데이터분석
- 주제 : 서울시 구별 지하철 승/하차 수와 스타벅스 매장수 상관관계
데이터
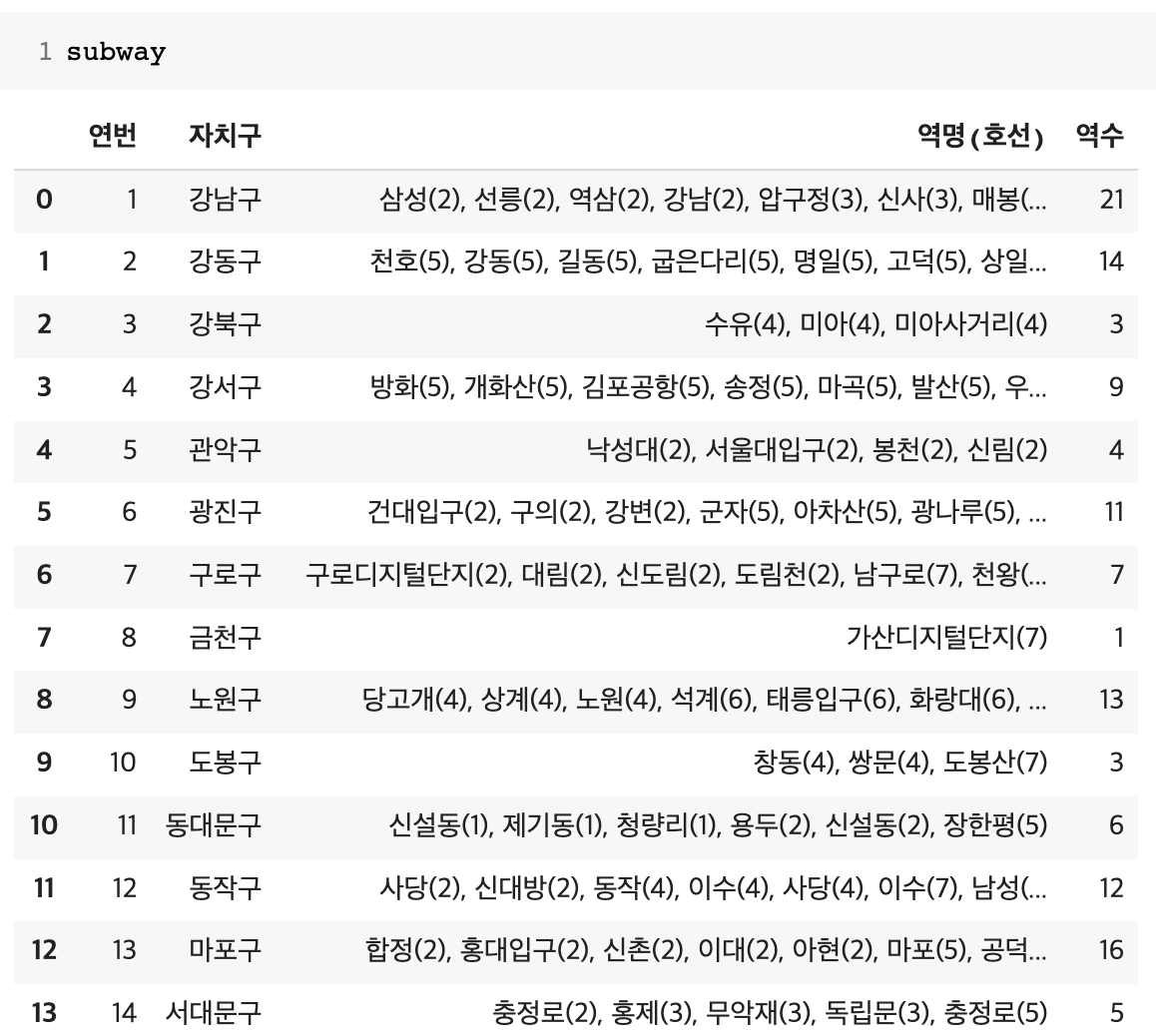
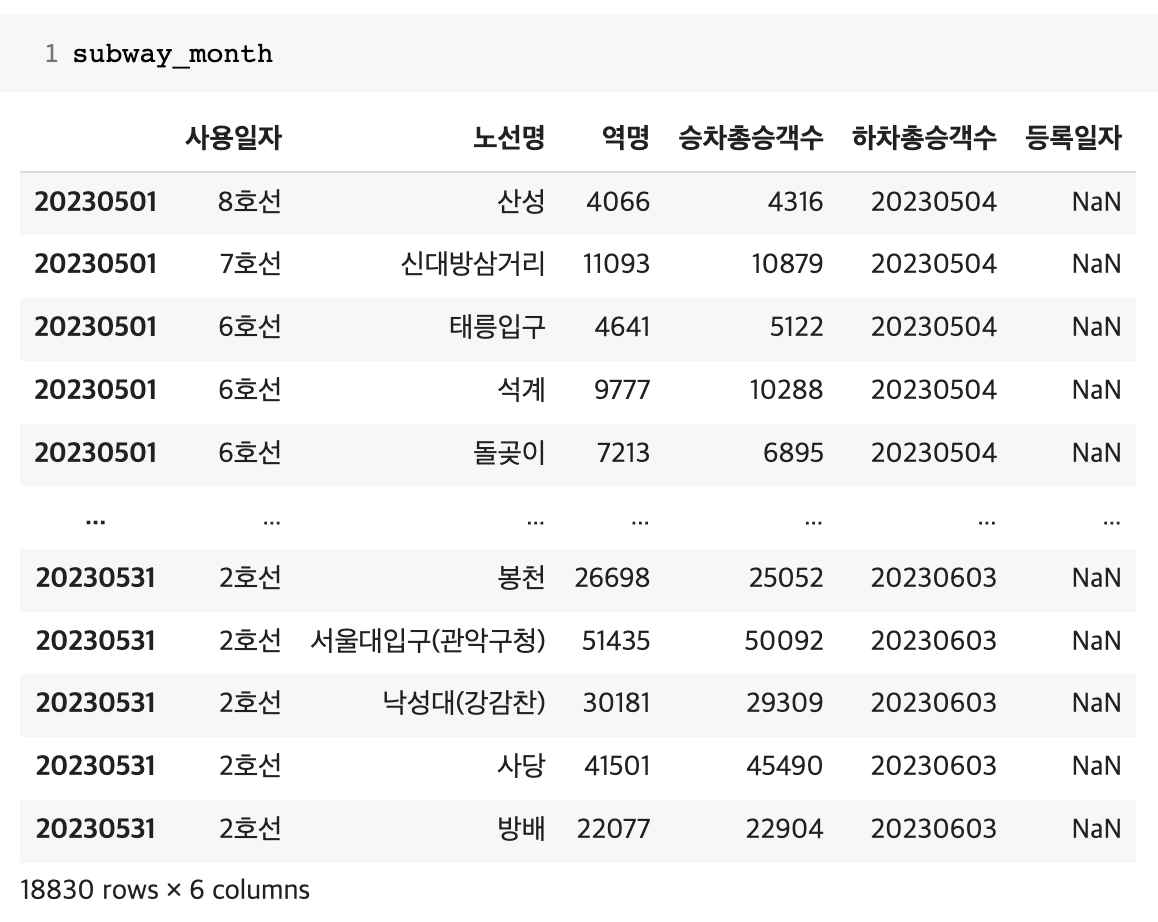
- 지하철 역별 승하차 인원정보
- 구별 지하철역 정보
- 스타벅스 매장수 정보
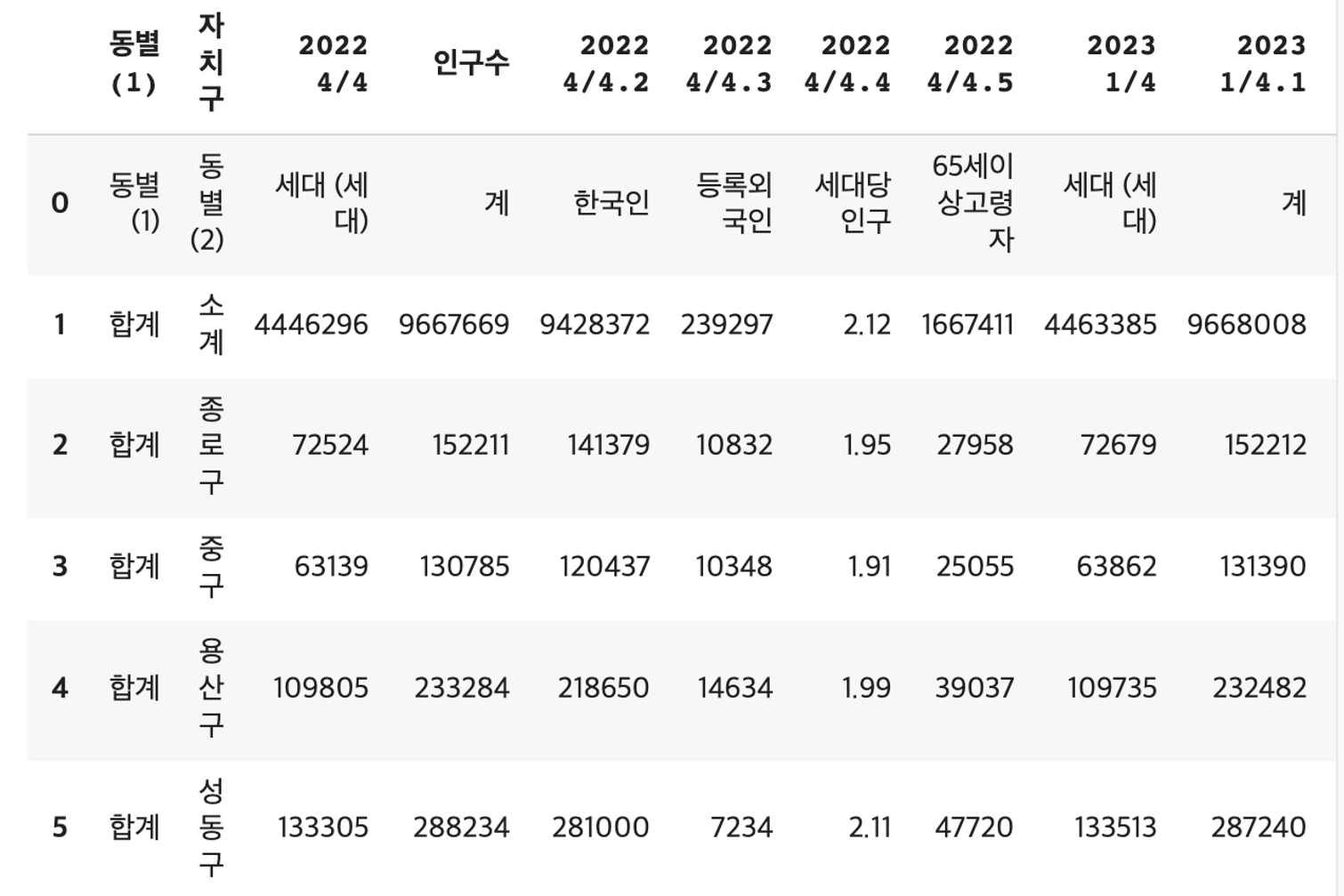
- 자치구별 인구수 정보
- 행정구역(구별) 통계 - 자치구별 면적
- 데이터 분석(참고)
분석 방법
0. 필요한 모듈 import
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 그래프 그릴 때 한글 오류 해결(나눔 폰트 설치)
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
# 런타임 다시 시작
# matplotlib의 폰트를 Nanum 폰트로 지정
plt.rc('font', family='NanumBarunGothic')1. 데이터 수집
# 서울시 지하철 역별 승하차 인원정보 (2023년 5월)
subway_month = pd.read_csv('/content/drive/MyDrive/CodingOn/CARD_SUBWAY_MONTH_202305.csv')
# 자치구별 지하철역 정보
subway = pd.read_csv('/content/drive/MyDrive/CodingOn/서울교통공사_자치구별지하철역정보_20221130.csv', encoding='cp949')
# 자치구별 인구수 정보
population = pd.read_csv('/content/drive/MyDrive/CodingOn/주민등록인구_20230611111431.csv')
# 스타벅스 매장수 통계 - 서울특별시
starbucks = {'강남': 87, '강동': 17,'강북':6,'강서':25,
'관악':12,'광진':19,'구로':14,'금천':13,'노원':14,'도봉':4,'동대문':10,
'동작':11,'마포':35,'서대문':22,'서초':48,'성동':15,'성북':15,
'송파':34,'양천':17,'영등포':41,'용산':25,'은평':13,'종로':40,
'중구':55,'중랑':8}
# 매장수만 배열로 저장
starbuckscount = list(starbucks.values())

2. 데이터 전처리
# 컬럼명 수정
subway_month.rename(columns={'노선명':'역명','역명':'승차수','승차총승객수':'하차수'}, inplace=True)
