Intro
프로그래머스 강의 '실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트 with Python' 을 수강했다. (6기)
이 강의 내용을 정리하여 공유하고자 한다.
https://programmers.co.kr/learn/courses/12916
3주차는 데이터 엔지니어링을 위한 SQL 문법을 공부했다.
6. SQL for Data Engineers
Why still SQL in the era of Big Data?
- 사람들이 맵리듀스로 프로그래밍을 하다가 깨달음
- “정형화된 데이터를 처리하는데는 SQL만한게 없구나!”
- “SQL을 scalable하지 않은 RDBMS에서 실행시키면 문제지만, 하둡같은 scalable한 곳 위에서 돌리면 충분히 좋구나”는 것이 밝혀지면서 SQL이 다시 살아남
- 2000년대 초반까지만 해도 죽어가는 언어였음
- 이 SQL을 하둡에 porting한 것이 바로 하이브이고, 그 하이브가 발전한 것이 presto이런 것들임
Easy to Use and Vetted over Time
- 70년대 초반 IBM에서 만듦
- 오래된 언어라 검증이 되었다
- DDL, DML 크게 2종류로 나뉨
- DDL : Data Definition Language.
- CREATE, DROP, ALTER
- DML : Data Manipulation Language.
- SELECT INSERT INTO
- DDL : Data Definition Language.
- 하둡이 뜨면서 맵리듀스가 데이터 분석에 사용되었는데, 생산성이 떨어지는 것으로 밝혀지자 SQL이 다시 부각됨.
Not Great in Handling Unstructured Data
- SQL은 만능이 아님. 비정형데이터는 SQL 사용하는 것이 좋지 않다.
- 하둡은 요새 잘 안 쓴다. Spark를 사용하기 위한 인프라정도로만 사용함
- 비정형데이터는 작을 때는 Pandas, 클 때는 Spark를 사용하여 처리함
실습 전 기억할 점 1
- 현업에서 깨끗한 데이터란 존재하지 않음
- 항상 데이터를 믿을 수 있는지 의심하기 → 의(疑)데이터증
- 실제 레코드를 몇 개 살펴보는 것 만한 것이 없다 → 노가다
- 테이블정의서만으로는 부족하고 직접 SELECT해서 봐야함
- 데이터 정제해서 깨끗하게 만드는 작업이 전체의 70% 시간 소요
- 데이터 일을 한다면 항상 데이터의 품질을 의심하고 체크하는 습관이 필요
- 중복된 레코드들 체크하기 → 중복 레코드 많으면 안 좋은 사인
- 최근 데이터의 존재 여부 체크하기 (freshness) → 최근이 아니면 문제가 될 수 있음
- Primary key uniqueness가 지켜지는지 체크하기
- 값이 비어있는 컬럼들이 있는지 체크하기 → NULL 체크
- 위의 체크는 코딩의 unit test 형태로 만들어 매번 쉽게 체크해볼 수 있음
- 어쩌면 DE에게는 그렇게 중요한 일이 아닐 수 있음.,
- 왜냐하면 DE는 보통 전체데이터 긁어서 주고 그러니까.
- 그런데 좋은 DE가 되려면 이런 습관 가지는 것이 좋다.
실습 전 기억할 점 2
- 어느 시점이 되면 너무나 많은 테이블들이 존재하게 됨 → Data Discovery 이슈
- 회사 성장과 밀접한 관련
- 중요 테이블들이 무엇이고 그것들의 메타 정보를 잘 관리하는 것이 중요해짐
- 그 시점부터는 Data Discovery 문제들이 생겨남
- 무슨 테이블에 내가 원하고 신뢰할 수 있는 정보가 들어있나?
- 테이블에 대해 질문을 하고 싶은데 누구에게 질문을 해야하나?
- 이 문제를 해결하기 위한 다양한 오픈소스와 서비스들이 출현
- DataHub (LinkedIn), Amundsen (Lyft), ...
