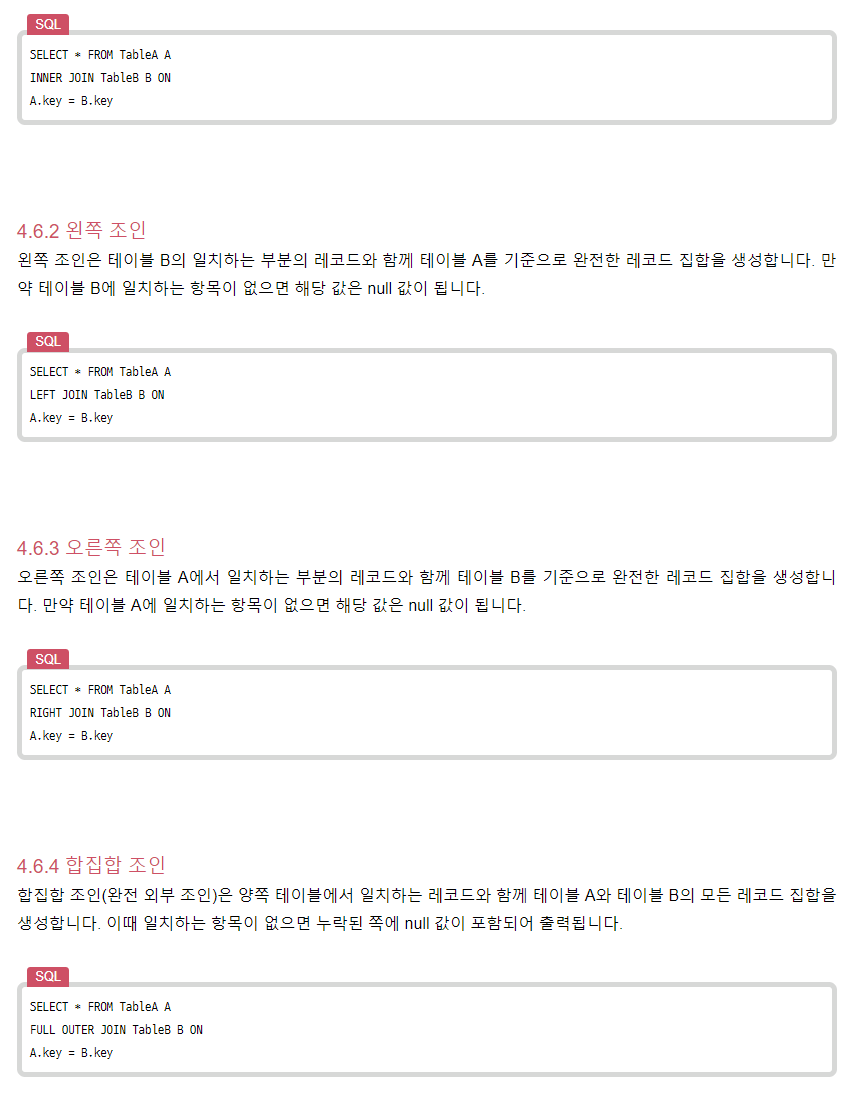
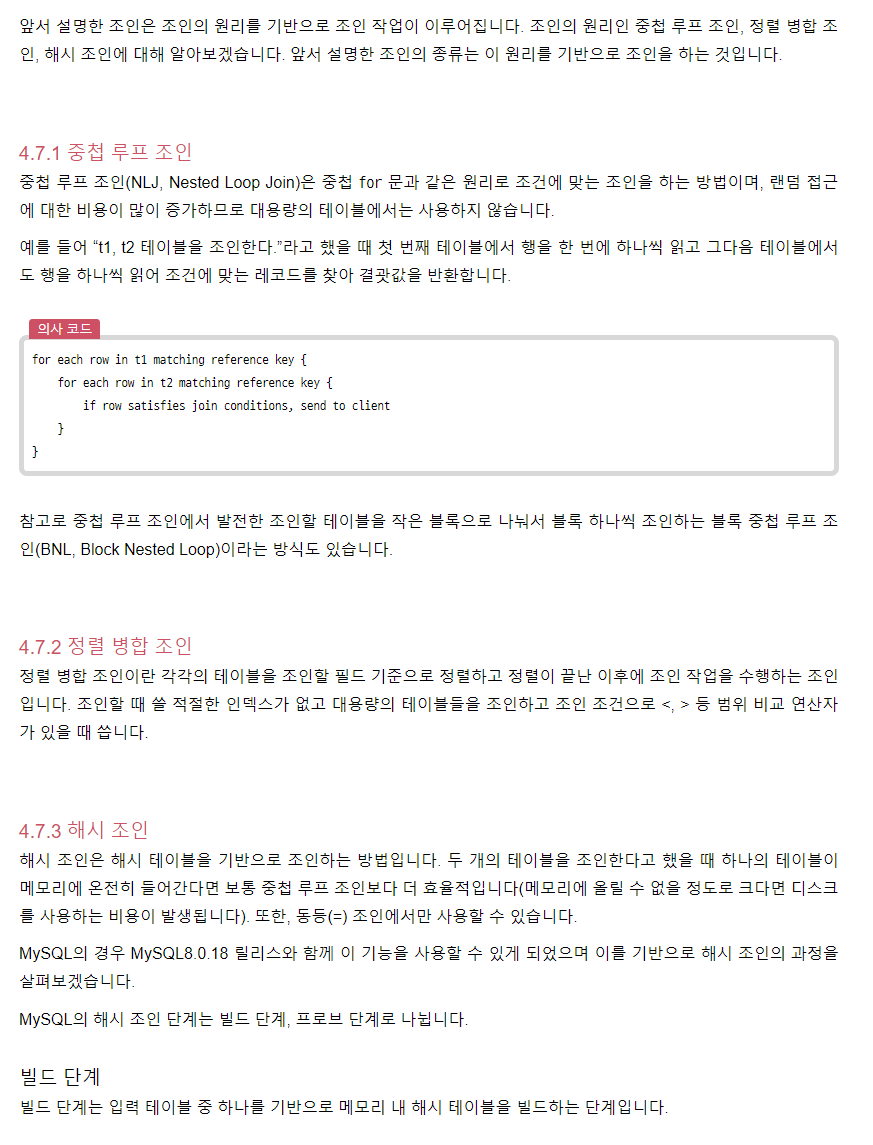
조인의 원리
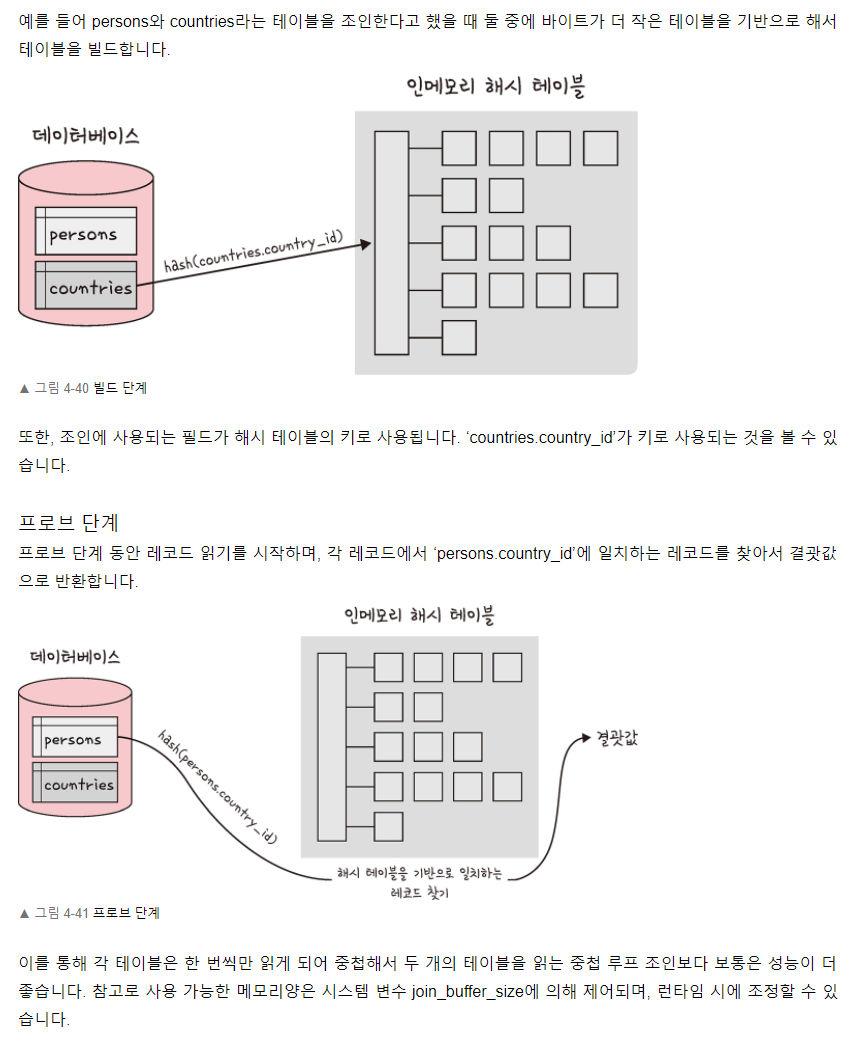
데이터베이스는 무엇인가요?

데이터베이스를 사용하는 이유?
데이터베이스를 사용하면 많은 양의 데이터를 효율적으로 사용할 수 있습니다. 업데이트 데이터를 쉽고 안정적으로 만들 수 있고 정확도를 보장하는 데도 도움이 됩니다. 정보에 대한 액세스를 제어하는 보안 기능을 제공하며 중복을 피하는 데 도움이 됩니다. 이전 파일시스템의 데이터 종속성 문제와 중복성, 무결성 문제를 해결하기 위해 데이터 베이스를 사용한다. 데이터 베이스는 다음과 같은 특징을 가진다.
- 데이터 독립성
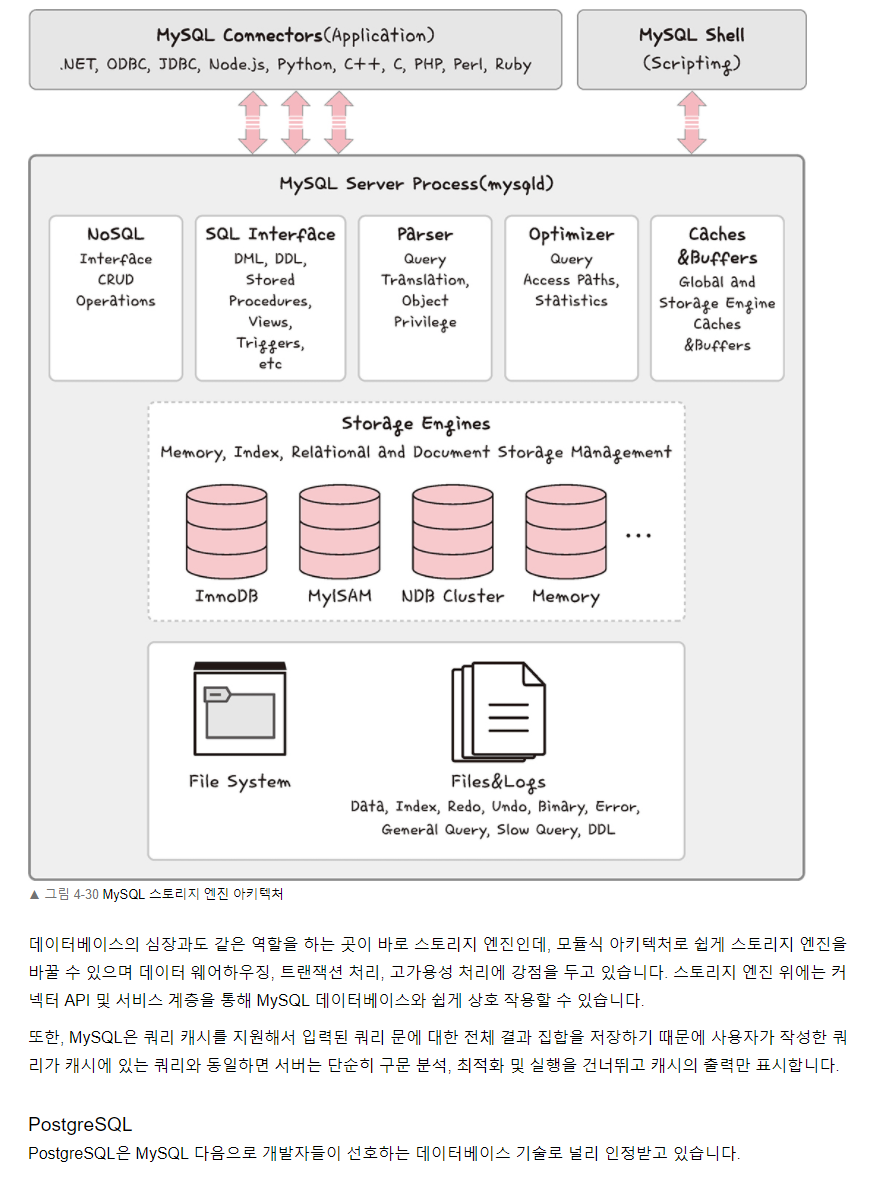
- 데이터의 무결성
- 데이터의 보안성
- 데이터의 일관성
- 데이터의 중복 최소화
데이터베이스의 특징에 대해 설명해주세요.

