💡 분석 환경의 이해
◽ 통계 패키지 R
-
R의 선택 기준
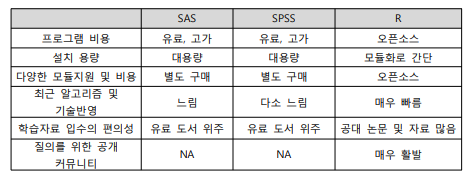
-
통계 분석 과정에서 수행되는 복잡한 계산이나 시각화 기법을 쉽게 사용할 수 있도록 설계된 무료 소프트웨어
-
기본으로 제공되는 기능 외에도 사용자들이 직접 제작한 패키지를 이용하여 무수히 많은 기능들을 사용할 수 있도록 확장 가능
-
상용 소프트웨어나 출력물에 견주어 뒤쳐지지 않는 강력한 시각화 요소
-
데이터 분석은 SQL 수준의 교육과 달리 분석도구가 다양하고
표준이 없다. -
오픈소스 프로그램으로 통계, 데이터 마이닝과 그래프를 위한 언어
-
다양한 최신 통계분석과 마이닝 기능을 제공한다.
-
전 세계적으로 사용자들이 다양한 예제를 공유한다.
◽ R의 역사
-
1993년 뉴질랜드 Ross Inaka와 Robert Gentleman에 의해 개발된 소프트웨어
-
AT&T에서 개발한 통계 프로그래밍 언어인 S언어 기반
-
S보다 한 단계 발전되었다는 의미에서 알파벳 S보다 앞선 R을 차용했다는 의미를 포함
-
S로 작성된 대부분의 코드를 실행시킬 수 있었으며, UNIXㆍWindowsㆍLinuxㆍMac OS를 지원하며 발전
◽ R의 특징
◾ 1) 그래픽 처리
-
상용 소프트웨어에 버금가는 상당한 수준의 그래프와 그림을 그릴 수 있다.
-
사용자가 세부적인 부분까지 직접 지정 하여 섬세한 작업을 수행할 수 있다.
-
고해상도 이미지를 생산하면서 처리 시간이 매우 빠르다.
-
보고서 작성이나 발표 자료 작성 시에도 유용하게 사용할 수 있다.
◾ 2) 데이터 처리 및 계산능력
-
벡터, 행렬, 배열, 데이터 프레임, 리스트 등 다양한 형태의 데이터 구조를 지원한다.
-
복잡한 데이터 구조 내의 개별 데이터에 접근하는 절차가 간단 하여 큰 데이터 를 핸들링하기 간편하다.
◾ 3) 패키지
-
사용자들이 스스로 개발하는 새로운 함수들을 패키지 의 형태로 내려받아 사용할 수 있다.
-
이러한 확장성 덕분에 다른 통계 프로그램에 비해 최신 이론이나 기법을 사용해보기가 더 쉽다.
◽ R 스튜디오
-
설치 방법
- R 공식 웹페이지인 https://www.rstudio.com에서 무료로 R을 다운로드 받고 설치할 수 있다.
-
R Studio는 R을 사용하는 통합 개발 환경 중의 하나이다.
-
R을 조금 더 간편하고 확장된 기능을 가지는 환경에서 실행할 수 있다.
-
R Studio 역시 무료로 사용할 수 있고 다양한 운영체제를 지원한다.
-
메모리에 변수가 어떻게 돼있는지 , 타입이 무엇 인지 볼 수 있고 스크립트 관리와 문서화가 편해 R studio 사용한다.
-
래틀과 R의 장단점
Rattle ❓: R 통계 프로그래밍 언어 를 사용하여 데이터 마이닝 을 위한 그래픽 사용자 인터페이스 (GUI)를 제공 하는 무료 오픈 소스 소프트웨어 ( GNU GPL v2) 패키지
출저 : https://en.wikipedia.org

R을 이용해 데이터를 다루는데에는 래틀(Rattle)과 R스튜디오가 널리 사용됩니다. 처음 접근할 때 래틀이 쉬울 수 있으나 통합성의 문재, 패키지에 정해진 기능만 사용해야 하는 문제등의 측면에서 R스튜디오를 통해 유연성을 확보하고자 했다.