- Select Star, DataFrame, …
- 실리콘밸리의 대부분 회사들은 이런 것 중 하나를 사용하더라
SQL 기본
- 먼저 다수의 SQL 문을 실행한다면 세미콜론으로 분리 필요
- SQL문1; SQL문2; SQL문3;
- SQL 주석
- -- : 인라인 한줄짜리 주석. 자바에서 //에 해당
- /* -- */: 여러 줄에 걸쳐 사용 가능한 주석
- SQL 키워드는 대문자를 사용한다던지 하는 나름대로의 포맷팅이 필요
- 팀 프로젝트라면 팀에서 사용하는 공통 포맷이 필요
- "," 위치 등등 사소하지만 정해놓는 것이 필요하다!
- 테이블/필드이름의 명명규칙을 정하는 것이 중요
- 단수형 vs. 복수형
- User vs. Users
- _ vs. CamelCasing
- user_session_channel vs. UserSessionChannel
- 단수형 vs. 복수형
SQL DDL 1
- CREATE TABLE
- Primary key 속성을 지정할 수 있으나 무시됨
- Primary key uniqueness
- Big Data 데이터웨어하우스에서는 지켜지지 않음 (Redshift, Snowflake, BigQuery)
- Primary key uniqueness
- CTAS: CREATE TABLE [table_name] AS SELECT → SELECT문의 결과로 테이블 생성
- vs. CREATE TABLE and then INSERT → 일반적인 방법
예시)
CREATE TABLE raw_data.user_session_channel (
userid int,
sessionid varchar(32) primary key,
channel varchar(32)
);- PK : 이 테이블에서 유일한 값을 가져야 하는 컬럼.
- 다만 DW(Redshift, bigqur, snow ..) 에서는 PK를 아무리 지정해도 먹히지 않음.
- 왜냐하면 PK를 지정하는 순간 수많은 데이터 조회시 모든 데이터의 PK를 식별하여 찾기 때문에 시간이 너무 많이 걸려서
- DW에서도 지정해줄 수는 있음 사용되지만 않을 뿐.
SQL DDL 2
- DROP TABLE
- DROP TABLE table_name;
- 없는 테이블을 지우려고 하는 경우 에러를 냄
- DROP TABLE IF EXISTS table_name; → 없을 경우에도 에러가 발생하지 않음!
- vs. DELETE FROM
- DELETE FROM은 조건에 맞는 레코드들을 지움 (테이블 자체는 존재)
- DROP TABLE table_name;
SQL DDL 3
- ALTER TABLE → 테이블 수정
- 새로운 컬럼 추가:
- ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입;
- 기존 컬럼 이름 변경:
- ALTER TABLE 테이블이름 RENAME 현재필드이름 to 새필드이름
- 기존 컬럼 제거:
- ALTER TABLE 테이블이름 DROP COLUMN 필드이름;
- 테이블 이름 변경:
- ALTER TABLE 현재테이블이름 RENAME to 새테이블이름;
- 새로운 컬럼 추가:
SQL DML - 테이블 레코드 조작 언어 (1)
- 레코드 질의 언어: SELECT
- 뒤에서 더 자세히 설명
- SELECT FROM: 테이블에서 레코드와 필드를 읽어오는데 사용
- WHERE를 사용해서 레코드 선택 조건을 지정
- GROUP BY를 통해 정보를 그룹 레벨에서 뽑는데 사용하기도 함
- DAU, WAU, MAU 계산은 GROUP BY를 필요로 함
- ORDER BY를 사용해서 레코드 순서를 결정하기도 함
- 보통 다수의 테이블의 조인해서 사용하기도 함
SQL DML - 테이블 레코드 조작 언어 (2)
- 레코드 수정 언어:
- INSERT INTO: 테이블에 레코드를 추가하는데 사용 → REDSHIFT의 COPY는 BULK로 몇 천만건의 데이터를 밀어넣는 명령어. 아마 POSTGRES기반이라 같은 명령어인듯
- UPDATE FROM: 테이블 레코드의 필드 값 수정
- DELETE FROM: 테이블에서 레코드를 삭제
- vs. TRUNCATE
Basic SQL
SELECT 1
- 테이블(들)에서 레코드들(혹은 레코드수)을 읽어오는데 사용
- WHERE를 사용해 조건을 만족하는 레코드
SELECT 필드이름1, 필드이름2, …
FROM 테이블이름
WHERE 선택조건
GROUP BY 필드이름1, 필드이름2, ...