중첩 루프 조인이 무엇인가요?

인덱스를 매 필드마다 설정하는 것이 좋을까요?

인덱스란?
빠른 데이터 검색을 위해 컬럼의 값과 해당 레코드가 저장된 주소를 key-value 쌍으로 인덱스를 만들어두는 것이다.
인덱스가 왜필요할까?
데이터는 디스크로부터 가져오게 된다. 자주 쓰일 경우 매번 조회하는 것은 비효율적이므로 컴퓨터는 자주 사용되는 테이블을 메모리에 올린다. 메모리에 데이터가 있다면 빠르게 가져올 수 있지만 없다면 디스크 전체를 스캔해야하며 이것을 풀 테이블 스캔이라고 한다. 대용량 데이터일 경우 비효율적이다. 이를 해결하기 위해 인덱스를 사용하며 인덱스는 메모리에 저장된다.
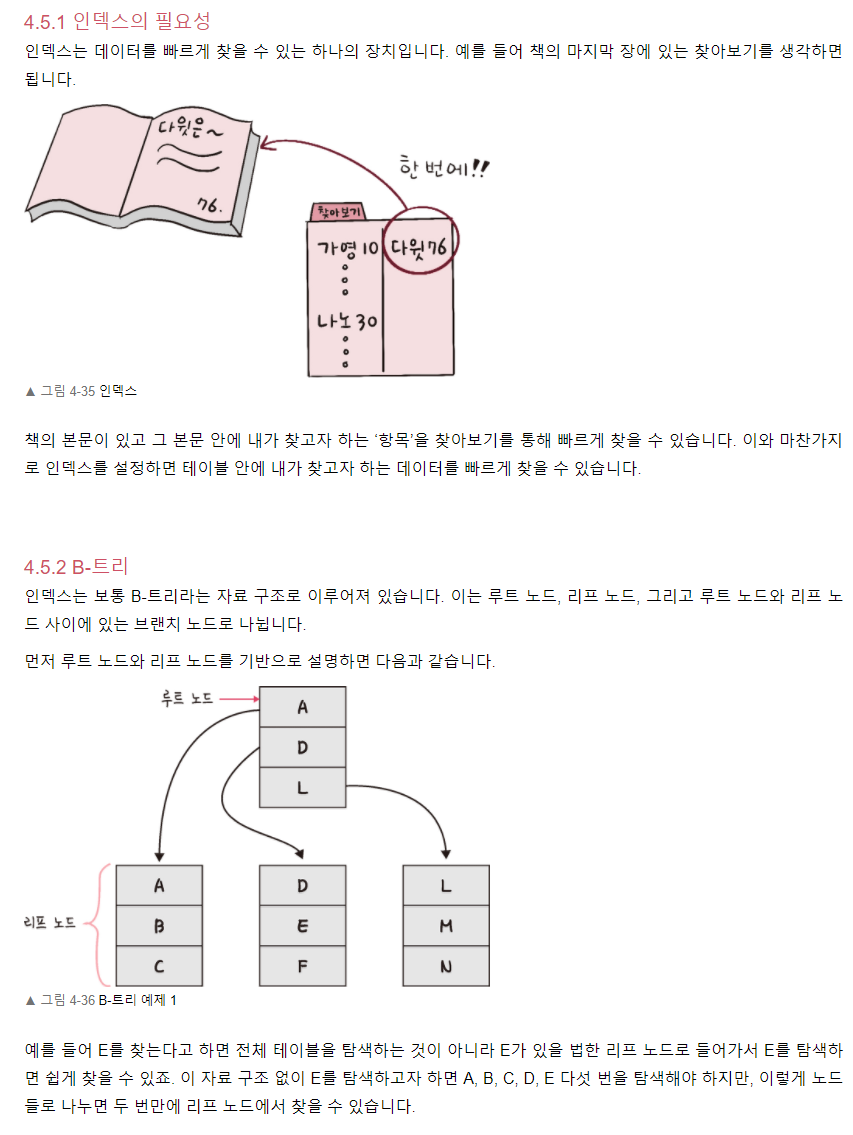
인덱스의 구조와 원리
인덱스에서 가장 많이 사용되는 구조는 B-tree이다. B-tree는 이진 트리의 변형으로 자식 노드가 최대 2인 이진트리와 달리 B-tree는 자식 노드의 개수를 2개 이상으로 가진다.
B-tree에서 자료의 탐색은 수직적 탐색과 수평적 탐색으로 이루어진다.
인덱스를 언제 쓰는게 좋을까?
인덱스는 조건이 붙은 조회를 할 때는 매우 효율적이지만 삽입, 삭제, 수정일 때는 오히려 성능을 저하시킨다. 인덱스는 정렬된 상태로 데이터를 저장해야하기 때문이다.
사용하면 좋은 경우는 다음과 같습니다.
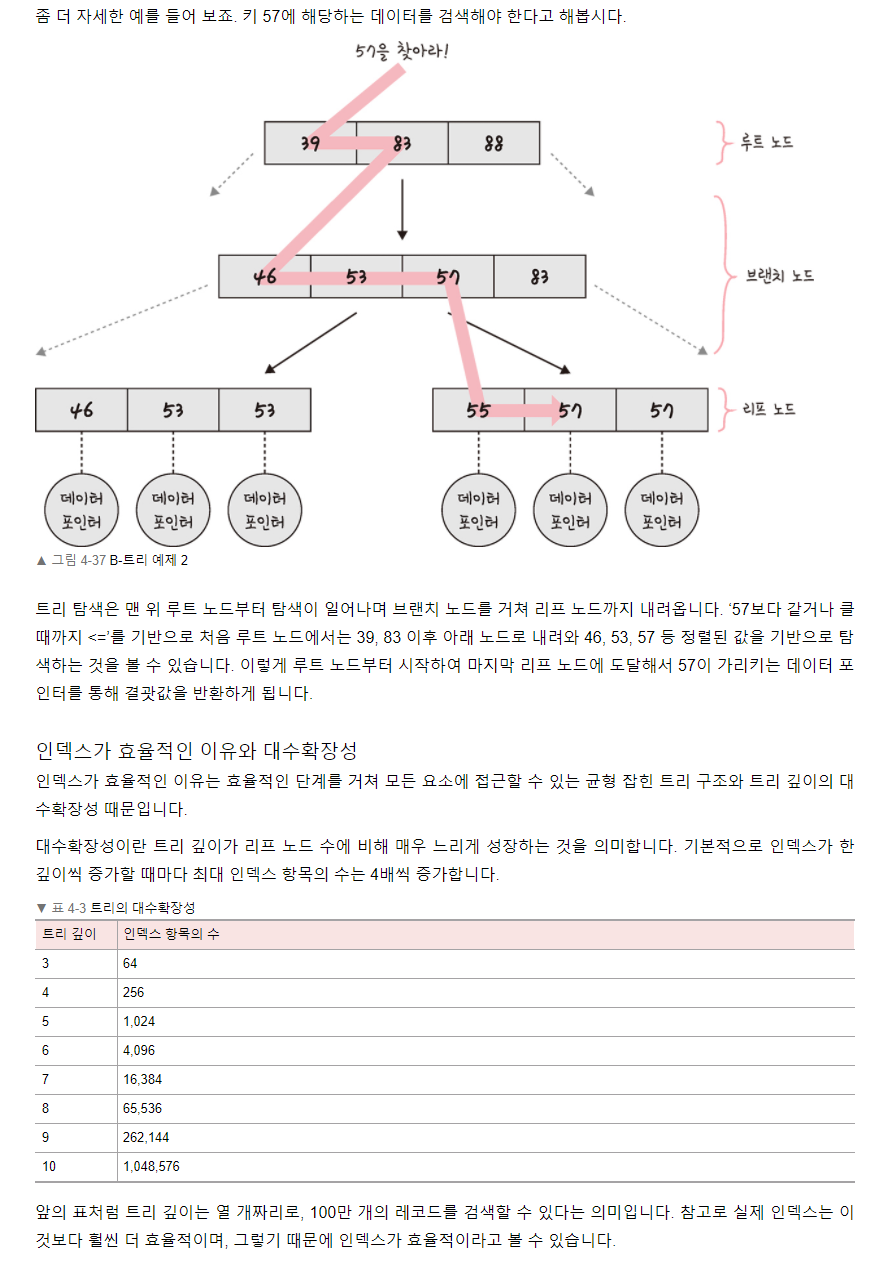
- where 절에서 자주 사용되는 컬럼
- 외래키가 사용되는 컬럼
- join에 자주 사용되는 컬럼
MySQL 8.0 특징
-
데이터 딕셔너리 업그레이드
MySQL 5.7 버전까지는 데이터 딕셔너리 정보가 FRM 확장자를 가진 파일로 별도로 보관됐었는데, MySQL 8.0 버전부터는 데이터 딕셔너리 정보가 트랜잭션이 지원되는 InnoDB 테이블로 저장되도록 개선됐다. 데이터 딕셔너리 업그레이드는 기존의 FRM 파일의 내용을 InnoDB 시스템 테이블로 저장한다. MySQL 8.0 버전부터는 딕셔너리 데이터의 버전 간 호환성 관리를 위해 테이블이 생성될 때 사용된 MySQL 서버의 버전 정보도 함께 기록한다.
-
서버 업그레이드
MySQL 서버의 시스템 데이터베이스(performance_schema와 information_schema, 그리고 mysql 데이터베이스)의 테이블 구조를 MySQL 8.0 버전에 맞게 변경한다.
5.7 vs 8.0 차이점
- 사용자 인증방식 변경
- 외래키 이름의 길이(64bit)
- MySQL 8.0과의 호환성 체크
- 인덱스 힌트
- group by에 사용된 정렬 옵션
- 파티션을 위한 공용 테이블 스페이스
UNION vs UNION ALL
UNION과 UNION ALL 모두 여러개의 SQL문을 합쳐 하나의 SQL문을 만들어 준다. 그러나 차이점이 있다.
UNION
두 쿼리의 결과 중에서 중복되는 값을 삭제하여 나타낸다.
UNION ALL
- 두 쿼리의 결과 중에서 중복되는 값을 모두 보여준다.
- 중복체크를 하지 않기 때문에 속도가 더 빠르다.
PK의 특징
-
엔티티를 식별하는 대표 key
-
table당 1개만 지정해야 한다.
-
각 데이터들의 고유한 값(각 데이터들의 구별점 역할)
-
중복이 없고, 비어있지 않음
-
주 식별자키로 테이블의 모든 데이터를 식별하는 컬럼
-
중복 불가, NULL 불가
-
함수적 종속 관계
1. 기술적인 의미
-
기본키는 다른 항목과 절대로 중복되어 나타날 수 없는 단일 값(
unique)을 가집니다. -
기본키는 절대 null(
아무런 값이 없는 상태) 값을 가질 수 없습니다.ex) 예를 들면 주민등록번호 같은 개념이죠. 동일한 이름을 가진 사람은 많을 수 있고, 동일한 날에 동일한 이름을 가진 사람도 존재할 수 있지만, 결국 그 사람들이 만나 서로의 민증을 대조해 보면.... 결국 다른 번호로 구분 됩니다.
