TABLE(테이블)
: 실제 데이터(레코드)를 담을 수 있는 대상
DROP TABLE ( 테이블 삭제 )
↓ 스키마 ↓ 테이블 이름
DROP TABLE `study1`.`table1`;SHOW TABLES IN ( 테이블 조회 )
↓ 스키마
SHOW TABLES IN `study1`;DESC ( 테이블 정보 조회 )
↓ 스키마 ↓ 테이블 이름
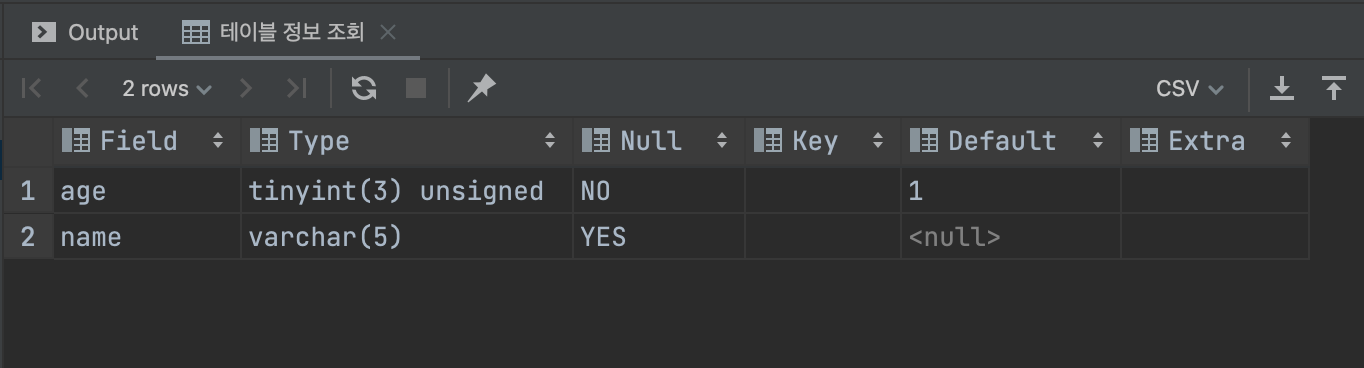
DESC `study1`.`table1`;< 테이블 정보 조회 결과 >
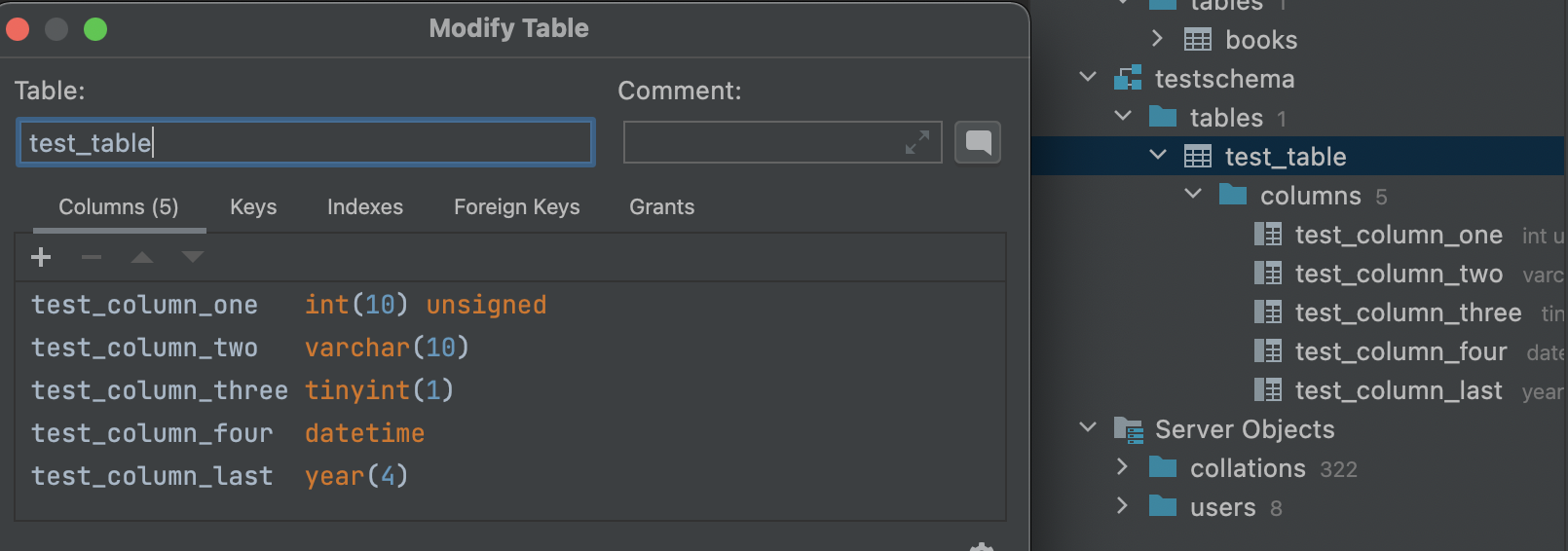
테이블 수정
테이블에 존재하는열을 삭제하거나 타입을 바꿀 때,
또는 존재하지 않는 열을 추가할 때 사용한다.
