문제 상황
상품 검색 API에서 각 상품의 썸네일을 구성할 때, ImageFile 테이블에서 해당 item_id에 연결된 이미지 중 첫 번째 값을 조회하여 사용하고 있습니다.
현재 상황
-
테이블 관계
Item테이블과ImageFile테이블은 1 : N 관계Item테이블과Brand테이블은 1 : 1 관계
-
인덱스 현황
Item테이블에(deleted_date, item_name),(deleted_date, brand_id)인덱스가 사용 중
-
데이터 규모
Item데이터 총 약 25만 건Brand데이터 총 약 3만 건ImageFile데이터 총 약 43만 건
-
사용 쿼리
브랜드명에 포함된 특정 키워드(예: '유한')로 상품을 검색하는 SQLSELECT i.item_uuid, i.item_name, i.price, MIN(img.ImageUrl), b.name FROM Item AS i JOIN Brand b ON i.brand_id = b.brand_id LEFT JOIN ImageFile img ON img.item_id = i.item_id WHERE i.deleted_date IS NULL AND b.name LIKE '%유한%' GROUP BY i.item_uuid LIMIT 0, 20;
발생하는 문제
b.name LIKE '%유한%'조건에 와일드카드가 앞에 있어 인덱스가 효과적으로 사용되지 않고,Brand테이블에서 많은 행을 스캔함ImageFile테이블에서MIN(img.ImageUrl)을 구하기 위해 상품별 모든 이미지 데이터를 스캔 및 그룹핑해야 하므로, 데이터량이 큰 만큼 조인 비용이 크게 증가함- 전체 조인 과정에서 대량의 데이터 스캔과 임시 테이블 생성이 발생하여 쿼리 실행 시간이 길어지고 시스템 자원 소모가 증가함
- 결과적으로, 상품 검색 API의 응답 지연 및 성능 저하가 발생함
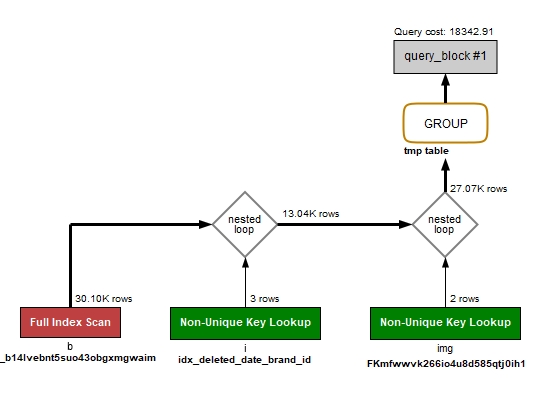
쿼리 시간 : 3.7초

실행 계획
- Brand 테이블에서 name LIKE '%유한%' 조건이 큰 비용 발생 원인
- 와일드카드
%가 앞에 붙어 인덱스를 완전히 활용하지 못함 - 총
30,104건을 인덱스로 스캔했으나, 필터링률은 약 11.1%로 낮음 (약 3,344건만 추출)
- 와일드카드
- Item 테이블은
deleted_date IS NULL AND brand_id조건을 통해 인덱스를 적절히 활용함- 한 번의 스캔당 3건을 검사하며, 조인 결과로 약 13,036건을 생성
- ImageFile 테이블은
item_id기준으로 조인하며 인덱스를 사용함- 총 27,069건의 결과가 생성되어 I/O 비용이 큼
- 최종적으로 img 테이블에서 약 11만 건 이상의 결과가 출력되며 전체 쿼리 비용을 상승시킴
using_temporary_table: true로 임시 테이블이 사용되어, 그룹핑 단계에서 추가 비용이 발생함
첫번째 시도 : 서브 쿼리 사용
SELECT
i.item_uuid,
i.item_name,
i.price,
img.min_url,
b.name
FROM Item AS i
JOIN Brand b ON i.brand_id = b.brand_id
LEFT JOIN (
SELECT item_id, MIN(ImageUrl) AS min_url
FROM ImageFile
GROUP BY item_id
) img ON img.item_id = i.item_id
WHERE
i.deleted_date IS NULL
AND b.name LIKE '%유한%'
LIMIT 0, 20;
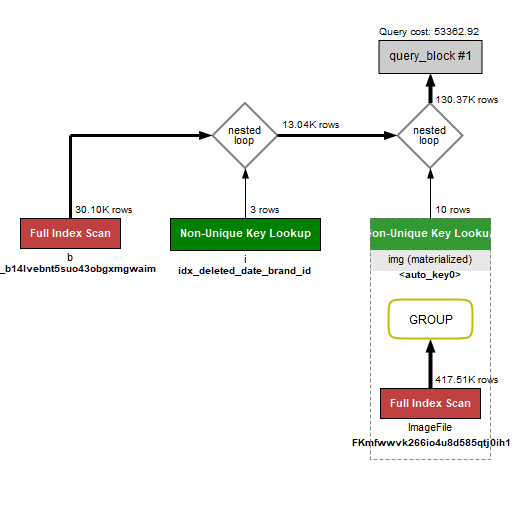
쿼리 시간 : 1.7초

