
@Bean이란?
빈(Bean)은 스프링 컨테이너에 의해 관리되는 재사용 가능한 소프트웨어 컴포넌트이다.
스프링에서 보면 @Bean을 자주 사용하는데 @Bean 어노테이션은 해당 메서드가 Spring IoC(제어의 역전) 컨테이너에 의해 관리되는 빈(Bean)을 생성한다는 것을 나타냅니다.
실무에서는 주로 정형화된 컨트롤러, 서비스, 리포지토리 같은 코드는 컴포넌트 스캔을 사용한다. 그리고 정형화 되지 않거나, 상황에 따라 구현 클래스를 변경해야 하면 설정을 통해 스프링 빈으로 등록한다.
@Autowired,@RequiredArgsConstructor를 통한DI는 helloController , memberService 등과 같이 스프링이 관리하는 객체에서만 동작한다. 스프링 빈으로 등록하지 않고 내가 직접 생성한 객체에서는 동작하지 않는다. 이 2개를 사용하면 스프링에서 알아서 필요한 부분을 주입을 해줍니다. 즉, 필요한 부분에 빈을 주입을 해줍니다.
스프링은 스프링 컨테이너에 스프링 빈을 등록할 때, 기본으로
싱글톤으로 등록한다(유일하게 하나만 등록해서 공유한다) 따라서 같은 스프링 빈이면 모두 같은 인스턴스다. 설정으로 싱글톤이 아니게 설정할 수 있지만, 특별한 경우를 제외하면 대부분 싱글톤을 사용한다.
빈 관리
스프링의 IoC 컨테이너는 Bean 객체들을 책임지고 의존성을 관리한다. 객체들을 관리한다는 것은 객체의 생성부터 소멸까지의 생명주기(LifeCycle) 관리를 개발자가 아닌 컨테이너가 대신 해준다는 말이다.객체 관리의 주체가 프레임워크(Container)가 되기 때문에 개발자는 로직에 집중할 수 있는 장점이 있다.
스프링 빈 이벤트 라이프 사이클
먼저 스프링 Bean의 LifeCycle을 보면 다음과 같다.
스프링 IoC 컨테이너 생성 → 스프링 빈 생성 → 의존관계 주입 → 초기화 콜백 메소드 호출 → 사용 → 소멸 전 콜백 메소드 호출 → 스프링 종료
스프링은 의존관계 주입이 완료되면 스프링 빈에게 콜백 메소드를 통해 초기화 시점을 알려주며,스프링 컨테이너가 종료되기 직전에도 소멸 콜백 메소드를 통해 소멸 시점을 알려준다.
@Configuration vs @Component
@Configuration은 내부적으로 @Component를 상속받고 있다. @Component를 사용해서 원하는 클래스를 빈으로 등록할 수 있는데 @Configuration이 왜 필요한 걸까?
포인트는 @Component는 구현한 클래스 위에 선언해야 하지만, @Configuration은 @Bean이 붙은 메서드 내부에서 생성한 객체를 빈으로 등록할 수 있다는 점이다.
외부에서 구현한 클래스를 빈으로 등록하고 싶은데, 이 클래스가 read-only로 쓰였다면 @Component를 클래스 위에 선언할 수 없다. @Configuration을 사용하면, 메서드 내부에서 해당 클래스를 호출해 반환함으로써 빈으로 등록할 수 있다. 또, 하나의 클래스에서 빈들을 관리하고 싶거나, 특정 패키지 내부에 있는 빈들만 스프링 컨테이너에 등록하고 싶은 경우는 @Configuration을 사용하면 편리하게 관리할 수 있다.
생성자 주입을 권고 하는 이유
1. SRP(단일 책임의 원칙)를 위반할 확률이 줄어든다.
우리가 작성한 비즈니스 로직을 담당하는 클래스는 하나의 책임에 집중되어 있어야 합니다. 이는 객체지향 프로그래밍의 원칙 중 하나입니다. 생성자 주입을 사용하지 않고 필드 주입을 사용하게 될 경우 클래스 내부에 선언된 필드에 그저 @Autowired를 붙이는 것만으로 쉽게 의존성을 사용할 수 있습니다. 쉽게 의존성을 주입할 수 있다는 것은 하나의 클래스가 여러 가지 기능을 담당하게 만들기도 쉽다는 이야기랑 같습니다. 그러나 생성자 주입을 사용하게 되면 생성자 파라미터에 사용하고자 하는 필드를 모두 넣어주어야 하기 때문에 코드가 길어지고 그로 인해 경각심을 가질 수 있습니다.
2. 필드에 final을 선언할 수 있다.
생성자 주입을 제외한 필드, 수정자 주입은 final을 선언할 수 없습니다. 필드에 final을 붙이기 위해서는 클래스의 인스턴스가 생성될 때 final이 붙은 필드를 반드시 초기화해야 합니다. Field /Setter Injection은 우선 인스턴스가 생성된 후에 해당 필드에 의존성 주입이 진행되므로 final을 붙일 수 없습니다. 그러나 생성자 주입은 필드를 파라미터로 받는 생성자를 통해 클래스의 인스턴스가 생성될 때 의존성 주입이 일어나고, 이 때 final 붙은 필드가 초기화됩니다. 우리가 웹 개발을 할 때 Bean객체의 필드 값이 바뀌는 일은 거의 없을 겁니다. 그러므로 필드에 final을 붙여 불변성을 가지도록 하는 것이 좋습니다.
3. DI 컨테이너에 독립적인 테스트 코드를 작성할 수 있다.
개발을 할 때 테스트 코드를 작성하는 것은 매우 중요합니다. 필드 주입을 사용하게 되면 테스트 코드에서 어떻게 내부 필드에 인스턴스를 넣어 줄 수 있을까요??? 아래와 같이 일반적인 JUnit을 사용하는 테스트 코드에서는 불가능합니다. 왜냐하면 일반적으로 필드의 접근 제한자를 public으로 하게 되면 외부에서 필드의 값을 변경할 수 있으므로 대부분은 이를 방지하기 위해 private로 선언합니다. Field Injection일 때 테스트 코드를 작성하기 위해서는 DI컨테이너를 사용하는 테스트 코드를 작성해야 합니다. 그러나 Constructor / Setter Injection을 사용하게 되면 DI컨테이너에 독립적으로 테스트 코드를 작성할 수 있습니다.

4. 순환 참조를 발견할 수 있다.
@Autowired를 사용고 생성자 주입을 할 수 있지만 @RequiredArgsConstructor로 생성자 주입을 하면 코드에 final만 붙이면 생성자 주입이 되서 코드가 간결해지고 가독성이 높아집니다. 그리고 불변성을 유지할 수 있어서 생성자를 통해 필드 값을 초기화하고 나면 해당 필드의 값을 변경할 수 없게 됩니다. 이는 불변성을 강제하여 안정성을 높이는데 도움이 됩니다. @RequiredArgsConstructor를 사용하면 필드를 추가하거나 제거할 때 Lombok이 알아서 생성자를 갱신해주므로 유지보수가 쉬워집니다.
레이어드 아키텍처
레이어드 아키텍처란 애플리케이션의 컴포넌트를 유사 관심사를 기준으로 레이어로 묶어 수평적으로 구성한 구조를 의미합니다.레이어드 아키텍처는 여러 방면에서 쓰이는 개념이며, 어떻게 설계하느냐에 따라 용어와 계층 수가 달라집니다.
일반적으로 레이어드 아키텍처라 하면 3계층 또는 4계층 구성을 의미합니다. 이 차이는 인프라(데이터 베이스) 레이어의 추가 여부로 결정됩니다.
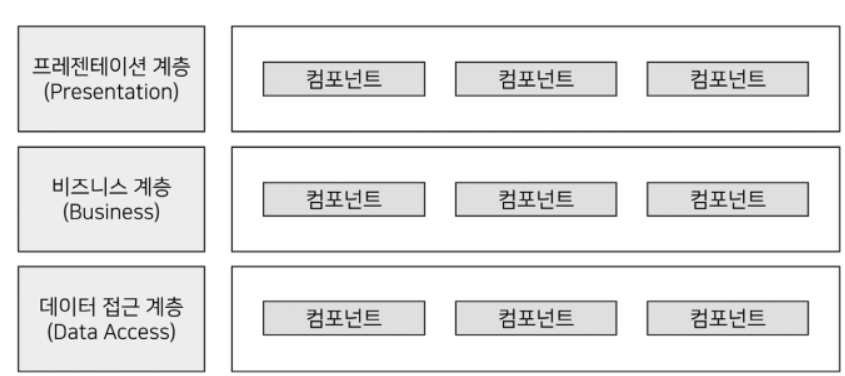
프레젠테이션 계층
- 애플리케이션의 최상단 계층으로, 클라이언트의 요청을 해석하고 응답하는 역할입니다.
- UI나 API를 제공합니다.
- 프레젠테이션 게층은 별도의 비즈니스 로직을 포함하고 있지 않으므로 비즈니스 계층으로 요청을 위임하고 받은 결과를 응답하는 역할만 수행합니다.
- 상황에 따라 유저 인터페이스 계층이라고도 합니다.
- 클라이언트와의 접점이 됩니다.
- 클라이언트로부터 데이터와 함께 요청을 받고 처리 결과를 읍답하는 역할입니다.
비즈니스 계층
- 애플리케이션이 제공하는 기능을 정의하고 세부 작업을 수행하는 도메인 객체를 통해 업무를 위임하는 역할을 수행
- DDD(Domain-Driven-Design) 기반의 아키텍처에서는 비즈니스 로직에 도메인이 포함되기도 하고, 별도로 도메인 계층을 두기도 합니다.
- 상황에 따라 서비스 계층이라고도 합니다.
- 핵심 비즈니스 로직을 구현하는 영역
- 트랜잭션 처리나 유효성 검사 등의 작업도 수행
데이터 접근 계층
- 데이터베이스에 접근하는 일련의 작업을 수행
- 상황에 따라 영속 계층이라고도 한다.
- 레포지토리로 대체할 수 있다.
레이어드 아키텍처는 하나의 애플리케이션에도 적용되지만 애플리케이션 간의 관계를 설명하는 데도 사용할 수 있습니다. 레이어드 아키텍처 기반 설계는 다음과 같은 특징을 가집니다.
- 각 레이어는 가장 가까운 하위 레이어의 의존성을 주입받습니다.
- 각 레이어는 관심사에 따라 묶여 있으며, 다른 레이어의 역할을 침범하지 않습니다.
- 각 컴포넌트의 역할이 명확하므로 코드의 가독성의 기능 구현에 유리합니다.
- 코드의 확장성도 좋아집니다.
- 각 레이어가 독립적으로 작성되면 다른 레이어와의 의존성을 낮춰 단위 테스트에 용이합니다.
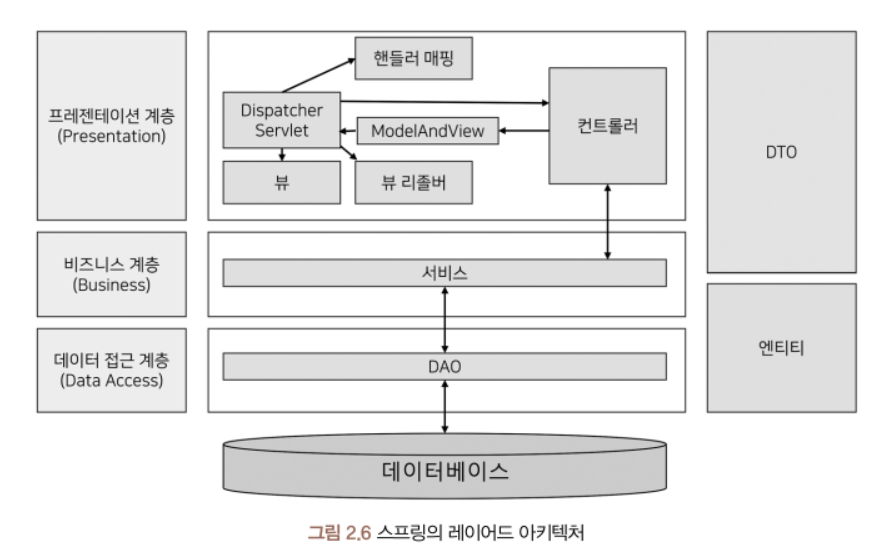
그림 2.6은 레이어드 아키텍처를 스프링에 적용한 모습입니다. Spring MVC는 Model- View-Controller의 구조로 View와 Controller는 프레젠테이션 계층 영역이며, Model은 비즈니스와 데이터 접근 계층의 영역으로 구분합니다. 다만 스프링MVC 모델로 레이어드 아키텍처를 구현하기 위해서는 역할을 세분화합니다. 비즈니스 계층에 서비스를 배치해 엔티티와 같은 도메인 객체의 비즈니스 로직을 조합하도록 하고 데이터 접근 계층에는 DAO(Spring Data JPA에서는 Repository)를 배치해 도메인을 관리합니다.
스프링의 레이어드 아키텍처는 다음과 같이 설명할 수 있습니다.
이렇게 처리함에 따라 하나의 레이어는 자신의 고유 역할을 수행하고 인접한 다른 레이어에 무언가 요청하거나 응답합니다. 각 레이어는자신의 역할에 충실할 수 있습니다. 따라서 시스템 전체를 수정하지 않고 특정한 레이어의 기능을 개선하거나 교체할 수 있기 때문에 재사용성이 좋고 유지보수하기 유리합니다. 그리고 테스트 구현이 편해지고 코드 가독성이 좋아집니다.