ORDER BY 필드이름 [ASC|DESC] -- 필드 이름 대신에 숫자 사용 가능
LIMIT N;처음 테이블을 볼 때 LIMIT 100 정도로해서 훑어봄
SELECT 2
*: 모든 컬럼 읽기
SELECT 3
특정한 컬럼 지정해도 됨.
SELECT userId, sessionId, channel
FROM raw_data.user_session_channel;
SELECT *
FROM raw_data.user_session_channel
LIMIT 10;
SELECT COUNT(1) → 여기에는 어떤 값이든 상관없음. 보통 1을 많이 씀
FROM raw_data.user_session_channel;WHERE
- IN
- WHERE channel in (‘Google’, ‘Youtube’)
- WHERE channel = ‘Google’ OR channel = ‘Youtube’
- NOT IN
- WHERE channel in (‘Google’, ‘Youtube’)
- LIKE and ILIKE
- LIKE is a case sensitive string match → 대소문자 구별O
- ILIKE is a case-insensitive string match → 대소문자 구별X
- WHERE channel LIKE ‘G**%**’ -> ‘G*’
- WHERE channel LIKE ‘%o%’ -> ‘o’
- NOT LIKE or NOT ILIKE
- BETWEEN
- Used for date range matching
STRING Functions
- LEFT(str, N)
- REPLACE(str, exp1, exp2)
- UPPER(str)
- LOWER(str)
- LEN(str)
- LPAD, RPAD
- SUBSTRING
INSERT INTO vs. COPY
INSERT INTO는 모든 곳에서 사용되지만 느린편이다
- INSERT INTO is slower than COPY
- COPY is a batch insertion mechanism.
- COPY는 4주차에 사용 예정
- INSERT INTO table_name SELECT * FROM … → SELECT결과를 INSERT하는 것도 가능
- This is better than CTAS (CREATE TABLE table_name AS SELECT) if you want to control the types of the fields
- But matching varchar length can be challenging
- Snowflake and BigQuery support String type (no need to worry about string length)
- This is better than CTAS (CREATE TABLE table_name AS SELECT) if you want to control the types of the fields
ORDER BY
- Default ordering is ascending
- ORDER BY 1 ASC
- Descending requires “DESC”
- ORDER BY 1 DESC
- Ordering by multiple columns:
- ORDER BY 1 DESC, 2, 3
- NULL value ordering
- By default, NULL values are ordered the last for ascending order → ASC일 경우 NULL이 맨 뒤로 가고
- By default, NULL values are ordered the first for descending order → DESC일 경우 NULL이 맨 앞으로 옴
- You can change this with NULLS FIRST | NULLS LAST → NULL위치를 내 마음대로 설정 가능
Type Cast and Conversion
CAST : 타입 변경을 의미
- DATE Conversion:
- CONVERT_TIMEZONE
- CONVERT_TIMEZONE('America/Los_Angeles', ts)
- select pg_timezone_names();
- DATE, TRUNCATE
- DATE_TRUNC
- 첫번째 인자가 어떤 값을 추출하는지 지정 (week, month, day, …)
- EXTRACT or DATE_PART: 날짜시간에서 특정 부분의 값을 추출가능
- DATEDIFF, DATEADD, GET_CURRENT, ...
- CONVERT_TIMEZONE
- Type Casting:
- cast or :: operator
- category::int or cast(category as int)
- TO_CHAR, TO_TIMESTAMP
NULL
- 값이 존재하지 않음을 의미
- 0이나 비어있는 string과는 다름을 분명히 인지
- IS NULL or IS NOT NULL
- ~\= NULL or <> NULL~
- Boolean 타입의 필드도 “IS TRUE” 혹은 “IS FALSE”로 비교
- 'AA Is Not False' == 'AA Is True' the same? → 서로 다른 의미! NULL 때문에
- A: True, False, NULL -> WHERE A is True, WHERE A is not FALSE
- LEFT JOIN시 매칭되는 것이 있는지 확인하는데 아주 유용
- NULL 값을 다른 값으로 변환하고 싶다면
- COALESCE를 사용 (뒤에서 더 설명)
- NULLIF
- NULL로 나누면? vs. 0으로 나누면?
