2장: 윈도우 실습 환경 구성
11.11.2022 현재 es/kibana version: 8.5.0
-
elasticsearch 압축을 풀고 bat파일 실행해보면 cmd에서 계속 뭐라고 뭐라고 씨부렁 거리는데 http://localhost:9200으로 접속해보면
ERR_EMPTY_RESPONSE라고 오류 메시지 반환
해결책: config/elasticsearch.yml에서 ssl 설정을 false로 수정
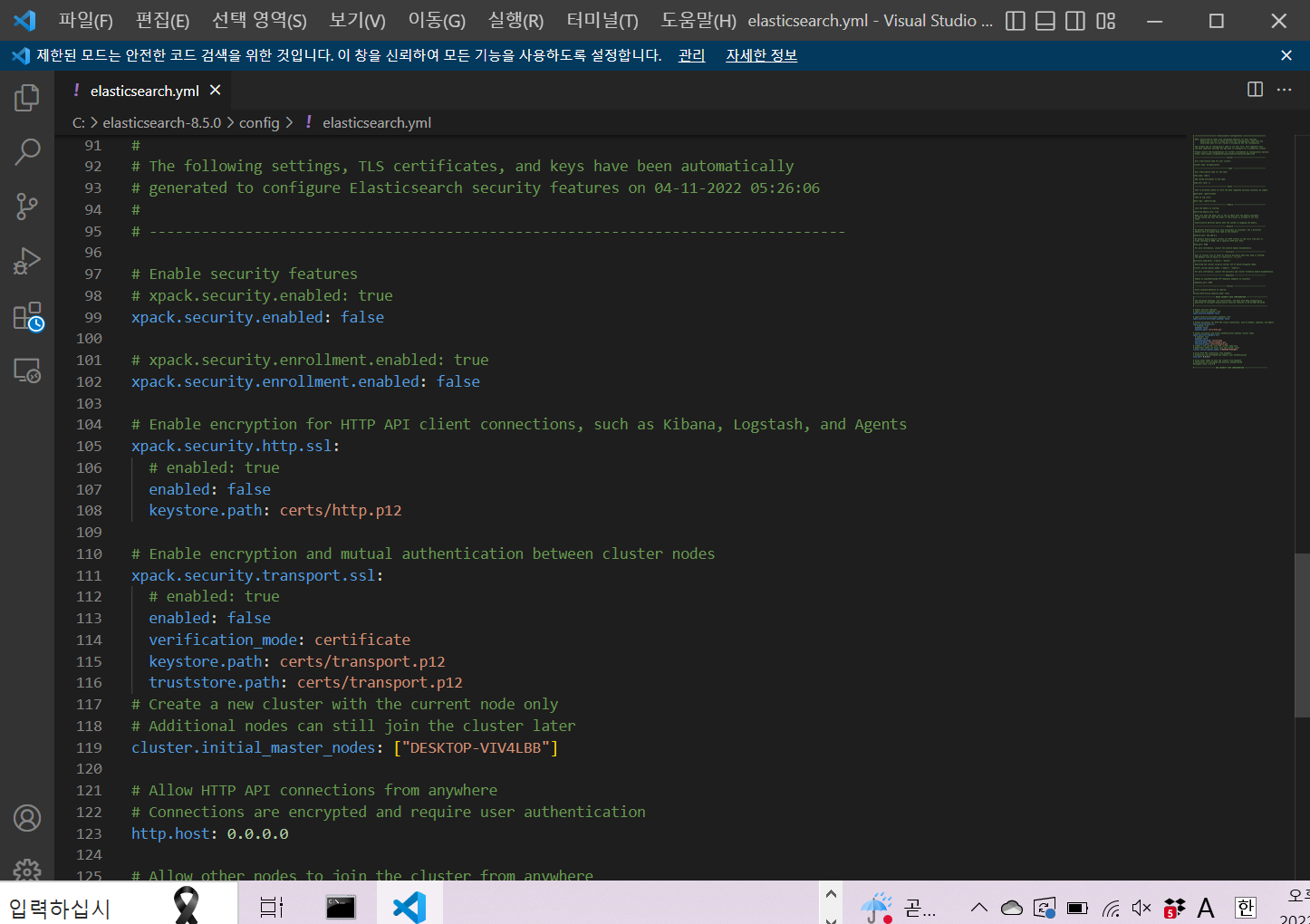
혹은 http://localhost:9200 대신 https://localhost:9200을 사용해도 된다고 함(검증해보지는 않음)
reference: https://nanglam.tistory.com/33 (원 source: https://stackoverflow.com/questions/71492404/elasticsearch-showing-received-plaintext-http-traffic-on-an-https-channel-in-con) -
kibana 압축 풀고 bat파일 실행하면 에러 메시지는 안 나는데 http://localhost:5601 접속하면 연결에러메시지창이 떠버림
해결책: kibana.yml 파일에서 server.port, server.host, elasticsearch.hosts 등 주석처리되어있는 거 주석 풀어주면 됨 https://m.blog.naver.com/ho96200/222019946006 -
http://localhost:5601 들어가면 작은 글씨로 "kibana server is not ready yet"이라고 쓰인 창만 나오고, kibana log에는
[.kibana_task_manager] action failed with '[index_not_green_timeout] timeout waiting for the status of the [.kibana_task_manager_8.5.0_001] index to become 'green' refer to https://www.elastic.co/guide/en/kibana/8.5/resolve-migrations-failures.html#_repeated_time_out_requests_that_eventually_fail for information on how to resolve the issue.'. retrying attempt 5 in 32 seconds.라고 뜸
해결책: 로컬의 저장공간 부족.. 이것저것 해보다가 안돼서 저장공간 확보(20gb -> 35gb)해주니 정상적으로 kibana 접속 가능해짐