-
기본키는 하나 이상의 컬럼이 그룹화 되어 키본키로도 쓰일 수도 있습니다.
2. 암묵적 성격
-
기본키를 추가할 때에는 기본키가 되는 컬럼 또는 컬럼의 그룹에 대하여 자동으로 단일의 B-트리 인덱스가 생성됩니다.
-
테이블은 기본키를 하나까지만 가질 수 있습니다.
-
기술적 측면에서 기본키는 단일 값(Unique)하고 not Null(Null 값 비허용)이면 기능적으로 동일하게 동작은 하지만, 실제적으로 기본키처럼 구분되는건 오직 하나입니다. 즉, 다 똑같은 Unique하고 not Null 이라고 기본키가 되는게 아닙니다.
-
관계형 DB 이론상 모든 테이블은 반드시 하나의 기본 키를 가져야 합니다.
FK의 특징
-
외래키(외부식별자키)
-
테이블끼리 관계를 맺을 때 받아오는 다른 테이블의 키(보통 PK)
- 테이블 간의 관계 의미
- 두 테이블 간의 종속이 필요한 관계이면 그 접점이 되는 컬럼을 FK로 지정하여 서로 참조할 수 있도록 관계를 맺어준다.
-
다른 테이블의 PK를 참조하는 키. 참조하는 PK와 동일한 domain을 갖는다.
-
중복 데이터 제거를 위해 테이블을 분리할 때, 반드시 필요한 개념
-
한 테이블에 존재하는 다른 테이블의 정보이기 때문에 외래키라고 부른다.
-
테이블 간 잘못된 매핑을 방지하는 역할
외래키의 역할
- 두 테이블을 연결해 주는
다리 역할을 한다. - 참조하는 테이블의 무결성을 높여 준다 (참조무결성)
create table dish (
id varchar(5) not null,
main_image varchar(100) not null,
...
stock int not null,
point int not null,
primary key (id),
foreign key (category_id) references category (id)
);사용
constraint 제약조건명 foregin key(부여할 컬럼) references 참고 테이블(부여할 컬럼)
# 부모 테이블 create table owner( id varchar(300) primary key, name varchar(300), phone varchar(300), age int, addr varchar(1000) ); # 자식 테이블 create table car( carnum varchar(300) primary key, brand varchar(300), color varchar(300), price int, id varchar(300), constraint car_owner_fk foreign key(id) references owner(id) );
테이블 생성, 삭제, 수정
DDL
Data Definition Language
- 데이터 정의어
- 테이블 관련 쿼리문
- create : 테이블 생성
- drop : 테이블 삭제
- alter : 테이블 수정
테이블 생성
create table 테이블명(
컬럼명1 자료형 [제약조건],
컬럼명2 자료형 [제약조건],
...
); # 테이블 생성
create table Car(
brand varchar(300),
color varchar(300),
price int
);테이블 삭제
drop table car;
테이블 수정
- 테이블명 수정
alter table 테이블명 rename to 새로운 이름
alter table user rename to userinfo alter table userinfo rename to user;
- 컬럼 수정
add(컬럼명 자료형[제약조건])
# 컬럼 추가 alter table user add(useridx int primary key); # 컬럼 수정 alter table user modify useridx bigin # 컬럼 삭제 alter table user drop username;
자료형
숫자
int : 정수
decimal(n, m) : n(전체 자리수) / m(소수점 자리수)
ex) decimal(4,2) → -99.99 ~ 99.99
문자열
- char(n) : n바이트의 문자열(고정형), 빈 자리는 그대로 남겨둔다.
ex) char(4) → [ ] → 'A'를 넣으면? → [A ] ← 용량확보- varchar(n) : n바이트의 문자열(가변형), 빈 자리는 할당 해제
ex) varchar(4) → [ ] → 'A'를 넣으면? → [A] ← 효율적으로 사용
varchar은 최대 4000까지 가능하다.- enum(값1,값2, ..): 해당하는 값들만 들어올 수 있는 자료형 설정
ex) enum('m','w') → 'm' 또는 'w'만 들어올 수 있음
하나짜리만 사용하지 대규모에서는 사용안함
시간(날짜)
date : 한 순간의 날짜를 저장하는 타입
datetime : 한 순간에 날짜와 시간을 저장하는 타입
제약조건
-
unique
고유한 값만 삽입될 수 있도록 하는 제약조건 -
not null
비어 있을 수 없도록 하는 제약조건
# 제약조건 # unique 제약조건 : 고유한 값만 삽입될 수 있도록 하는 제약조건 # not null 제약조건 : 비어있을 수 없도록 하는 제약조건 create table user( userid varchar(300) unique, userpw varchar(300) not null, username varchar(300) );
모델링
모델링이라는 것은 우리 주변에 있는 사람, 사물, 개념 등 다양한 현상을 발생시키는 것들을 일정한 표기법에 의해 나타내는 것을 이야기한다.
모델링의 특징
모델링의 특징으로는 다음과 같이 대표적으로 3가지 추상화, 단순화, 명확화 3가지로 요약할 수 있다.
1. 추상화(모형화, 가설적)
추상화는 현실세계를 일정한 형식에 맞추어 표현을 한다는 의미이다. 다양한 현상을 일정한 양식인 표기법에 의해 표현한다는 것이다.
2. 단순화
단순화는 복잡한 현실세계를 약속된 규약에 의해 제한된 표기법이나 언어로 표현하여 현실세계를 보다 쉽게 이해할 수 있도록 하는 개념을 의미한다.
3. 명확화
명확화란 누구나 이해하기 쉽도록 대상에 대한 애매모호함을 제거하고 보다 정확하게 현상을 기술하는 것을 의미한다.
설계시 고려 사항
-
충실성
필요로 하는 모든 데이터를 표현 -
단순성
단순하고 이해하기 쉬운 구조로 표현 -
중복의 최소화
데이터의 중복을 최소화해야 한다. -
제약조건의 표현
데이터가 갖추어야 할 조건을 표현
개체관계 모델 : 개념적 설계
-
<개체>
현실 세계에서 물리적/추상적으로 존재하는 실체사람, 자동차, 집, 성적 등
-
<개체 집합>
동일한 특성을 갖는 개체들의 모임{'컴퓨터공학과','산업공학과', ...}
→ 학과 개체 집합 -
<속성>
1) 개체의 특성
2) 관계형 데이터 모델의 필드와 같은 개념
3) 동일한 특성을 갖는 개체
→ 속성이 동일한 개체필드와 속성의 차이점
<필드>
- 관계형 데이터 모델에서 테이블의 컬럼
- 원자 값만 허용됨
<속성>
- 개체 관계 모델에서 개체의 특성
- 다중값 속성, 복합 속성 가능
관계와 관계집합
● <관계>
○ 개체간의 대응성을 표현
○ 개체간의 관계를 통해 유용한 의미를 규정할 수 있음 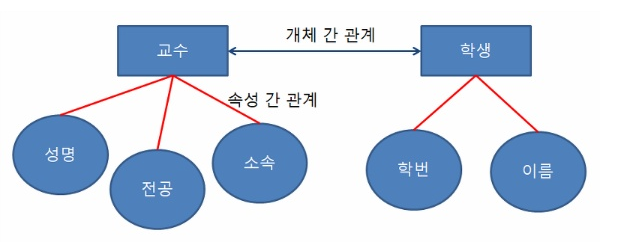
● <관계집합>
○ 동일한 유형의 관계들의 집합
● 관계의 형태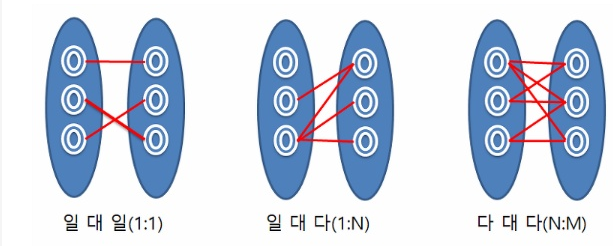
- 관계집합의 속성
✔ 개체들 사이의 관계의 특성을 표현
- 관계집합의 차수
✔ 관계집합에 참여하는 개체집합의 개수
-
이진관계
-
두 개체집합 사이에 정의된 관계집합
예) 학생 - 학과의 소속관계
-
삼진관계
-
세 개체집합 사이에 정의된 관계집합
예) 학생 - 과목 - 교수의 강의/수강 관계
DML(Data Manipulation Language)
- 데이터 조작어
- 실질적으로 데이터들을
CRUD작업을 하는 언어
데이터 추가
- 방법 1
insert into 테이블명[(컬럼명1, 컬럼명2, ...)]
values(값1, 값2, ...);
# table car에 있는 carnum, brand, color만 추가 # null이 들어간다. insert into car (carnum, brand, color) values('123가4567','Ferrari','Red');# foreign key는 비어있게 넣을 수는 있지만, 참조값이 없는 경우에는 삽입 불가능 # insert into car # values('134다7961', 'k8', 'White', 4000000, 'banana'); # → 여기서 보면 마지막에 'banana'가 들어가 있는데 table car을 보면 마지막은 id(FK)다. # → 이 id(FK)는 부모 테이블인 owner에 id = 'apple'에서 가져온 것이므로 # → 'banana'를 쓰면 참조값이 없어서 삽입이 불가능하다. insert into car values('135다7961', 'k8', 'White', 4000000, 'apple');
- 방법2
insert into 테이블명[(컬럼명1, 컬럼명2, ...)] values (값1, 값2, ...);
insert into car values ('246다2468', 'Porsche', 'Yellow', 180000000, 'apple');
데이터 삭제
delete from 테이블명 where 조건식
delete from car where carnum = '135다7961';
데이터 수정
update 테이블명 set 컬럼명 = 새로운 값 where 조건식;
# null 비교는 is(컬럼 is null / 컬럼 is not null) # 조건이 null인 table car에 있는 id를 'apple'로 변경 update car set id = 'apple' where id is null; # 조건이 '123가4567'인 table car에 있는 price를 650000000으로 변경 update car set price = 650000000 where carnum = '123가4567';
데이터 검색
- 방법 1
select 컬럼명1, 컬럼명2, ... from 테이블명 where 조건식;
# 검색된 결과가 하나의 표다.
select price from car where carnum = '123가4567';- 방법 2
select from 테이블명
select from 테이블명 where 조건식# table car 모두 불러옴 select * from car; # 조건식이 가격이 1억이상인 table car을 불러옴 select * from car where price > 100000000;
○ select * from 테이블명 where 조건식 or 조건식
```sql
select * from car where brand = 'Ferrari' or brand = 'Porsche';
# 컬럼 in (값1, 값2, ...) : 컬럼에 존재하는 값이 뒤
select * from car where brand in('Ferrari', 'Porsche'); ○ select * from 테이블명 where 조건식 and 조건식
select * from car where price >= 100000000 and price <= 200000000;
# 컬럼 between 값1 and 값2 : 컬럼의 값이 값1 이상 값2 이하 이면 참
select * from car where price between 100000000 and 200000000;■ 여기서 *가 나오는데 *은 '모든'이라는 뜻 # table country에 있는 모든 것을 검색
select * from country;별칭정하기
- 검색할 때 편하기위해서 별칭을 정할 수 있다.
- select 컬럼명1 별칭, 컬럼명2 별칭 from 테이블명 where 조건식
# 별칭(ALIAS)
# 원래는 as를 써야하는데 생략 가능!
select carnum as 차번호, price 가격 from car where price > 100000000;- 별칭이 키워드거나 띄어쓰기가 포함된 경우
쌍따음표로 묶어준다.
select 1+1+12 *364/112 "계산된 결과" from dual;
# dual : 간단한 값이나 연산의 결과를 검색하기 위한 한 행짜리 내장 테이블조건식
where 조건식
- = : 같다.
- !=, <> : 다르다.
- and : 두 조건식이 모두 참이면 참
- or : 두 조건식이 하나라도 참이면 참
Auto_increment
- table에 값이 추가될 때마다 증가하는 값을 미리 설계할 수 있다.
