대회 주최 측에서 간단한 baseline을 제공했다. 해당 baseline을 참고하여 학습 및 inference 까지 과정을 수행하는 자체적인 baseline을 재구성 했다. Jupyter Notebook은 간단하게 사용하기엔 편하고 좋지만, 모델 학습 과정과 같은 복잡한 프로세스를 처리하기에는 개인적으로 조금 불편한 것 같다.
PyTorch를 위한 다양한 template들이 있겠지만, 나는 개인적으로 victoresque/pytorch-template을 기초로 살짝 변형해서 사용한다.
일반적으로 dataset, model, trainer 3개의 class를 기본적으로 작성하고, 필요한 부분들을 추가한다.
dataset.py
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__():
def __len__():
def __getitem__():Dataset class를 상속하여 세가지 함수를 작성한다. 그다지 특별한 부분은 없다.
model.py
import torch.nn as nn
class Net(nn.Module):
def __init__():
def forward():마찬가지로 함수 2개를 기본적으로 작성한다. 제공된 baseline에서 EfficientNet을 사용해서, 일단은 그대로 가져와서 사용했다. 추후 다른 모델로 교체 될 수 있다.
trainer.py
class Trainer:
def __init__():
# model, dataloader, epochs, learning rate 등을 받는다.
def train():
# 아래 함수들을 이용해 학습을 진행한다.
for epoch in range(1, self.epochs + 1):
self._train_epoch()
self._valid_epoch()
self._save_checkpoint()
# 각각의 기능에 대한 구현
def _train_epoch():
def _valid_epoch():
def _save_checkpoint():위와 같은 방법으로 학습을 진행한다. 앞서 언급한 template에서 소개했는데, 깔끔하고 직관적이여서 내가 좋아하는 방법이다.
train.py
앞서 작성한 3개의 class를 이용하여 학습을 진행한다. 성능을 내려고 진행한 부분이 아니라 단순히 학습부터 제출까지의 pipe line 구성을 위한 작업이라서 cross validation이나 valid 전략 같은 부분은 대충 했다.
def main(config):
# 시드 고정
seed_everything(config["SEED"])
# 학습 데이터 가져오고, train, valid 분리
# 대충 100으로 끊었다.
image_path_list, label_list = get_train_data()
train_image_path_list, valid_image_path_list = (
image_path_list[:-100],
image_path_list[-100:],
)
train_label_list, valid_label_list = label_list[:-100], label_list[-100:]
# dataset 선언
train_dataset = CustomDataset(
image_path_list=train_image_path_list,
label_list=train_label_list,
transforms=None,
)
valid_dataset = CustomDataset(
image_path_list=valid_image_path_list,
label_list=valid_label_list,
transforms=None,
)
# dataloader
train_dataloader = DataLoader(train_dataset, batch_size=config["BATCH_SIZE"], shuffle=True)
valid_dataloader = DataLoader(valid_dataset, batch_size=config["BATCH_SIZE"], shuffle=False)
# model 선언
model = EfficientNet()
# 앞서 선언된 model, dataloader들 주입
trainer = Trainer(
model=model,
train_dataloader=train_dataloader,
valid_dataloader=valid_dataloader,
device=config["DEVICE"],
epochs=config["EPOCHS"],
learning_rate=config["LEARNING_RATE"],
weight_decay=config["WEIGHT_DECAY"],
)
# 학습 진행
trainer.train()
if __name__ == "__main__":
config = CFG.copy()
wandb.init(config=config)
config["DEVICE"] = torch.device("cuda" if torch.cuda.is_available() else "cpu")
main(config)inference.py
학습된 모델을 가져와서 제출할 .csv 파일을 만들어야 한다. 어려운 부분은 아니니까 생략한다.
결과
10에폭만 간단하게 돌려보고, 학습 과정을 wandb에 기록했는데, 아무리 대충 짰다고 해도 아예 잘못된 결과가 나온 것을 한눈에 확인할 수 있었다.
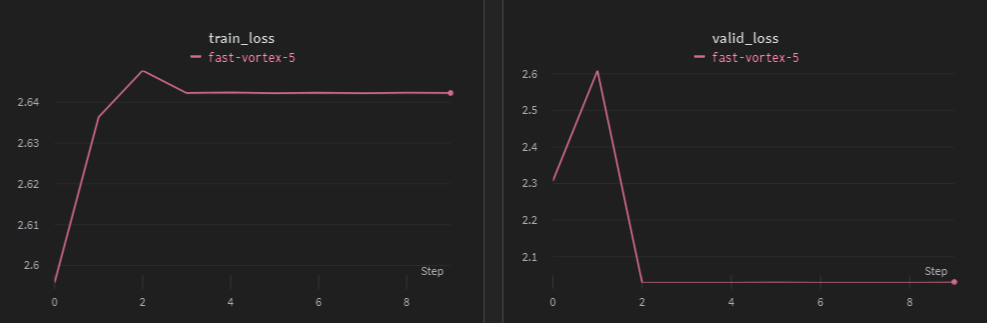
train_loss가 꾸준히 증가하고 있고, 특정 값에서 train_loss와 valid_loss가 모두 멈춰버렸다. inference를 통해 제출 결과를 보니 모두 하나의 class로 예측했다. 아무래도 학습 자체를 잘못 한 것 같아 찾아보니 torch.nn.CrossEntropyLoss 사용 과정에서 중대한 실수를 발견했다. model의 output에 softmax를 사용해버렸다. 해당 실수와 해결 내용은 여기에 정리해두었다.
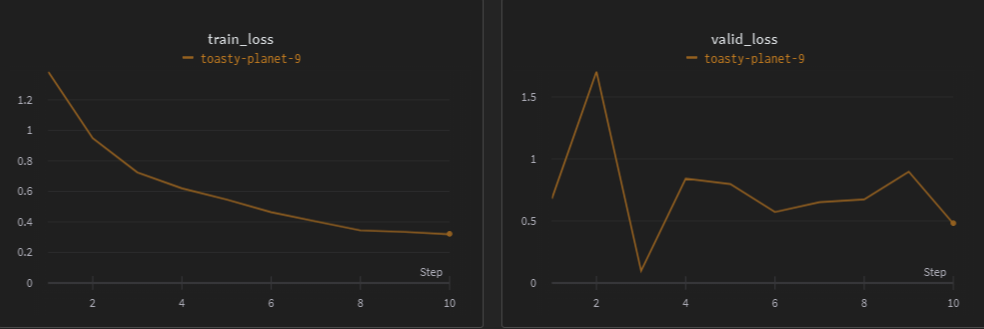
수정 후 간단하게 돌려본 결과 위와 같은 결과가 나왔다. 제출 결과에도 문제가 없는 것을 확인했다. Baseline이 완성되었으니 다음부터는 성능 향상을 위한 본격적인 작업을 시작해보자.