실행 계획
-
Brand 테이블에서
name LIKE '%유한%'조건이 큰 비용 발생 원인- 와일드카드
%가 앞에 붙어 인덱스가 완벽하게 활용되지 않음 - 총
30,104건 스캔 후3,344건만 필터링됨
- 와일드카드
-
Item 테이블은 brand_id와 deleted_date 조건을 인덱스로 잘 활용하고 있음
-
ImageFile 테이블은 서브쿼리에서 임시 테이블 사용하며 item_id 인덱스를 통해 417,513건을 스캔함
- 이로 인해 이미지 관련 조인 비용이 매우 큼
-
최종적으로
img조인에서130,367건 결과가 나오면서 비용 상승 -
임시 테이블(
using_temporary_table: true)이 사용되고 있어 그룹핑 관련 작업에 비용이 발생함
두번째 시도 : 반정규화
- Item 테이블에 thumbnail 컬럼 추가
- 이미지의 첫 번째 URL을 별도로 저장하여 조인 및 그룹핑 비용 제거
SELECT
i.item_uuid,
i.item_name,
i.price,
i.thumbnail,
b.name
FROM Item AS i
JOIN Brand b ON i.brand_id = b.brand_id
WHERE
i.deleted_date IS NULL
AND b.name LIKE '%유한%'
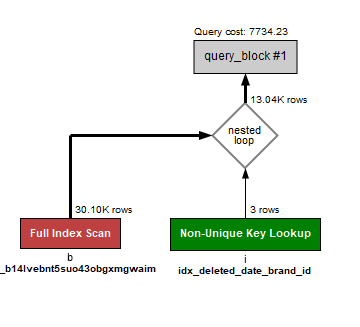
LIMIT 0, 20;쿼리 시간 : 0초

실행 계획
-
Brand 테이블의
name LIKE '%유한%'조건으로 인해 약 26,553건을 인덱스 스캔하며 2,950건으로 결과가 필터링됨 -
Item 테이블은
deleted_date와brand_id를 복합 인덱스로 효율 조회하여 11,498건을 조인 결과로 생성 -
인덱스를 효과적으로 사용해 추가 테이블 액세스 없이 커버 인덱스 스캔으로 성능 향상
-
Brand 이름에 대한 와일드카드 검색은 여전히 비용 발생 요소
느낀점
다대다나 일대다 관계에서 데이터를 많이 집계하는 쿼리는 비용이 커서, 반정규화를 통해 미리 필요한 데이터를 저장해두는 방법이 효과적이라는 걸 배웠습니다. 임시 테이블과 그룹핑 작업이 쿼리 속도를 많이 떨어뜨리니, 가능한 한 미리 집계된 데이터를 활용하는 설계가 중요하다는 것도 느꼈습니다. 다음에는 브랜드 이름 검색 조건도 개선해보려고 합니다.