- PK의 자료형이 int라면 설정 가능
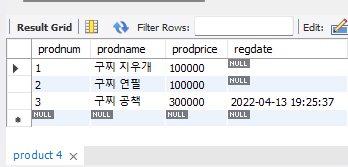
create table 테이블명( 컬럼명 int primary key auto_increment, ... );create table product( # auto_increment를 사용하면 숫자가 하나씩 증가 prodnum int primary key auto_increment, prodname varchar(300) not null, prodprice int not null, # regdate 등록시간 regdate datetime );여기에서
datetime과date의 차이점:
- DATE는 날짜를 저장할 수 있는 타입(YYYY-MM-DD)
- DATETIME는 날짜와 함께 시간까지 저장할 수 있는 타입(YYYY-MM-DD HH:MI:SS)
insert into product(prodname, prodprice, regdate) values('구찌 공책', 300000, '2022-04-13 19:25:37');
now() : 현재시간이 나옴# 현재시간으로 등록을 나타낼 때 insert into product(prodname, prodprice, regdate) values('구찌 필통', 250000, now());
like 조건식
뒤에 오는 와일드카드 문자열과 비교하여 같다면 참, 다르면 거짓
컬럼 like('와일드카드문자열')와일드 카드
_: 한글자 ex) '_다솔' : 성은 상관없이 이름이 '다솔'이면 참% : 모든 것 (%는 0글자도 포함) ex) '정%' : 이름은 상관없이 성이 '정'이면 참
%A: 글자수에 상관없이 끝이 'A'이면 참
_A: 두글자 중에 끝이 'A'면 참
_이_: 세글자중 가운데가 '이'면 참
_이%: 두번째 글자가 '이'면 참
%이_: 뒤에서 두번째 글자가 '이'면 참
__이%: 세번째 글자가 '이'면 참
이% : 두번째 글자가 '이'이며 3글자 이상이면 참# Like 조건식 select * from product where prodname like('%구찌%'); select * from product where prodname like('%필%');

함수
단일행 함수
- 행 하나당 결과를 하나 만들어나내는 함수
- 문자함수, 숫자함수, 형변환함수, NULL처리 함수
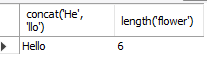
# 단일행 함수 # 문자함수 # 문자열 연결, 문자열 길이 select concat('He', 'llo'), length('flower') from dual;
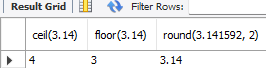
# 숫자함수 # 올림, 버림, 반올림 select ceil(3.14), floor(3.14), round(3.141592, 2) from dual;
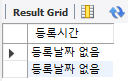
# 널처리 함수( Null 값을 0 등으로 바꾸고 싶을 때) select ifnull(regdate, '등록날짜 없음') "등록시간" from product where prodname = '구찌 지우개';
그룹함수
- 여러 행의 데이터들을 받아서 하나의 결과로 도출해주는 함수
- 반드시 하나의 값만을 반환한다.
- NULL 값은 무시된다.
group by설정 없이 일반 컬럼들과 기술될 수 없다.SUM,MIN,MAX,AVG,COUNT행을 세는 것들임

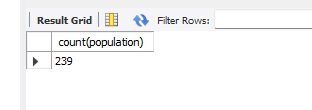
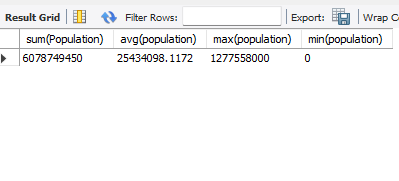
# 그룹함수 use world; select count(Population) from country;
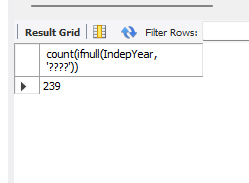
# ifnull을 안쓰면 null은 count하지 않는다. # null 값도 세고 싶어서 사용 # '????'는 null대신 숫자가 아닌 아무 값넣어서 데이터 갯수 확인 select count(ifnull(IndepYear, '????')) from country;
select sum(Population), avg(population), max(population), min(population) from country;
# 대륙별 총 인구수 select Continent 대륙, sum(population) "총 인구수" from country group by Continent;
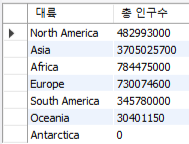
# 대륙별로 정렬 # 여기서 order by 1, 2는 검색된 결과의 1번째 컬럼, 2번째 컬름을 뜻한다. # 즉, 그 컬럼들을 기준으로 정렬한다는 뜻이다. select Continent 대륙, Region 지역, sum(population) "총 인구수" from country group by Continent, Region order by 1,2 desc;
group by
-
그룹함수를 적용시킬
파트(범위)를 나누는 문법 -
GROUP BY절의 의미는 그룹 함수를 GROUP BY절에 지정된 컬럼의 값이 같은 행에 대해서 통계 정보를 계산하라는 의미
group by 컬럼1, 컬럼2, ... → 컬럼1로 그룹짓고, 그 내부에서 컬럼2로 그룹짓고, ...select Continent 대륙, Region 지역, sum(population) "총 인구수" from country group by Continent, Region;having 조건절
-
group by를 통해 그룹을 짓고 구해진 결과가 있을 때 각 그룹에 조건을 부여할 때 사용하는 문법 -
where과 비슷한 개념으로 조건 제한 -
집계 함수에 대해서 조건 제한하는 편리한 개념
-
having절은 반드시 group by절 다음에 나와야 한다.
where절과 having절의 차이
- where절은 각 데이터들에게 적용되는 조건을 설정, 조건식에 그룹함수 사용불가
- having절은 각 그룹에게 적용되는 조건을 설정, 조건식에 그룹함수 사용가능
select countrycode, max(population) from city group by countrycode having max(population) > 8000000;
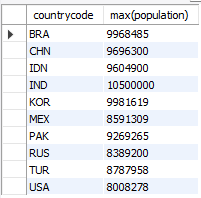
order by
- 검색 결과를 정렬하는 문법
- SELECT로 데이터를 조회할 때, ORDER BY를 추가하여 지정된 컬럼을 기준으로 정렬
order by 컬럼1 [정렬기준], 컬럼2 [정렬기준], ... → 컬럼1 기준으로 정렬, 그 내부에서 컬럼2 기준으로 정렬, ...
[정렬기준]
생략시 오름차순
ASC : 오름차순
DESC : 내림차순
-
오름차순 정렬
SELECT * FROM 테이블 ORDER BY 컬럼1 ASC;
-
오름차순 정렬(ASC 생략)
select * from 테이블 order by 컬럼1; -
내림차순 정렬
select * from 테이블 order by 컬럼1 DESC; -
여러 컬럼으로 정렬
select * from 테이블명 order by 컬럼1 [, 컬럼2, 컬럼3, ...];
limit
- 검색된 결과의 개수와 위치를 제한하는 문법
- Oracle에는 존재하지 않는다.
select문 limit 정수(n);
→ 검색된 결과 맨 위에서 n개만 추출
select문 limit(n), 정수(m);
→ 검색된 결과의 n번째부터 m개만 추출 # 행 데이터 10개만 조회하기
SELECT title, content, writer FROM board LIMIT 10; # 11번째 ~ 20번째 행 데이터 조회
SELECT title, content, writer FROM board LIMIT 10, 10;join
RDBMS에서 여러 테이블에 흩어져 있는 정보 중 사용자가 필요한 정보를 가져와서 가상의 결과 테이블을 만들고 결과를 보여주는 기술
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
연결하려는 테이블들이 적어도 하나의 컬럼을 공유하고 있어야 한다.
이 공유하고 있는 컬럼을PKorFK값으로 사용한다.
# from 테이블1 join 테이블2 on join 조건식 # 회원명 핸드폰번호 자동차번호 브랜드 가격 select o.name, o.phone, c.carnum, c.brand, c.price from owner o join car c on o.id = c.id;
join
RDBMS에서 여러 테이블에 흩어져 있는 정보 중 사용자가 필요한 정보를 가져와서 가상의 결과 테이블을 만들고 결과를 보여주는 기술
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
연결하려는 테이블들이 적어도 하나의 컬럼을 공유하고 있어야 한다.
이 공유하고 있는 컬럼을PKorFK값으로 사용한다.
# from 테이블1 join 테이블2 on join 조건식 # 회원명 핸드폰번호 자동차번호 브랜드 가격 select o.name, o.phone, c.carnum, c.brand, c.price from owner o join car c on o.id = c.id;
서브쿼리
- SQL문 내부에 SQL문을 선언하는 기법
- select문 안에 또다시 select문이 있는 쿼리문입니다.
- from : inline view
- select : scalar
- where : sub query
서브쿼리(sub query)
일반적으로 where절에 사용하는 서브쿼리

인라인 뷰(Inline View)
from절에 사용하는 서브쿼리입니다.

스칼라 서브쿼리(Scala Subquery)
select문에 사용하는 서브쿼리입니다.

서브쿼리 사용시 주의사항
- 서브쿼리를 괄호로 감싸서 사용한다.
- 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능하다.
- 서브쿼리에는 order by를 사용하지 못한다.
서브쿼리 사용 가능한 곳
- SELECT 절
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT 문의 VALUES 절
- UPDATE 문의 SET 절
Any
- 서브쿼리의 여러개의 결과 중 한 가지만 만족해도 가능
- some은 any와 동일한 의미로 사용
- =any 구문은
in과 동일한 의미
select * form city where population > any ( select population from city where district = "New York");select * form city where population > some ( select population from city where district = "New York");→ any가 없으면 서브쿼리에서 값이 여러개가 나와서 에러가 생기는데
any를 사용함으로써 사용가능해진다.
all
- 서브쿼리의 여러 개의 결과를 모두 만족 시켜야 함
select * form city
where population > all ( select population from city
where district = "New York");→ New York에 인구수보다 많은 인구수의 도시를 보여줘라는 의미
cascade
- cascade란 두 테이블을 연결해서 PK를 가지고 있는 쪽의 값을 삭제하면 FK로 연결된 값이 동시에 삭제되게 하는 옵션이다.