# 필요한 컬럼만 추출
mysubwaymonth = subway_month[['역명','승차수','하차수']]
# 지하철역명에서 괄호 제거
mysubwaymonth['역명']=mysubwaymonth['역명'].str.replace(r"\(.*\)","")
# 컬럼명 변경
subway.rename(columns={'역명(호선)':'역명'}, inplace=True)
# 필요한 컬럼 추출, index25~29는 구가 아닌 시라서 제외
mysubway = subway[['자치구','역명']].iloc[:25]
# 역명에서 괄호 제거
mysubway['역명']=mysubway['역명'].str.replace(r"\(.\)","")
# subway_month와 데이터 호환을 위해 서울을 서울역으로 대체
mysubway['역명']=mysubway['역명'].str.replace(r"서울,","서울역,")
# 컬럼명 변경
population.rename(columns={'2022 4/4.1':'인구수', '동별(2)':'자치구'}, inplace=True)
# 필요없는 데이터 제거
mypopulation=population[['자치구', '인구수']].iloc[2:]
# 자치구순으로 정렬하고 인덱스 초기화
populationstatis=mypopulation.sort_values('자치구').reset_index(drop=True)
# 데이터타입 변경
populationstatis['인구수']=populationstatis['인구수'].astype(int)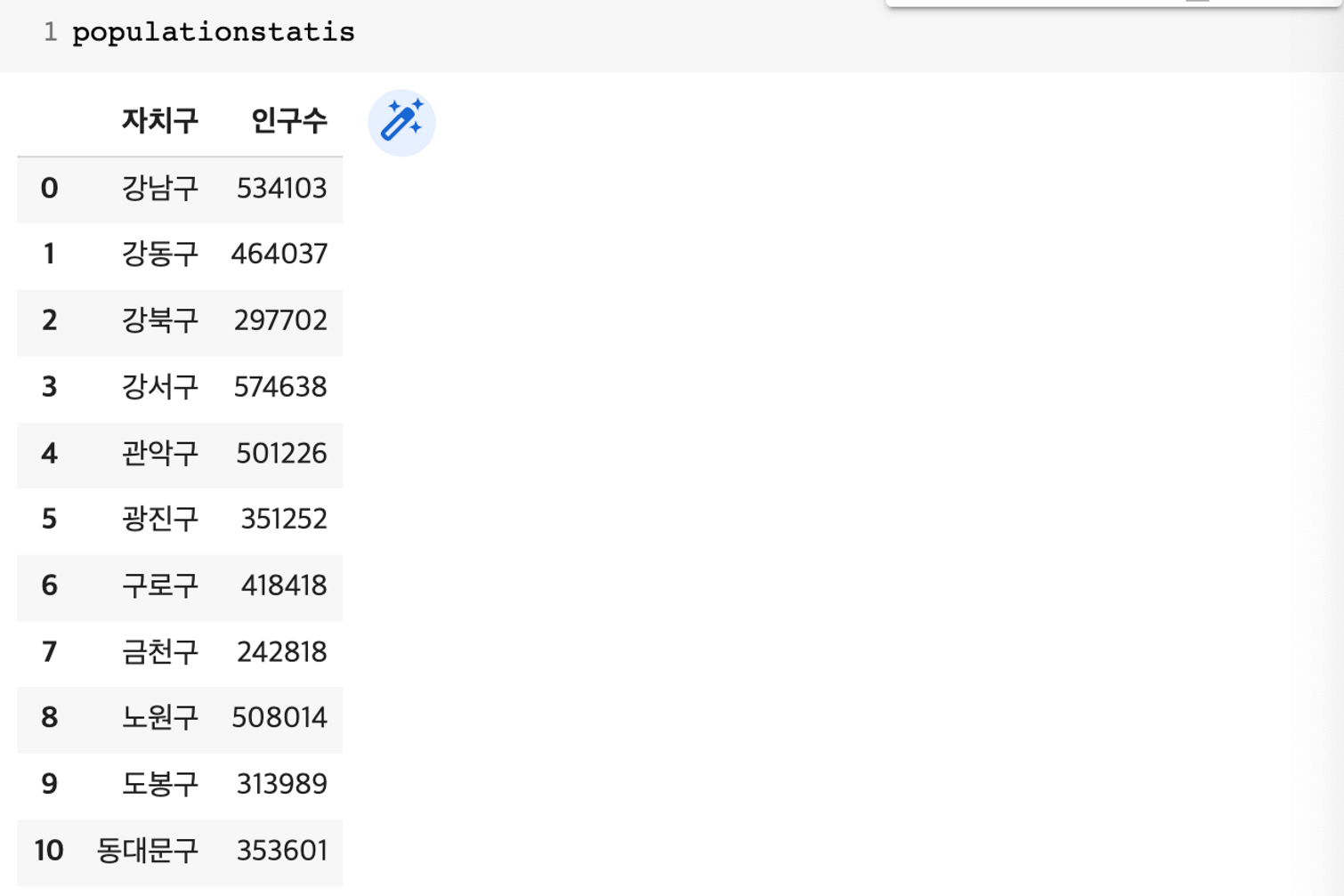
3. 데이터 분석
- 5월 일별 승하차 정보에서 5월 총 승하차 정보 계산
subwaystatis=mysubwaymonth.groupby("역명")['승차수','하차수'].sum()
- 자치구별 지하철역에서 각 지하철역의 승차수, 하차수를 각각 더하고 합계 리스트를 새로운 칼럼으로 추가
in_sum_list = [] # 총 승차수 리스트
out_sum_list = [] # 총 하차수 리스트
for i in range(len(mysubway)):
in_sum = 0
out_sum = 0
stations=list(mysubway.loc[i]['역명'].split(', '))
for s in stations: # 자치구별 각 지하철역마다
# 5월 총 승하차 정보 테이블에서 일치하는 역명의 승하차수를 더함
in_sum += subwaystatis.loc[subwaystatis.index == s]['승차수'].values.astype(int)
