
scraping(스크래핑)
특정 사이트를 스크래핑을 한다 => 특정 사이트의 한 페이지를 쭉 긁어와 1번 가져오는 것
- 라이브러리 : Chreerio
crawling(크롤링)
크롤링을 한다 => 특정 사이트에서 돌아다니며 버튼을 클릭해 여러 페이지를 가지고 오는 것
(여러번의 스크래핑을 한 것이 크롤링)보통 Puppeteer로 가져온 데이터를 파싱할 때 cheerio를 많이 사용한다.
- 라이브러리: Puppeteer
크롤링시 주의점❗️
- 크롤링 해온 데이터를 상업목적으로 사용시 소송대상이 될 수 있다.
- 너무 많은 접속으로 해당 회사 서버에 부하를 주게 될 경우,
공격으로 판단되기 때문에 주의해야 한다.
HTTP 응답 결과
페이지 그려줄때 Network에서 문서를 받아오는 순서
- HTML 문서를 받아오기
- HTML문서를 읽으며 <Link/ > 태그 같은데에 바인딩 된 CSS 파일과 JS파일을 가지고 온다.
- 받아온 HTML 문서를 Network를 통해 확인해보면, response와 Header가 있음을 확인할 수 있다.
즉, 주소창에 주소를 입력 후 문서들을 받아오는 과정이 Http통신이라는 뜻!
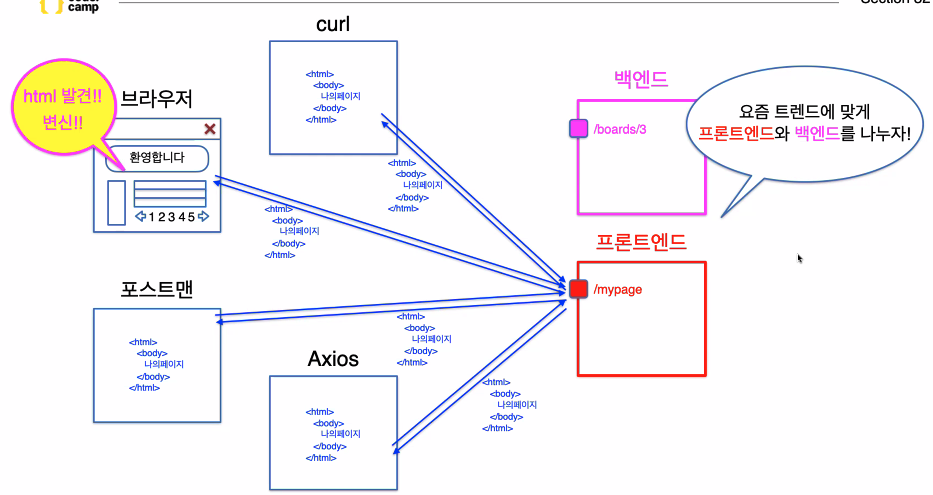
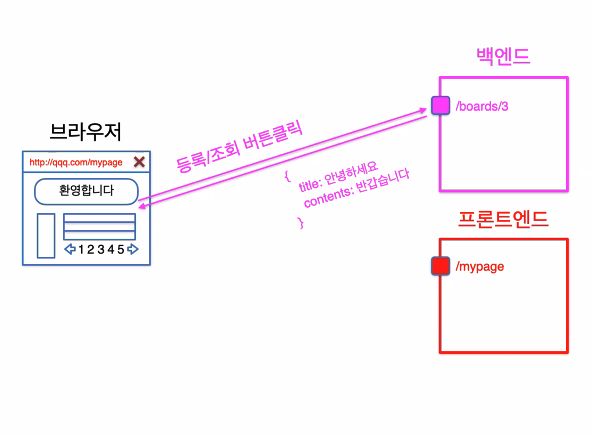
주소창에 입력된 페이지에 대한 요청은 프론트엔드 서버에서 처리하게 된다.
그럼 프론트서버에서는 요청에 대한 응답 결과물로 html을 반환하게 되고,
해당 결과물이 우리가 Network에서 보는 html인 것.주소창에 입력된 페이지에서 다른 api요청을 보낼때는 백엔드 서버에서 처리하게 된다.
백엔드 서버에서는 다양한 응답 결과물을 반환할 수 있는데, 응답 결과물로 html,json,xml을 반환할 수 있다.브라우저의 주소창 또한 http요청의 도구인 것!
백엔드에서 받아온 결과값들을 브라우저가 해석해 화면에 그려준다.
크롬개발자의 역할 -> 화면에 그려줌
▼ 현대 웹서비스 동작원리

JUST DO WHATEVER