
우리는 2가지 이유로 Batch가 필요했다.
우리 앱에 상품을 담은 사용자가 해당 상품의 변동된 가격을 알았으면 좋겠다.
여러 사용자가 같은 url의 상품을 담을 때 전부 다 스크래핑 및 분석해오는 것이 아니라 한 번만 했으면 좋겠다!
Spring Batch 관련 여러 자료들이 많지만 우리 프로젝트에 맞게 적용하는 데에는 시간이 걸렸다. 그치만 처음 들어봐서 신기하고 호기심이 가는! 한번쯤 사용해보면 배울 점이 많을 것 같은 프레임워크라 포기하지 않고 진행해보았다.
Spring Batch
Batch 는 일괄처리 라는 뜻을 가진다.
우리와 같이 이미 상품을 담아 DB에 저장된 모든 데이터들의 변동된 가격을 알아오기 위해서는
DB에서 데이터를 읽고, 스크래핑하고(가공), 변동되었다면 저장을 하게되는데
서비스 이용자가 많아질수록, 가격 변동이 잦은 시기일수록(블랙 프라이데이 같은 이벤트)
해당 서버는 순식간에 CPU, I/O 등의 자원을 다 써서 다른 request를 처리하지 못할 것이다.
그리고 데이터가 많아서 처리 중 1만번째에서 실패한다면, 1만 1번째부터 다시 실행할 수 있다면 얼마나 좋을까?
이러한 대용량 데이터를 처리하는 어플리케이션을 배치 어플리케이션이라고 하고, Spring에서는 Spring Batch가 있다.
실제 기업에서는 일매출 집계시 많이 사용된다고 한다.
Quartz
Quartz는 스케줄러의 역할로, Batch 와 같은 대용량 데이터 배치 처리에 대한 기능은 지원하지 않아
정해진 스케줄마다 Quartz가 Batch를 실행하는 구조로 보통 사용된다.
시행착오 및 적용 과정
먼저, build.gradle 에 아래와 같이 추가한다.
implementation 'org.springframework.boot:spring-boot-starter-batch'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
testImplementation 'org.springframework.batch:spring-batch-test'
implementation'org.springframework.boot:spring-boot-starter-quartz'프로젝트 main 함수를 찾아가 @EnableBatchProcessing 과 @EnableScheduling 를 추가한다.
@EnableScheduling
@EnableBatchProcessing
@EnableJpaAuditing
@SpringBootApplication
public class BackendApplication {
@PostConstruct
public void setTimeZone() {
TimeZone.setDefault(TimeZone.getTimeZone("Asia/Seoul"));
}
public static void main(String[] args) {
SpringApplication.run(BackendApplication.class, args);
}
}그리고 job이라는 패키지를 만들어 BatchSheduler 클래스 파일과 JpaPagingItemReaderJobConfiguration 클래스 파일을 만들어주었다.
JpaPagingItemReaderJobConfiguration 부터 하나하나 쪼개 보자.
@Slf4j // log 사용 위한 lombok 어노테이션
@RequiredArgsConstructor // 생성자 DI 위한 lombok 어노테이션
@Configuration
public class JpaPagingItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory; // 생성자 DI 받음
private final StepBuilderFactory stepBuilderFactory; // 생성자 DI 받음
private final EntityManagerFactory entityManagerFactory; // JPA를 사용하기 때문에 영속성 관리를 위해 EntityManager를 할당
private int chunkSize = 10;
@Bean
public Job jpaPagingItemReaderJob() {
return jobBuilderFactory.get("itemBatchUpdate")
.start(jpaPagingItemReaderStep())
.build();
}
@Bean
public Step jpaPagingItemReaderStep() {
return stepBuilderFactory.get("jpaPagingItemReaderStep")
.<Item, Item>chunk(chunkSize)
.reader(jpaPagingItemReader())
.processor(jpaItemProcessor())
.writer(jpaPagingItemWriter())
.build();
}@Configuration
Spring Batch의 모든 Job은@Configuration으로 등록해서 사용한다.jobBuilderFactory.get("itemBatchUpdate")
itemBatchUpdate이란 이름의 Batch Job을 생성한다.
job을 통해 하고자 하는 기능의 이름을 적어주면 좋을 것 같다.
job의 이름은 별도로 지정하지 않고, 이렇게 Builder를 통해 지정한다.stepBuilderFactory.get("jpaPagingItemReaderStep")
jpaPagingItemReaderStep이란 이름의 Batch Step을 생성한다.