💡 분석 환경의 기본 사용법
◽ R과 R Studio의 구성
◾ Ⅰ) R의 구성

-
1) 메뉴바
다양한 기본 기능 나열
-
2) 단축 아이콘 툴바
자주 사용 기능의 단축 아이콘
-
3) R 콘솔
R 명령어 입력, 결과가 출력 (한 번에 한 줄의 명령어 입력, 바로 실행) ➡️ 핵심 작업공간
-
4) 스크립트 창
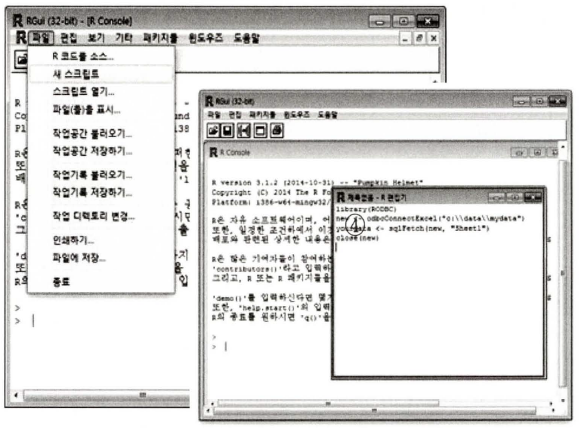
긴 프로그래밍 코드 작성 용이, 별도 실행, 여러 줄의 코드 한 번에 작성하고 한 줄씩 실행 가능, 별도의 스크립트 파일로 저장 가능
◾ Ⅱ) R Studio의 구성
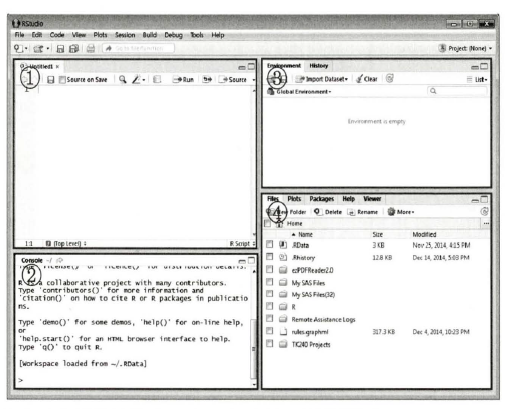
-
1) 스크립트 창
R 명령어 입력하는 창. 명령어를 실행할 때는 실행하려는 문장에 커서를 두고 CTRL + ENTER 를 동시에 눌러주면 콘솔창에서 명령어가 실행된다.
-
2) R 콘솔
- 동일, 명령어 입력하여 실행, 결과 나타난다.
한 줄씩의 코드만 입력 가능하다.
- 스크립트 창에서 실행한 명령문이 실행되는 것을 볼 수 있는 곳이며,
오류 있으면 에러메시지 가 뜬다.
명령어 직접 입력하면 저장 X , 재실행이 불가능 하다.
- 동일, 명령어 입력하여 실행, 결과 나타난다.
-
3) 워크 스페이스창 (WorkSpace,환경 및 히스토리)
할당된 변수와 데이터 나타난다.
히스토리 창에는 현재까지 정상적으로 실행한 명령어들 나열
-
4) Search Results(패키지, 저장위치, 도움말, 그래프 등)
현재 문서들이 저장되는 폴더나 R을 이용해 그린 그림들, 불러온 패키지들과 도움말 등을 별도의 한 영역에서 확인할 수 있다.
그림 출저 : https://m.blog.naver.com/PostList.naver?blogId=jdhpuppy
◽ R 패키지 설치하기
R 패키지를 통해 최신 통계 이론을 적용한 분석을 실시할 수도 있고, 복잡한 그래프 설정에 대해 미리 정의된 패키지로 손쉽게 작업할 수 있다.
또한, 기본 프로그램 R에서 지원하지 않는 명령어 나 함수 를 사용할 수 있으며 유용한 데이터셋이 내장되어 있는 패키지를 이용할 수도 있다.