Filter, Interceptor
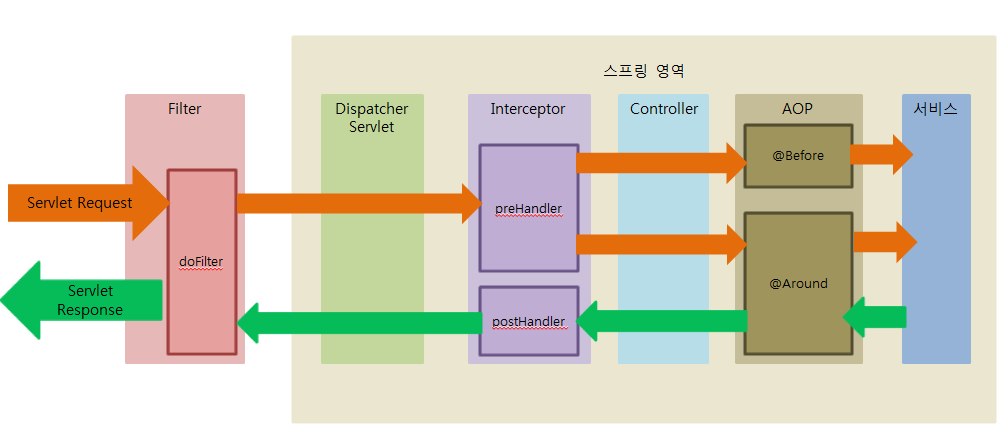
Filter
- Dispatcher Servlet에 요청이 전달되기 전/후에 url 패턴에 맞는 모든 요청에 대해 부가 작업을 처리하는 기능을 제공
- 톰켓과 같은 웹 컨테이너에서 동작하기 때문에 Spring과 무관한 자원에 대해 동작
- init
- 필터 객체를 초기화하고 서비스에 추가하기 위한 메소드
- 웹 컨테이너에서 1회 init 메서드를 호출하여 필터 객체를 초기화하면 이후 요청들은 doFilter를 통해 전/후처리가 된다.
- doFilter
- url-pattern에 맞는 모든 HTTP 요청이 디스페처 서블릿으로 전달되기 전/후에 웹 컨테이너에 의해 실행되는 메서드
- doFilter 파라미터로 FilterChain이 있는데, FilterChain의 doFilter를 통해 다음 대상으로 요청을 전달한다.
- destory
- 필터 객체를 서비스에서 제거하고 사용하는 자원을 반환하는 메소드
- 웹 컨테이너에 의해 1번 호출
Interceptor
- Spring에 제공하는 기술로 Dispatcher Servlet이 컨트롤러를 호출하기 전/후에 요청과 응답을 참조하거나 가공할 수 있는 기능을 제공
- 스프링 컨텍스트에서 동작
- 스프링 컨텍스트에서 동작하므로 @ControllerAdvice을 사용하여 예외처리
- perHandle
컨트롤러가 호출되기 전에 실행되어 컨트롤러 이전에 처리해야 하는 전처리 작업이나 요청 정보를 가공하거나 추가하는 경우 사용가능
- postHandle
- 컨트롤러 호출된 후에 실행되어 컨트롤러 이후에 처리해야 하는 후처리 작업이 있을 때 사용할 수 있다.
- 보통 컨트롤러가 반환하는 ModelAndView 타입의 정보가 제공되는데 최근에는 JSON 형태로 데이터를 제공하는 REST API 기반의 컨트롤러가 사용되면서 잘 사용하지 않는다.
- afterCompletion
- 모든 뷰에서 최종 결과를 생성하는 일을 포함해 모든 작업 완료된 후 실행
- 요청 처리 중에 사용한 리소스를 반환할 때 사용하기 적합

AOP와 Interceptor 차이
AOP와 Interceptor가 비슷한 기능을 수행한다고 할 수 있는데 이들의 사용을 구분 짓는 방법은파라미터입니다. 모든 메서드의 파라미터와 타입은 제각각이기 때문에 이에 대해 AOP를 적용하게 되면 부가 작업들이 생식게 된다. 그리고 Service 앞에서 동작한다. 반면 Interceptor의 경우 HttpServletRequest, HttpServletResponse를 파라미터로 사용하기 때문에 부가 작업이 필요고 Controller 앞에서 동작합니다.
💡스프링 filter와 interceptor의 차이는 무엇인가요
필터는 J2EE(자바 기술) 표준 스펙 기능으로 디스패처 서블릿에 요청이 전달되기 전/후에 url패턴에 맞는 모든 요청에 대해 부가작업을 처리할 수 있는 기능을 제공합니다. 필터는 웹 컨테이너가 관리하고, 보안 관련, 모든 요청에대한 로깅 또는 감사, 이미지/데이터 압축 및 문자열 인코딩 등에 쓰입니다.
인터셉터는 스프링이 제공하는 기술로써, 디스패처 서블릿이 컨트롤러를 호출하기 전과 후에 요청과 응답을 참조하거나 가공할 수 있는 기능을 제공합니다. 인터셉터는 스프링 컨테이너가 관리하며, 인증/인가 등과 같은 공통 작업, API호출에 대한 로깅 또는 감사, Controller로 넘겨주는 정보의 가공 등에 쓰입니다.
💡Bean이란? 등록방법은?
스프링 IoC 컨테이너가 관리하는 객체들을 Bean이라고 부릅니다.
@Component 어노테이션을 통해 개발자가 직접 작성한 class를 빈으로 등록해줄 수 있습니다. 컨테이너 안에 들어있는 객체를 빈이라고 하는데 필요할 때 컨테이너에서 가져와서 사용합니다. 메소드를 빈으로 등록할 때는 @Bean을 사용하면 됩니다.
@SpringBootApplication 어노테이션 정의를 보면 @ComponentScan 어노테이션이 붙어있음. 이 어노테이션은 어느 지점부터 컴포넌트를 찾아보라고 알려 주는 것. 이를 통해 찾아서 등록해준다.
생명주기
스프링 컨테이너 실행 → 스프링 빈 생성 → 의존 관계 주입 → 초기화 콜백 → 사용 → 소멸전 콜백 → 스프링 종료
- 스프링 컨테이너에서 생명주기 관리
- 스프링 컨테이너 초기화 시 빈 객체 생성, 의존 객체 주입 및 초기화
- 싱글톤 빈들은 컨테이너가 종료되기 직전에 소멸전 콜백이 발생
💡스프링 컨테이너의 생명주기는 어떻게 되나요?
스프링 컨테이너는 자바 객체의 생명 주기를 관리하며, 생성된 자바 객체들에게 추가적인 기능을 제공하는 역할한다. 스프링 컨테이너의 종류에는 BeanFactory와 ApplicationContext 가 있다. 둘 다 빈을 등록하고 생성하고 조회하고 돌려주는 등 빈을 관리하는 역할을 한다. ApplicationContext가 BeanFactory의 빈 관리 기능들을 상속받았고, 그 외에 국제화 등의 추가적인 기능을 갖고 있어 스프링 컨테이너라고 하면 보통 ApplicationContext라고 한다. IoC와 DI의 원리가 이 스프링 컨테이너에 적용된다. ApplicationContext 구현 클래스를 이용한 스프링 컨테이너 초기화(생성), getBean()을 이용한 빈(Bean) 객체 이용, close()를 이용한 스프링 컨테이너 종료가 있습니다.
Bean의 생명주기 : 스프링 컨테이너의 생명주기와 동일
1. 스프링 컨테이너 초기화: 빈 객체 생성 및 주입
2. 스프링 컨테이너 종료: 빈 객체 소멸
💡BeanFactory와 ApplicationContext의 차이점은 무엇입니까?
BeanFactory는 Bean을 제공하고 관리하는 기본적인 IoC컨테이너 인터페이스를 뜻합니다. 기본 구현은 getBean()이 호출될 때 빈을 인스턴스화합니다. ApplicationContext는 BeanFactory의 확장된 버전으로, 애플리케이션에 대한 모든 정보, 메타 데이터도 가지고 있습니다. 기본구현은 어플리케이션이 시작될 때 빈을 인스턴스화합니다.
스프링 부트의 자동설정
스프링 부트로 만든 프로젝트에는 애플리케이션 실행을 위한 메인 클래스가 기본적으로 제공된다. 이 메인 클래스를 실행하면 내장 톰캣이 구동되고 스프링 기반의 웹 애플리케이션이 잘 동작하는 것을 확인할 수 있다. 하지만 스프링 MVC를 이용해서 웹 애플리케이션을 개발할 때는 여러가지 설정이 필요하다.
하지만 이런 복잡한 설정 없이도 웹 애플리케이션을 만들고 실행할 수 있었다. 이런 것이 가능한 이유는 스프링 부트가 제공하는 자동설정 기능이 동작하여 수 많은 빈들이 등록하고 동작했기 때문이다. 이 비밀은 메인 클래스 위에 선언된 @SpringBootApplication에 있다.
그러면 어떻게 스프링 부트는 메인 클래스의 @SpringBootApplication 하나만으로 복잡한 설정들을 대신할 수 있었을까? 사실은 @EnableAutoConfiguration 어노테이션 때문이다.
@SpringBootApplication에 들어가면 많은 어노테이션 중에서 중요한 것은 @SpringBootConfiguration, @ComponentScan, @EnableAutoConfiguration이다.
@SpringBootConfiguration은 @Configuration과 동일하다. 단지 이 클래스가 스프링 부트 환경설정 클래스임을 표현하기 위해 이름만 @SpringBootConfiguration로 표현한 것이다. 나머지 두 개는 초기화와 관련된 어노테이션인데, 먼저 @ComponentScan은 @Configuration, @Repository, @Service, @RestController, @Controller가 붙은 객체를 메모리에 올려주는 역할을 한다.
@EnableAutoConfiguration은 자동설정과 관련된 어노테이션이다. 스프링 부트는 스프링 컨테이너를 구동할 때 두 단계로 나누어 객체들을 초기화(생성)한다. 스프링 부트가 이렇게 두 단계로 나누어 빈들을 초기화하는 이유는 애플리케이션을 운영하기 위해서는 두 종류의 빈들이 필요하기 때문이다.
예를들어, 웹 애플리케이션에서 파일 업로드 기능을 추가한다고 가정하자면 파일 업로드를 추가하기 위해서는 먼저 BoardController 같은 컨트롤러를 MultipartFile 객체를 이용해서 업로드 가능한 컨트롤러로 구현해야 합니다. 그런데 실제로 파일 업로드 기능이 동작하기 위해서는 반드시 사용자가 업로드한 파일 정보가 MultipartFile 객체에 설정되어 있어야 하며, 이를 위해서 멀티파트 리졸버 객체가 반드시 필요합니다. 즉, 파일 업로드가 정상적으로 동작하기 위해서는 내가 만든 컨트롤러뿐만 아니라 이를 위해 멀티파트 리졸버 객체를 메모리에 올리는 두 개의 객체 생성 과정이 필요한 것이다. 결국 @ComponentScan은 내가 만든 컨트롤러 객체를 메모리에 올리는 작업을 처리하고 @EnableAutoConfiguration은 CommonsMultipartResolver 같은 객체들을 메모리에 올리는 작업을 처리한다.
@Configuration은 이클래스가 스프링 빈 설정 클래스임을 의미한다. 따라서 @ComponentScan이 처리될 때 자신뿐만 아니라 이 클래스에 @Bean으로 설정된 모든 빈들도 초기화된다.
@ConditionalOnWebApplication은 웹 애플리케이션 타입이 어떻게 설정되어 있느냐를 확인하는 어노테이션이다.
@ConditionalOnClass는 특정 클래스가 클래스 패스에 존재할 때, 현재 설정 클래스를 적용하라는 의미다.
💡템플릿 메소드 패턴이란 무엇인가요?
Gof의 디자인 패턴 중 하나로써, 알고리즘 구조에서 일부 기능을 자식 클래스가 확장할 수 있도록 템플릿을 제공하는 패턴입니다. 즉, 공통된 기능은 부모 클래스에서 정의하고 자식 클래스마다 다른 기능들을 오버라이딩 가능하게끔 추상메서드로 열어둡니다.
장점으로는 코드를 재사용하여 중복 코드를 줄일 수 있고, 공통된 기능이 바뀐다 하더라도 한번만 수정하면 됩니다. 단점으로는 상속을 씀으로써 리스코프 치환원칙에 위반될 수 있는 가능성이 있습니다. 왜냐하면 하위클래스에서 오버라이딩 하여 기능을 바꿀수 있기 때문입니다. 템플릿 부분은 final로 막을 수 있지만 구현 클래스는 막을 수 없습니다.
※ 리스코프 치환 원칙이란?
상속 구조에서 상위클래스의 타입으로 사용하는 코드에서 해당 코드를 하위클래스로 바꾸더라도 코드가 의도한대로 동작을 해야 한다.
💡리다이렉트란?
리다이렉트는 서버에서 클라이언트 요청한 URL에 대한 응답에서 다른 URL로 재접속하라고 명령을 보내는 것을 말합니다.
상품 주문을 했을 때 그냥 가게하면 새로고침을 하면 두번 주문을 하게 될 수 있으므로 리다이렉트를 해서 새로고침을 해도 두번 주문이 안되게 할 수 있다.
💡포워드란?
클라이언트가 한 번 더 요청을 보내도록 하는 리다이렉트와 다르게 포워드는 서버 내부에서 일어나는 호출이다. 클라이언트의 URL에 대한 요청이 들어오면 해당 URL이 다른 URL로 포워딩 된 것이 확인되었을 경우 서버에서 포워딩된 URL의 리소스를 확인하여 클라이언트에 응답합니다. 포워딩이 일어나면 클라이언트 단에서는 아무런 동작을 하지 않으며, 모든 동작을 서버에서 처리합니다. 따라서 클라이언트(웹브라우저)에서 요청한 URL은 물론 요청 정보는 바뀌지 않습니다.