out_sum += subwaystatis.loc[subwaystatis.index == s]['하차수'].values.astype(int)
# 리스트에 값 추가
in_sum_list.extend(in_sum.astype(int))
out_sum_list.extend(out_sum.astype(int))
# 새로운 컬럼으로 추가
mysubway['총승차수'] = in_sum_list
mysubway['총하차수'] = out_sum_list
mysubway['합계'] = mysubway['총승차수'] + mysubway['총하차수']
- 지하철 역별 승차수 내림차순정렬 후 10개 추출
statisbar = subwaystatis.sort_values('승차수', ascending=False).head(10)
- 지하철 역별 하차수 내림차순정렬 후 10개 추출
statisbar2 = subwaystatis.sort_values('하차수', ascending=False).head(10)
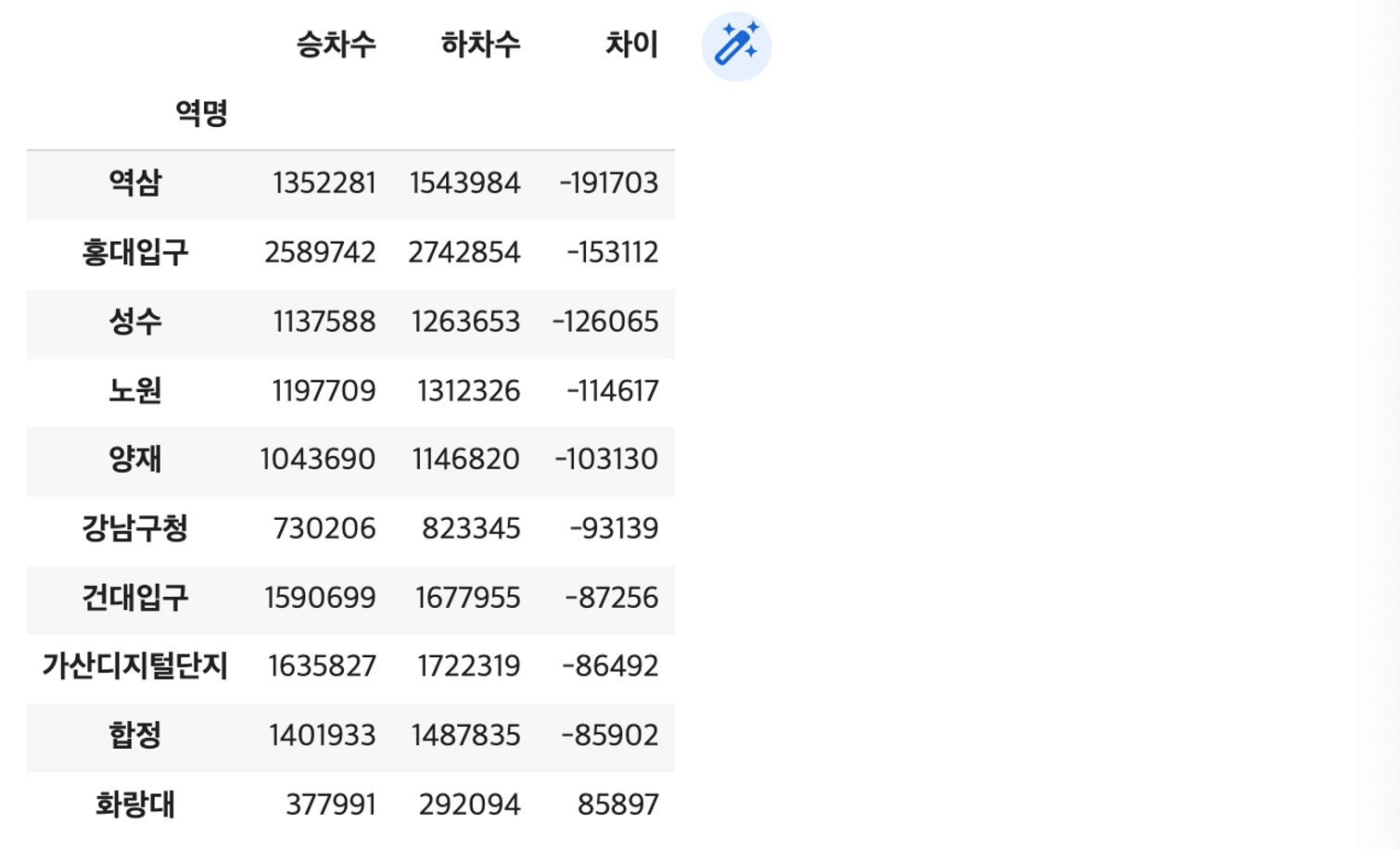
- 지하철 역별 승차수 - 하차수 테이블 만들고 절댓값으로 내림차순정렬 후 10개 추출
subwaystatis['차이']=subwaystatis['승차수']-subwaystatis['하차수']
statisbar3 = subwaystatis.sort_values('차이', key=abs, ascending=False).head(10)
- 2023년 자치구별 인구수 내림차순으로 정렬하고 10개 추출
populationbar = populationstatis.sort_values('인구수', ascending=False).head(10)
4. 데이터 시각화
- 2023 5월 지하철 역별 승차수 TOP 10
xlist = statisbar.index.values.tolist()
ylist = statisbar['승차수'].values.tolist()
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(10,10))
plt.bar(xlist, ylist, width=0.7)
plt.xticks([xlist],rotation=45 )
plt.axis([-0.5, 9.5, 1000000, 3000000])
plt.xlabel('역명')
plt.ylabel('승차수')
plt.title('2023 5월 지하철 역별 승차수 TOP 10')