◾ R : [메뉴 - 패키지툴] > [CRAN 미러사이트 지정] > [설치할 패키지 선택]
◾ R Studio : [우측 하단 인터페이스 - Packages 탭] > [Install 선택] > [패키지 이름 입력](대소문자 구분) > [CRAN 미러사이트 지정] > [미러사이트에서 패키지 다운로드 ]
- 명령어를 사용한 설치
# 패키지 설치
install.packages("패키지 이름")
# 설치 후 패키지를 R 콘솔에 불러오기
library(패키지 이름)
# 패키지 설치 명령과 불러오는 명령어에 따옴표 사용 유무 다름◽ R 도움말 (help)
- '?'나 'help' 명령어를 통해 도움말을 불러올 수 있다.
# par 함수에 대한 도움말
?par
help(par)💡 R 언어와 문법
-
C언어와 유사 하다.
-
'>' : 자동적으로 출력되는 기호, 따로
적지는 않는다. -
'#' 이후는 주석
◽ R의 데이터 구조
◾ 1. Vector(벡터)
-
하나의 스칼라값 또는 하나 이상의 스칼라 원소들을 갖는 단순 형태의 집합
-
원소는 숫자, 문자, 논리 연산자 등
- 숫자만은➡️ 숫자 벡터,
- 문자만은➡️ 문자 벡터
-
TRUE= 1, FALSE= 0
-
가장 단순 형태이다.
-
명령어 "c"를 이용해 선언된다. ('c'는 concentration, 연결을 의미한다.)
-
대소문자 구분 ➡️ 논리 연산자는 반드시 대문자로 해야된다.
-
벡터의 결합
> xy <- c(x, y)
> xy
[1] "1" "10" "24" "40" "한국" "중국" "일본"x <- c(1, 10, 24) # 문자형 벡터
y <- c("사과", "바나나") # 문자형 벡터
z = c(TRUE, FALSE, TRUE) # 논리 연산자 벡터
xy <- c(x, y) # 새로운 벡터 형성, 결과는 문자형 벡터◾ 2. 행렬(matrix)
m x n 형태의 직사각형 데이터 나열
- 기본적으로 열우선 방식
- 행과 열로 이루어진 2차원의 데이터 형태이며,명령어 matrix를 사용해서 선언한다.
matrix(벡터, [ ncol | nrow | byrow ])
- ncol : 열 의 개수를 지정
- nrow : 행 의 개수를 지정
- byrow : T값이면 행우선 방식 방식으로 변경
# 행렬 선언
mx = matrix(c(1,2,3,4,5), ncols=2) # 3행 2열 행렬
> mx
[ , 1] [ , 2]
[ 1 , ] 1 4
[ 2 , ] 2 5
[ 3 , ] 3 6 - 행렬 합치기
명령어 rbind : 행을 추가하는 형태로 데이터 결합
> r1 = c(10, 10)
> rbind(mx, r1)
[ , 1] [ , 2]
1 4
2 5
3 6
r1 10 10명령어 cbind : 열을 추가하는 형태로 데이터 결합
> c1 = c(20, 20, 20)
> cbind(mx, c1)
c1
[ 1 , ] 1 4 20
[ 2 , ] 2 5 20
[ 3 , ] 3 6 20◾ 3. 배열(array)
행렬[2차원]에 3차원 또는 n차원까지 확장된 형태 , 행렬 형태의 데이터를 층위별로 저장한다.
aarray(x, dim=c( x, y, z, ...))
- x = 벡터를 지정
- dim = 원하는 차원을 지정하며, 지정하는 숫자의 개수에 따라 차원이 결정된다.
-
주어진 벡터에 많은 차원을 부여함으로써 배열을 생성한다.
-
벡터와 행렬처럼 하나의 데이터 유형 만 가진다.
-
araay함수의 예

◾ 4. 데이터 프레임(data frame)
2차원 구조로 행렬처럼 행과 열로 구성된 형태로 강력하고 유연한 구조
-
행렬은 하나의 데이터 유형만을 가질 수 있지만 데이터 프레임은 여러가지 데이터 유형을 가진다.
-
데이터 프레임에서 하나의 열은 벡터 처럼 하나의 데이터 유형만 가진다.
-
데이터 프레임의 리스트의 원소는 벡터 or 요인
-
데이터 프레임에 들어갈 벡터의 길이는 동일해야 한다.
-
데이터 프레임은 표 형태 의 데이터 구조이며, 각 열 은 서로 다른 데이터 형식을 가질 수 있다.