💡리다이렉트와 포워드 사용
사용자 정보가 바뀌어버리는 리다이렉트와 요청 정보는 그대로 유지한체 서버 내부의 동작만 바뀌는 포워드는 적절히 사용되어야 합니다. 리다이렉트의 경우 다음과 같은 경우에서 사용됩니다. 로그인을 한 회원만 볼 수 있는 마이페이지가 있을 때, 로그인 하지 않은 사람이 마이페이지 url로 접속하려 한다고 하자. 이때, 로그인을 하지 않은 회원의 경우 마이페이지에 접속할 수 있는 권한이 없기 때문에 로그인 페이지로 리다이렉트를 걸거나 메인 페이지로 리다이렉트 걸어줄 수 있다. 포워드는 특정 URL에 대해 외부에 공개되지 말아야하는 부분을 가리는데 사용하거나 조회를 위해 사용합니다.
ResponseEntity 타입
일반적인 API는 반환하는 리소스에 Value 값만 있지 않습니다. 상태코드, 상태 메시지 등등 데이터들이 있는데 이러한 Data를 return 하는 것을 주 용도로 사용하는 것이 ResponseEntity입니다. ResponseEntity란 httpentity를 상속받는, 결과 데이터와 HTTP 상태 코드를 직접 제어할 수 있는 클래스이다. ResponseEntity에는 사용자의 HttpRequest에 대한 응답 데이터가 포함된다. 또한, HTTP 아케텍쳐 형태에 맞게 Response를 보내주는 것에도 의미가 있습니다. RestController는 별도의 View를 제공하지 않는 형태로 서비스를 실행합니다. 때문에 결과 데이터가 예외적인 상황에서 문제가 발생할 수 있습니다.
Web을 다루다 보면 HTTP 프로토콜의 헤더를 다루는 경우도 종종 있습니다. 스프링 MVC의 사상은 HttpServletRequest나 HttpServletResponse를 직접 핸들링하지 않아도 이런 작업이 가능하도록 작성되었기 이러한 처리를 위해 ResponseEntity를 통해 원하는 헤더 정보나 데이터를 전달할 수 있습니다.
ResponseEntity란, httpentity를 상속받는, 결과 데이터와 HTTP 상태 코드를 직접 제어할 수 있는 클래스이다. ResponseEntity에는 사용자의 HttpRequest에 대한 응답 데이터가 포함된다.
✨ 또한, HTTP 아케텍쳐 형태에 맞게 Response를 보내주는 것에도 의미가 있습니다.
에러 코드와 같은 HTTP상태 코드를 전송하고 싶은 데이터와 함께 전송할 수 있기 때문에 좀 더 세밀한 제어가 필요한 경우 사용한다고 합니다.
ResponseEntity는 개발자가 직접 결과 데이터와 HTTP 상태 코드를 직접 제어할 수 있는 클래스로 개발자는 404나 500 ERROR와 같은 HTTP 상태 코드를 전송하고 싶은 데이터와 함께 전송할 수 있기 때문에 좀 더 세밀한 제어가 필요한 경우 사용합니다.
사용 이유
ResponseEntity를 사용하면, 객체와 status를 함께 보내줄 수 있다. 때문에 @ResponseStatus를 사용하지 않아도 되고 메서드 별로 다른 status를 리턴할 수 있기 때문에 좀 더 세밀하게 상태 전송이 가능하다.
HTTP Status Code (상태 코드)
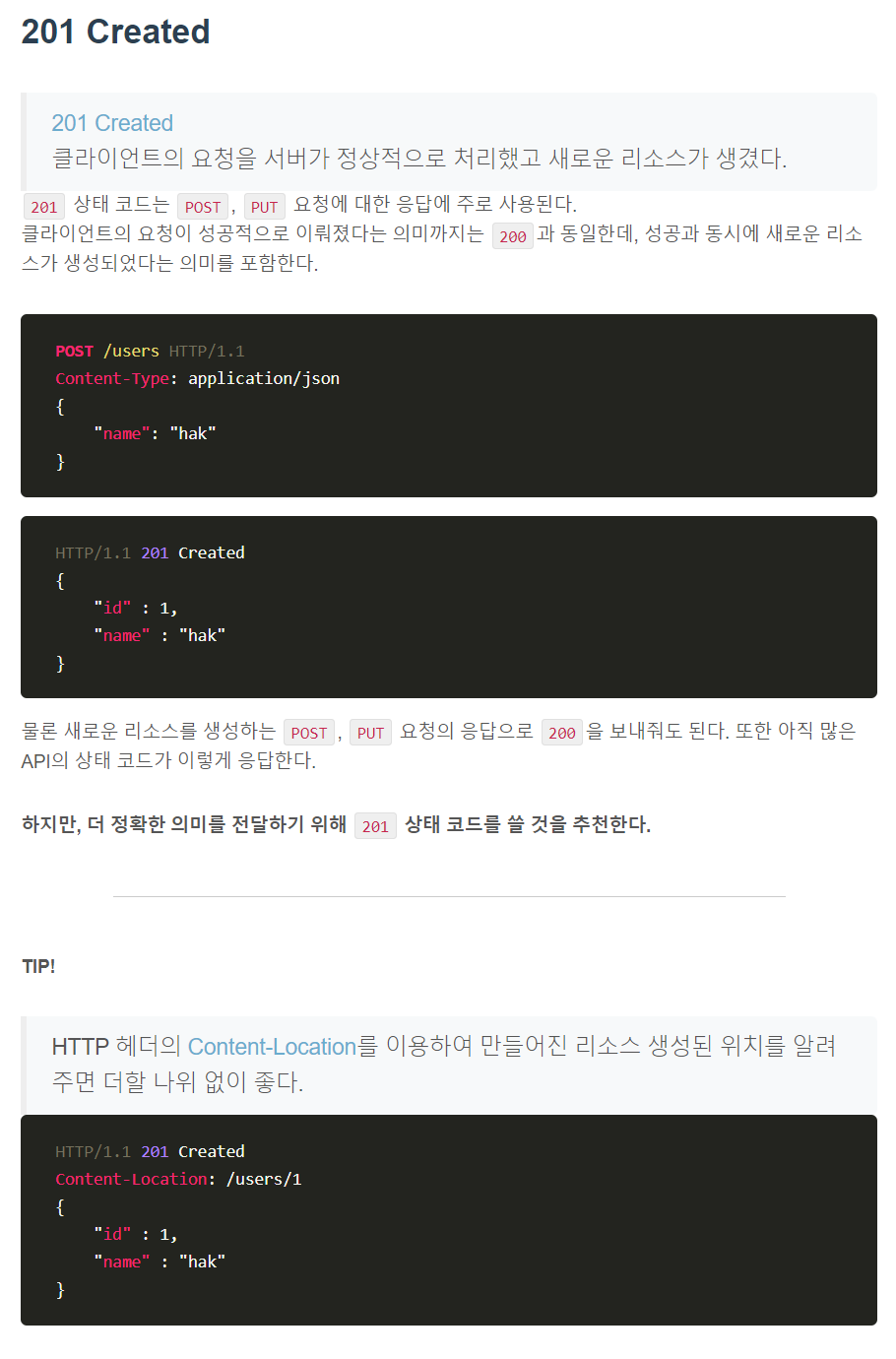
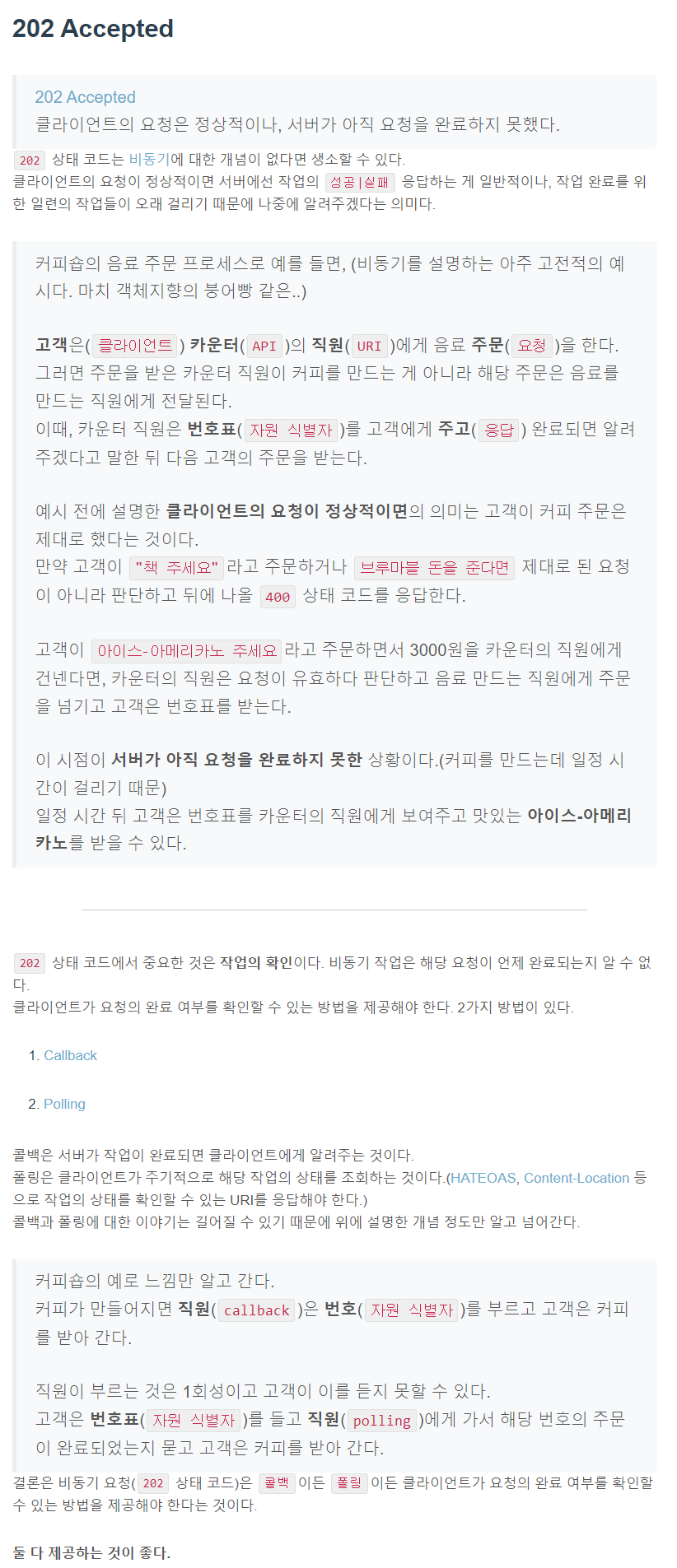
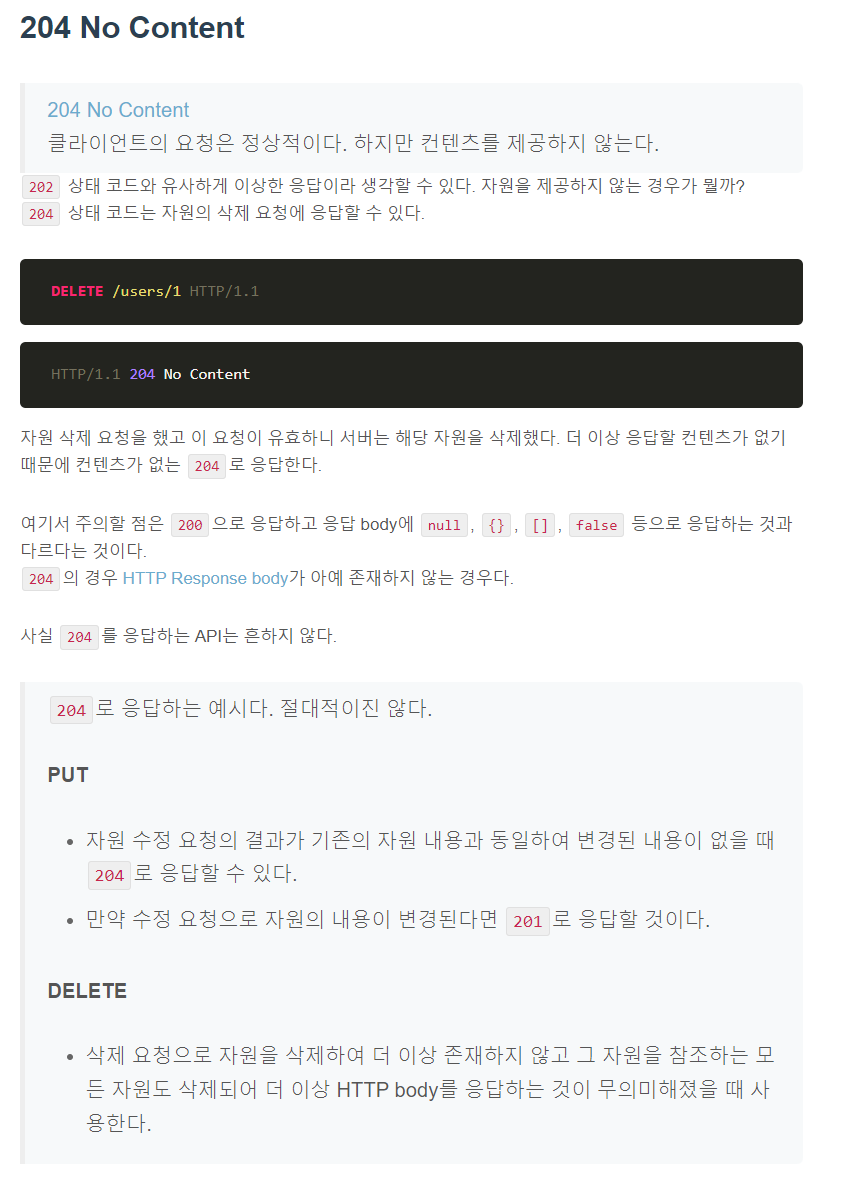
HTTP Status code, 상태 코드는 HTTP 요청이 성공했는지 실패했는지를 서버에서 알려주는 코드다.