마찬가지로, Builder를 통해 이름을 지정한다.chunkSize
한번에 처리될 트랜잭션 단위를 얘기하며, chunkSize 단위로 트랜잭션을 수행하기 때문에 실패할 경우엔 해당 chunkSize 만큼만 롤백한다.
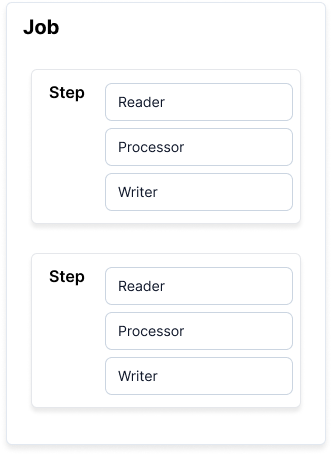
Batch Job을 생성하는 jpaPagingItemReaderJob 코드는 jpaPagingItemReaderStep 을 품고 있다.
Spring Batch에서 Job은 하나의 배치 작업 단위이다.
Job 안에는 여러 Step이 존재하고, Step안에 Reader & Processor & Writer 묶음이 존재한다.
Step은 Job의 구성요소로, 독립적이고 순차적으로 배치 처리를 수행한다. 트랜잭션은 Step 내에서 이뤄지며, 서로 독립되도록 의도적으로 설계되었다.
@Bean
public JpaPagingItemReader<Item> jpaPagingItemReader() {
return new JpaPagingItemReaderBuilder<Item>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(chunkSize)
.queryString("SELECT p FROM Item p")
.build();
}
@Bean
public ItemProcessor<Item, Item> jpaItemProcessor() {
return item -> {
Integer price = item.getPrice();
RestTemplate restTemplate = new RestTemplate();
MultiValueMap<String, String> params = new LinkedMultiValueMap<>();
params.add("url", item.getOriginUrl());
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<MultiValueMap<String, String>> entity = new HttpEntity<>(params, headers);
JSONObject jsonObject = null;
log.info("====START PARSING====");
try{
jsonObject = new JSONObject(
restTemplate.postForObject(${server.url.scrap}, entity, String.class));
}catch (Exception e){
log.info(String.valueOf(e));
throw new ScrapingException();
}
log.info("====FINISH PARSING====");
Integer newPrice = jsonObject.getInt("price");
boolean isIgnoreTarget = price.equals(newPrice);
if(isIgnoreTarget){
return null;
}
log.info(">>>>>>>>> update target item name={}, price={}", item.getName(), newPrice);
item.updatePrice(newPrice);
return item;
};
}
@Bean
public ItemWriter<Item> jpaPagingItemWriter() {
JpaItemWriter<Item> jpaItemWriter = new JpaItemWriter<>();
jpaItemWriter.setEntityManagerFactory(entityManagerFactory);
try {
jpaItemWriter.afterPropertiesSet();
} catch (Exception e) {
throw new RuntimeException(e);
}
return jpaItemWriter;
}JpaPagingItemReader
DB의 데이터를 읽어들인다.pageSize
한번에 조회할 Item의 양을 뜻한다.
(우리가 사용할 JpaPagingItemReader가 상속받는 AbstractPagingItemReader에 보면 pageSize가 기본 10으로 정해져있다. chunk 단위로 reader에서 processor로 전달되기에 pageSize와 chunkSize를 맞춰주는 것이 좋다.)ItemProcessor
Reader에서 넘겨준 데이터 개별건을 가공, 처리한다. Reader에서 읽은 데이터를 원하는 타입으로 변환해서 Writer에 넘겨주거나, Reader에서 넘겨준 데이터를 Writer로 넘겨줄 것인지 결정할 수 있다.null반환시 Writer에 전달되지 않는다.