-
강력하고 유연한 구조로 SAS의 데이터셋을 모방해서 만든 구조이다.
-
데이터 프레임은 엑셀의 데이터 시트와 같은 역활이다.
-
텍스트, CSV, 엑셀, DB형태로 되어있는 외부데이터 를 R로 불러오면 '데이터프레임'구조를 가진다.
-
구조
data.frame(벡터1, 벡터2,...)
> v1 <- c(1,2,3)
> v2 <- c('a','b','c')
> df = data.frame(v1,v2)
> df
v1 v2
1 1 a
2 2 b
3 3 c
◽ 데이터 프레임의 속성
◾ 행의 개수와 행의 이름
| nrow( ) | 행의 개수를 알려주는 함수. [행렬에서만 사용가능] |
| NROW( ) | 행의 개수를 알려주는 함수. [행렬과 벡터에서 사용가능] |
| rownames( ) | 행의 이름을 알려주는 함수. 기본적으로 행의이름은 문자형 [1부터 시작] 행의 이름을 변경하고 싶을 때는 c( )함수나 paste( )함수 등을 사용 |
◾ 열의 개수와 열의 이름
| ncol( ) | 열의 개수를 알려주는 함수 [행렬에서만 사용가능] |
| NCOL( ) | 열의 개수를 알려주는 함수 [행렬과 벡터에 사용가능] |
| colnames( ) | 열의 이름을 알려주는 함수, 기본적으로 열의 이름은 문자형 열의 이름을 변경하고 싶을 때는 c()함수나 paste()함수 등을 사용 |
◾ 차원 & 차원의 이름
| dim( ) | 행의 개수와 열의 개수를 한번에 알려주는 함수 첫번째 나오는 숫자가 행의 개수, 두번째 나오는 숫자가 열의 개수를 의미함 |
| dimnames( ) | 행의 이름과 열의 이름을 한번에 알려주는 함수 첫번째 나오는 이름이 행의 이름, 두번째로 나오는 이름이 열의 이름을 의미 차원의 이름은 리스트[list] 형태로 되어 있음 |
◾ 데이터 프레임 합치기
| 데이터 프레임 두 개 합치기 | rbind(df1,df2) | 열의 개수와 열 이름이 동일 |
| cbind(df1,df2) | 행의 개수가 동일해야 함 | |
| 두 개의 데이터 프레임을 동일한 변수 기준으로 합치기 | merge(df1,df2, by="DF_name") | df1과 df2의 공통 열의 이름을 기준으로 데이터셋을 병합 |
◾ 5. 리스트(list)
- 벡터와 비슷하나 벡터와 달리 데이터 타입에 상관없이 저장할 수 있는 자료구조.
- list()로 선언한 뒤에, A[[1]]과 같이 인덱스로 원소를 추가해줄 수 있다. 인덱스는 1부터 시작한다.
- 리스트 구조로 데이터를 저장해 분석하며 분석결과의 형태가 대부분 '리스트'이다.
- unlist() : 리스트형식의 데이터를 벡터로 변환한다.
> a <- c(1,2,3)
> b <- c("apple","orange","banana")
> list(100,a,b,"lee","kim")
[[1]]
[1] 100
[[2]]
[1] 1 2 3
[[3]]
[1] "apple" "orange" "banana"
[[4]]
[1] "lee"
[[5]]
[1] "kim"
◽ 배열[Array] VS 리스트[List]
| 배열[Array] | 리스트[List] |
| 이미 정해진 크기 의 메모리공간이 필요 | 데이터를 하나씩 집어넣을 때마다 메모리 공간을 생성한다. |
| 데이터의 위치에 대해 직접적인 엑세스가 가능하다. | 처음부터 몇 번째인지 세면서 위치를 찾아나가야한다. |
| 데이터의 삽입이나 삭제가 상당히 불편하다. | 데이터의 삽입이나 삭제가 상당히 편리하다. |
◽ R의 데이터 핸들링
◾ 1) 벡터형 변수
벡터 뒤에 대괄호 [ ] 를 붙여 숫자를 지정하여, 원하는 값을 불러온다.