적용
#☆★☆★☆★☆★ database : web0315 ☆★☆★☆★☆★☆★☆★
use web0315;
# owner에 두명 더 추가하기(banana, cherry)
insert into owner values('banana','바나나', 01012345678, 22, '서울시 구로구');
insert into owner values('cherry', '체리', 01098245568, 24, '서울시 양천구');# car에 3대 더 추가하기(cherry의 2000만원 이하짜리 필수, banana의 4000이상 1억이하 필수)
insert into car values('111다1111', 'k8', 'Black', 4000000, 'banana');
insert into car values('222가2222', 'genesis','Black',90000000,'banana');
insert into car values('333나3333', 'tico', 'Red', 3000000,'cherry'); # car에서 banana의 자동차 중 4000만원 이상 1억원 이하의 자동차 색깔을 Gold로 바꾸기
update car set color = 'Gold' where id = 'banana' and price between 40000000 and 100000000;# car에서 cherry 자동차 중 2000만원 이하의 자동차 삭제하기
delete from car where id = 'cherry' and price <= 20000000;
select * from owner;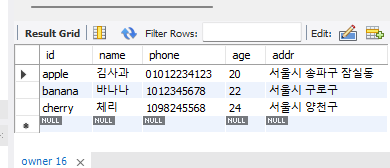
select * from car;
#☆★☆★☆★☆★ database : world ☆★☆★☆★☆★☆★☆★
use world;
#country 테이블
#소속 대륙(Continent)이 Asia인 나라 검색
select * from country where Continent = 'Asia'; 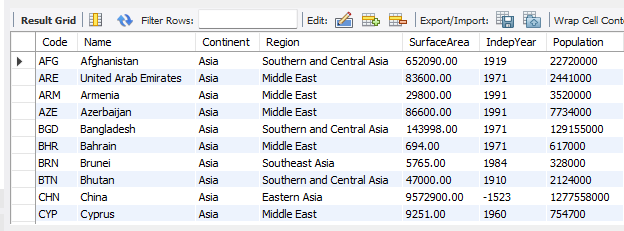
#소속 대륙(Continent)이 Europe이 아닌 나라 검색
select * from country where Continent != 'Europe';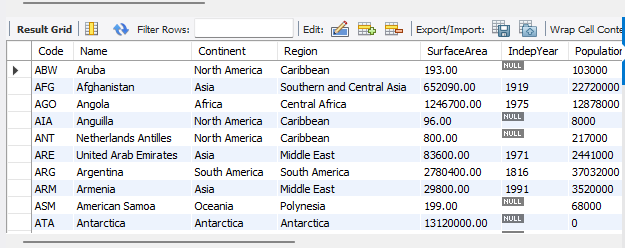
#인구수(Population)가 1000만 이하인 나라 검색
select * from country where Population <= 10000000;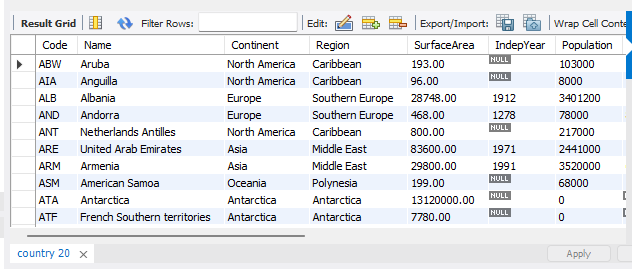
#인구수(Population)가 7000만 이상인 나라 검색
select * from country where Population >= 70000000;
#인구수(Population)는 4500만 이상이면서 넓이(SurfaceArea)가 10만제곱km이하인 나라 검색
select* from country where Population >= 45000000 and SurfaceArea <= 100000;
#소속 대륙(Continent)은 Asia 이고 건국 연도(IndepYear)가 1948인 나라 검색
select * from country where Continent = 'Asia' and IndepYear = 1948;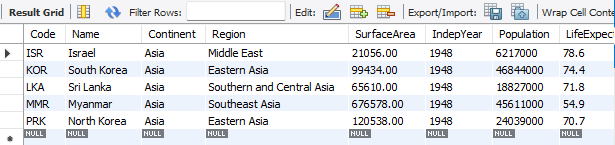
#지역(Region)이 동아프리카(Eastern Africa) 이고 건국 연도 가 1970~1980인 나라 검색
select * from country where Region = 'Eastern Africa' and IndepYear between 1970 and 1980;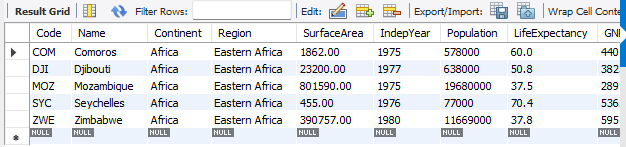
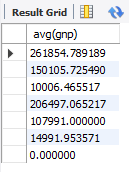
대륙별로 평균 gnp 검색
select avg(gnp) from country group by Continent;
● gnp 평균이 100000 이상인 지역들의 지역명, gnp 최대값, gnp 최소값, gnp 평균 검색# group by를 사용하고 조건문을 사용할거면 having을 사용해야 한다.
select Region 지역명, max(gnp), min(gnp), avg(gnp) from country
group by Region having avg(gnp) > 100000;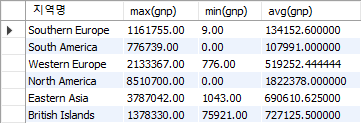
● 대륙별 평균 인구를 출력하되 15000000명을 넘는 대륙만 검색 select Continent 대륙, avg(Population) "평균 인구"
from country where population > 150000000 group by Continent order by 1 asc;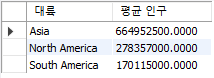
● 인구수가 2000만명을 넘는 나라들의 평균 넓이가 2000000 제곱km를 넘는 대륙들만 검색 select Continent 대륙 from country where population > 20000000
group by Continent having avg(SurfaceArea) > 2000000;
● 대륙별, 그리고 지역별로 나라들의 평균 수명 검색 select Continent 대륙별, Region 지역별, avg(LifeExpectancy) "평균 수명"
from country group by Continent, Region order by 1,2;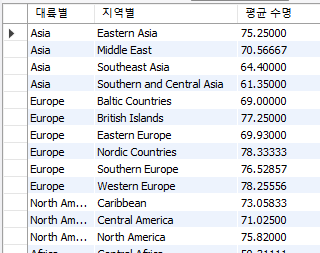
# 서브쿼리
# id가 14인 임직원보다 생일이 빠른 임직원의 ID, 이름, 생일을 알고 싶다.
select id, name, bith_date from employee
where birth_date < ( select birth_date from employee where id =1);
# ID가 5인 임직원과 같은 프로젝트에 참여한 임직원들의 ID와 이름를 알고 싶다.
# where절 서브 쿼리
select id, name from employee
where id in(
select distinct empl_id
from works
where empl_id != 5 and proj_id in(
select proj_id
from works where empl_id =5)
);
# from절 서브 쿼리
# 여기서 id는 employee를 가르키고 from절 서브쿼리의 id가 employee id와 같으면 조건에 맞다.
select id, name
from employee,
(
select distinct empl_id
from works
where empl_id != 5 and proj_id in(
select proj_id
from works where empl_id =5)
) as DSTINCT_E
where id = DSTINCT_E.empl_id;
# ID가 7 혹은 12인 임직원이 참여한 프로젝트의 ID와 이름을 알고 싶다.
# exists : 존재하는 것을 찾아준다.
select P.id, P.name
from project P
where exists (
select W.proj_id
from works W
where W.empl_id in(7, 12)
);
# 위에꺼와 같은 의미
select P.id, P.name
from project P
where id in(
select W.proj_id
from works W
where W.empl_id in(7, 12)
);
# 2000년대생이 없는 부서의 ID와 이름을 알고싶다.
select D.id, D.name
from department as D
where not exists(
select * from employee E
where E.dept_id = D.id and E.birth_date >= '2000-01-01'
);
# 리더보다 높은 연봉을 받는 부서원을 가진 리더의 Id와 이름과 연봉을 알고 싶다.
# <>는 != 와 같다.
# any : 단 하나라도 조건에 맞는게 있다면 true
# some == any
select E.id, E.name, E.salary
from department D, employee E
where D.leader_id = E.id and E.salary < any(
select salary
from employee
where id <> D.leader_id and dept_id = E.dept_id
);질문 예상
💡SQL 인젝션이란?
보안상의 취약점을 이용하여, 임의의 SQL 문을 주입하고 실행되게 하여 데이터베이스가 비정상적인 동작을 하도록 조작하는 공격 입니다. 클라이언트가 입력한 데이터를 제대로 필터링 하지 못하는 경우에 발생합니다. URL을 통해서 SQL문을 주입할 수 있습니다.
- 예방방법
- 검증 로직을 추가해서 미리 설정한 특수문자들이 들어왔을 때 요청을 막는방법이 있습니다.
- 에러 메시지 노출을 방지합니다.
- Prepared Statement 구문을 사용합니다.
💡Primary Key와 Unique Key 차이
primiary key(기본키)와 unique key(유일성을 가지기 위해 설정한 키)는 제약 조건 중에 하나로 유일한 값을 식별하는 것이 주된 목적이다. 기본키는 해당 테이블의 식별자 역할을 한다. 따라서 중복성이 없어야하고 null 값을 가질 수 없다. 유니크 키는 유일성을 가지기 위해서 설정한 것으로 지정이 되면 중복이 되는 것을 제어하는 역할을 하게 된다. 유니크 키는 하나의 테이블에서 각각 컬럼마다 지정이 가능하지만 기본키는 한 테이블에서 오직 하나만 설정할 수 있다.
💡Database에서 Index란?
인덱스는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다.
데이터베이스에서 테이블과 클러스터에 연관되어 독립적인 저장 공간을 보유하고 있는 객체(object)이다. 사용자는 데이터베이스에 저장된 자료를 더욱 빠르게 조회하기 위하여 인덱스를 생성하고 사용한다.
DB에서 자료를 검색하는 두 가지 방법
1. FTS(Full Table Scan) : 테이블을 처음 부터 끝까지 검색하는 방법
2. Index Scan : 인덱스를 검색하여 해당 자료의 테이블을 액세스 하는 방법.
인덱스는 적용하면 어떤 알고리즘으로 동작할까요?
B-Tree, 해시 등 여러 가지가 있지만 B-Tree 알고리즘이 가장 대표적입니다.
B-Tree
B-Tree는 이진트리와 달리 하나의 노드에 여러 개의 정보를 가질 수 있습니다. 해당 정보들은 정렬되어 있으며, 이진검색트리처럼 각 key들의 왼쪽 자식들은 항상 key보다 작은 값을, 오른쪽 자식들은 key보다 큰 값을 갖습니다.
B-Tree에서 값을 찾을 때는 각 노드의 key를 순차적으로 검색하다 찾고자 하는 값을 만나면 데이터를 리턴하고, 큰 값을 만나는 경우 이전 Key와 현재 Key 사이의 자식 노드로 내려갑니다. 이러한 동작을 리프 노드에 닿을 때까지 반복하면 검색이 종료됩니다.
왜 DB 인덱스 알고리즘으로 B-Tree를 선택했을까?
데이터가 항상 정렬되어 있기 때문에 부등호 연산에 문제가 없으며, 데이터 탐색, 저장, 수정, 삭제에 모두 O(logn)의 빠른 속도를 갖기 때문입니다.
또한, 노드 내에 여러 데이터를 저장할 수 있으며 노드에 저장된 데이터들은 배열 형태이기 때문에 물리적으로 인접한 위치에 저장되고, 탐색속도가 매우 빠릅니다.
💡Index에 대해 설명해주시고, 장/단점에 대해 아는대로 말해주세요.

💡DBMS는 Index를 어떻게 관리하고 있나요? (Index 자료구조)

💡인덱스는 언제 사용하는 것이 좋을까요?
데이터의 삽입, 삭제, 수정이 자주 일어나지 않는 컬럼에 적용하는 것이 적합합니다. 또한, 규모가 큰 테이블, 데이터 중복이 적은 컬럼, Where나 Order by, Join 등이 자주 사용되는 컬럼에 적용하는 것이 적합합니다.
💡DCL, DDL, DML 이란?
-
DCL(Data Control Language) 데이터 제어어
데이터베이스에 접근하거나 객체에 권한을 주는등의 역할을 하는 언어를 말합니다.(GRANT, REVOKE, COMMIT, ROLLBACK) -
DDL(Data Definition Language) 데이터 정의어
데이터베이스를 정의하는 언어이며 데이터를 생성, 수정, 삭제하는 등의 데이터의 전체의 골격을 결정하는 역할을 하는 언어 입니다.(CREATE, ALTER, DROP, TRUNCATE) -
DML(Data Manipulation Language) 데이터 조작어
정의된 데이터베이스에 입력된 레코드를 조회하거나 수정하거나 삭제하는 등의 역할을 하는 언어를 말합니다.(SELECT, INSERT, UPDATE, DELETE)
💡group by의 역할에 대해 설명해주세요.
GROUP BY 는 GROUP BY 명령어를 통해 특정 컬럼을 기준으로 연산한 결과를 집계 키로 정의하여 그룹을 짓는 역할을 합니다.
집합 연산자는 COUNT, SUM, AVG, MAX, MIN 등이 있고, DISTINCT와 같이 중복 데이터를 제거하는 특징이 있습니다.
💡DELETE, TRUNCATE, DROP의 차이를 설명해주세요.
-
DELETE는 데이터는 지우지만 테이블 용량은 줄어들지 않고 원하는 데이터만 골라서 지울 수 있습니다. 삭제 후 되돌릴 수 있습니다. -
TRUNCATE는 전체 데이터를 한번에 삭제하는 방식입니다. 테이블 용량이 줄어들고 인덱스 등도 삭제되지만 테이블은 삭제할 수 없고, 삭제 후 되돌릴 수 없습니다. -
DROP은 테이블 자체를 완전히 삭제하는 방식(공간, 인덱스, 객체 모두 삭제)입니다. 삭제 후 되돌릴 수 없습니다.
💡HAVING과 WHERE의 차이를 설명해주세요.
having은 그룹화 또는 집계가 발생한 후 필터링 하는데 사용되고, where은 그룹화 또는 집계가 발생하기 전에 필터링하는데 사용됩니다.
집계 함수(COUNT, SUM, AVG, MAX, MIN 등)는 having절과 함께 사용할 수 있으나, where절은 사용할 수 없습니다.
집계함수를 사용할 수 있는 GROUP BY 절보다 WHERE절이 먼저 수행
ERD란?