ItemProcessor<R, W> 의 R는 Reader에서 받을 데이터 타입이고, W는 Writer에 보낼 데이터 타입이다.
ItemWriter
chunk 단위로 묶인 item List를 다룬다. 아래 그림에서와 같이 reader와 processor는 item 하나를 반환하지만, writer의 write()는 Item List를 인자로 받습니다. JPA EntityManger를 이용해 Entity를 DB에 write 해준다.

- jpaPagingItemReader 에서 데이터를 chunkSize만큼씩 읽어온다.
- jpaItemProcessor에서 읽어온 데이터를 가공한다.
- jpaPagingItemWriter에서 저장한다.
영속성을 사용하면 JPA의 경우 ItemWriter구현체에서는flush()가 따라온다.
MySQL 환경에서 Spring Batch
Spring Batch에선 메타 데이터 테이블이 필요하다.
Spring Batch 메타 데이터가 담고 있는 내용은 아래와 같다.
- 이전에 실행한 Job은 어떤 것들인지
- 최근 실패한 Batch Parameter는 어떤 것이고, 성공한 Job은 어떤 것인지
- 다시 실행하면 어디서부터인지
- 어떤 Job에 어떤 Step들이 있었고, Step들 중 성공한 Step과 실패한 Step은 어떤 것인지
해당 테이블이 없다면 Table 'spring_batch.BATCH_JOB_INSTANCE' doesn't exist 오류를 만나게 된다.
IDE에서 파일 검색으로 schema-mysql.sql를 찾아 복사해서
DB Client로 JetBrains의 datagrip을 사용하고 있다면 프로젝트 스키마에 해당 테이블을 추가해서 만들어주면 된다!
(이전에는 schema-만 IDE에 검색해도 촤라락 나왔는데 어느순간부터 나오지 않는다. IDE 검색 설정을 잘못 해준 것으로 보이는데 다른 깃헙에서 찾은 schema-mysql.sql로 테이블을 만들었더니 진행에 오류를 많이 만났다. 내 IDE 내 외부 라이브러리에서 다시 찾아서 해결했었다.)
또한, Spring Batch가 MySQL을 사용하도록 하기 위해서는 application.yml 에 Datasource 설정을 추가한다. 우리는 이미 있던 MySQL 설정에 아래 부분만 추가하였다.
driver-class-name: com.mysql.jdbc.DriverQuartz 활용한 Batch Schedule
@Slf4j
@Component
@RequiredArgsConstructor
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final JpaPagingItemReaderJobConfiguration jpaPagingItemReaderJobConfiguration;
@Scheduled(cron = "0 0 2 * * *")
public void runJob() {
Map<String, JobParameter> confMap = new HashMap<>();
confMap.put("time", new JobParameter(System.currentTimeMillis()));
JobParameters jobParameters = new JobParameters(confMap);
try {
jobLauncher.run(jpaPagingItemReaderJobConfiguration.jpaPagingItemReaderJob(), jobParameters);
} catch (Exception e) {
log.error(">>>>> Error", e);
}
}
}JobLauncher
JobLauncher는 Job과 JobParameters를 사용해 Job을 실행하는 객체다.JobParameters
JobParameters 객체로 JobInstance(Job의 실행 단위)를 구분한다.@Scheduled(cron = "0 0 2 * * *")
주기적인 작업이 있을 때 @Scheduled 어노테이션을 사용해 적용할 수 있다. cron 표기법은 linux의 crontab과 같다.
해당 시간에 맞춰서 정확히 Batch Job 성공!
성공하면 BATCH_JOB_EXECUTION table에 해당 시간에 맞춰 COMPLETED 되어 있는 것을 확인할 수 있다!!

(50개가 있다면 batch scheduling 약 2분 걸림)
참고. pageSize와 chunkSize를 같게 하는 이유
Scheduled cron Expression 크론 표현식