plt.show()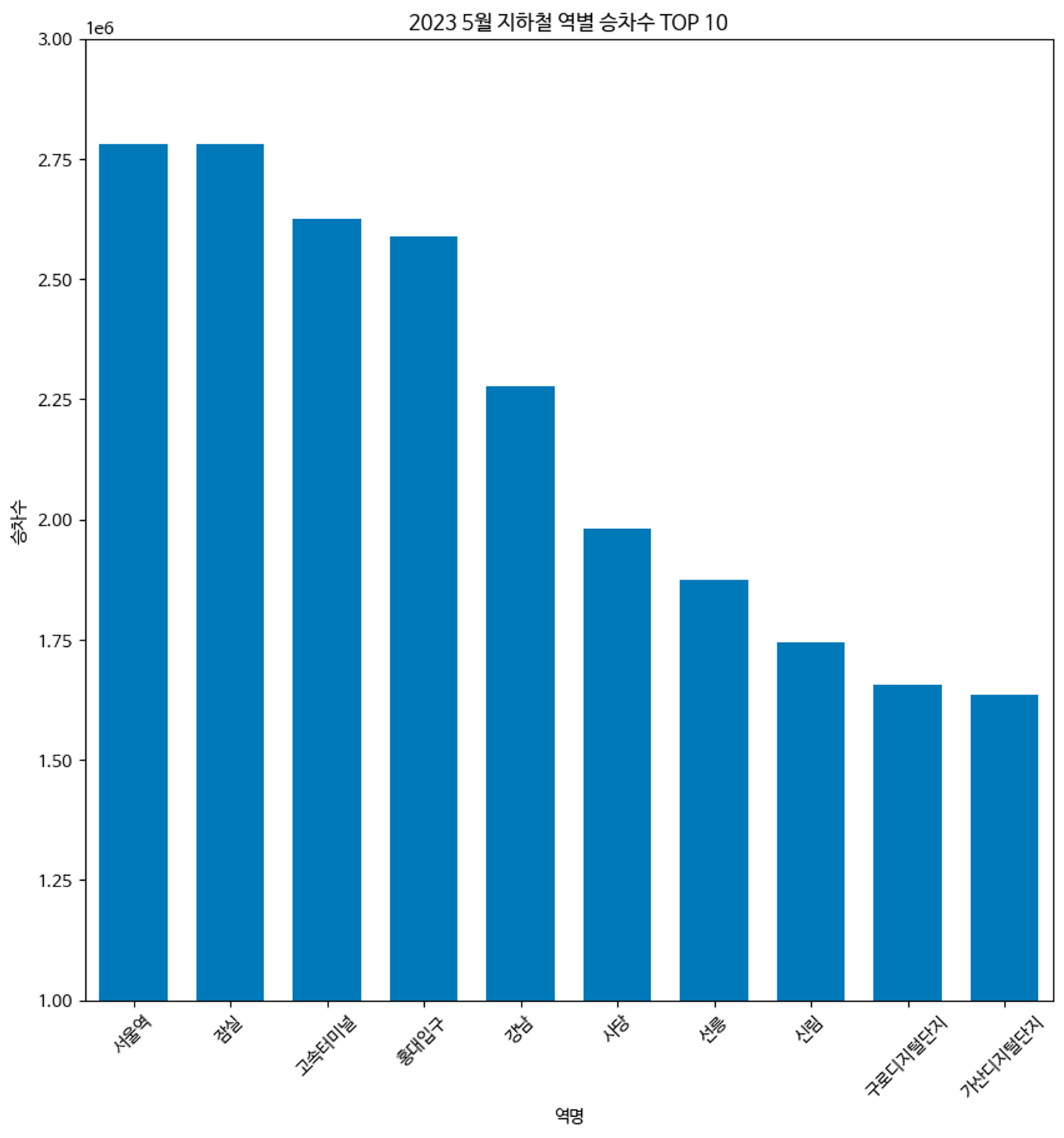
- 2023 5월 지하철 역별 하차수 TOP 10
xlist2 = statisbar2.index.values.tolist()
ylist2 = statisbar2['하차수'].values.tolist()
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(10,10))
plt.bar(xlist2, ylist2, width=0.7)
plt.xticks(xlist2,rotation=45 )
plt.axis([-0.5, 9.5, 1000000, 3000000])
plt.xlabel('역명')
plt.ylabel('하차수')
plt.title('2023 5월 지하철 역별 하차수 TOP 10')
plt.show()
- 지하철 역별 승차수-하차수 차이
xlist3 = statisbar3.index.values.tolist()
ylist3 = statisbar3['차이'].values.tolist()
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(10,10))
plt.bar(xlist3, ylist3, width=0.7)
# y=0 기준선
plt.axhline(0.0, 0.0, 1.0, color='gray', linestyle='solid', linewidth=3)
plt.xticks(xlist3,rotation=45 )
plt.xlabel('역명')
plt.ylabel('승차수-하차수')
plt.title('2023 5월 지하철 승차수-하차수 차이 TOP 10')
plt.show()
- 자치구별 지하철 승하차수와 스타벅스 매장 수
xlist4 = mysubway['자치구'].values.tolist()
xlist5 = list(range(25))
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(20,10))
plt.plot(in_sum_list, color='skyblue', label='승차수')
plt.plot(out_sum_list, color='orange', label='하차수')
plt.plot(starbuckscount, color='red', label='스타벅스수')
plt.xticks(xlist5, xlist4,rotation=45)
plt.xlabel('자치구')
plt.ylabel('인구수')
plt.title('2023 5월 자치구별 지하철 승하차수와 스타벅스 매장 수')