- NULL로 나누면 다 NULL로 나옴
JOIN
- INNER JOIN
양쪽 테이블에서 매치되는 레코드만 리턴
양쪽 테이블 필드가 모두 채워진 상태로 리턴됨
- LEFT JOIN
왼족 테이블의 모든 레코드를 리턴함
오른쪽 테이블의 필드는 매칭되는 경우만 채워진 상태로 리턴됨, 매칭 안 되면 NULL로 리턴
- FULL JOIN
양쪽 모든 레코드 리턴
매칭되는 경우에만 양쪽 테이블의 모든 필드가 채워진 상태로 리턴됨
아주 가끔 사용함
- CROSS JOIN
왼쪽 테이블과 오른쪽 테이블의 모든 레코드 조합을 리턴함
JOIN컨디션 없이 (컬럼지정없이) 사용함
- SELF JOIN
동일한 테이블을 ALIAS를 달리해서 자신과 조인함
가끔 사용함
질의응답
Q. 스타 스키마가 뭐에요??
A.
데이터 모델링할 때 entity단위로 여러 테이블로 나눠놓는 것이 Star schema.
join 많이 써야하니까 쓸 때는 번거롭지만 특정 값을 변경할 때 어느 테이블에서만 변경하면 되니까 수정이 편함스타 스키마와 정반대로, 한 테이블에 모든 정보 들어가있는 것이 denormalized schema.
사용하기는 편한데 특정 값 변경할 때는 불편함.Star schema <-> denormalized schema
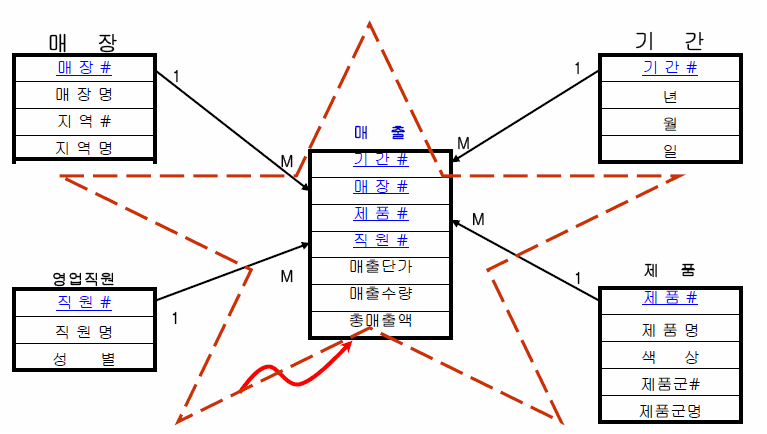
출처 : https://itwiki.kr/w/%EC%8A%A4%ED%83%80_%EC%8A%A4%ED%82%A4%EB%A7%88
Q. 기초적인 부분인 것 같은데, 헷갈려서 여쭤봅니다.
SQL을 사용하기 위한(?) RDMBS의 종류에 MySQL, OracleDB, PostgreSQL 등등이 있는 것이고, 서로 공유 되는 문법(select, from, count 등등)도 있는 반면에 각 RDBMS에서만 사용될 수 있는 고유의 문법(MySQL: date_format. PostgreSQL: to_char 등)이 있는 것이 올바른 이해일까요?
A.
맞음. 사투리처럼 각자 고유한 문법이 있다.
Q. Redshift와 PostgreSQL의 차이점에 대해 여쭤봅니다...!
Redshift는 데이터웨어하우스로, 다양한 raw data를 저장할 수 있는데, 그 중에 관계형 데이터에 대해서는 PostgreSQL을 사용해서 저장하는 건가요!?
A.
REDSHIFT는 POSTGRES기반으로 만들어져서,, 그 문법을 거의 그대로 사용하지만 일부 다른 점이 있다.