2xx 성공
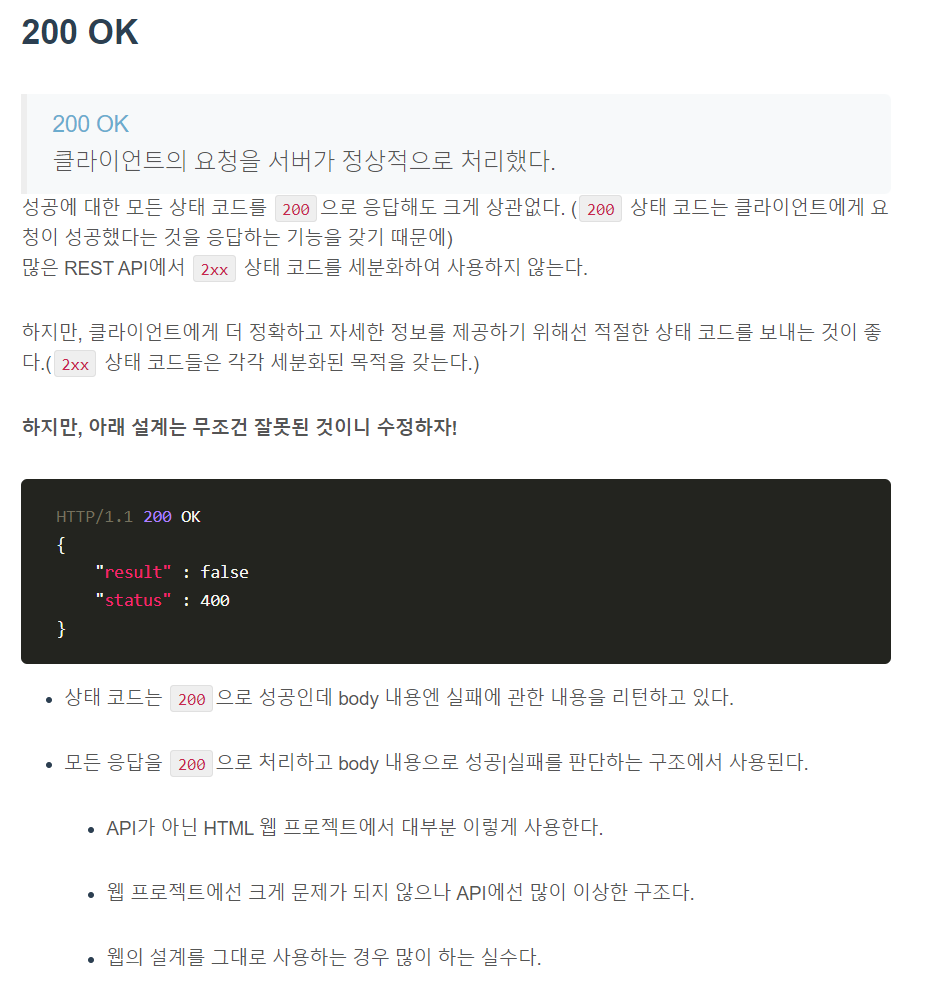
4xx Client errors
4XX의 상태 코드들은 클라이언트의 요청이 유효하지 않아 서버가 해당 요청을 수행하지 않았다는 의미다.
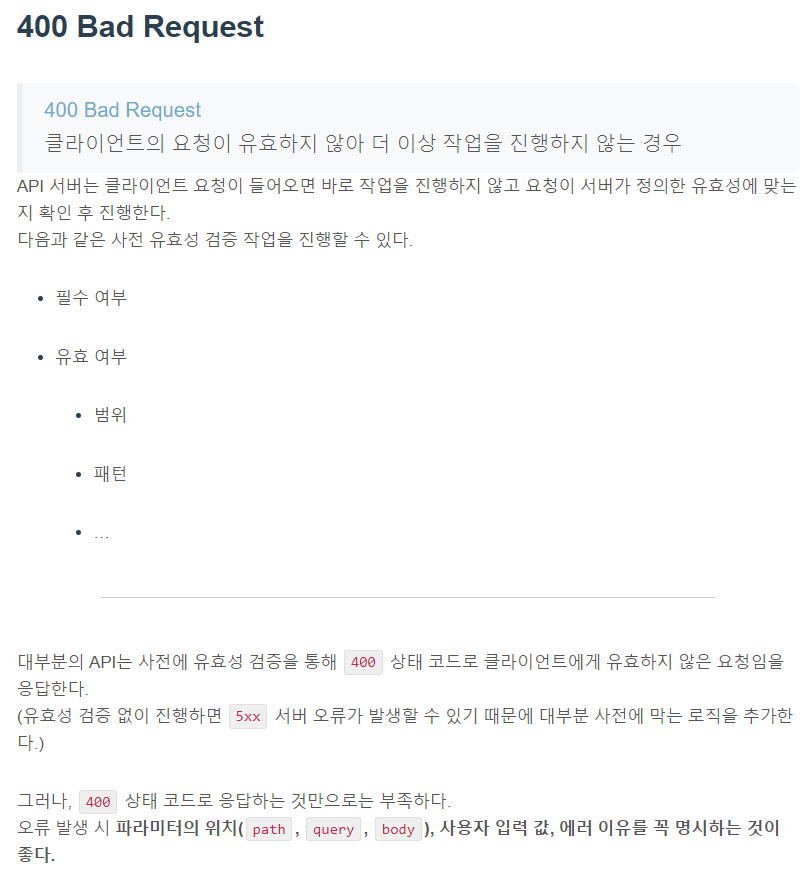
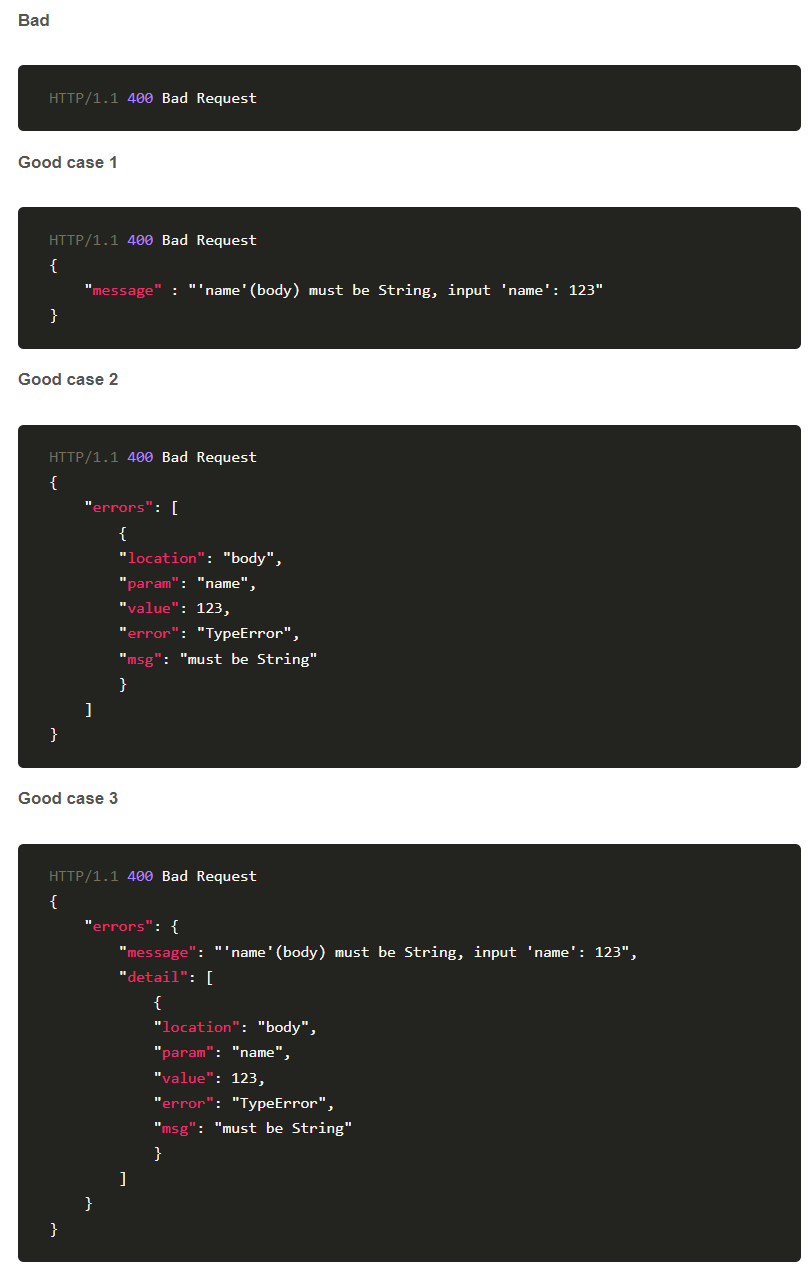

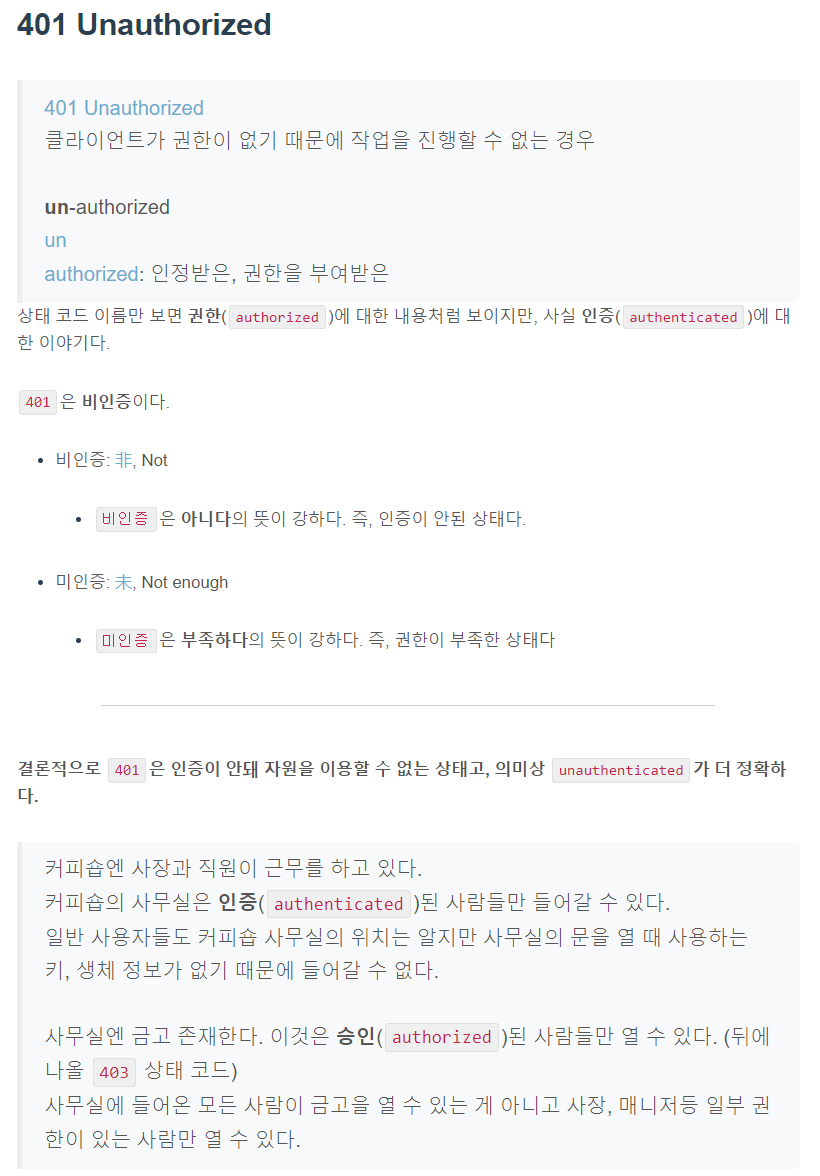
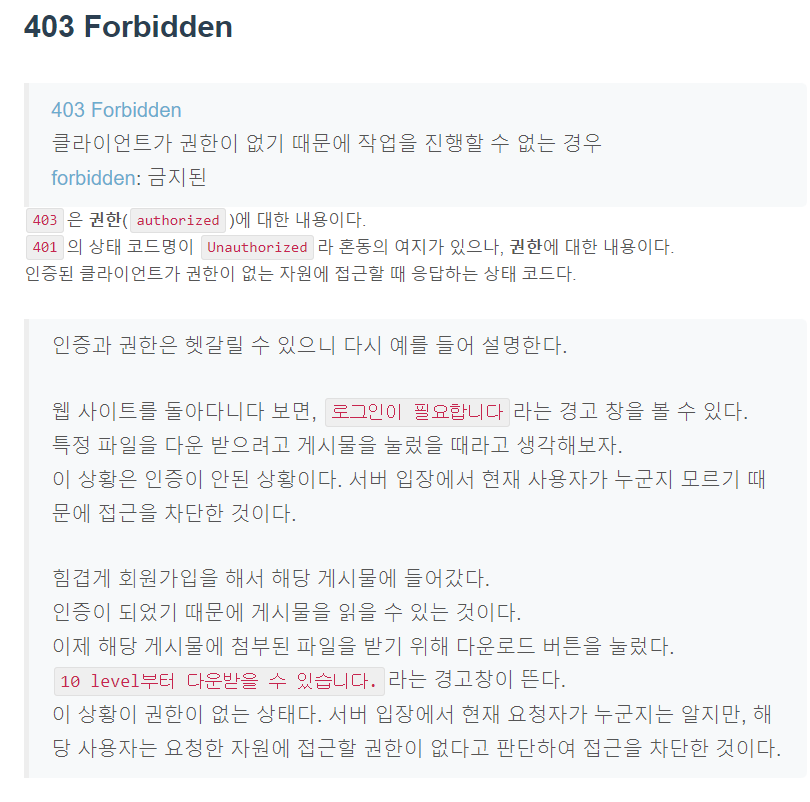
