< 참고 >
DELETE FROM `school`.`temp` WHERE ? LIMIT 9;
- ' ? ' 조건에 해당하는 레코드를 삭제하는데 9개 이하만 삭제한다.
UPDATE `school`.`temp` SET ? = ? LIMIT 3;
- UPDATE 도 동일하다. 9와 3은 레코드 갯수 제한 이다.
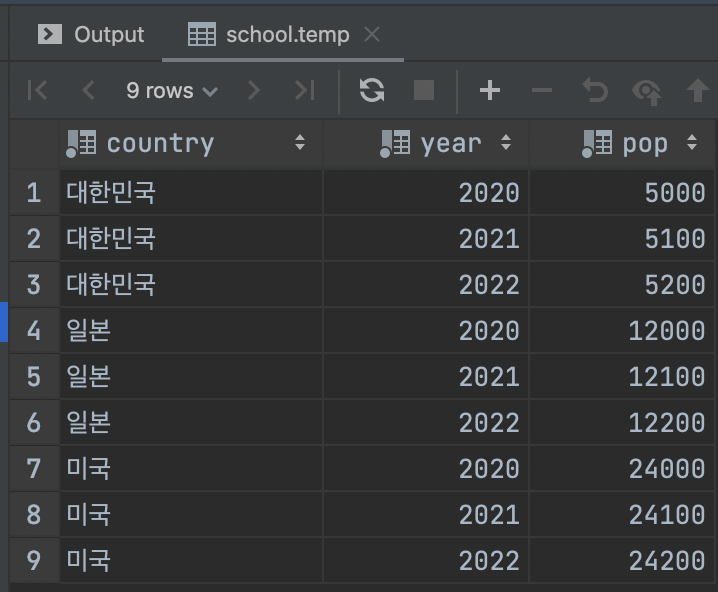
-> GROUP BY 예제를 위한 테이블 temp 추가
CREATE TABLE `school`.`temp` ( `country` VARCHAR(5) NOT NULL, `year` YEAR NOT NULL, `pop` INT UNSIGNED NOT NULL ); INSERT INTO `school`.`temp` (`country`,`year`,`pop`) VALUES ('대한민국', 2020, 5000), ('대한민국', 2021, 5100), ('대한민국', 2022, 5200), ('일본', 2020, 12000), ('일본', 2021, 12100), ('일본', 2022, 12200), ('미국', 2020, 24000), ('미국', 2021, 24100), ('미국', 2022, 24200);
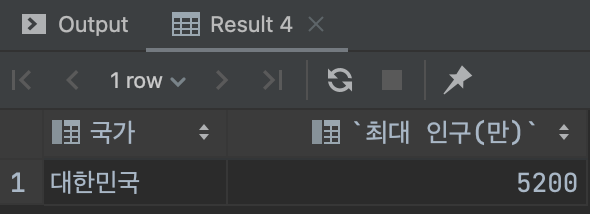
-> 대한민국의 역대 인구 SELECT (MAX)
SELECT `country` AS `국가`, MAX(`pop`) AS `최대 인구(만)` FROM `school`.`temp` WHERE `country` = '대한민국';
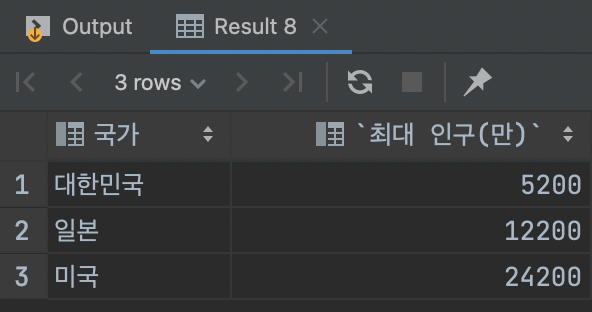
-> 각 국가의 역대인구를 뽑아라. (사진과 같이 SELECT 해보시오.)
