SQL(Structured Query Language)
DBMS는 데이터베이스를 관리하는 소프트웨어로 이를 이용하면 데이터베이스를 참고, 추가, 삭제, 갱신 가능한데, SQL은 그중에서도 관게형 데이터베이스 관리 시스템의 데이터를 관리하기 위해서 만들어진 프로그래밍 언어이다.
- RDBMS로는 다음과 같은 것들이 있다.
- Oracle
- DB2
- SQL Server
- PostgreSQL
- MySQL
- SQLite
DML(Data Manipulation Language)
- SQL의 기본이 되는 명령어로 데이터 조작 언어이며 데이터베이스에 이미 존재하는 레코드를 조회, 삽입, 수정, 삭제 등 데이터를 조작할 때 사용한다.
SELECT
데이터를 읽어들일 때 사용한다. (질의)
SELECT
id,
name,
age,
gender
FROM usersINSERT
데이터를 삽입할 때 사용한다. (등록)
INSERT INTO users (
id,
name,
age,
gender
) VALUES (
1,
"david",
27,
"man"
), (
2,
"jane",
19,
"woman"
)UPDATE
데이터를 업데이트할 때 사용한다. (수정)
UPDATE users SET age = 25 WHERE name = "david"DELETE
데이터를 삭제할 때 사용한다.
DELETE FROM users WHERE gender = "man"DDL(Data Definition Language)
- 데이터 정의 언어로 테이블이나 관계의 구조를 생성하는데 사용한다.
- SCHEMA, DOMAIN, TABLE, VIEW, INDEX를 정의하거나 변경 또는 삭제할 때 사용한다.
CREATE
데이터베이스, 테이블 등을 생성한다.
CREATE TABLE accounts (
id INT NOT NULL AUTO_INCREMENT,
, name VARCHAR2(10)
, address VARCHAR2(50)
, phone VARCHAR2(20)
, PRIMARY KEY(id));ALTER
테이블을 수정한다.
ALTER TABLE accounts ADD age INT;DROP
이미 존재하는 데이터베이스, 테이블을 삭제한다.
DROP DATABASE USERS;TRUNCATE
테이블을 초기화 하며 한번 삭제시 돌이킬 수 없다.
TRUNCATE TABLE users;DCL(Data Control Language)
-
데이터 제어 언어로 데이터의 사용 권한을 관리하는데 사용하며 트랜잭션과 제이터 접근 권한을 제어하는 명렁어가 포함되어 있다.
-
GRANT : 사용자에게 작업에 대한 수행 권한을 부여한다.
GRANT ALL ON [dbname.table_name] TO [user@host] IDENTIFIED BY 'my_password';
- REVOKE : 사용자에게 부여한 권한을 박탈한다.
REVOKE insert,update,create ON [dbname.table_name]TO [user@host];- COMMIT : 작업한 결과를 저장하고, 데이터 조작(INSERT, UPDATE, DELETE 등)이 정상적으로 완료되었음을 관리자에게 알려주는 명령어로 데이터가 완전히 업데이트되며, 모든 사용자가 변경한 데이터의 결과를 볼 수 있게 된다.
COMMIT;- ROLLBACK : 트랜잭션의 작업을 취소 및 원래대로 복구하는 역할을 한다.
COMMIT 명령어를 사용하기 이전의 상태만 ROLLBACK이 가능하다.
COMMIT을 하게 되면 위물리디스크에 직접 저장하고 알리는 기능이므로, 이미 물리적으로는 이전의 상태가 저장되어 있지 않기 때문에 이전으로 돌아갈 수 없다.
ROLLBACK;SQL 명령
SELECT
SELECT 뒤에는 찾고싶은 목적 대상들(Column)을 나열하고, FROM 뒤에는 찾을 대상이 있는 공간(Table)을 작성, WHERE 뒤에는 조건문을 작성한다.