plt.show()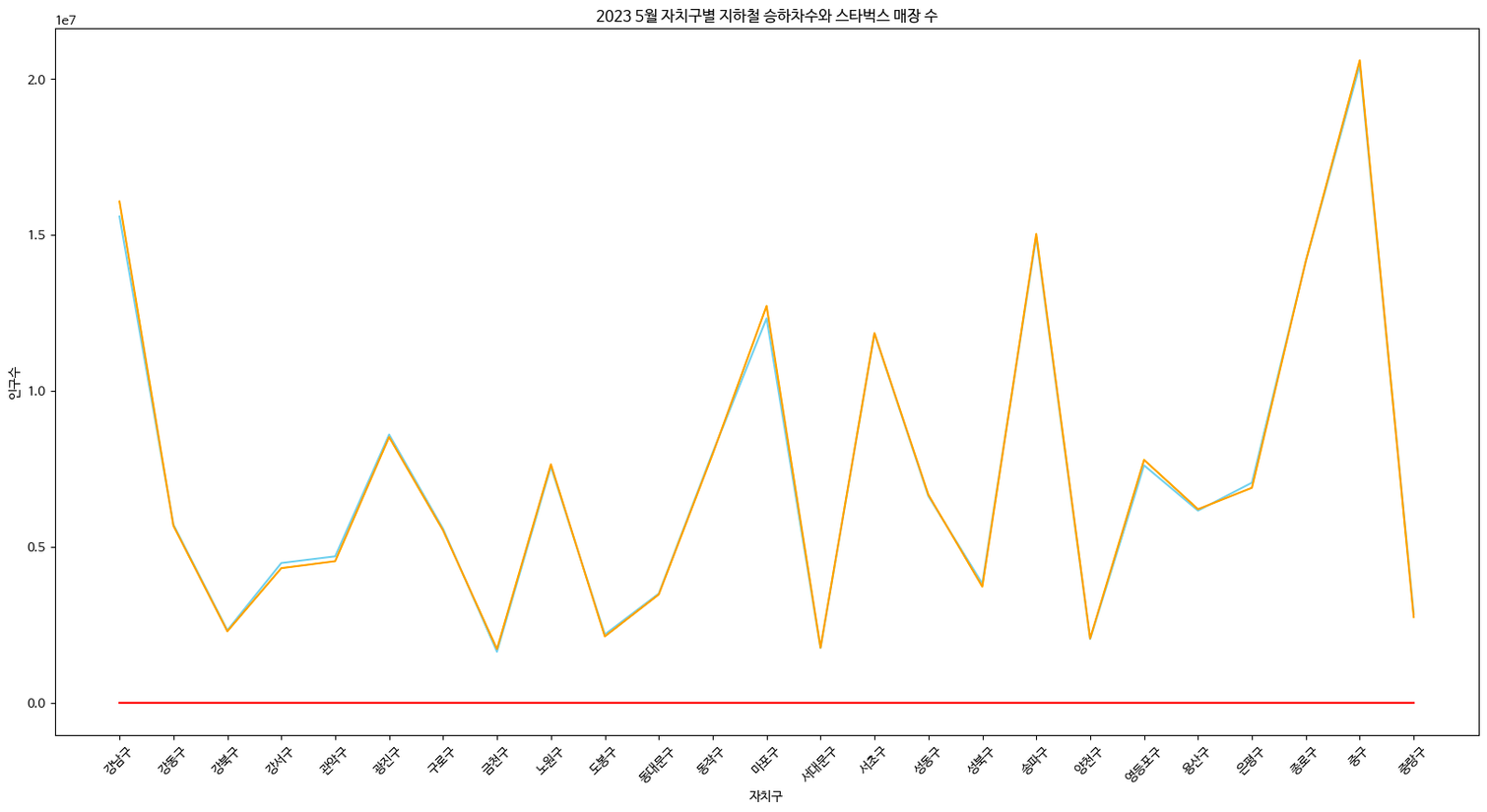
→단위 차이로 원하는 그래프가 만들어지지 않음
-
승하차수를 특정값으로 나누거나 스타벅스 매장수에 특정값을 곱해서 원하는 단위로 만드는방법 - 데이터가 변질될 우려
-
이중축 그래프!!
-
이중축 그래프 그리기
## 이중축 그래프 그리기
xlist4 = mysubway['자치구'].values.tolist()
xlist5 = list(range(25))
# left side
fig, ax1 = plt.subplots(figsize=(20,10))
ax1.set_title('2023 5월 자치구별 지하철 승하차수와 스타벅스 매장 수')
ax1.set_ylabel('5월 지하철 승하차수', color='tab:blue')
ax1.plot(xlist5, in_sum_list, marker='s', color='tab:blue', label='지하철 승차수')
ax1.plot(xlist5, out_sum_list, marker='s', color="orange", label='지하철 하차수')
ax1.tick_params(axis='y', labelcolor='tab:blue')
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
ax2.set_ylabel('스타벅스 매장 수', color='tab:red')
ax2.plot(xlist5, starbuckscount, marker='o', color='tab:red', label='스타벅스 매장 수')
ax2.tick_params(axis='y', labelcolor='tab:red')
plt.xticks(xlist5, xlist4, rotation=45)
ax2.grid(axis='y')
ax1.grid(axis='x')
ax1.legend(loc='lower left')
ax2.legend(loc='lower right')
fig.tight_layout()
plt.show()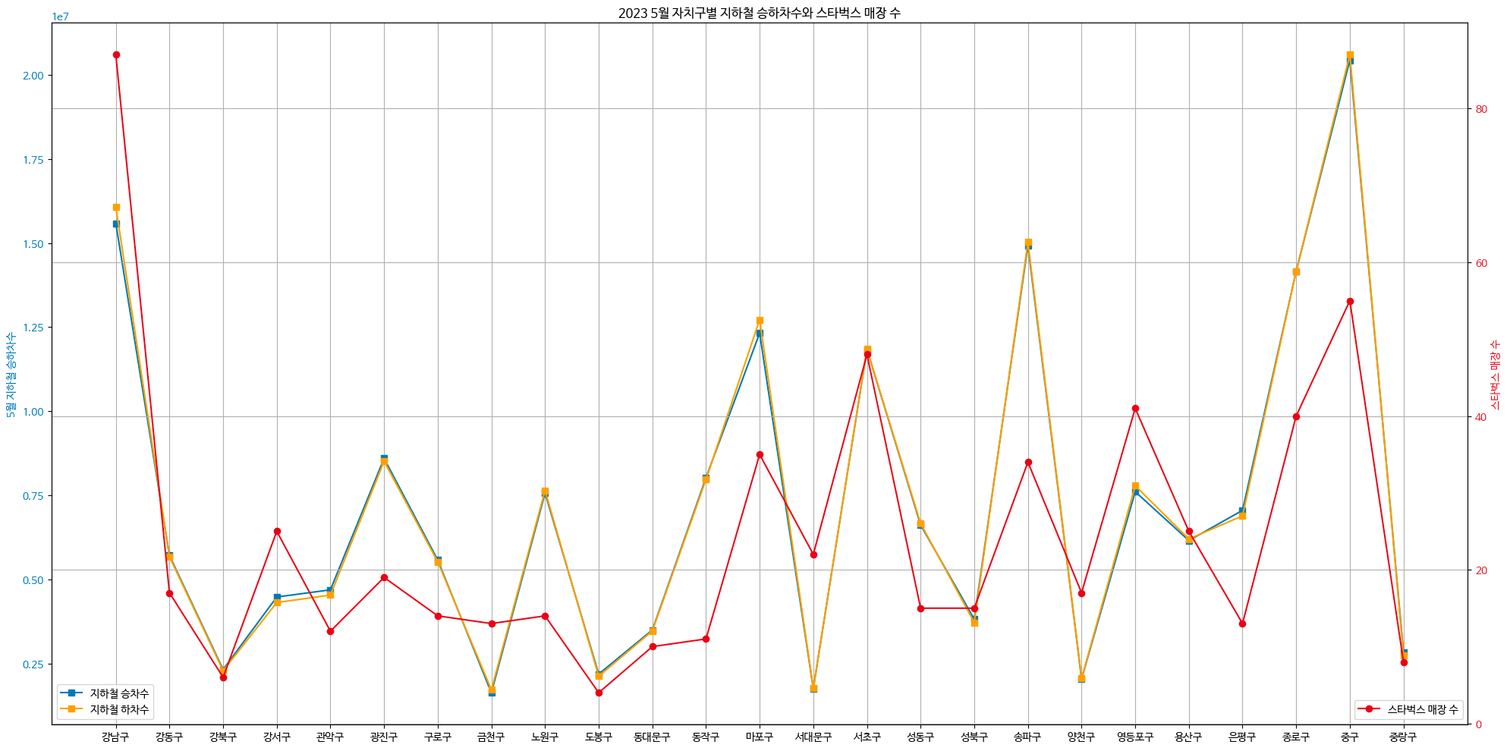
- 승하차수 합계와 스타벅스 매장 수 그래프
## 이중축 그래프 그리기
xlist4 = mysubway['자치구'].values.tolist()
ylist4 = mysubway['합계'].values.tolist()
xlist5 = list(range(25))
# left side
fig, ax1 = plt.subplots(figsize=(20,10))