ADD COLUMN ( 열 추가 )
↓ 열 이름 ↓ 열 타입
ALTER TABLE `study1`.`table1` ADD COLUMN `contact` VARCHAR(11) NOT NULL;- AFTER
: ~ 뒤에 추가
ALTER TABLE `study1`.`table1` ADD COLUMN `email` VARCHAR(11) NOT NULL AFTER `contact`;
- contact 뒤에 email이 추가 된 것을 확인 할 수 있다.

- FIRST
: 제일 앞에 추가
ALTER TABLE `study1`.`table1` ADD COLUMN `index` INT UNSIGNED NOT NULL FIRST ;
- 맨 앞에 index가 추가 되었다.

DROP COLUMN ( 열 삭제 )
↓ 열 이름
ALTER TABLE `study1`.`table1` DROP COLUMN `contact`;MODIFY COLUMN ( 열 수정 )
↓ 열 이름
ALTER TABLE `study1`.`table1` MODIFY COLUMN `contact` VARCHAR(13) NOT NULL; ex >
만약 연락처를 입력받는데 '-'가 필요없을 줄(11자) 알았는데 필요해졌을 때(13자) 수정 사용.
ALTER TABLE `testschema`.`test_table` RENAME COLUMN `test_column_five` TO `test_column_last`;- 열 이름 수정
- 실제로 이렇게 적어서 사용을 많이 하지 않는다. 아래의 방법도 있기 때문이다.
- 클릭하고 cmd + F6
Record ( 레코드 )
: 데이터의 종류와 목적을 제한하고 테이블의 구조를 정의할수 있는 대상
INSERT ( 삽입 )
INSERT INTO `<스키마>`.`<테이블>` (`<열>`,...) VALUES (<값>,...),...;↓ 스키마 ↓ 테이블 ↓ 열(insert할) INSERT INTO `study1`.`table1` (`age`,`name`,`contact`,`email`) VALUES (20, '김김김', '010-0000-0000','a@a.a')
- VALUES 값은 테이블 열 순서랑 관계없이 명시한 열의 순서대로 기입
- NOT NULL이면서 AUTO_INCREMENT 속성 및 DEFAULT 속성이 없는 열은 반드시 명시해야한다.
INSERT INTO `study1`.`table1` (`age`,`index`,`contact`,`email`) VALUES (20, 1, '010-0000-0000','a@a.a');
- name을 빼고 명시를 했더니 name에 null이 들어가게 된다.

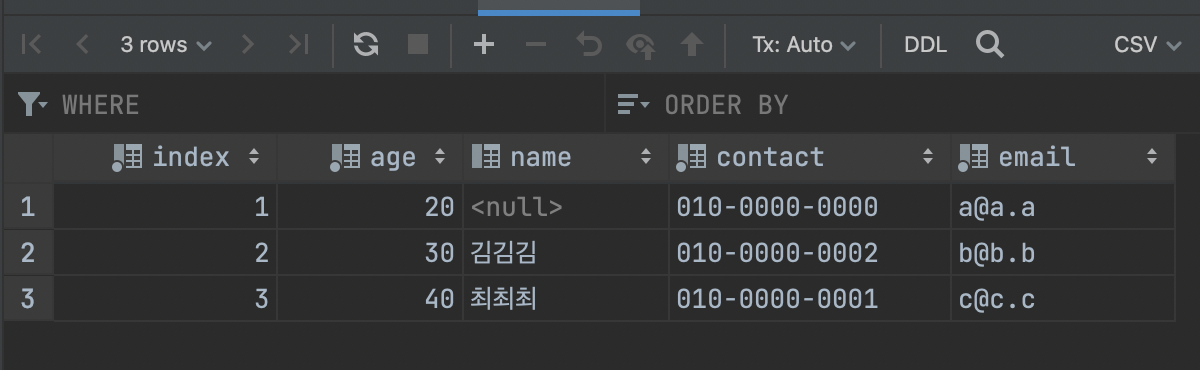
INSERT INTO `study1`.`table1` (`index`,`age`, `name`,`contact`,`email`) VALUES (2, 30, '김김김', '010-0000-0002','b@b.b'), (3, 40, '최최최', '010-0000-0001','c@c.c');
- 한번의 INSERT문으로 여러 레코드를 삽입할 수 있다.
DELETE ( 삭제 )
DELETE FROM `<스키마>`.`<테이블>` WHERE `<조건>` = 1;이렇게 해서는 삭제되지 않는다. safe모드이기 때문에 적용이 되지 않고 조건을 걸어줘야 가능하다.
UPDATE ( 수정 )
UPDATE `study1`.`table1` SET `<변경할 열>` = <변경할 값> WHERE <조건>;
- 하나의 열만 수정
UPDATE `study1`.`table1` SET `<변경할 열>` = <변경할 값> , `<변경할 열>` = <변경할 값> WHERE <조건>;
- 여러 개의 열 한꺼번에 수정
SELECT ( 조회 )
SELECT `<열>`,... FROM `<스키마>`.`<테이블>` <기타>;
- 이때 테이블의 전체 열을 조회하려면 키워드를 이용한다. (SELECT FROM ... )
LIMIT x ( 제한 )
: 조회되는 레코드의 개수를 x개로 제한한다.