Entity Relationship Diagram. 데이터베이스를 구축할 때 가장 기본적인 뼈대 역할을 하는 설계도와 같은 자료를 말합니다. 각 테이블간의 관계, 테이블의 필드 및 타입등을 기록합니다.
💡Join 문이란?
관련 있는 칼럼을 기준으로 행을 합쳐주는 연산
조인 원리
-
중첩 루프 조인
중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법을 말합니다. -
정렬 병합 조인
각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬 이후 조인 작업을 수행하는 조인을 말합니다. -
해시 조인
해시테이블을 기반으로 조인하는 방법입니다. 보통 중첩 루프 조인보다 더 효율적입니다.
💡JOIN에서 ON과 WHERE의 차이를 설명해주세요.
ON이 WHERE 보다 먼저 실행되어 JOIN 을 하기 전에 필터링을 하고 (=ON 조건으로 필터링이 된 레코들간 JOIN이 이뤄진다)
WHERE은 JOIN 을 한 후에 필터링을 합니다. (=JOIN을 한 결과에서 WHERE 조건절로 필터링이 이뤄진다)
💡JOIN과 UNION에 대해 설명해보세요.
JOIN은 한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현하는 기술을 말하며, UNION은 여러 테이블의 값을 함께 표현한다는 점에서 JOIN과 비슷하지만, 테이블을 수직적으로 결합시킨다는 면에서 JOIN과 다릅니다.
UNION이 잘 작동하기 위해서는 어떤 조건이 필요할까요?
모든 테이블이 같은 수의 필드를 갖고 있어야 하고 관련 있는 필드들은 필드 이름과 데이터 타입이 같아야 합니다.
UNION과 UNION ALL의 차이점은 무엇일까요?
UNION은 중복 데이터를 허용하지 않으며, UNION ALL은 허용합니다.
💡SELECT 쿼리의 수행 순서를 알려주세요.

💡트리거(Trigger)에 대해 설명해주세요.
-
트리거는 특정 테이블에 대한 이벤트에 반응해 INSERT, DELETE, UPDATE 같은 DML 문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램입니다.
-
사용자가 직접 호출하는 것이 아닌, 데이터베이스에서 자동적으로 호출한다는 것이 가장 큰 특징입니다.
💡정규화에 대해 설명하시오.
-
정규화란 RDBMS의 설계에서 중복을 최소화하여 데이터를 구조화하는 프로세스
-
연관성 있는 속성들을 분류하여, 각 릴레이션들에 이상 현상이 생기지 않도록 하는 과정
정규화 과정이란?
정규화 과정은 릴레이션 간의 잘못된 종속 관계로 인해 데이터베이스 이상 현상이 일어나서 이를 해결하거나, 저장 공간을 효율적으로 사용하기 위해 릴레이션을 여러 개로 분리하는 과정을 말합니다.
이상현상
불필요한 데이터 중복으로 인해 릴레이션에 대한 데이터 삽입, 삭제, 수정 연산을 할 때 논리적으로 생기는 오류를 의미합니다.
- 삽입 이상은 데이터를 삽입할 때 의도하지 않은 속성까지 삽입해야만 데이터를 테이블에 추가할 수 있는 현상을 말합니다.
- 삭제 이상은 데이터를 삭제하면, 의도하지 않은 다른 데이터까지 삭제되는 현상을 말합니다.
- 갱신 이상은 중복된 데이터 중 일부만 수정되어 데이터 불일치가 일어나는 현상을 말합니다.
회원이 한 개의 등급을 가져야 하는데 세 개의 등급을 갖는 경우, 삭제할 때 필요한 데이터 값이 같이 삭제되는 경우 등
정규형 원칙이란?
같은 의미를 표현하는 릴레이션이지만 좀 더 좋은 구조로 만들어야 하고, 자료의 중복성은 감소해야 하고, 독립적인 관계는 별개의 릴레이션으로 표현해야 하며, 각각의 릴레이션은 독립적인 표현이 가능해야 하는 것을 말합니다.
정규화는 무조건 하는 것이 바람직한가?
그렇지 않습니다. 정규화를 하게 되면 데이터가 분화되므로 데이터 조회시 JOIN이 발생할 확률이 증가합니다. 만약 통계 데이터 등 여러 데이터를 복합적으로 표시하는 상황이 자주 있다면 반대로 반정규화를 통해 함께 사용되는 데이터를 한 테이블에 두는 것이 성능상 이점이 있을 수 있습니다.
정규화의 종류
- 제 1정규화 : 각 컬럼들은 값이 원자값을 가지게 바꾼다.
- 제 2정규화 : 테이블의 모든 컬럼에서 부분 함수적 종속을 제거하는 것
- 제 3정규화 : 기본키를 제외한 속성들 간의 이행적 함수 종속을 없애는 것
- 제 BCNF화 : 결정자이면서 후보키가 아닌 것들 제거
- 제 4정규화 : 다치 종속 제거
💡정규화가 필요한 이유는?
-
DB설계를 잘못하면 불필요한 데이터 중복으로 인해 공간이 낭비되고 부작용을 초래할 수 있기 때문
-
이러한 부작용을 이상(Anomaly)이라 한다.
-
삽입 이상, 갱신 이상, 삭제 이상이 있다.
정규화 장단점
장점
-
데이터베이스 변경 시 이상현상이 발생하는 문제점을 해결할 수 있다.
-
데이터베이스 구조 확장 시 정규화된 데이터베이스는 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
단점
릴레이션의 분해로 인해 릴레이션 간의 연산(JOIN 연산)이 많아진다. 이로인해 질의에 대한 응답 시간이 느려질 수 있다.
- 정규화를 수행한다는 것은 이상현상을 제거하는 것이다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다. 따라서 정규화된 테이블은 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있는 특성이 있다.
💡데드락(교착상태)이란 무엇이며, 어떻게 발생할까요?
드락은 상호배제, 점유와 대기, 환형 대기, 비선점이 모두 충족될 경우 발생합니다.
💡데이터베이스 스키마란?
-
스키마란 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 메타데이터의 집합이다.
-
스키마는 데이터베이스를 구성하는 데이터 개체(Entity), 속성(Attribute), 관계(Relationship) 및 데이터 조작 시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의한다.
-
사용자의 관점에 따라 외부 스키마, 개념 스키마, 내부 스키마로 나눠진다.
외부 스키마란?
사용자 뷰로서 사용자나 응용프로그래머가 각 개인의 입장에서 필요로 하는 데이터베이스의 논리적 구조를 정의한 것이다. 서브 스키마라고도 한다.
💡스키마의 특징은?
-
데이터사전(Data Dictionary)에 저장되며, 다른 이름으로 메타데이터라고도 한다.
-
현실 세계의 특정한 한 부분의 표현으로서 특정 데이터 모델을 이용해서 만들어진다.
-
시간에 따라 불변인 특성을 갖는다.
-
데이터의 구조적 특성을 의미하며, 인스턴스에 의해 규정된다.
💡역정규화를 하는 이유
정규화를 거치면 릴레이션 간의 연산(JOIN 연산)이 많아지는데, 이로인해 성능이 저하될 우려가 있습니다.
역정규화를 하는 가장 큰 이유는 성능 문제가 있는(읽기작업이 많이 필요한) DB의 전반적인 성능을 향상시키기 위함입니다.
💡이상 현상의 종류에 대해 설명해주세요.
이상 현상은 테이블을 설계할 때 잘못 설계하여 데이터를 삽입,삭제,수정할 때 생기는 논리적 오류를 말합니다.
- 삽입 이상 : 자료를 삽입할 때 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 갱신 이상 : 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
- 삭제 이상 : 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
이러한 이상 현상을 예방하고 효과적인 연산을 하기 위해 데이터 정규화를 합니다.
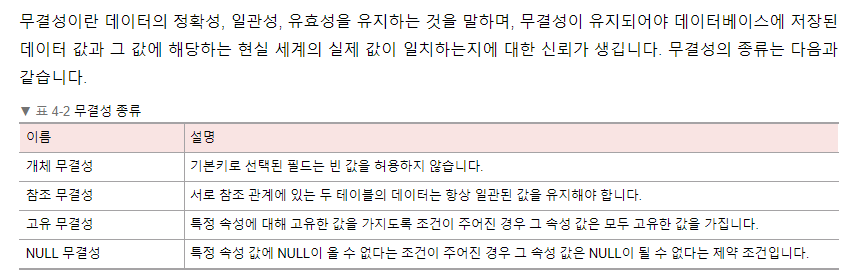
💡무결성이란?
무결성이란 데이터의 정확성, 일관성, 유효성을 유지하는 것을 말합니다.
-
개체 무결성 : 기본키로 선택된 필드는 빈 값을 허용하지 않습니다.
-
참조 무결성 : 서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지합니다.
-
도메인 무결성 : 특정 속성의 값이 그 속성이 정의된 도메인에 속한 값이어야 한다는 규정(도메인 '남', '여')
-
고유 무결성 : 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우 그 속성값은 모두 고유한 값을 가집니다.
-
NULL 무결성 : 특정 속성값에 NULL이 올 수 없다는 조건이 주어진 경우 그 속성값은 NULL이 될 수 없다는 제약조건
-
키 무결성 : 한 릴레이션에는 최소한 하나의 키가 존재해야하는 제약조건
-무결성을 유지하려는 이유? : 무결성이 유지가 되어야 DB에 저장된 데이터 값과 거기에 해당하는 현실 세계의 실제값이 일치하는지 신뢰할 수 있기 때문입니다.
💡트랜잭션이란?
-
트랜잭션은 작업의 완전성을 보장해주는 것이다.
-
논리적인 작업 셋을 모두 완벽하게 처리하거나 또는 처리하지 못할 경우에는 원 상태로 복구해서 작업의 일부만 적용되는 현상이 발생하지 않게 만들어주는 기능
-
트랜잭션의 4가지 특성(ACID) : 원자성, 일관성, 고립성, 지속성
트랜잭션
데이터베이스의 상태를 변경시키기 위해 수행하는 작업이다. 이러한 트랜잭션은 상황에 따라 여러개 만들어질 수 있다.
- 트랜잭션의 특징
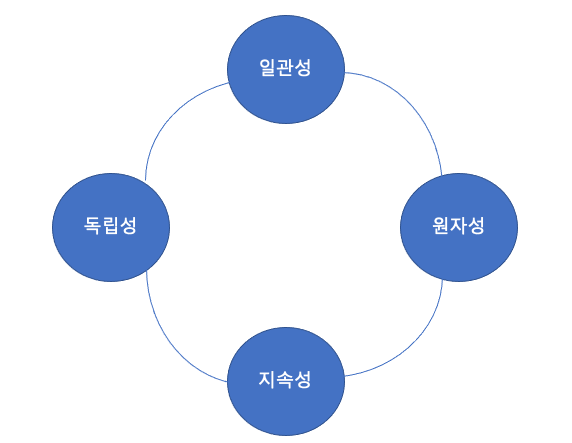

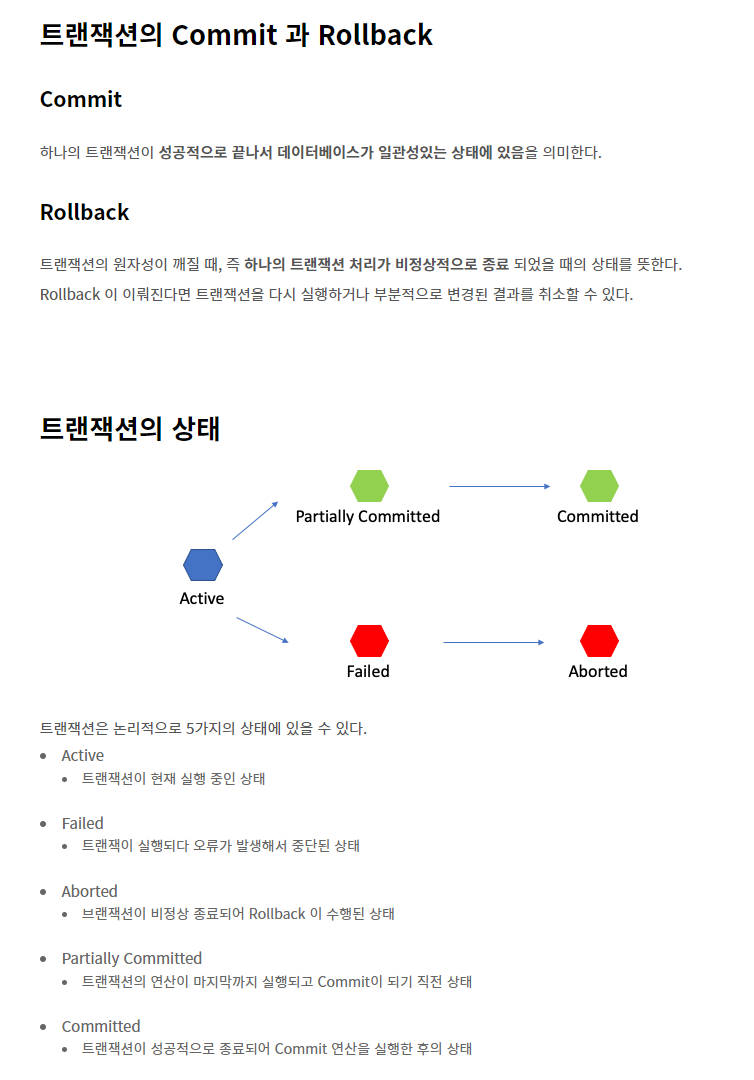
💡DB Connection Pool 이란?