SELECT `country` AS `국가`, MAX(`pop`) AS `최대 인구(만)` FROM `school`.`temp` WHERE `country` = '대한민국' UNION SELECT `country` AS `국가`, MAX(`pop`) AS `최대 인구(만)` FROM `school`.`temp` WHERE `country` = '일본' UNION SELECT `country` AS `국가`, MAX(`pop`) AS `최대 인구(만)` FROM `school`.`temp` WHERE `country` = '미국';
- UNION을 사용해서 결과를 만들어낼 수 있다.
- 그런데 중복되는 코드가 너무 많다.개발자는 중복되는 코드를 싫어해야한다. 그래서 사용하는게 GROUP BY 이다.
GROUP BY
: 무엇으로 묶어내겠다. 특정 컬럼을 그룹화한다.
- 통계나 최대값 최소값 구할 때 많이 사용한다.
- 유형별로 갯수를 알고 싶을 때는 컬럼에 데이터를 그룹화 할 수 있는 GROUP BY를 사용한다.
GROUP BY (그룹화 할 컬럼)
SELECT `country`, MAX(`pop`) FROM `school`.`temp` GROUP BY `country`;
- GROUP BY을 사용하면 중복된 코드를 다 적을 필요없다.
- country 로 묶어서 그 안에 것들끼리 중 최댓값을 뽑는다.
그 안에 것 : 대한민국, 일본, 미국
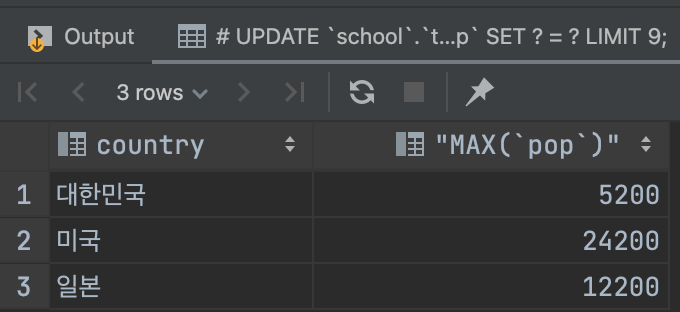
GROUP BY 할 때는 GROUP BY가 되는 열이랑
통계 대상이 되는 열만 SELECT 해야 유의미한 결과를 얻을 수 있다.
예시를 통해 이해해보자.
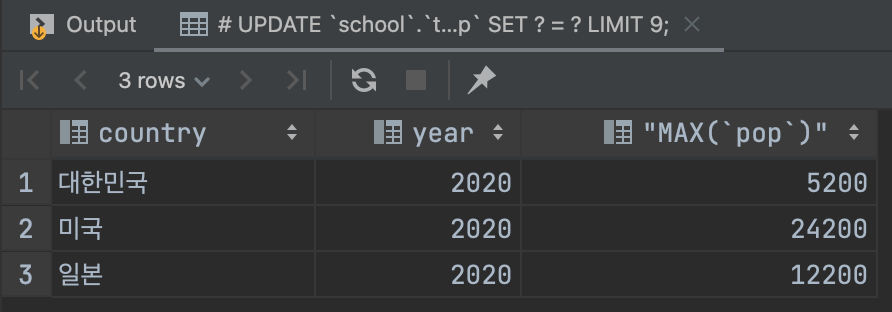
SELECT `country`, `year`, MAX(`pop`) FROM `school`.`temp` GROUP BY `country`;
year을 같이 SELECT 했을 때 2022년의 인구가 아닌 2020년의 인구가 의미 없이 도출되는 것을 확인 할 수 있다.
그렇다면, 각 국가의 역대인구를 뽑는데 연도도 같이 뽑고 싶다면?
SUBQUERY 를 사용하는데 예제가 좋지않아 하지는 않겠음.
DATEDIFF(a,b)
: a라는 일시에서 b라는 일시를 뺀 값이 나온다.
- 양수로 나오기 위해서 미래에서 과거를 빼야한다.