SELECT [컬럼 이름]
FROM [테이블 이름]
WHERE [조건]
SELECT user_id, event, event_date
FROM user_log
WHERE user_id = '1';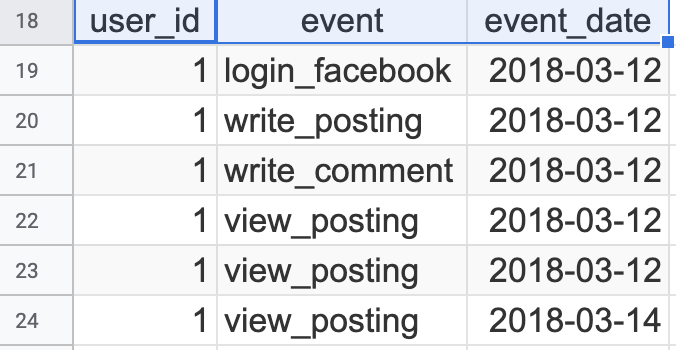
GROUP BY
컬럼들을 그룹화한다. (aggregate)
GROUP BY [그룹화할 컬럼]
SELECT user_id, event, event_date, COUNT(DISTINCT user_id) AS unique', COUNT(user_id) AS 'total'
FROM user_log
WHERE user_id = '1'
GROUP BY user_id, event, event_date;

HAVING
GROUP BY를 통해 나온 값을 조건으로 걸고 싶은 경우에 사용한다.
HAVING [그룹화한 뒤 조건]
SELECT event_date, COUNT(DISTINCT user_id) AS 'unique'
FROM user_log
GROUP BY event_date
HAVING unique >= 2
ORDER BY event_date;
ORDER BY
반환되는 튜플들의 정렬방식
ORDER BY [칼럼명]
SELECT user_id, event, event_date, COUNT(DISTINCT user_id) AS 'unique', COUNT(user_id) AS 'total'
FROM user_log
WHERE user_id = '1'
GROUP BY event, event_date
ORDER BY event_date;
DELETE vs TRUNCATE vs DROP
DELETE
테이블 정의는 그대로 둔 채 데이터만 삭제한다.
TRUNCATE
테이블이 삭제되지는 않고 데이터만 삭제되며, 행은 지정 선택해서 지울수 없고 DELETE보다 빠른 속도로 처리된다.
DROP
테이블과 테이블에 저장된 데이터를 모두 삭제한다.
Join
- 관계형 데이터베이스는 중복을 최소화해 데이터를 관리하기 위해서 정규화 과정을 거치는데 이 과정에서 테이블끼리 관계를 갖게된다.
- Foreign key로 걸려있는 2개의 table들을 join(연결)해서 양쪽 table에서 모두 row를 읽어 들이고 싶을 때는 join 문을 사용해야 한다.(교집합)
기본 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
INNER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키Join의 종류
-
Inner Join
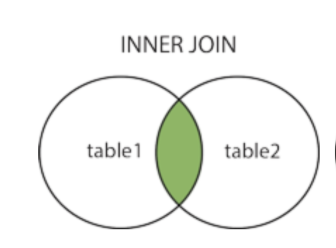
일반적인 join문으로 기준 테이블과 조인한 테이블의 중복값을 선택한다.
-
Outer Join
-
Left Join
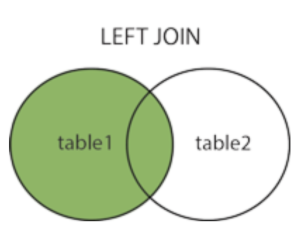
왼쪽 테이블을 기준으로 조인하며 기준이 되는 테이블과 조인이 되는 테이블 중 기준 테이블과 중복된 값을 선택한다. -
Right Join
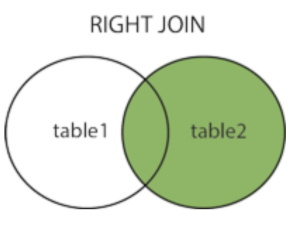
오른쪽 테이블을 기준으로 조인하며 조인되는 테이블과 기준이 되는 테이블중 조인 되는 테이블과 중복된 값을 선택한다.
- Full Join
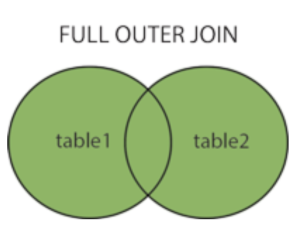
기준이 되는 테이블과 조인이되는 테이블의 모든 row를 선택한다.
-