웹 컨테이너(WAS)가 실행되면서 DB와 미리 연결해놓은 객체들을 Pool에 저장해두었다가 클라이언트 요청이 오면 connection을 빌려주고, 처리가 끝나면 다시 connection을 반납받아 pool에 저장하는 방식
Connection이 모두 사용중이면 어떻게 되나요?
해당 클라이언트는 대기 상태로 전환시키고 Connection이 반환되면 순차적으로 제공됩니다.
왜 사용할까요?
Connection 생성, 소멸 비용 세이브, DB 접근시간 단축, DB에 접근하는 Connection 수 제한하여 메모리와 DB에 걸리는 부하 조정
Thread Pool과 Connection Pool은 같은 개념인가요?
아닙니다. 쓰레드 풀은 일반적으로 쓰레드 풀의 크기가 커넥션 풀의 크기보다 더 큰 것이 바람직합니다. 쓰레드는 DB 관련 작업 외에 다른 작업들도 처리하기 때문입니다.
💡로킹(Locking)이란?
-
트랜잭션이 DB를 다루는 동안 다른 트랜잭션이 관여하지 못하게 막는 것을 말합니다.
-
한 번에 한명만 사용할 수 있게 하는 단위를 로킹 단위라고 하며 파일, 레코드, 필드 등 다양한 로킹 단위가 있을 수 있습니다.
-
무조건적인 Locking은 DB 성능을 저하시킬 수 있으며 Locking 범위를 줄인다면 값이 잘못 처리될 여지가 있습니다.
💡데이터베이스의 격리 수준엔 무엇무엇이 있는가?
-
Serializable
트랜잭션을 순차적으로 진행시킴. 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서는 접근 불가. 여러 트랜잭션이 동시에 같은 행에 접근 불가. 가장 성능이 떨어짐. -
Repeatable_read
하나의 트랜잭션이 수정하고 있는 행을 다른 트랜잭션이 수정할 수 없도록 막아줌. 자신보다 트랜잭션 ID가 높은 트랜잭션에서 일어난 일에 대해서는 커밋이 완료됐더라도 무시한다. 이 역시 Undo 영역을 활용하기 때문에 가능한 것. 이렇게 논리피터블리드 해결. 새로운 행 추가는 막지 않음. MySQL 기본값. - 팬텀리드 발생 -
Read_committed
다른 트랜잭션이 커밋 완료한 데이터에 대해서만 조회 허용. 커밋이 완료되기 전에 다른 트랜잭션이 Select 쿼리를 날리면 Undo 영역을 활용하여 수정 이전값을 돌려준다. - 논리피터블리드 발생 -
Read_uncommitted
트랜잭션이 커밋되기 이전에 다른 트랜잭션에 노출됨. 데이터 무결성 문제가 생길 가능성이 높음 - 더티리드 발생
격리 수준에 따라 발생하는 부정합 문제는 무엇무엇이 있는가?
-
더티리드
다른 트랜잭션에서 처리한 작업이 완료되지 않았음에도 다른 트랜잭션에서 볼 수 있게 되는 현상을 말한다. -
Non-repeatable read
한 트랜잭션 내에서 동일한 SELECT 쿼리를 실행했을 때 항상 같은 결과를 보장해야 하는 Repeatable 정합성에 어긋나는 것을 말한다. -
팬텀리드
다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안 보였다가 하는 현상을 말한다.
💡트리거란?
DML문이 수행됐을 때 데이터베이스에서 자동적으로 동작하도록 작성된 프로그램을 말합니다. 전체 트랜잭션 작업에 대해 발생되는 트리거와 각행에 대해 발생되는 트리거가 있습니다.
💡RDB와 RDBMS란?
-
RDB는 관계형 데이터베이스, RDBMS는 관계형 데이터베이스를 생성하고 수정하고 관리할 수 있는 소프트웨어를 말함(예: MySQL, Oracle 등).
-
모든 데이터를 2차원 테이블로 표현함. 이러한 테이블들은 상호 관련성을 가질 수 있음. 상호 관련성을 갖게 하기 위해서는 외래키를 사용하는 방식이 일반적임.
💡샤딩이란?
RDB의 수평적 확장을 가능케하는 기술입니다. 한 테이블의 데이터를 ROW 단위로 잘라 다른 데이터베이스 서버에 나눠 저장하는 방식입니다. 그러나 RDB가 수평적인 확장에 친화적이지 않은 구조인 만큼, 선호할 만한 옵션은 아니며 수직적 확장을 비롯한 다른 방법으로 해결이 가능한지 여부를 먼저 따져보는 것이 바람직합니다.
💡관계형 데이터베이스 명령어 종류를 간략히 설명해주세요.
관계형 데이터베이스 명령어는 크게 정의어, 조작어, 제어어로 나눌 수 있습니다. 정의어에는 테이블, 인덱스 등의 개체를 만들고 관리하는데 사용하는 명령어로, CREATE, ALTER, DROP 등이 있습니다. 조작어는 데이터 검색, 삽입, 갱신, 삭제를 위한 명령어로 SELECT, DELETE, UPDATE, INSERT 등이 있습니다. 제어어는 데이터 핸들링 권한 설정, 데이터 무결성 처리 등을 수행하는 명령어로, GRANT, COMMIT, ROLLBACK 등이 있습니다.
비정형 데이터란?
일정한 규격이나 형태가 없는 그림이나 영상, 문서와 같은 구조화되지 않은 데이터를 말합니다. 정해진 규칙이 없어 값의 의미를 쉽게 파악하기 힘듭니다.
정형 데이터란?
데이터베이스의 정해진 규칙(Rule)에 맞게 들어간 데이터 중에 수치만으로 파악이 쉬운 데이터들을 말합니다. 데이터베이스에 들어간 모든 데이터가 아니라, 그 값의 의미를 파악하기 쉽고, 규칙적인 값으로 데이터가 들어가 있어야 한다.
반정형 데이터란?
반정형 데이터의 반은 Semi를 말합니다. 즉, 완전한 정형이 아니라 약한 정형 데이터라는 것입니다. HTML이나 XML등을 말합니다. 일반적인 데이터베이스는 아니지만 스키마를 갖고있는 형태입니다. 데이터베이스를 JSON이나 XML형태의 포맷으로 변경하면 반 정형 데이터가 되는것입니다.
NoSQL
NoSQL 데이터베이스(일명 SQL만을 사용하지 않는 데이터베이스)는 표 형식이 아니며 관계형 테이블과는 다른 방식으로 데이터를 저장합니다. NoSQL 데이터베이스는 데이터 모델에 따라 유형이 다양합니다. 주요 유형으로는 문서, 키, 값, 와이드 컬럼, 그래프가 있습니다. 이들은 유연한 스키마를 제공하며, 대량의 데이터와 높은 사용자 부하에서도 손쉽게 확장이 가능합니다.
보통 NoSQL은 비관계형 데이터베이스를 지칭할 때 사용합니다. NoSQL은 관계형 데이터베이스와 다르지만 관계 데이터를 저장할 수 있습니다. NoSQL 데이터 모델을 사용하면 관련 데이터를 단일 데이터 구조 내에 중첩시킬 수 있습니다. NoSQL 데이터베이스는 2000년대 말 스토리지 비용이 크게 하락하면서 등장했습니다. 단순히 데이터 중복 감소를 목적으로 복잡하고 관리가 어려운 데이터 모델을 생성해야 하던 시절은 지나갔습니다.
💡NoSQL과 SQL의 차이점은?
NoSQL이란 Not only SQL의 약자로 관계형 데이터베이스 뿐만 아니라, 여러 유형의 데이터베이스를 사용하는 확장된 데이터베이스 또는 데이터베이스 관리 시스템입니다.
SQL은 엄격한스키마를 갖는다는 Structured Query Language의 약자입니다. 데이터베이스 자체를 나타내는 것이 아니라, 특정 유형의 데이터베이스(주로 RDB)와 상호작용하는데 사용하는 쿼리 언어입니다. RDB에서 데이터는 테이블에 레코드로 저장되며 각 테이블에는 명확하게 정의된 구조가 있습니다.
SQL은 스키마와 맞지 않는 형식의 데이터는 저장할 수 없고, NoSQL은 다른 구조의 데이터를 추가할 수 있습니다.
NoSQL과 SQL의 종류에 대해 말해보세요
- SQL : MYSQL, PostgreSQL
- NoSQL : mongoDB, redis
💡SQL의 장단점은?
장점
- 명확하게 정의된 스키마로, 데이터의 무결성을 보장합니다.
- 데이터의 중복없이 한번만 저장됩니다.
단점
-
스키마가 사전에 계획되고 알려져야 하기 때문에, 상대적으로 덜 유연해 수정하기가 불가능하거나 번거롭습니다.
-
관계를 맺고있기 때문에, JOIN문이 많은 매우 복잡한 쿼리가 만들어질 수 있습니다.
-
수평적 확장이 어렵고, 수직적 확장만 가능합니다. 즉, 어떤 시점에서 성장 한계에 직면하게 됩니다.
-
관계를 맺고 있는 데이터가 자주 변경(수정)되는 어플리케이션일 경우와 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우일 때 사용하는 것이 유리합니다.
데이터베이스의 수평적 확장과 수직적 확장이란?
- 수평적 확장 : 리소스 풀에 더 많은 시스템을 추가하여 확장하는 방식입니다.
- 수직적 확장 : 기존 시스템에 더 많은 전력(CPU, RAM)을 추가하여 확장 할 수 있음을 의미합니다.
NoSQL은 수평적 확장에 유리하고 SQL은 불리하다고 했는데 예시를 들어 설명해봐라.
RDB가 갖고 있는 관계성 때문에 수평적 확장이 어렵습니다. 게시글과 댓글 테이블이 있고 이 데이터가 A, B, C 서버에 나눠 저장돼있는 상황을 가정해보겠습니다. 최악의 경우 한 게시글의 데이터와 그와 관련된 댓글 데이터가 A, B, C 서버에 나눠 저장돼있을 수 있습니다. 이렇게 되면 한 게시글을 표시하기 위해 A, B, C 서버의 데이터를 조회하고 가져와 조합해야 합니다.
반면, NoSQL에서는 애초에 서비스에 필요한 형태로 한 게시글과 그 하위의 댓글들을 하나의 도큐먼트에 저장할 수 있기 때문에 도큐먼트 단위로 잘라 여러 서버에 나눠 저장하기 수월한 것입니다.
RDB도 한 테이블에 게시글과 댓글 정보 뭉쳐놓으면 똑같지 않나?라고 의문이 생길 수 있지만 이론적으로 가능하겠으나 RDB에 데이터를 그러한 방식으로 저장하는 것은 정규화라는 측면에서 좋지 않은 구조입니다. RDB는 중복된 데이터를 최소화하고 JOIN을 통해 필요한 정보를 조합하는 형태가 바람직하다고 알고 있습니다.