3장: 엘라스틱서치 기본
- es의 요청과 응답은 REST API 형태로 이루어짐: 간단히 웹상으로 왔다갔다 한다는 얘기인 듯
- kibana는 왜 필요한가?: es와 편리하게 rest api로 통신하기 위한 도구임
- kibana의 cat API를 통해 가독성 좋은 상태로 상태 확인 가능
필드 -> 도큐먼트(json) -> 인덱스 -> 클러스터의 구조
- 도큐먼트
레코드와 같음. field: value의 형태로 이루어진 json으로 저장, data type은 es의 mapping으로 지정할 수 있음. dynamic mapping이 가능해서 data type 명시적으로 지정하지 않아도 됨.
update 과정이 꽤나 귀찮아서 도큐먼트 업데이트가 필요하다면 다른 db를 사용하는 게 좋을 것
도큐먼트 하나하나 생성하기에는 손이 너무 많이 가니까 bulk api를 사용하는데, 키바나에서는 파일 넣는 게 안되니까 파일을 만들어서 cmd에서 curl로 파일을 집어넣음. 단, bulk api는 json이 아니라 ndjson을 사용하므로 json처럼 개행을 넣으면 안됨
- 인덱스
다수 도큐먼트를 저장하는 단위로, rdb의 테이블과 유사. 동일 인덱스의 도큐먼트는 동일한 스키마를 가지며, 도큐먼트는 무조건 하나의 인덱스에 포함돼야 함. 관리의 효율성을 위해 grouping을 하기도 함.
- 매핑
기본적으로 dynamic mapping(자동으로 매핑)이지만, short/long text/keyword 등 데이터 타입 선택할 수 있음. properties 내에 type: data type을 이용해 명시적 매핑을 할 수도 있음
텍스트 데이터의 경우, text/keyword 데이터 타입을 선택할 수 있는데, text는 전문 검색이 필요한 데이터로 텍스트 분석기가 텍스트를 작은 단위로 분리하며(분석기 통해 역색인 진행), keyword는 정렬이나 집계에 사용되는 텍스트 데이터로 분석을 하지 않고 원문을 통째로 인덱싱함
multifield를 설정할 수 있어서 하나의 필드를 여러 데이터 타입으로 사용할 수 있음
- 인덱스 템플릿
동일한 스키마의 인덱스를 관리 편의성 등을 위해 여러 개의 인덱스로 만들어야 할 일이 있는데, 그런 경우에 사용될 수 있는 기능임
다이내믹 템플릿도 가능한데, 로그 시스템이나 비정형화된 데이터의 인덱싱이 필요할 수도 있기 때문
- 분석기
캐릭터 필터(선택) -> 토크나이저 -> 토큰 필터(선택)의 구성
캐릭터 필터: 문자열 변경 및 불필요 문자 제거
토크나이저: 토큰 분리(시작 및 끝 index 기록)
토큰 필터: 토큰의 대소문자 구분, 형태소 분석 등
custom analyzer도 가능
