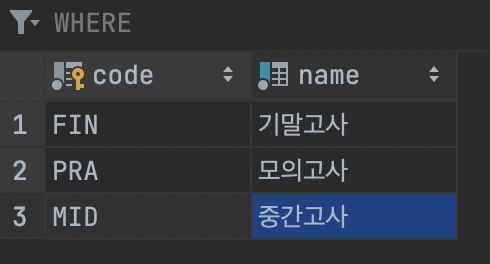
-> 시험의 종류 대한 테이블 생성 : tests
CREATE TABLE `school`.`tests` ( `code` VARCHAR(3) NOT NULL , `name` VARCHAR(10) NOT NULL , CONSTRAINT PRIMARY KEY (`code`), CONSTRAINT UNIQUE (`name`) );
-> school.tests 테이블 열 추가
- 중간고사, 기말고사, 모의고사
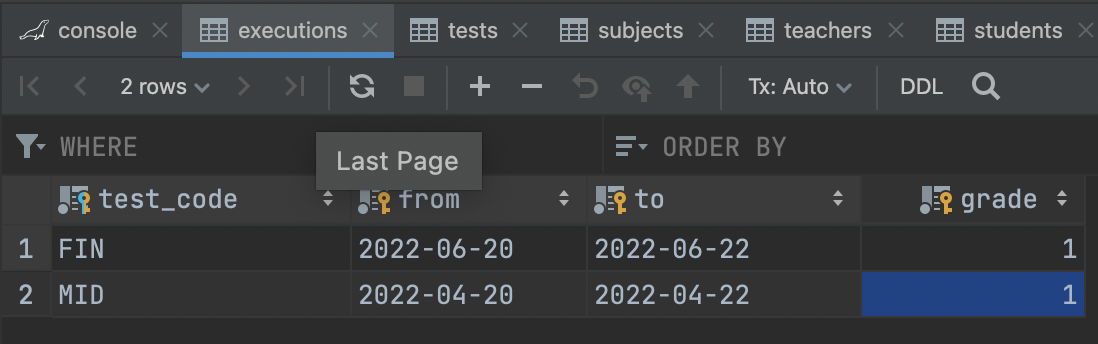
-> 테스트 일정을 담는 테이블 생성 : executions
- 어떤 시험인가? 언제부터? 언제까지? 학년? 에 대한 정보로 분류를 하자.
- 4개 싹 다 primaryKey로 건다.
CREATE TABLE `school`.`executions` ( `test_code` VARCHAR(3) NOT NULL, `from` DATE NOT NULL, `to` DATE NOT NULL, `grade` TINYINT(1) UNSIGNED NOT NULL, CONSTRAINT PRIMARY KEY (`test_code`, `from`,`to`,`grade`), CONSTRAINT FOREIGN KEY (`test_code`) REFERENCES `school`.`tests` (`code`) );
-> 점수에 대한 테이블 : scores
- 어느시험? 누가? 어떤과목? 점수?
CREATE TABLE `school`.`scores` ( `execution_test_code` VARCHAR(3) NOT NULL, `execution_from` DATE NOT NULL, `execution_to` DATE NOT NULL, `execution_grade` TINYINT(1) UNSIGNED NOT NULL, `student_grade` TINYINT(1) UNSIGNED NOT NULL, `student_class` TINYINT(1) UNSIGNED NOT NULL, `student_number` TINYINT(2) UNSIGNED NOT NULL, `subject_code` VARCHAR(3) NOT NULL, `score` TINYINT(3) NOT NULL, CONSTRAINT PRIMARY KEY (`execution_test_code`, `execution_from`, `execution_to`, `execution_grade`, `student_grade`, `student_class`, `student_number`, `subject_code` ), CONSTRAINT FOREIGN KEY (`execution_test_code`, `execution_from`, `execution_to`, `execution_grade`) REFERENCES `school`.`executions` (`test_code`, `from`, `to`, `grade`), CONSTRAINT FOREIGN KEY (`student_grade`, `student_class`, `student_number`) REFERENCES `school`.`students` (`grade`, `class`, `number`), CONSTRAINT FOREIGN KEY (`subject_code`) REFERENCES `school`.`subjects` (`code`) );
CONSTRAINT PRIMARY KEY (`test_code`, `from`,`to`,`grade`)
- 얘네에 대한 정보도 추가해야 있어야 외래키를 걸수있다.
execution_를 붙여서 추가
PRIMARY KEY : 레코드가 하나밖에 들어갈 수 없다!!
-> executions 열 추가 ( 실시한 시험 추가 )
-> scores 점수에 대한 열 추가
- 열을 작성해보니 무결성은 잘 지켜졌다.
그런데 이렇게 작성했을 시에 중복되는 데이터에 대해서는 처리가 어떻게 되어있나?

- 같은 색끼리 똑같은 정보들인데 그대로 한자도 빠짐없이 들어가있다.