💡NoSQL이랑 RDBMS의 특징과 차이점은? (비 관계형과 관계형의 차이점)

💡RDBMS와 NoSQL은 어느 경우에 적합한가요?
-
RDBMS는 데이터 구조가 명확하고, 변경 될 여지가 없으며 스키마가 중요한 경우 사용하는 것이 좋습니다. 또한 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템에 적합합니다.
-
NoSQL은 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장 될 수 있는 경우 사용하는 것이 좋습니다. 또한 단점에서도 명확하듯 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시 모든 컬렉션에서 수정해야 하기 때문에 Update가 많이 이루어지지 않는 시스템에 좋으며, Scale-out이 가능하다는 장점을 활용해 막대한 데이터를 저장해야 해서 DB를 Scale-out 해야 되는 시스템에 적합합니다.
MongoDB
몽고DB는 강력하고 유연하며 확장성이 높은 범용 데이터베이스다. 보조 인덱스, 범위 쿼리, 정렬, 집계, 공간 정보 인덱스 등을 확장 기능과 결합했다.
-
몽고DB 데이터의 기본 단위는
도큐먼트이며, 이는 관계형 데이터베이스의 행과 유사하다.(하지만 더 다양한 자료 표현이 가능하다) -
같은 맥락에서
컬렉션은 동적 스키마가 없는 테이블과 같다. -
몽고DB의 단일 인스턴스는 자체적인 컬렉션을 갖는 여러 개의 독립적인 데이터베이스를 호스팅한다.
-
모든 도큐먼트는 컬렉션 내에서 고유한 특수키인 "_id"를 가진다.
-
몽고DB는 몽고 셸이라는 간단하지만 강력한 도구와 함께 배포된다. mongo 셸은 몽고DB 인스턴스를 관리하고 몽고DB 쿼리 언어로 데이터를 조작하기 위한 내장 지원을 제공한다. 또한 사용자가 다양한 목적으로 자신의 스크립트를 만들고 로드할 수 있는 완전한 기능의 자바스크립트 해석기다.
손쉬운 사용
몽고DB는 관계형 데이터베이스가 아니라 도큐먼트 지향 데이터 베이스다. 관계형 모델을 사용하지 않는 주된 이유는 분산 확장을 쉽게 하기 위함도 있지만 다른 이점도 있다. 관계형 모델을 사용하지 않는 이유는 분산 확장을 쉽게 하기 위함이지만 다른 이점도 있다.
도큐먼트 지향 데이터베이스에서는 행 개념 대신에 보다 유연한 모델인 도큐먼트를 사용한다. 내장 도큐먼트와 배열을 허용함으로써 도큐먼트 지향 모델은 복잡한 계층 관계를 하나의 레코드로 표현할 수 있다. 이 방식은 최신 객체 지향 언어를 사용하는 개발자의 관점에 매우 적합하다.
또한 몽고DB에서는 도큐먼트의 키와 값을 미리 정의하지 않는다. 따라서 고정된 스키마가 없다. 고정된 스키마가 없으므로 필요할때마다 쉽게 필드를 추가하거나 제거할 수 있다. 덕분에 개발 속도가 향상되고 모델을 실험해보기도 쉽다. 개발자는 수십개의 데이터 모델을 시도해본 후 최선의 모델을 선택할 수 있다.
확장 가능한 설계
애플리케이션 데이터셋의 크기는 놀라운 속도로 증가하고 있다. 가용 대역폭과 값싼 스토리지의 증가로 인해 작은 애플리케이션에도 현재 데이터베이스의 한계를 넘어서는 데이터를 저장하게 됐다. 과거에는 흔치 않았던 테라바이트 수준의 데이터도 이제는 꽤 흔하게 접한다.
저장할 데이터가 증가함에 따라 개발자는 데이터베이스를 어떻게 확장할 것인가라는 어려운 의사 결정을 해야 하는 상황에 직면한다. 데이터베이스의 확장은 결국 더 큰 장비로 성능 확장할지 혹은 여러 장비에 데이터를 나눠 분산 확장할지 결정해야하는 갈림길에 서게 한다.
다양한 기능
몽고DB는 범용 데이터베이스로 만들어졌기 때문에 데이터의 생성, 읽기, 삭제 외에도 데이터베이스 관리 시스템(DBMS)의 대부분의 기능과 더불어 다음과 같은 기능을 제공한다.
-
인덱싱
몽고DB는 일반적인 보조 인덱스를 지원하며 고유, 복합, 공간정보, 전문 인덱싱 기능도 제공한다. 중첩된 도큐먼트 및 배열과 같은 계층 구조의 보조 인덱스도 지원하며, 개발자는 모델링 기능을 애플리케이션에서 가장 적합한 방식으로 최대한 활용할 수 있다. -
집계
몽고DB는 데이터 처리 파이프라인 개념을 기반으로 한 집계 프레임워크를 제공한다. 집계 파이프라인은 데이터베이스 최적화를 최대한 활용해, 서버 측에서 비교적 간단한 일련의 단계로 처리함으로써 복잡한 분석 엔진을 구축하게 해준다. -
특수한 컬렉션 유형
몽고DB는 로그와 같은 최신 데이터를 유지하고자 세션이나 고정 크기 컬렉션(제한 컬렉션)과 같이 특정 시간에 만료해야 하는 데이터에 대해 유효 시간(TTL) 컬렉션을 지원한다. 또한 기준 필터와 일치하는 도큐먼트에 한정된 부분 인덱스를 지원함으로써 효율성을 높이고 필요한 저장 공간을 줄인다. -
파일 스토리지
몽고DB는 큰 파일과 파일 메타데이터를 편리하게 저장하는 프로토콜을 지원한다.
관계형 데이터베이스에 공통적으로 사용하는 일부 기능, 특히 복잡한 조인(join)은 몽고DB에 존재하지 않는다. 몽고DB는 3.2에 도입된 $lookup 집계 연산자를 사용함으로써 매우 제한된 방식으로 조인하도록 지원한다. 3.6 버전에서는 관련 없는 서브쿼리 뿐만 아니라 여러 조인 조건으로 보다 복잡한 조인도 할 수 있다.
고성능
몽고DB는 주요 목표인 성능은 몽고DB 설계에 지대한 영향을 미쳤다. 몽고DB에서는 동시성과 처리량을 극대화하기 위해 와이어드타이거 스토리지 엔진에 기회적 락을 사용했다. 따라서 캐시처럼 제한된 요량의 램으로 쿼리에 알맞은 인덱스를 자동으로 선택할 수 있다. 요약하자면 몽고DB는 모든 측면에서 고성능을 유지하기 위해 설계됐다.
몽고DB는 강력한 성능을 제공하면서도 관계형 시스템의 많은 기능을 포함한다. 하지만 관계형 데이터베이스의 작업을 전부 하려는 것은 아니다. 일부 기능의 경우 데이터베이스 서버는 처리와 로직을 클라이언트 측에 오프로드한다(드라이버 또는 사용자의 애플리케이션 코드에 의해 처리된다). 이러한 간단한 설계 때문에 몽고DB는 뛰어난 성능을 발휘한다.
도큐먼트
몽고 DB의 핵심은 정렬된 키와 연결된 값의 집합으로 이루어진 도큐먼트다. 도큐먼트 표현 방식은 프로그래밍마다 다르지만 대부분의 언어는 맵(map), 해쉬(hash), 딕셔너리(dictionary)와 같이 도큐먼트를 자연스럽게 표현하는 자료구조를 가진다. 예를들어 자바스크립트에서 도큐먼트는 객체로 표현한다.
컬렉션
컬렉션은 도큐먼트의 모음이다. 몽고DB의 도큐먼트가 관계형 데이터베이스의 행에 대응된다면 컬렉션은 테이블에 대응된다고 볼 수 있다.
동적 스키마
컬렉션은 동적 스키마를 가진다. 하나의 컬렉션 내 도큐먼트들이 모두 다른 구조를 가질 수 있다는 의미다. 예를 들어 다음 도큐먼트들을 하나의 컬렉션에 저장할 수 있다.
{"greeting" : "Hello, world!", "views": 3}
{"signoff" : "Good ngint, and good luck"}도큐먼트들의 키, 키의 개수, 데이터 형의 값은 모두 다르다. 다른 구조의 도큐먼트라도 같은 컬렉션에 저장할 수 있는데 왜 하나 이상의 컬렉션이 필요할까?
-
같은 컬렉션에 다른 종류의 도큐먼트를 저장하면 개발자와 관리자에게 번거로운 일이 생길 수 있다. 각 쿼리가 특정 스키마를 고수하는 도큐먼트를 반환하는지, 혹은 쿼리한 코드가 다른 구조의 도큐먼트를 다룰 수 있는지 확실히 확인하자. 예를들어 블로그 게시물을 쿼리한 데이터 중 작성자 데이터만 제거하려면 상당히 번거롭다.
-
컬렉션별로 목록을 뽑으면 한 컬렉션에 내 특정 데이터형별로 쿼리해서 목록을 뽑을 때보다 훨씬 빠르다. 예를들어 "요약", "전체", "뚱뚱이 원숭이"와 같은 컬렉션형을 값으로 하는 type 키가 도큐먼트 내에 있다면, 단일 컬렉션에 들어 있는 값을 찾기보다 세 컬렉션 중에서 올바른 컬렉션을 쿼리하는 편이 훨씬 빠르다.
-
같은 종류의 데이터를 하나의 컬렉션에 모아두면 데이터 지역성에도 좋다. 블로그 게시물 여러개를 뽑는 경우, 게시물과 저자 정보가 섞인 컬렉션보다 게시물만 들어 있는 컬렉션에서 뽑을 때 디스키 탐색 시간이 더 짧다.
-
인덱스를 만들면 도큐먼트는 특정 구조를 가져야 한다(고유 인덱스일 경우 특히 더 그렇다). 이러한 인덱스는 컬렉션별로 정의한다. 같은 유형의 도큐먼트를 하나의 컬렉션에 넣음으로써 컬렉션을 효율적으로 인덱싱할 수 있다.
네이밍
컬렉션은 이름으로 식별된다. 컬렉션명은 어떤 UTF-8 문자열이든 쓸 수 있지만 몇가지 제약 조건이 있다.
-
빈 문자열("")은 유효한 컬렉션 명이 아니다.
-
\0(null 문자)은 컬렉션명의 끝을 나타내는 문자이므로 컬렉션명에 사용할 수 없다.
-
system.으로 시작하는 컬렉션명은 시스템 컬렉션에서 사용하는 예약어이므로 사용할 수 없다.
-
사용자가 만든 컬렉션은 이름에 예약어인 $를 포함할 수 없다. 시스템에서 생성한 몇몇 컬렉션에서 $ 문자를 사용하므로 데이터베이스에서 사용하는 다양한 드라이버가 $ 문자를 포함하는 컬렉션명을 지원하기는 한다. 이럴 때 빼고는 $를 사용하면 안된다.
서브컬렉션
서브컬렉션은 네임스페이스에 .(마침표) 문자를 사용해 컬렉션을 체계화한다. 예를들어 블로그 기능이 있는 애플리케이션은 blog.posts와 blog.authors라는 컬렉션을 가질 수 있다. 이는 단지 체계화를 위함이며 blog 컬렉션이나 자식 컬렉션과는 아무런 관계가 없다.
데이터베이스
컬렉션에는 도큐먼트를 그룹화할 뿐 아니라 데이터베이스에 컬렉션을 그룹 지어 놓는다. 몽고DB의 단일 인스턴스는 여러 데이터베이스를 호스팅할 수 있으며, 각 데이터베이스를 완전히 독립적으로 취급할 수 있다. 한 애플리케이션의 데이터를 동일한 데이터베이스에 저장하는 것은 좋은 방식이다. 데이터베이스를 나누면 하나의 몽고DB 서버에서 여러 애플리케이션이나 여러 사용자 데이터를 저장할 때 유용하다.
제약조건
- 빈 문자열("")은 유효한 데이터베이스 이름이 아니다.
- 데이터베이스 이름은 다음 문자를 포함할 수 없다. /, \, ., '', *, <, >, :, ?, $,공백, \0(null 문자)
- 데이터베이스 이름은 대소문자를 구별한다.
- 데이터베이스 이름은 최대 64바이트다.