SELECT DATEDIFF('2020-01-01', '2020-01-02');

GROUP BY 예제
-> 학년, 반 으로 묶기
SELECT `test`.`name` AS `시험`, `score`.`execution_from` AS `실시 일자`, DATEDIFF(`execution_to`, `execution_from`) + 1 AS `실시 기간`, `score`.`student_grade` AS `학년`, `score`.`student_class` AS `반`, AVG(`score`) AS `평균`, `teacher`.`name` AS `담임` FROM `school`.`scores` AS `score` LEFT JOIN `school`.`tests` AS `test` ON `score`.`execution_test_code` = `test`.`code` AND `code` = 'MID' LEFT JOIN `school`.`teachers` AS `teacher` ON `score`.`student_grade` = `teacher`.`designated_grade` AND `score`.`student_class` = `teacher`.`designated_class` GROUP BY `score`.`student_grade`, `score`.`student_class`;
- DATEDIFF에 +1을 한 이유는 DATEDIFF 함수는 꽉찬 기간을 계산한다. 그래서 하루가 적게 나오게 된다.
- 보통 두 날짜 사이의 정확한 기간을 계산해야 할 경우, YEARFRAC 함수를 사용한다.

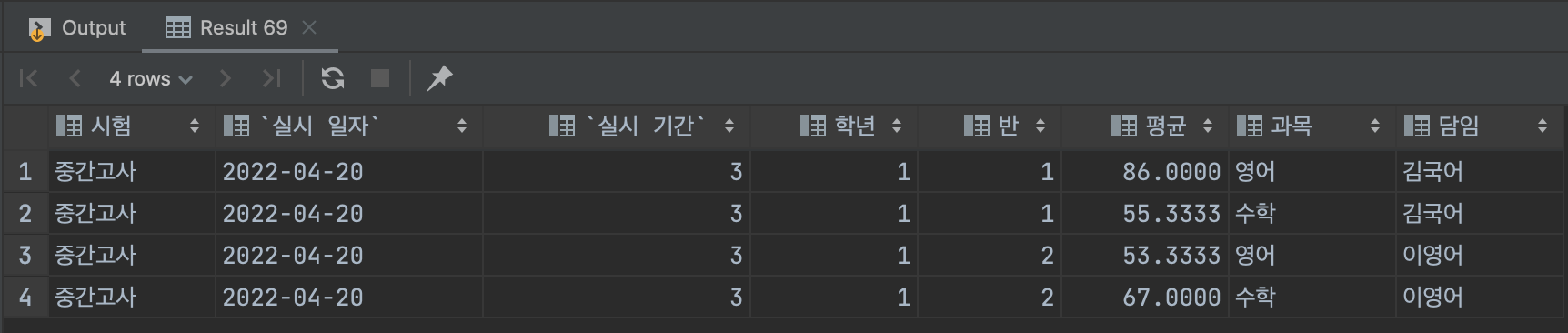
-> 학년, 반, 과목으로 묶기
SELECT `test`.`name` AS `시험`, `score`.`execution_from` AS `실시 일자`, DATEDIFF(`execution_to`, `execution_from`) + 1 AS `실시 기간`, `score`.`student_grade` AS `학년`, `score`.`student_class` AS `반`, AVG(`score`) AS `평균`, `subject`.`name` AS `과목`, `teacher`.`name` AS `담임` FROM `school`.`scores` AS `score` LEFT JOIN `school`.`tests` AS `test` ON `score`.`execution_test_code` = `test`.`code` AND `code` = 'MID' LEFT JOIN `school`.`teachers` AS `teacher` ON `score`.`student_grade` = `teacher`.`designated_grade` AND `score`.`student_class` = `teacher`.`designated_class` LEFT JOIN `school`.`subjects` AS `subject` ON `score`.`subject_code` = `subject`.`code` GROUP BY `score`.`student_grade`, `score`.`student_class` ,`score`.`subject_code`;