ax1.set_title('2023 5월 자치구별 지하철 승하차수와 스타벅스 매장 수')
ax1.set_ylabel('5월 지하철 승하차수', color='tab:blue')
ax1.plot(xlist5, ylist4, marker='s', color='tab:blue', label='지하철 승하차수')
ax1.tick_params(axis='y', labelcolor='tab:blue')
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
ax2.set_ylabel('스타벅스 매장 수', color='tab:red')
ax2.plot(xlist5, starbuckscount, marker='o', color='tab:red', label='스타벅스 매장 수')
ax2.tick_params(axis='y', labelcolor='tab:red')
plt.xticks(xlist5, xlist4, rotation=45)
ax2.grid(axis='y')
ax1.grid(axis='x')
ax1.legend(loc='lower left')
ax2.legend(loc='lower right')
fig.tight_layout()
plt.show()
- 2023 자치구별 인구수 TOP 10
xlistp = populationbar['자치구'].values.tolist()
ylistp = populationbar['인구수'].values.tolist()
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(10,10))
plt.bar(xlistp, ylistp, width=0.7)
plt.xticks(xlistp,rotation=45 )
plt.axis([-0.5, 9.5, 300000, 700000]) # x좌표 0부터 5, y좌표 0부터 10까지
plt.ylabel('인구수')
plt.title('2023 자치구별 인구수 TOP 10')
plt.show()
- 2023 자치구별 인구수와 스타벅스 매장 수
## 이중축 그래프 그리기
ylistp = populationstatis['인구수'].values.tolist()
# left side
fig, ax1 = plt.subplots(figsize=(20,10))
ax1.set_title('2023년 자치구별 인구수와 스타벅스 매장 수')
ax1.set_ylabel('2023년 인구수', color='tab:blue')
ax1.plot(xlist5, ylistp, marker='s', color='tab:blue', label='인구수')