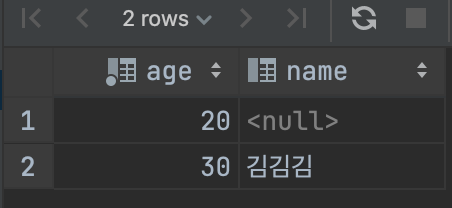
SELECT `age`,`name` FROM `study1`.`table1` LIMIT 2;
ORDER BY
: <열> ASC|DESC : <열> 기준으로 정렬한다.
- ASC : 오름차순, DESC : 내림차순
SELECT `age`,`name` FROM `study1`.`table1` ORDER BY `age` DESC LIMIT 2;=> 나이가 많은차순으로 정렬된다.
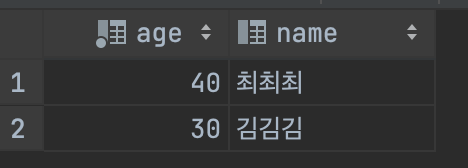
🙅♀️ORDER BY 와 LIMIT의 순서는 바뀌면 안된다.
WHERE
: SELECT문에 조건을 걸 수 있다.
SELECT `age`, `name` FROM `study1`.`table1` WHERE `age` >= 40 ORDER BY `age` DESC LIMIT 2;=> 나이가 40이상인 사람만 골라라
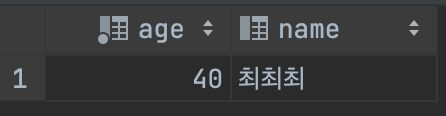
- x >= y : x가 y이상
- x <= y : x가 y이하
- x > y : x가 y초과
- x < y : x가 y미만
- x = y : x가 y랑 같음 (숫자, 문자 등 SQL은 == 사용하지 않는다)
- x <> y : x가 y랑 다름
- x IS NULL : x가 NULL임
- x IS NOT NULL : x가 NULL이 아님
- x AND y : x 및 y 조건 둘다 참(TRUE)이여야 참을 반환
- x OR y : x 및 y 조건 중 하나 이상이 참이면 참을 반환
- LIKE y : x가 y의 형태를 가진('모든'을 표시하기 위해 % 사용) 이때 y는 문자열 취급
null이랑 비교할 때는
`name`<> NULL이렇게 하면 안된다.
`name` IS NOT NULL이라고 작성해야한다.
SELECT `age`, `name` FROM `study1`.`table1` WHERE `name` IS NULL ORDER BY `age` DESC LIMIT 2;
=> name이 null인 레코드를 찾아라.
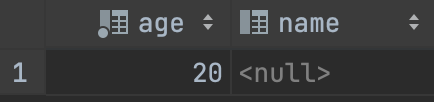
😎
보통 index 는 순번으로 들어가게 되고 보통 NOT NULL이며 기본키로 들어가게 된다.
CONSTRAINT ( 제약조건 )
지역번호와 지역명은 겹쳐서는 안된다.
이미 쓰고 있는 지역번호를 사용할 수 없다. 이름 또한 그렇다.
INSERT가 되지 못하게 해야한다. : 제약조건을 걸어야한다.
기본키 또한 제약조건이다.
예시를 통해 더 알아보도록 하자.
PRIMARY KEY ( 기본 키 )
:
CREATE TABLE내에서CONSTRAINT PRIMARY KEY (`<열 이름>`,...)
- PRIMARY KEY는 UNIQUE의 속성을 가진다.
UNIQUE ( 유니크 )
:
CREATE TABLE내에서CONSTRAINT UNIQUE (`<열 이름>,...`)
- 테이블 내에서 해당 컬럼 값은 항상 유일무일(중복값 허용안함)한 값, NULL 허용
CONSTRAINT UNIQUE (`code`,`name`)
이라고 써도 되긴한데 의미가 많이 달라진다. 즉, code와 name이 세트로UNIQUE여야INSERT하지 않겠다는 의미이다.
AUTO_INCREMENT 참고
마지막 번호에서 +1을 하는 것이 아니다.
INSERT 를 시도햇던 횟수를 TABLE이 기억하고 있다.
문제점 : 인덱스 값이 늘어나면 최댓값을 가져오는게 굉장히 느려지게 된다.
< example >
CREATE SCHEMA `region`;
CREATE TABLE `region`.`provinces`(
`index` TINYINT UNSIGNED NOT NULL AUTO_INCREMENT,
`code` VARCHAR(3) NOT NULL,
`name` VARCHAR(3) NOT NULL,
CONSTRAINT PRIMARY KEY (`index`),
CONSTRAINT UNIQUE (`code`),
CONSTRAINT UNIQUE (`name`),
);CONSTRAINT PRIMARY KEY (`index`) : index를 기본키로 사용할 것이다.
CONSTRAINT UNIQUE (`code`) : 중복이 되면 안된다.
다음시간에 계속...