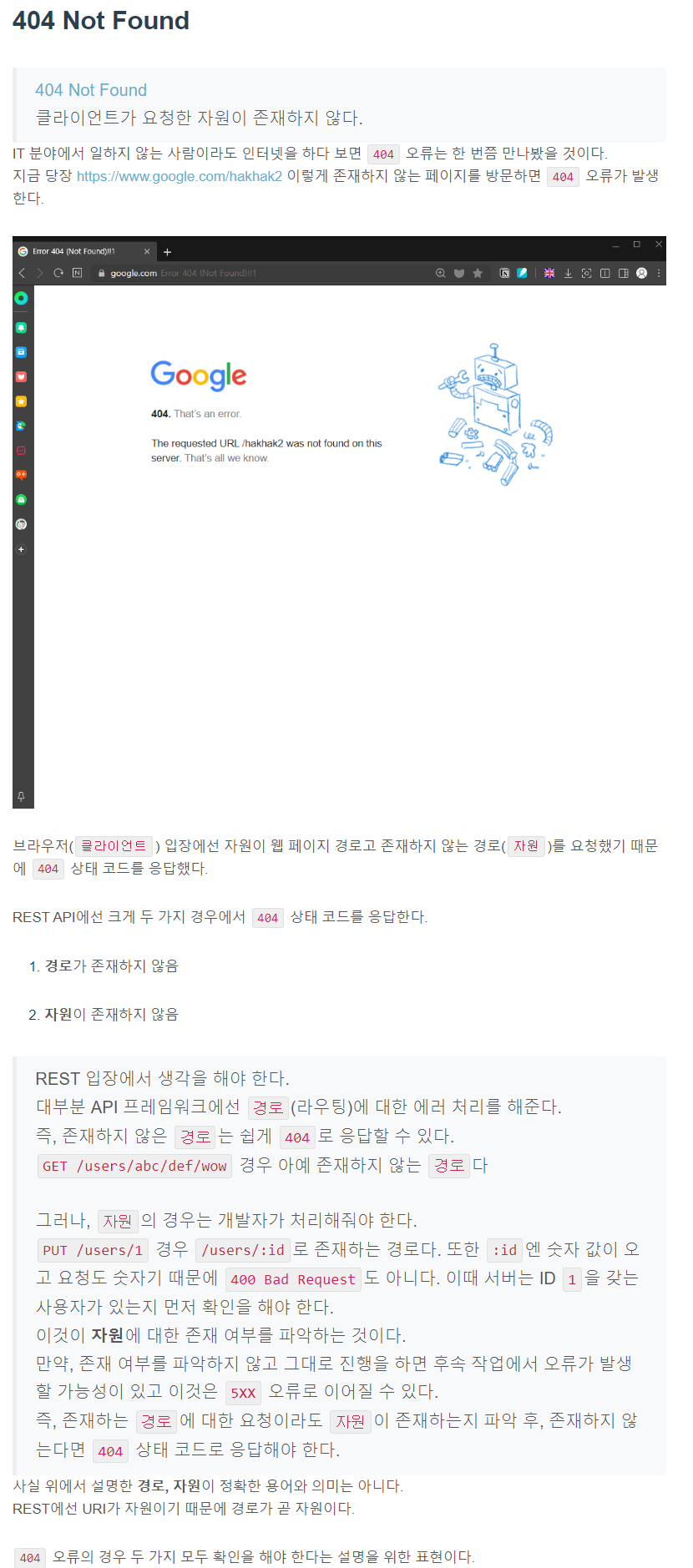
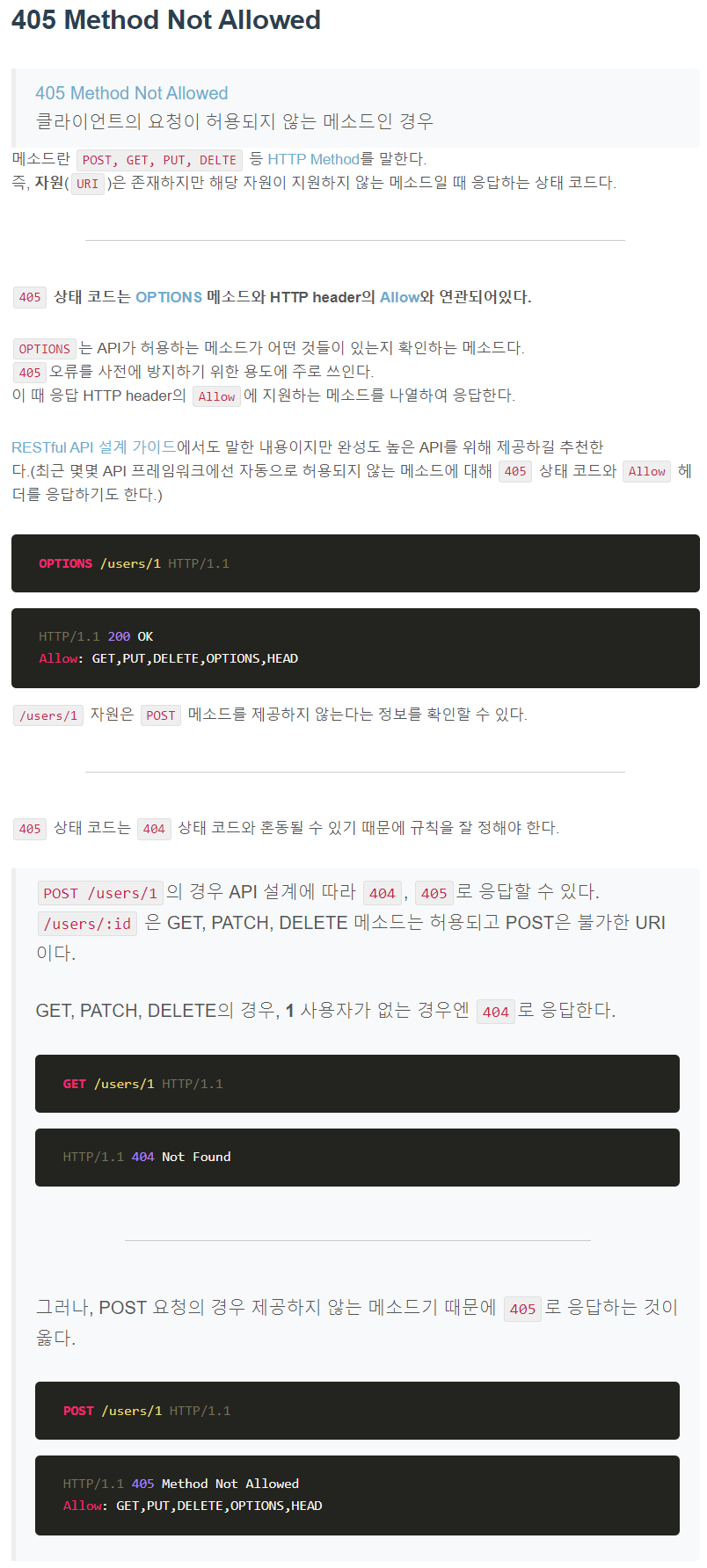
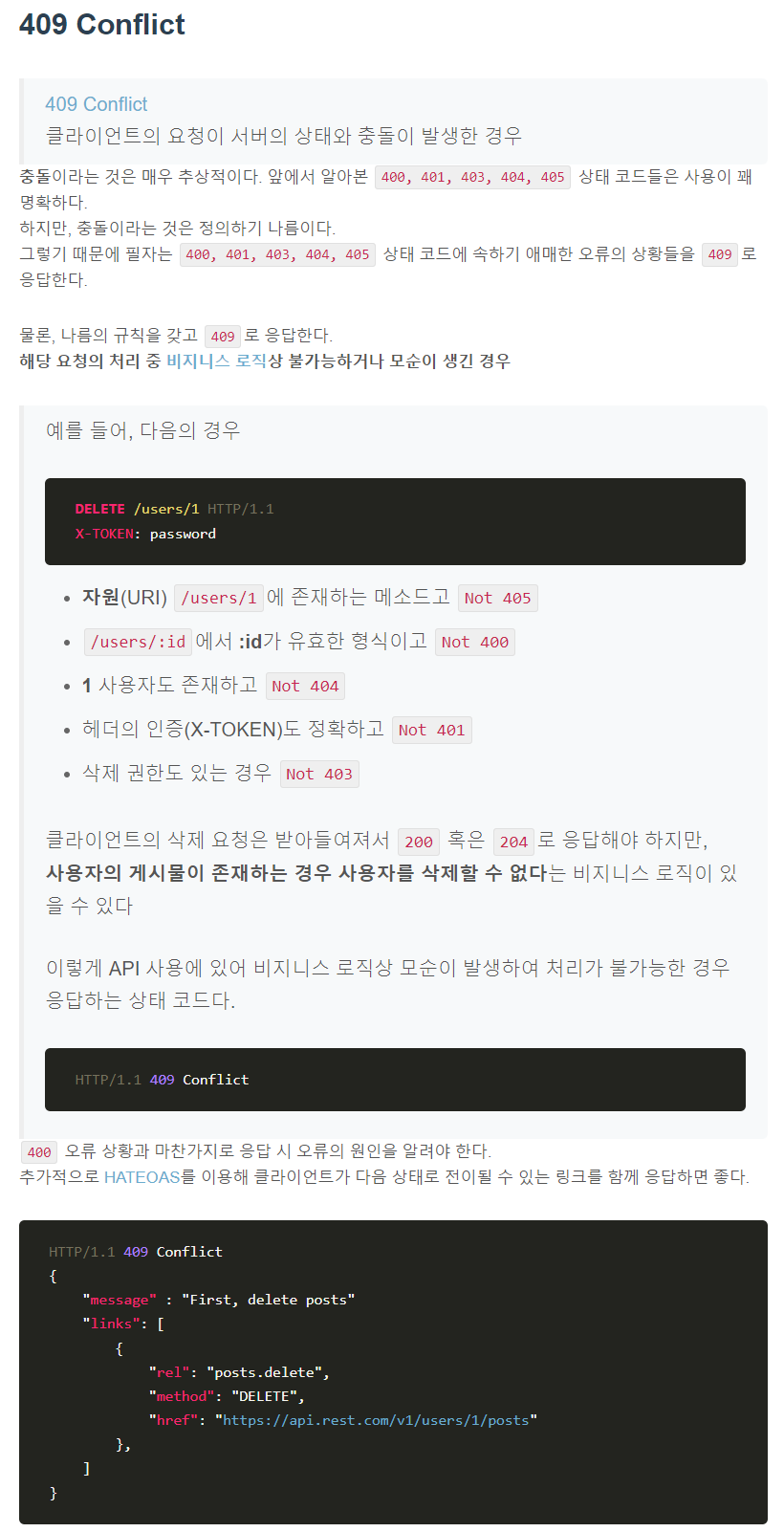
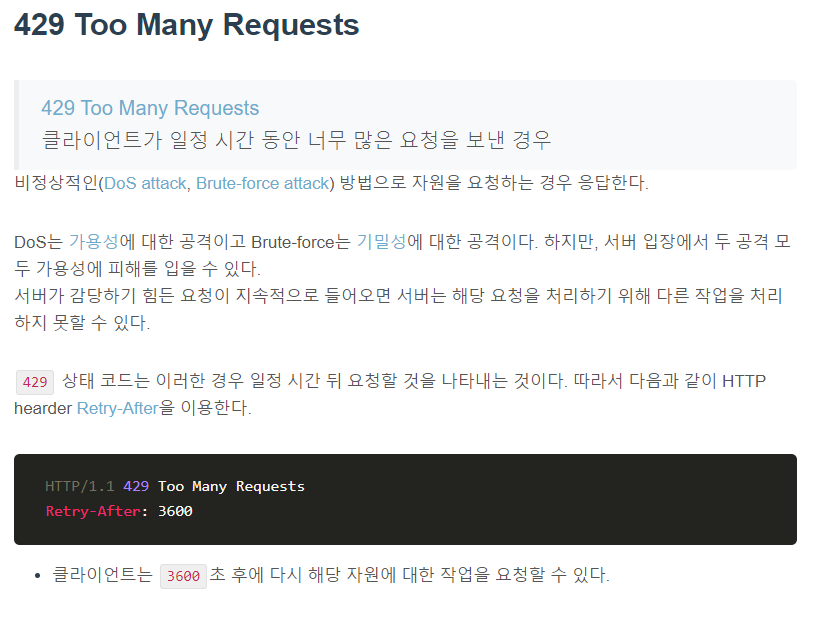
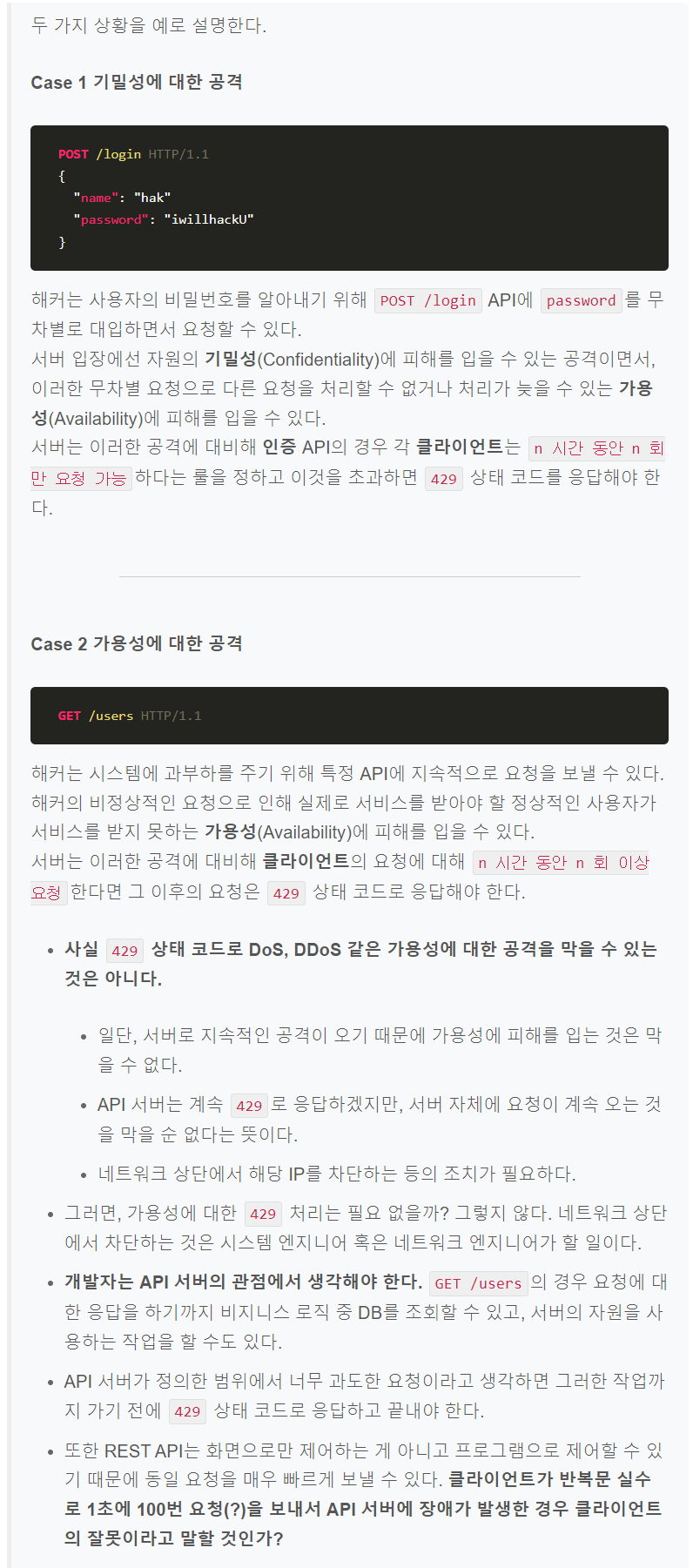
5xx Server errors
5XX 상태 코드들은 서버 오류로 인해 요청을 수행할 수 없다는 의미다.