ax1.tick_params(axis='y', labelcolor='tab:blue')
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
ax2.set_ylabel('스타벅스 매장 수', color='tab:red')
ax2.plot(xlist5, starbuckscount, marker='o', color='tab:red', label='스타벅스 매장 수')
ax2.tick_params(axis='y', labelcolor='tab:red')
plt.xticks(xlist5, xlist4, rotation=45)
ax2.grid(axis='y')
ax1.grid(axis='x')
ax1.legend(loc='lower left')
ax2.legend(loc='lower right')
fig.tight_layout()
plt.show()
- 2023 자치구별 인구수와 지하철 승하차수
## 이중축 그래프 그리기
# left side
fig, ax1 = plt.subplots(figsize=(20,10))
ax1.set_title('2023년 자치구별 인구수와 지하철 승하차수')
ax1.set_ylabel('2023년 인구수', color='tab:blue')
ax1.plot(xlist5, ylistp, marker='s', color='tab:blue', label='인구수')
ax1.tick_params(axis='y', labelcolor='tab:blue')
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
ax2.set_ylabel('지하철 승하차수', color='tab:red')
ax2.plot(xlist5, ylist4, marker='o', color='tab:red', label='지하철 승하차수')
ax2.tick_params(axis='y', labelcolor='tab:red')
plt.xticks(xlist5, xlist4, rotation=45)
ax2.grid(axis='y')
ax1.grid(axis='x')
ax1.legend(loc='lower left')
ax2.legend(loc='lower right')
fig.tight_layout()
plt.show()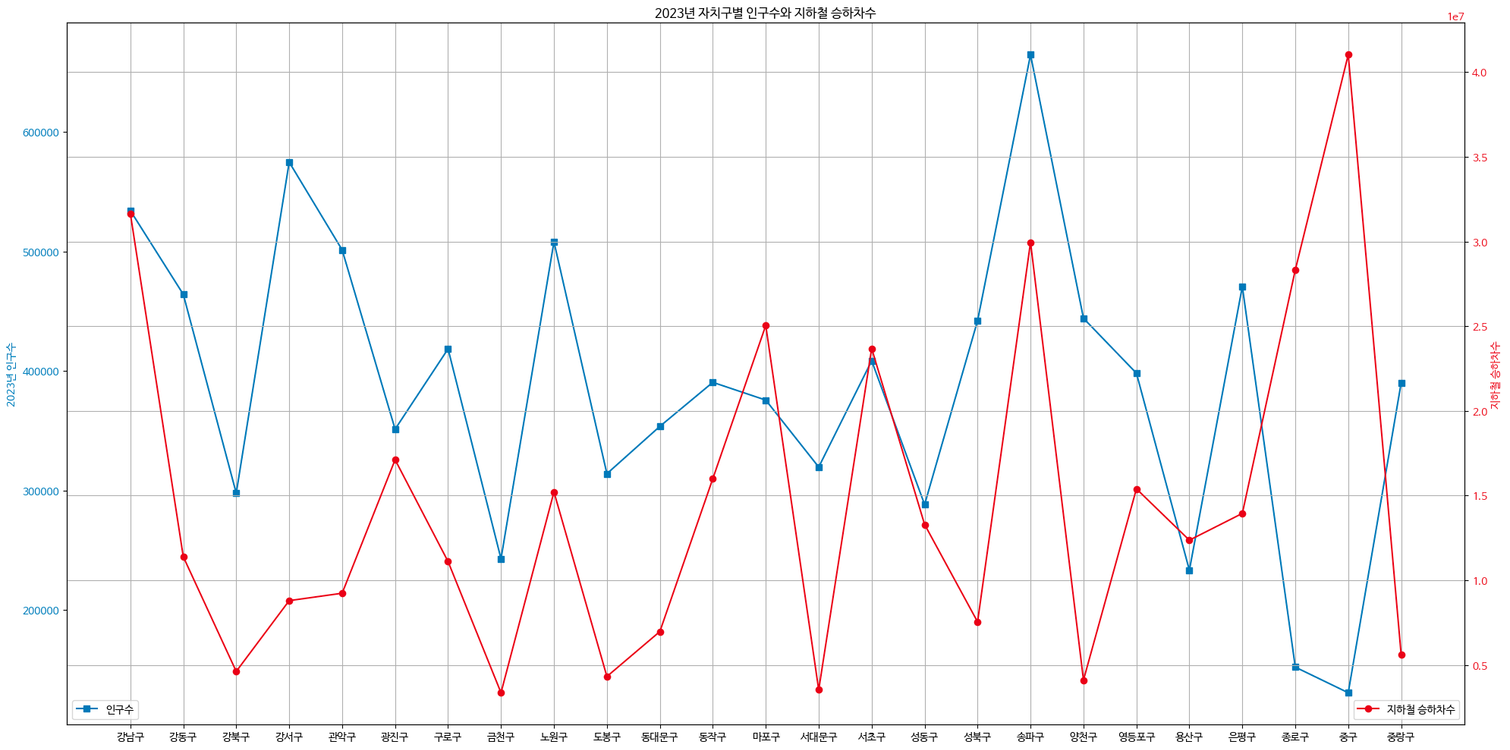
- 지역구별 승하차수 TOP 10을 구하고 지도에 표시
import folium