> b = c ("a", "b", "c", "d", "e")
> b [2] # 2번째 값
[1] "b"
> b [-2] # 2번째 값을 제외한 벡터
[1] "a" "c" "d" "e"
> b [ c( 2 , 3 ) ] # 2, 3번째 값
[1] "b" "c"◾ 2) 행렬/데이터 프레임 변수
-
행렬형 변수나 데이터 프레임 변수에 대해서도 대괄호[ ]를 통해 특정요소 의 참조 가 가능하다.
-
원하는 행, 열, 행과열 / 제외하려는 행, 열을 선택할 수 있으나, [ -m , -n ] 의 형태로 하
나의 원소만을 제외할 수는 없다.
> mydat [ 3 , 2 ] # 3행 2열의 값
> mydat [ , 2 ] # 2열의 값
> mydat [ 4 , ] # 4행의 값◽ 데이터 구조 변환
데이터 구조를 다른 구조로 바꾸고 싶을 때 사용하며,변환 적용 안 되면 NA값 이 나타난다.
-
as.data.frame(x) : 데이터프레임 형식으로 변환
-
as.list(x) : 리스트 형식으로 변환
-
as.matrix(x) : 행렬 형식으로 변환
-
as.vector(x) : 벡터 형식으로 변환
-
as.factor(x) : 팩터(factor) 형식으로 변환
-
as.numeric(논리값) : FALSE=0 , TRUE=1
-
as.character(숫자) : 숫자 ➡️ 문자
◽ 문자열 ➡️ 날짜 변환
2013-08-13처럼 문자열 표현으로 된 날짜를 Date 객체로 변환한다.
- as.Date("yyyy-mm-dd") 함수 이용
- yyyy-mm-dd" 형식의 문자열이 아닐경우, format 옵션으로 형식을 지정한다.
- yyyy-mm-dd" 형식의 문자열이 아닐경우, format 옵션으로 형식을 지정한다.
- Sys.Date() : 현재 날짜 를 반환
- as.Date() : 날짜 객체 로 변환(yyyy-mm-dd)
- format : 날짜 스타일 변환(“%m/%d/%Y”→08/13/2013“)
> as.Date ( "01/13/2015" , format="%m/%d/%Y" )
[1] "2015-01-13"◽ 날짜 ➡️ 문자열 변환
- format(날짜, 포맷)
- as.character(Sys.Date())
- format(Sys.Date(),‘%a’) : 요일 조회 → 월
- format(Sys.Date(),‘%b’) : 축약 월 이름 조회 → 3
- format(Sys.Date(),‘%B’) : 전체 월 이름 조회 → 3월
- format(Sys.Date(),‘%d’) : 두자리 숫자로 된 일 조회 → 17
- format(Sys.Date(),‘%m’) : 두자리 숫자로 된 월 조회 → 03
- format(Sys.Date(),‘%y’) : 두자리 숫자로 된 연도 조회 → 14
- format(Sys.Date(),‘%Y’) : 네자리 숫자로 된 연도 조회 → 2014
◽ 알아두면 유용한 기타 함수들
• write.csv(변수 이름,“지정할 파일이름.csv”) : 변수를 csv 파일로 저장
• read.csv(“저장된 파일이름.csv”) : csv 파일을 R로 읽는다.
• save(변수이름, file=“지정할 데이터 파일이름.Rdata”) : R데이터 파일로 저장
• load(“저장된 파일이름.Rdata”) : R 데이터를 읽어 들이는 방법
• rm() : 데이터 삭제, 선택 변수만 삭제
• rm(list=ls(all=TRUE)) : 모든 변수를 삭제
• summary() : 한 번에 간단한 통계량들을 데이터세트 열마다 요약
• head() : 데이터세트의 6번째 행 까지 조회
• install.packages(“패키지 이름”) : R 패키지 설치
• library(패키지 이름) : R에 패키지를 불러오는 함수
• vignette(“알고 싶은 package 이름”) : 정보 간단 요약본
• q() : 작업종료. 종료시 작업환경 변수 저장여부 물음
• setwd(“~/”) : R 데이터와 파일등을 로드하거나 저장할 때 워킹 디렉터리 지정
• ? 명령어 : 도움말 로드
• ?? 명령어 : 명령어 검색
본 게시물에 포함된 내용은 한국데이터산업진흥원에서 발행한]
[데이터 분석 전문가 가이드, 2019년 2월 8일 개정]에 근거한 것임을 밝힙니다. 