클라이언트의 요청은 유효하여 작업을 진행했는데 도중에 오류가 발생한 경우다. 404 오류와 마찬가지로 인터넷을 하다 보면 500, 502, 503 등의 오류를 만나봤을 거다. API 서버의 응답에서 5XX오류가 발생해서는 안된다. 보통 개발 과정에서 유효하지 않은 요청을 사전에 처리하지 않은 경우(400)에 많이 발생한다.
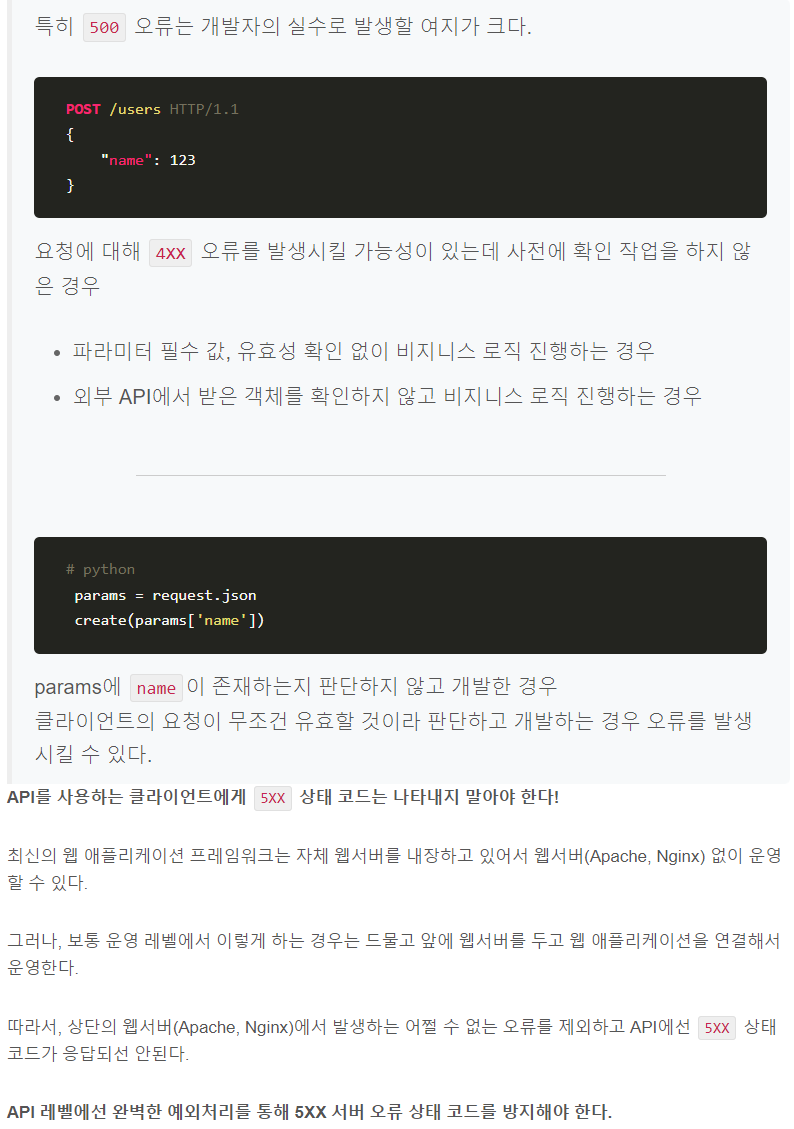
ResponseEntity 구조
ResponseEntity는 HttpEntity를 상속받고 사용자의 응답 데이터가 포함된 클래스이기 때문에 밑에거를 포함한다.
- HttpStatus
- HttpHeaders
- HttpBody
@GetMapping("/ex16")
public ResponseEntity<String> ex16() {
log.info("/ex16---------------------");
// {"name" : "홍길동"}
String msg = "{\"name\": \"홍길동\"}";
// HTTP POST를 요청할때 보내는 데이터(Body)를 설명해주는 헤더(Header)도 만들어서 같이 보내줘야 한다.
HttpHeaders header = new HttpHeaders();
// add()를 사용해 Header에 들어갈 내용을 추가해주자.
header.add("Content-Type", "appplication/json;charset=UTF-8");
return new ResponseEntity<>(msg, header, HttpStatus.OK);
}ResponseEntity는 HttpHeaders 객체를 같이 전달할 수 있고, 이를 통해서 원하는 HTTP 헤더 메시지를 가공하는 것이 가능합니다. ex16()의 경우 브라우저에는 JSON 타입이라는 헤더 메시지와 200 OK라는 상태 코드를 전송합니다.
사용이유
@RequestBody가 붙은 곳에서 객체를 HttpMessage로 자동 변환 해준다. 또한, JSON형태로 변환이 필요하다면 MappingJacksonHttpMessageConverter가 자바 Object와 JSON문서 사이에서 자동으로 변화해준다.
@ResponseBody를 붙이면 알맞은 HttpMessageConter가 동작해서 header, body, status를 만들어준다. @ResponseStatus(HttpStatus.OK)를 사용해서 직접 상태를 만들어 줄수 있다.
ResponseEntity를 사용하면, 객체와 status를 함께 보내줄 수 있다. 때문에 @ResponseStatus를 사용하지 않아도 되고 메서드 별로 다른 status를 리턴할 수 있기 때문에 좀 더 세밀하게 상태 전송이 가능하다.
일반적인 애플리케이션 유효성 검사의 문제점
일반적으로 사용되는 데이터 검증 로직에는 몇 가지 문제점이 있습니다. 계층별로 진행하는 유효성 검사는 검증 로직이 각 클래스별로 분산돼 있어 관리하기가 어렵습니다. 그리고 검증 로직에 의외로 중복이 많아 여러 곳에 유사한 기능의 코드가 존재할 수 있습니다. 검증해야할 값이 많다면 코드가 길어지고 가독성을 해치게 됩니다.
이 같은 문제를 해결하기 위해 자바 진영에서는 2009년부터 Bean Validation이라는 데이터 유효성 검사 프레임워크를 제공합니다. Bean Validation은 어노테이션을 통해 다양한 데이터를 검증하는 기능을 제공합니다. Bean Valiation을 사용한다는 것은 유효성 검사를 위한 로직을 DTO 같은 도메인 모델과 묶어서 각 계층에서 사용하면서 검증 자체를 도메인 모델에 얹는 방식으로 수행한다는 의미입니다. 또한 Bean Validation은 어노테이션을 사용한 검증 방식이기 때문에 코드의 간결함도 유지할 수 있습니다.
Validation
올바르지 않은 데이터를 걸러내고 보안을 유지하기 위해 데이터 검증(validation)은 여러 계층에 걸쳐서 적용됩니다. Client의 데이터는 조작이 쉬울 뿐더러 모든 데이터가 정상적인 방식으로 들어오는 것도 아니기 때문에, Client Side뿐만 아니라 Server Side에서도 데이터 유효성을 검사해야 할 필요가 있습니다. 스프링부트 프로젝트에서는 @validated를 이용해 유효성을 검증할 수 있습니다.
@Validated 활용
앞의 예제에서 유효성 검사를 수행하기 위해 @Valid 어노테이션을 선언했습니다.@Valid 어노테이션은 자바에서 지원하는 어노테이션이며, 스프링도 @Validated라는 별도의 어노테이션으로 유효성 검사를 지원합니다.
@Validated은 @Valid 어노테이션의 기능을 포함하고 있기 때문에 @validated로 변경할 수 있습니다. 또한 @Validated는 유효성 검사를 그룹으로 묶어 대상을 특정할 수 있는 기능이 있습니다. 검증 그룹은 별다른 내용이 없는 마커 인터페이스를 생성해서 사용합니다.
ENUM
우리가 흔히 상수를 정의할 때 final static string 과 같은 방식으로 상수를 정의를합니다. 하지만 이렇게 상수를 정의해서 코딩하는 경우 다양한 문제가 발생됩니다. 따라서 이러한 문제점들을 보완하기 위해 자바 1.5버전부터 새롭게 추가된 것이 바로 Enum 입니다. Enum은 열거형이라고 불리며, 서로 연관된 상수들의 집합을 의미합니다. 기존에 상수를 정의하는 방법이였던 final static string 과 같이 문자열이나 숫자들을 나타내는 기본자료형의 값을 enum을 이용해서 같은 효과를 낼 수 있습니다.
enum은 요소, 멤버라 불리는 명명된 값의 집합을 이루는 자료형이다. 상수 컬렉션을 정의하는데 쓰이는 특수한 자바 유형(type)이다. enum은 상수 그룹을 나타내는 특수한 클래스다.
enum 장점
-
코드가 단순해지며 가독성이 좋습니다.
-
인스턴스 생성과 상속을 방지하여 상수값의 타입 안정성이 보장됩니다.(컴파일 에러)
-
enum class를 사용해 새로운 상수들의 타입을 정의함으로 정의한 타입 이외의 타입을 가진 데이터값을 컴파일시 체크한다.
-
키워드 enum을 사용하기 때문에 구현의 의도가 열거임을 분명하게 알 수 있습니다.
optional & stream & .map & forEach
Optional<>
Java NPE 예방
자바 프로그램 코드를 작성하다보면 null 값에 대해 고려해야 하는 경우가 많다. null 값을 제대로 처리하지 않으면 NPE(NullPointerExcepion)을 만나게 된다. 안정적인 실행을 위해 NPE가 발생하지 않도록 중간중간 null 체크를 해줘야 한다.
자바 8부터 이런 null 값에 대한 처리를 좀 더 깔끔하게 할 수 있도록 Optional 클래스가 추가되었다.
Optional<T> 클래스는 null 값일 수도 있는 어떤 변수를 감싸주는 래퍼(Wrapper)클래스다. Optional 클래스는 제너릭(Generic)으로 값의 타입을 지정해줘야 한다. Optional 클래스는 여러가지 메소드를 통해 value 값에 접근하기 때문에 바로 NPE가 발생하지 않으며, null일 수도 있는 값을 다루기 위한 다양한 메소드들을 제공한다.
findById같은 경우는 optional로 감싸져 있습니다.
stream
java8부터 지원 되는 대표적인 API인 stream에 대해 알아보려고 한다. Stream은 컬렉션, 배열에 저장되어 있는 요소들을 하나씩 참조하며 반복적인 처리를 가능하게 한다.
Stream과 람다표현식을 사용하면 for문과 if문을 사용하지 않고도 깔끔하고 직관적이게 코드를 변경 할수있다.
몰라도 당연히 처리 할수 있지만, Strame이 생겨서 컬렉션 배열 계열의 처리가 간단하게 할수 있다 이런말로 요약할수 있다.