mysubwaystatis = subwaystatis.sort_values('합계', ascending=False).head(10)
# 지하철역의 위도,경도를 구해서 리스트에 저장
x_location=[37.513,37.554,37.556,37.505,37.498,37.476,37.504,37.484,37.480, 37.485]
y_location=[127.101,126.971,126.925,127.004, 127.028,126.981,127.049,126.930,126.883,126.901]
# 지하철역 이름 저장
subway_name=mysubwaystatis.index.values.tolist()
# 승하차수의 앞자리 수 2개로 원의 크기 결정
subway_area=[56, 55, 53, 52, 44, 39, 37, 34, 33, 32]
for i in range(10):
subway_area[i] = round((subway_area[i]/5) ** 3)
# 지도 만들기
m=folium.Map(
location=[37.554, 126.971],
zoom_start=12
)
colors = ['red', 'pink', 'orange', 'yellow', 'purple', 'green', 'blue','brown','indigo','violet']
# 원 마크
# 마우스를 위에 올리면 역 이름이, 클릭하면 순위가 뜬다
for i in range(10):
folium.Circle(
[x_location[i], y_location[i]],
radius=subway_area[i],
color='black',
fill_color=colors[i],
tooltip=subway_name[i],
popup=i+1
).add_to(m)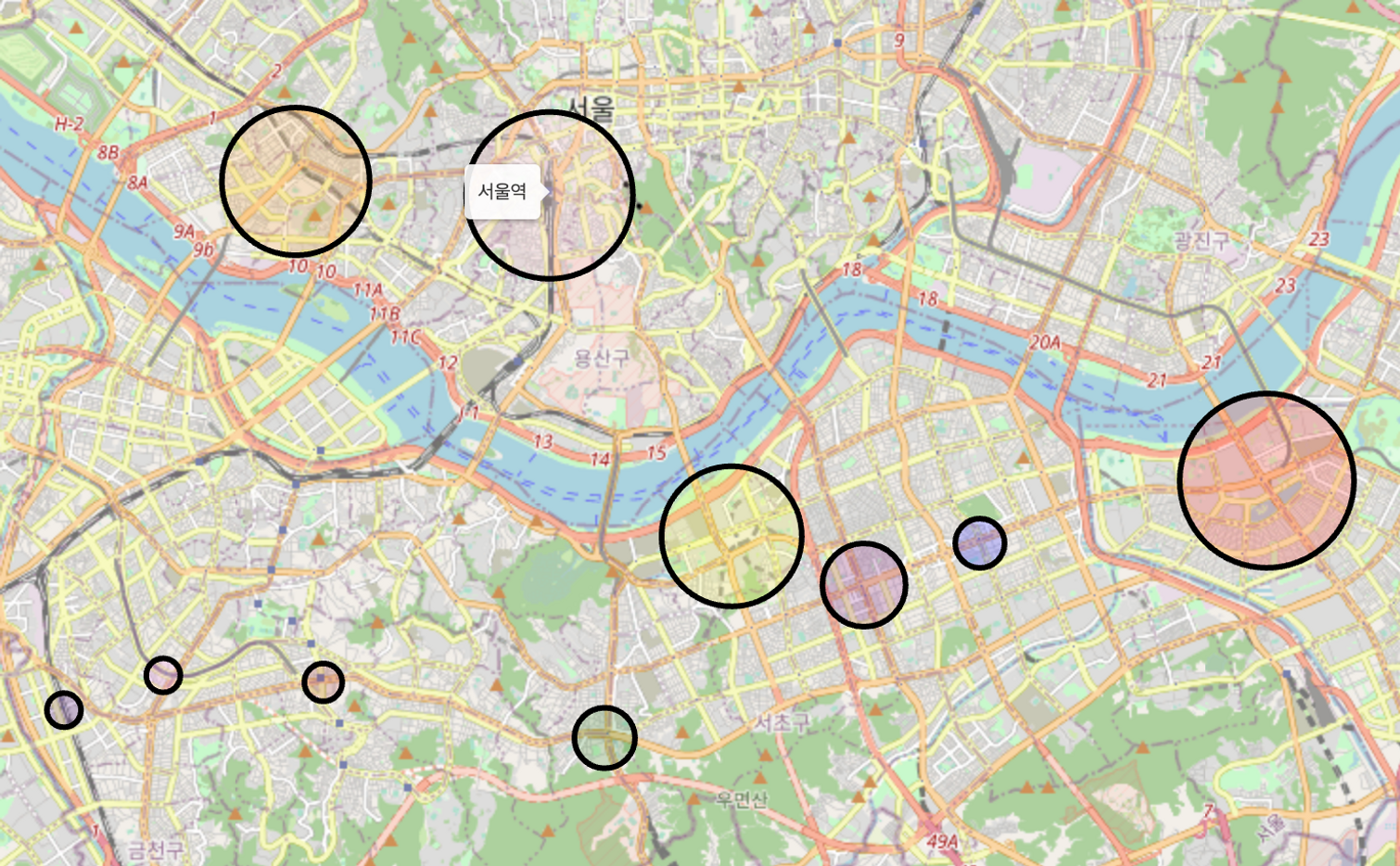
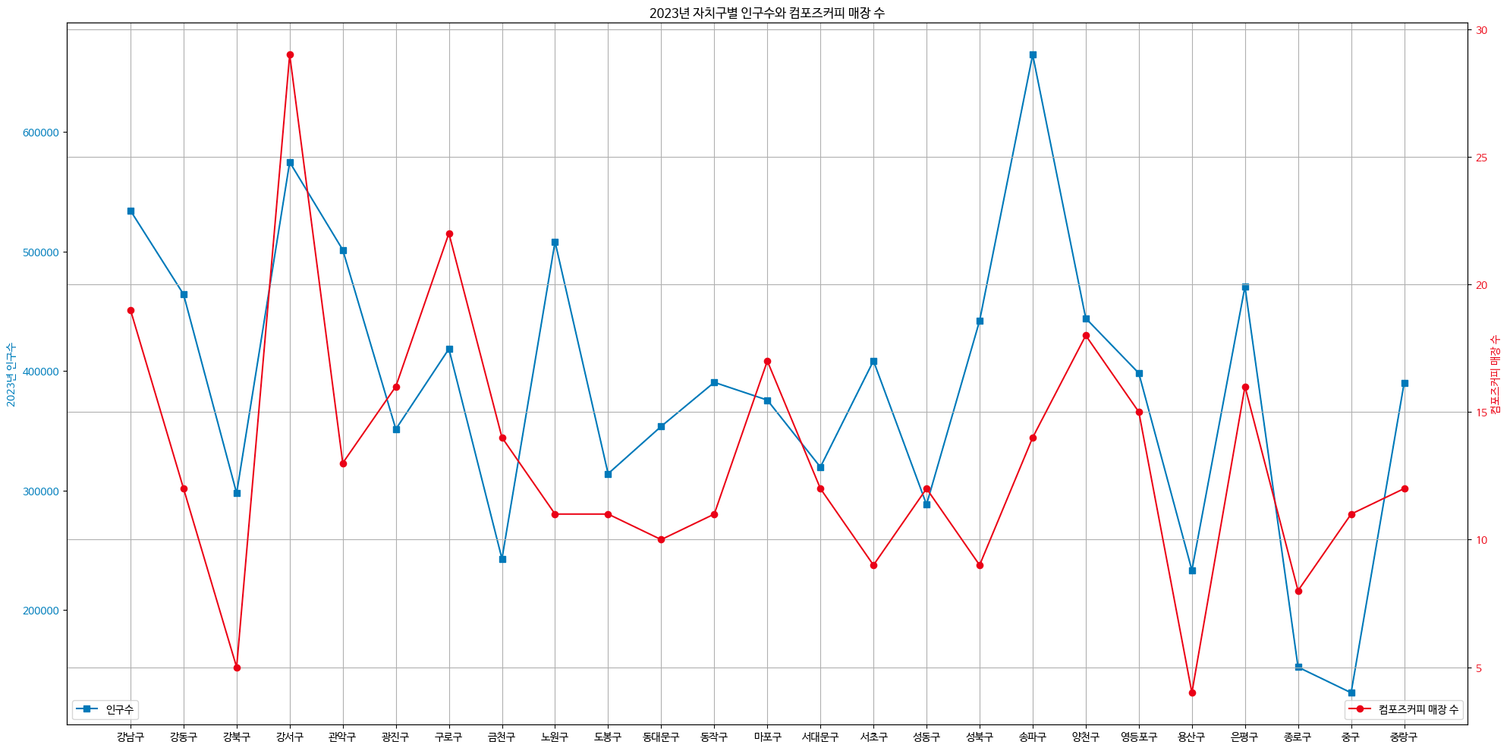
- 2023 자치구별 인구수와 컴포즈커피 매장수
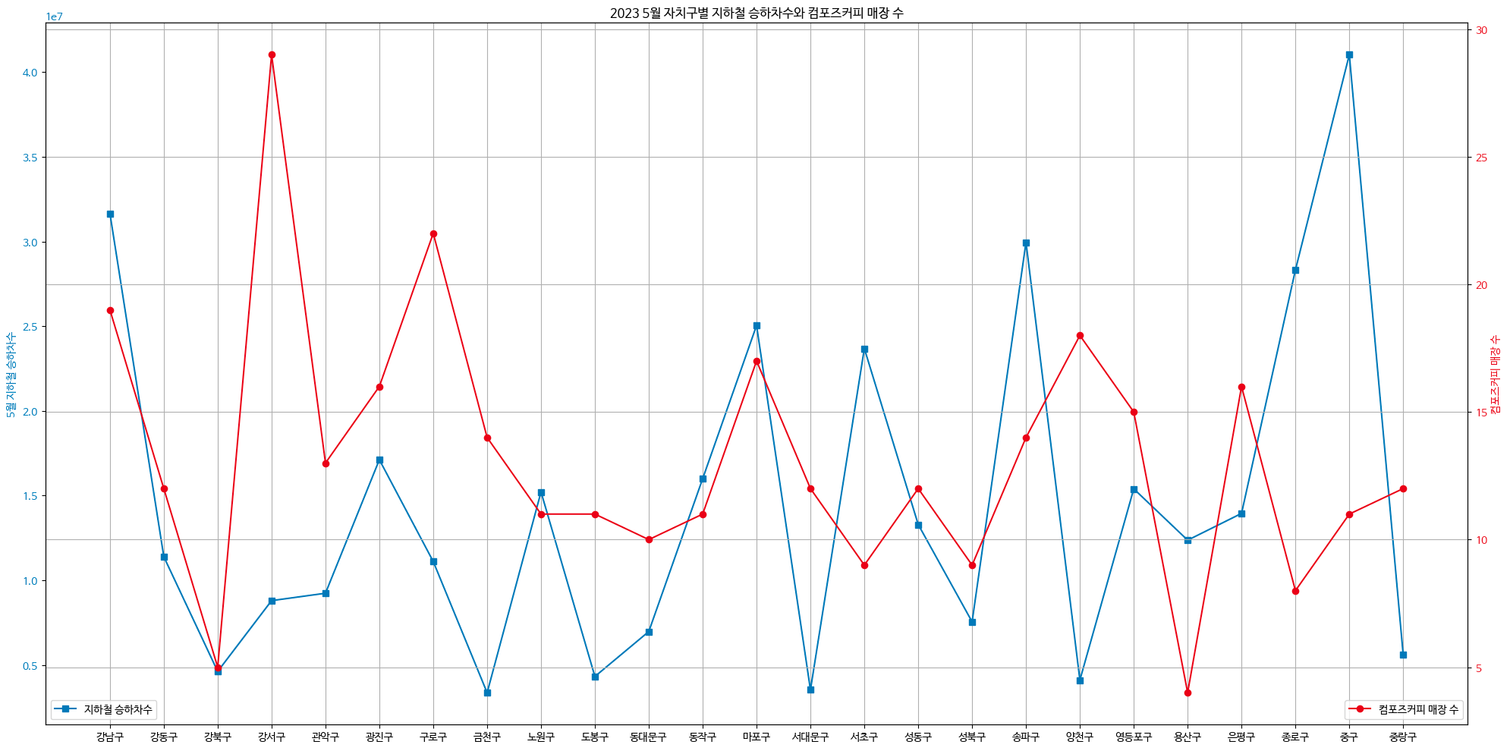
- 2023 5월 지하철 승하차수와 컴포즈커피 매장수
5. 결론
- 지하철 승차수와 하차수는 거의 유사하다
- 스타벅스 매장수 와 지하철 승하차수는 연관이 있다
- 스타벅스의 매장수는 인구수보다 지하철 승하차수와 더 연관이 있다
- 지하철 승하차수와 인구수는 차이가 있다
- 컴포즈커피의 매장수는 지하철 승하차수보다 인구수와 더 연관이 있다
- 내가 만약 창업을 한다면
- 지하철 승하차수는 많은데 매장수는 적은 중구에 스타벅스
- 인구수는 많은데 매장수는 적은 송파구에 컴포즈커피