=> 즉, 데이터 낭비가 심한 것 같다는 생각이 든다.
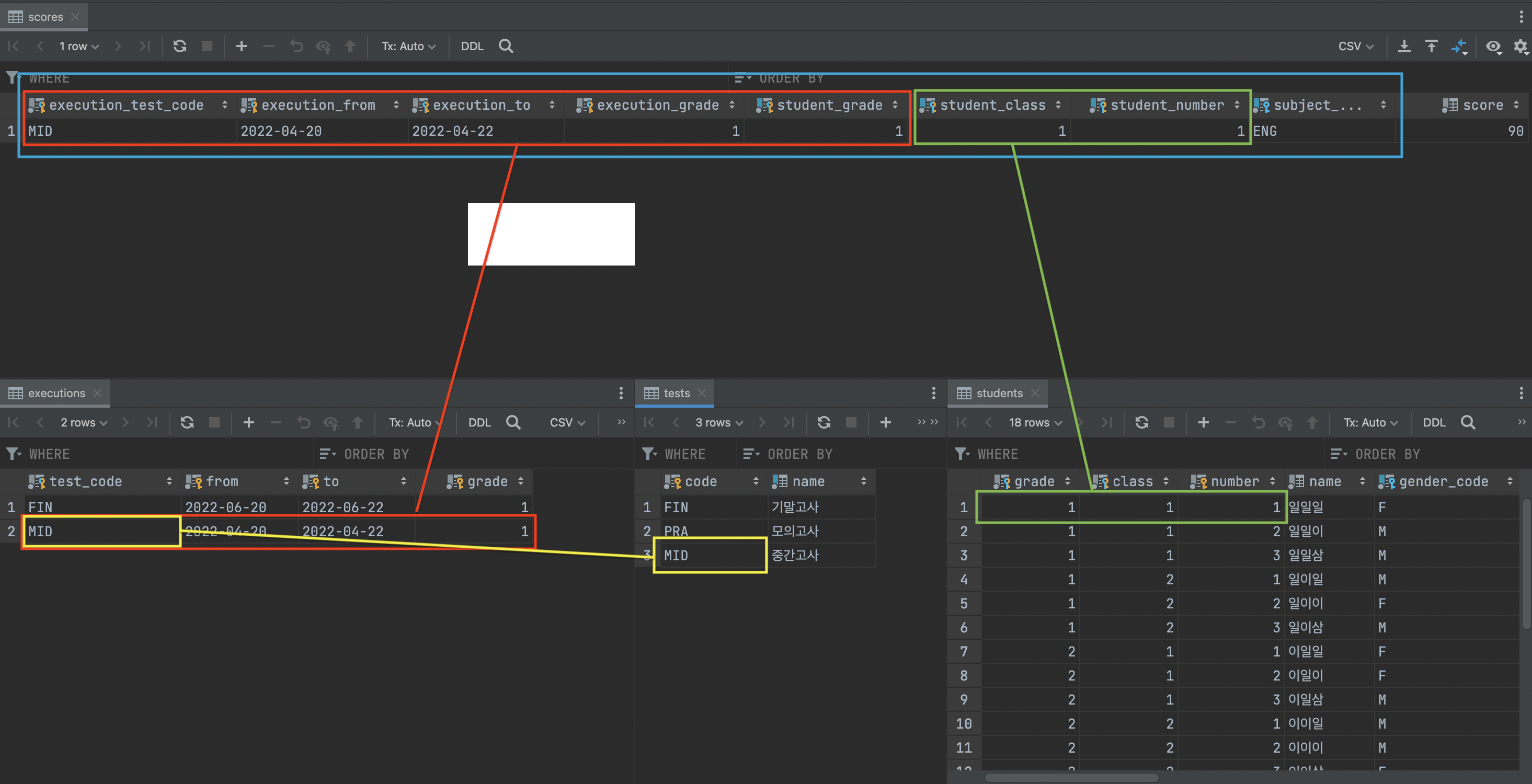
정수형을 가지는 Index를 사용해서 index만 넣어주면 어떨까?
빨간색으로 표시된 애들을 보면 12byte짜리를 1byte로 줄일 수 있다.
- 그렇게 해서 얻는것은 중복을 없앨 수 있으며 효율성이 늘어난다.
- 그렇지만 효율성이 늘어났다는건 컴퓨터 입장에서 바라본 것이기에
컴퓨터 입장에서는 일처리가 빨라지지만 개발자는 효율성을 갖다버린것이다.
즉, 개발하기가 힘들어진다는 뜻이다.
<-> 효율성을 따지지 않으면 컴퓨터가 힘들게 되고 개발자는 편하다.
❗️요점
무결성은 무조건 지켜져야하지만 효율성은 경우에 따라 버려질수도 사용할 수도 있다.
효율성을 따지지 않았을 때는 잘못된 DB라고는 할 수 없지만
무결성을 따지지 않으면 잘못된 DB가 되버린다.