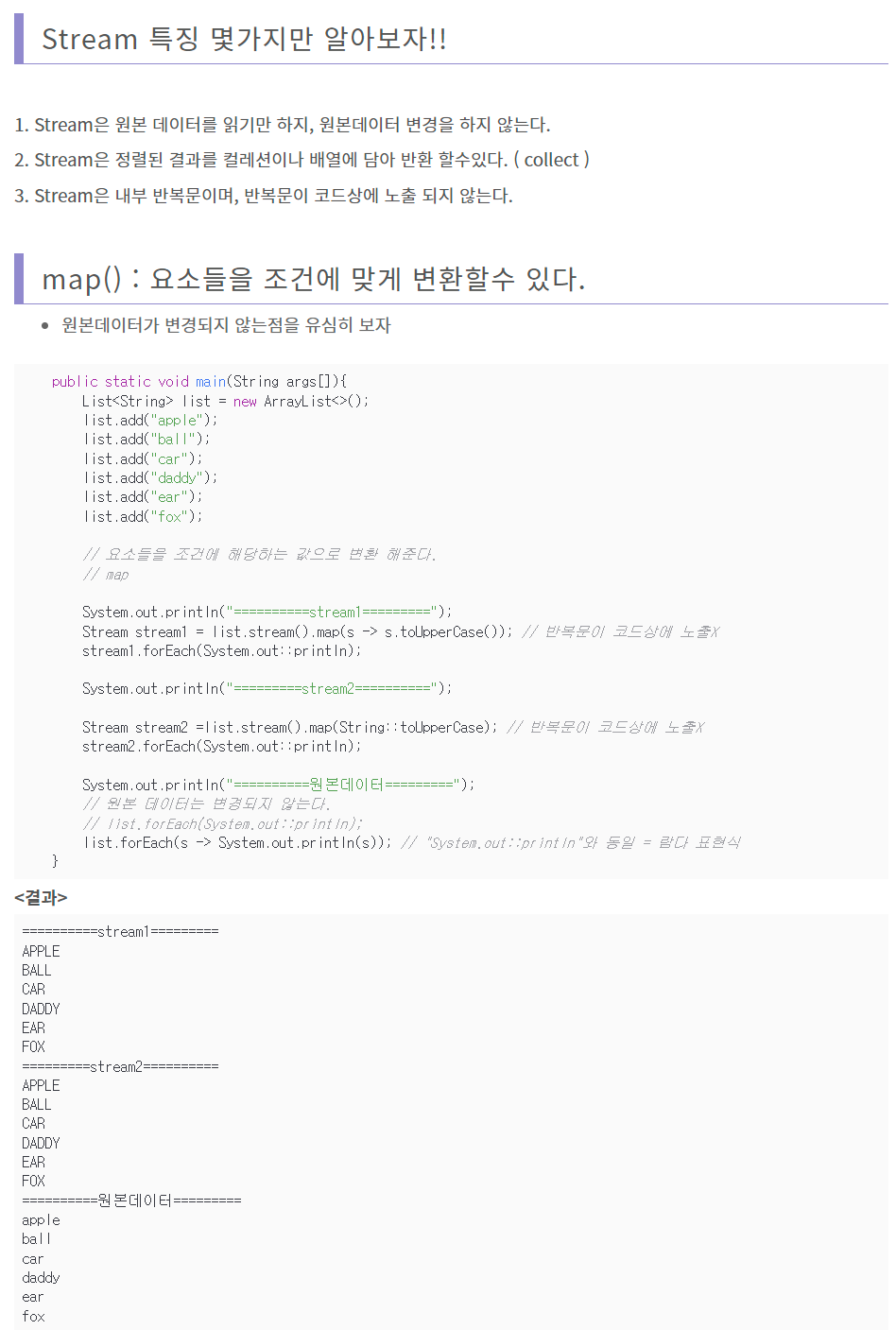
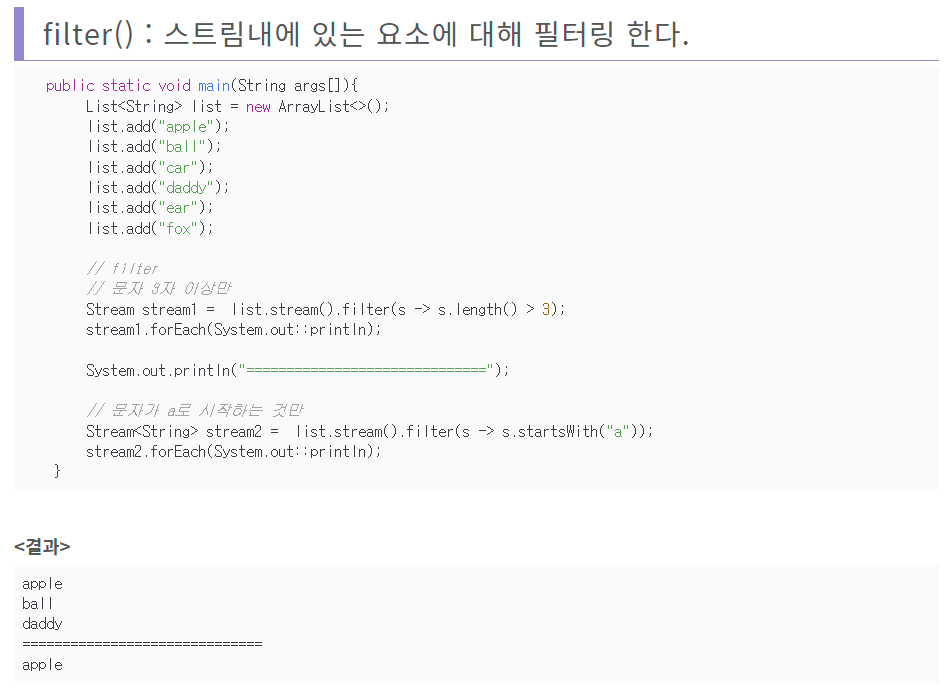

stream().map()과 .map()의 차이
전자는 stream()은 컬렉션을 스트림으로 변환하고, map()은 각 요소에 함수를 적용하여 새로운 값을 생성합니다. stream()을 사용하면 연속된 작업을 체인으로 구성할 수 있습니다.
후자는 컬렉션을 스트림으로 변환하지 않고도 map() 메서드를 사용할 수 있습니다. 이 경우, map() 메서드는 컬렉션 클래스의 메서드로 직접 호출됩니다.
전자를 사용하면 기존의 값을 변경하지 않고 새로운 스트림으로 만들어서 반환하고 후자는 기존의 값을 바꿔준다. stream().map()은 컬렉션을 변환하거나 필터링할 때 Stream이 효과적입니다. .map()는 컬렉션으로 변환하지 않고 처리를 할 때 유용합니다.
forEach()
forEach는 각 요소에 대해 주어진 작업을 수행할 때 사용됩니다. 주로 컬렉션의 각 요소를 반복하면서 상태를 변경하거나 특정 조건을 만족하는 요소를 찾을 때 사용됩니다. 그러나 forEach를 남용하면 가독성이 떨어질 수 있으며, 함수형 프로그래밍 스타일을 깨뜨릴 수 있으므로 주의가 필요합니다. 이거는 아무 값을 반환하지 않습니다.
로그(log)
로그 사용 시 장점
-
쓰레드 정보, 클래스 이름 같은 부가 정보를 함께 볼 수 있고, 출력 모양을 조정할 수 있다.
-
로그 레벨에 따라 개발 서버에서는 모든 로그를 출력하고, 운영서버에서는 출력하지 않는 등 로그를 상황에 맞게 조절할 수 있다.
-
시스템 아웃 콘솔에만 출력하는 것이 아니라, 파일이나 네트워크 등, 로그를 별도의 위치에 남길 수 있다. 특히 파일로 남길 때는 일별, 특정 용량에 따라 로그를 분할하는 것도 가능하다.
-
성능도
System.out보다 좋다. (내부 버퍼링, 멀티 쓰레드 등등) 그래서 실무에서는 로그를 사용한다.
Log4j2란?
log4j(Log for Java)란 이전 버전인 Log4j 1.x에 비해 크게 개선된 Log4j로의 업그레이드이며 Logback 아키텍처의 몇 가지 고유한 문제를 수정하면서 Logback에서 사용할 수 있는 많은 개선 사항을 제공하는 대표적인 자바 로깅 프레임워크이다. og4j 2.13.0 이상에는 Java 8이 필요합니다. 버전 2.4~2.12.1에는 Java 7이 필요합니다(Log4j 팀은 더 이상 Java 7을 지원하지 않습니다). 일부 기능에는 선택적 종속성이 필요합니다. 이러한 기능에 대한 설명서는 필요한 종속성을 지정합니다.
예외와 에러
프로그래밍에서 예외(exception)란 입력 값의 처리가 불가능하거나 참조된 값이 잘못된 경우 등 애플리케이션이 정상적으로 동작하지 못하는 상황을 의미합니다. 예외는 개발자가 직접 처리할 수 있는 것이므로 미리 코드 설계를 통해 처리할 수 있습니다.
다음으로는 에러(error)가 있습니다. 많은 사람들이 예외와 비슷한 의미로 사용하고 있지만 소프트웨어 공학에서는 엄연히 다르게 사용되는 용어입니다. 에러는 주로 자바의 가상머신에서 발생시키는 것으로서 예외와 달리 애플리케이션 코드에서 처리할 수 있는것이 거의 없습니다.
사용자가 시스템을 사용하다보면 웹 페이지 URL 경로를 잘못 입력하거나 파라미터를 잘못전달하여 문제가 발생하는 경우가 있다. 또는 서버에서 실행되는 프로그램에서 생각하지 못 했던 문제가 발생할 수도 있다. 이렇게 사용자의 부주의나 코드 자체의 오류로 인해 문제가 발생할 때, 발생된 문제를 적절하게 처리하지 않으면 사용자 브라우저에는 에러 페이지가 출력된다.
자바는 시스템에서 발생되는 문제를 시스템 에러(Error)와 예외(Exception)로 구분한다. 시스템 에러는 개발자가 제어할 수 없는 문제이므로 제외하고 예외에 집중한다. 일반적인 자바 애플리케이션이라면 try-catch를 사용하겠지만 스프링 기반의 웹 애플리케이션은 스프링에서 지원하는 예외처리 기법을 이용한다.
일반적으로 스프링에서 예외를 처리하는 방법는 두 가지가 있다.
-
@ControllerAdvice 어노테이션을 이용하여 모든 컨트롤러에서 발생하는 예외를 일괄적으로 처리하는 것이다. 전역 예외처리라고 하며 일반적으로 가장 많이 사용한다.
-
@ExceptionHandler 어노테이션을 이용하여 각 컨트롤러마다 발생하는 예외를 개별적으로 처리하는 것이다.
예외 클래스

모든 예외 클래스는 Throwable 클래스를 상속받습니다. 그리고 가장 익숙하게 볼 수 잇는 Exception 클래스는 다양한 자식 클래스를 가지고 있습니다. 이 클래스는 크게 Checked Exception과 Unchecked Exception으로 구분할 수 있습니다.
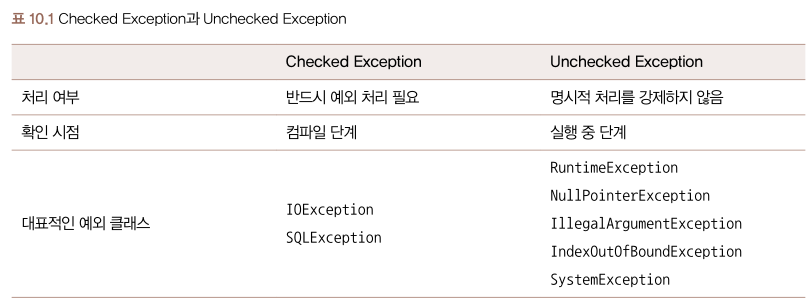
Checked Exception은 컴파일 단계에서 확인 가능한 예외 상황입니다. 이러한 예외는 IDE에서 캐치해서 반드시 예외 처리를 할 수 있게 표시해줍니다. 반면 Unckecked Exception은 런타임 단계에서 확인되는 예외 상황을 나타냅니다. 즉, 문법상 문제는 없지만 프로그램이 동작하는 도중 예기치 않은 상황이 생겨 발생하는 예외를 의미합니다.
예외 처리 방법
예외가 발생했을 때 이를 처리하는 방법은 크게 세 가지 있습니다.
- 예외 복구
- 예외 처리 회피
- 예외 전환
먼저 예외 복구 방법은 예외 상황을 파악해서 문제를 해결하는 방식입니다. 대표적인 방법이 try/catch구문 입니다. try 블록에는 예외가 발생할 수 있는 코드를 작성합니다. 대체로 외부 라이브러리를 사용하는 경우에는 try블록을 사용하라는 IDE의 알람이 발생하지만 개발자가 직접 작성한 로직은 예외 상황을 예측해서 try 블록에 포함시켜야 합니다. 이 때 catch 블록은 여러 개를 작성할 수 있습니다. 이 경우 예외 상황이 발생하면 여러 개의 catch 블록이 순차적으로 거치면서 예외 유형과 매칭되는 블록을 찾아 예외 처리 동작을 수행합니다.
또 다른 예외 처리 방법 중 하나는 예외 처리를 회피하는 방법입니다. 이 방법은 예외가 발생한 시점에서 바로 처리하는 것이 아니라 예외가 발생한 메서드를 호출한 곳에서 에러 처리를 할 수 있게 전가하는 방식입니다. 이 때 throw 키워드를 사용해 어떤 예외가 발생했는지 호출부에 내용을 전달할 수 있습니다.
@ExceptionHandler와 @ControllerAdvice를 이용한 처리
예외 사항을 전부 매번마다 핸들링해야 한다면 중복적이고 많은 양의 코드를 작성해야 하지만, 공통적인 예외사항에 대해서는 별도로 @ControllerAdvice를 이용해서 분리한다. AOP를 이용하는 방식이다.
@ControllerAdvice
@ControllerAdvice는 뒤에서 배우는 AOP를 이용하는 방식이다. 핵심적인 로직은 아니지만 프로그램에서 필요한 공통적인 관심사는 분리하자는 개념입니다. Controller를 작성할 때는 메서드의 모든 예외사항을 전부 핸들링해야 한다면 중복적이고 많은 양의 코드를 작성해야 하지만, AOP 방식을 이용하면 공통적인 예외사항에 대해서는 별도로 @ControllerAdvice를 이용해서 분리하는 방식입니다.
테스트
JUnit
-
자바 프로그래밍 언어용 유닛 테스트 프레임워크
-
가장 많이 사용되는 테스트 환경
-
테스트 성공시 JUnit GUI 창에 녹색으로 표시 / 실패시 적색으로 표시
-
하나하나의 케이스별로(단위로 나누어서) 테스트를 하는 단위 테스트 도구
-
JUnit이 되면 text할 수 있는 폴더가 생긴다.
JUnit(제이 유닛)은 자바 프로그래밍 언어용 단위 테스트 도구로 보이지 않고 숨겨진 단위 테스트를 끌어내어 정형화시켜 단위 테스트를 쉽게 해주는 테스트용 Framework입니다. 플러그인 형태로 Eclipse에 포함되어있으며, 하나의 jar 파일이 전부이기 때문에 사용법도 간단합니다. JUnit은 외부 테스트 프로그램(케이스)을 작성하여 번거롭게 디버깅하지 않아도 되며, 프로그램 테스트 시 걸릴 시간도 관리할 수 있는 기능을 가지고 있습니다. 테스트 결과를 확인하는 것 이외 최적화된 코드를 유추해내는 기능도 제공합니다. 또한, 테스트 결과를 단순한 텍스트로 남기는 것이 아니라 Test클래스로 남깁니다. 그래서 개발자에게 테스트 방법 및 클래스의 History를 넘겨줄 수도 있습니다.
JUint의 특징
- 자바 프로그래밍 언어용 유닛 테스트 프레임워크
- 가장 많이 사용되는 테스트 환경
- 테스트 성공시 JUnit GUI 창에 녹색으로 표시 / 실패시 적색으로 표시
- 하나하나의 케이스별로(단위로 나누어서) 테스트를 하는 단위 테스트 도구
- JUnit이 되면 text할 수 있는 폴더가 생긴다.
- 어노테이션 기반의 테스트 방식을 지원
단정문(assert)을 통해 테스트 케이스 기댓값이 정상적으로 도출됐는지 검토할 수 있다.
JUnit(제이 유닛)은 자바 프로그래밍 언어용 단위 테스트 도구로 보이지 않고 숨겨진 단위 테스트를 끌어내어 정형화시켜 단위 테스트를 쉽게 해주는 테스트용 Framework입니다. 플러그인 형태로 Eclipse에 포함되어있으며, 하나의 jar 파일이 전부이기 때문에 사용법도 간단합니다. JUnit은 외부 테스트 프로그램(케이스)을 작성하여 번거롭게 디버깅하지 않아도 되며, 프로그램 테스트 시 걸릴 시간도 관리할 수 있는 기능을 가지고 있습니다. 테스트 결과를 확인하는 것 이외 최적화된 코드를 유추해내는 기능도 제공합니다. 또한, 테스트 결과를 단순한 텍스트로 남기는 것이 아니라 Test클래스로 남깁니다. 그래서 개발자에게 테스트 방법 및 클래스의 History를 넘겨줄 수도 있습니다.
JUint의 특징
@Test메서드가 호출할 때마다 새로운 인스턴스가 생성되어 독립적인 테스트 가능- 단위 테스트 Framework 중 하나
- 문자 혹은 GUI 기반으로 실행됨
- 단정 문으로 테스트 케이스의 수행 결과를 판별함(assertEquals(예상 값, 실제 값))
- JUnit4부터는 어노테이션으로 간결하게 테스트를 지원함
- 결과는 성공(녹색), 실패(붉은색) 중 하나로 표시
- 테스트 결과를 확인하는 것 이외 최적화된 코드를 유추해내는 기능도 제공
JUnit의 세부 모듈


JUnit의 생명주기
JUnit의 동작 방식을 확인하기 위해 생명주기를 알아보겠습니다. 생명주기와 관련되어 테스트 순서에 관여하게 되는 대표적인 어노테이션은 다음과 같습니다.
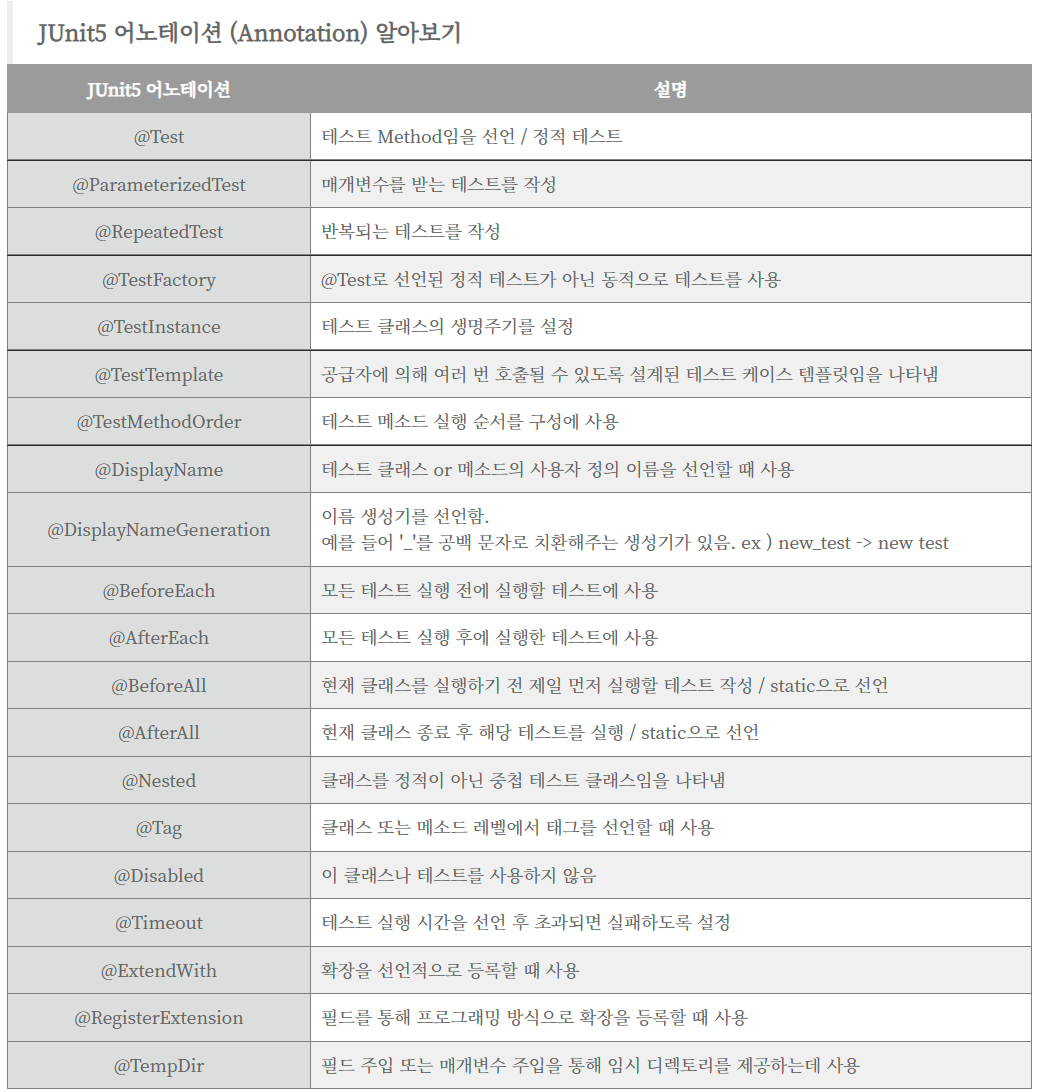
- @Test : 테스트 코드를 포함한 메서드를 정의
- @BeforeAll : 테스트를 시작하기 전에 호출되는 메서드 정의
- @BeforeEach : 각 테스트 메서드가 실행되기 전에 동작하는 메서드를 정의
- @AfterAll : 테스트를 종료하면서 호출되는 메서드 정의
- @AfterEach : 각 테스트 메서드가 종료되면서 호출되는 메서드를 정의
SpringBoot에서 JUnit5와 log
JUnit의 버전5를 뜻하며 2017년 2월에 출시되어 많은 개발자들이 사용하고 있는 테스팅 프레임워크입니다. JUnit 5는 이전 버전들과 다르게 3개의 서브 프로젝트 모듈로 이루어져있습니다.


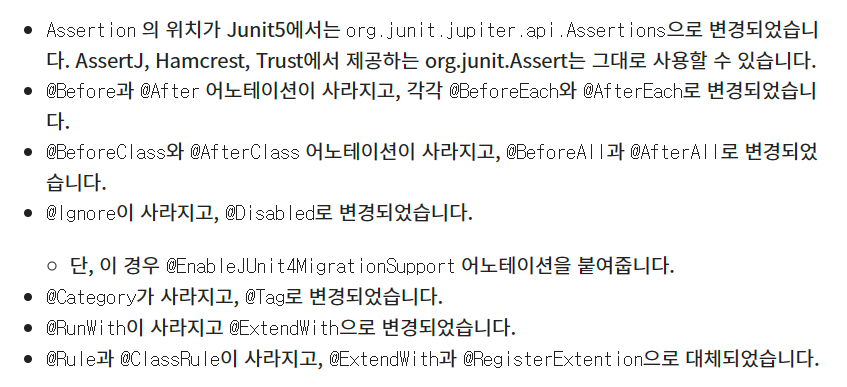
JUnit5에서 JUnit Vintage 모듈을 포함하고 있어 JUnit 3, 4 문법을 사용할 수 있습니다. 하지만 완벽하게 지원해주는 것이 아니기 때문에 만약 사용한다하면 추가로 작업이 필요합니다.
JUnit5란?
SpringBoot 2.2.0 이전에는 JUnit4가 기본으로 설정되었지만, SpringBoot 2.2.0 버전부터는 JUnit5가 기본으로 설정됩니다. JUnit5는 런타임 시 Java8 이상이 필요하며, Junit5를 사용하려면 Gradle 4.7 이상이 여야 합니다. JUnit의 경우 Spring boot initializer에서 Spring-Web을 dependencies를 사용하게 되면 자동적으로 추가가 됩니다.

💡Junit4와 Junit5의 차이점에 대해 설명해주세요
Junit4는 junit 라이브러리만 정의하면 되지만 junit5는 3가지의 모듈을 정의해야 한다.
-
junit platform : 테스트를 실행해주는 런처를 제공(일종의 컨텍스트), TestEngine API 제공(실제 구현체는 별도)
-
junit jupiter : TestEngine API 구현체
-
junit vintage : Junit4와 3을 지원하는 TestEngine 구현체
로 나눠져 있습니다.

단위 테스트 특징
단위 테스트는 테스트 대상의 범위를 기준으로 가장 작은 단위의 테스트 방식입니다. 일반적으로 메서드 단위로 테스트를 수행하게 되며, 메서드 호출을 통해 의도한 결괏값이 나오는지 확인하는 수준으로 테스트를 진행합니다. 단위 테스트는 테스트 비용이 적게 들기 때문에 테스트 피드백을 빠르게 받을 수 있습니다. 다른 객체들과 의존관계를 맺고 있는데 어떻게 그거만 테스트할 수 있을까? 그것은 Bean Container에 주입된 실제 객체들을 가져다 쓰는 방법이 있고 Mock 객체를 만들어서 쓰는 방법이 있습니다.
단위 테스트 이점
-
단위 테스트는 개발단계 초기에 문제를 발견하게 도와줍니다.
-
단위 테스트는 개발자가 나중에 코드를 리팩토링하거나 라이브러리 업그레이드 등에서 기존 기능이 올바르게 작동하는지 확인할 수 있습니다.
-
단위 테스트는 기능에 대한 불확실성을 감소시킬 수 있습니다.
-
단위 테스트는 시스템에 대한 실제 문서를 제공합니다. 즉, 단위 테스트 자체가 문서로 사용할 수 있습니다.
작성하는 이유
- 개발 과정에서 문제를 미리 발견할 수 있다.
- 리팩토링의 리스크가 줄어든다.
- 애플리케이션을 가동해서 직접 테스트하는 것보다 테스트를 빠르게 진행
- 하나의 명세 문서로서의 기능을 수행
- 몇 가지 프레임워크에 맞춰 테스트 코드를 작성하면 좋은 코드를 생산할 수 있다.
- 코드가 작성된 목적을 명확하게 표현할 수 있으며, 불필요한 내용이 추가되는 것을 방지

통합 테스트의 특징
통합 테스트는 모듈을 통합하는 과정에서의 호환성 등을 포함해 애플리케이션이 정상적으로 동작하는지 확인하기 위해 수행하는 테스트 방식입니다. 앞에서 언급한 단위 테스트와 비교하자면 단위 테스트는 모듈을 독립적으로 테스트하는 반면 통합 테스트는 여러 모듈을 함께 테스트해서 정상적인 로직 수행이 가능한지를 확인합니다. 그리고 단위 테스트는 일반적으로 특정 모듈에 대한 테스트만 진행하기 때문에 데이터베이스나 네트워크 같은 외부 요인들을 제외하고 진행하는 데 비해 통합 테스트는 외부 요인들을 포함하고 테스트를 진행하므로 애플리케이션이 온전히 동작하는지를 테스트하게 됩니다. 다만 수행할 때마다 모든 컴포넌트가 동작해야 하기 때문에 테스트 비용이 커지는 단점이 있습니다.

