📌 감성 분석 위한 리뷰 데이터 번역
에어비엔비 도쿄 리뷰 데이터를 Goolgle translator를 사용하여 번역하였다.
리뷰 데이터 언어는 대부분 영어로 존재하나, 다국적 언어로 다양하고 이를 한국어로 번역하였다.
리뷰 글자수가 500개 넘어가면, GoogleTranslator가 번역 할 수 없으므로 예외처리 하였다.
리뷰 번역 코드
from deep_translator import GoogleTranslator
from tqdm import tqdm
class Translator:
def __init__(self, source, target):
self.source = source
self.target = target
def translate_text(self, text):
translator = GoogleTranslator(source=self.source, target=self.target)
translated_text = translator.translate(text)
return translated_text
import tqdmLinguaUtil as tlu
import pandas as pd
from tqdm import tqdm
import sys
#print(sys.path)
if __name__ == '__main__':
source_lan = 'auto'
target_lan = 'ko'
ex = tlu.Translator(source = source_lan, target = target_lan)
translated_comments = pd.DataFrame(columns=['kr_comments'])
with tqdm(total=len(df)) as pbar:
for index, row in df.iterrows():
try:
translated_text = ex.translate_text(row['comments'])
translated_comments.loc[index] = [translated_text]
pbar.update(1)
except:
print(f'{index}error')
pass
df['kr_comments'] = translated_comments['kr_comments']📌 Hugging Face - Sentiment analysis Kcelectra
문장에 대해 다음과 같은 감정 종류와, 해당 감정에 대한 확률을 결과로 도출한다.
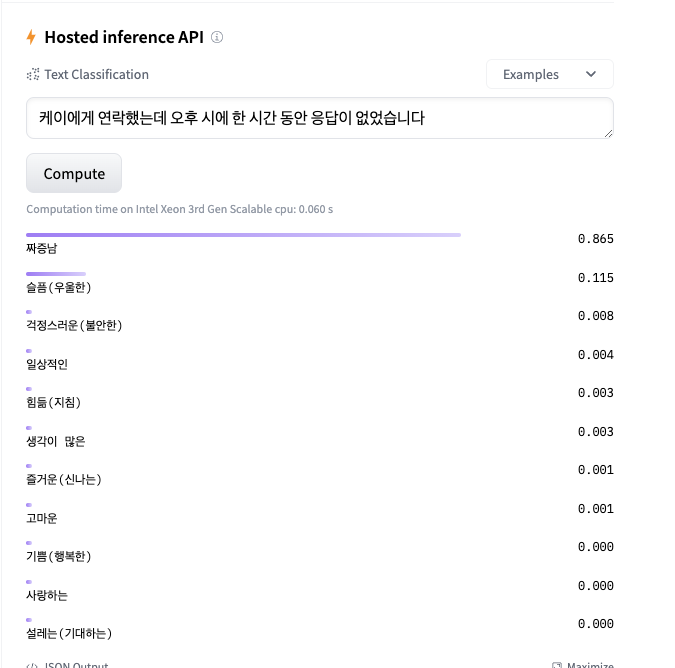
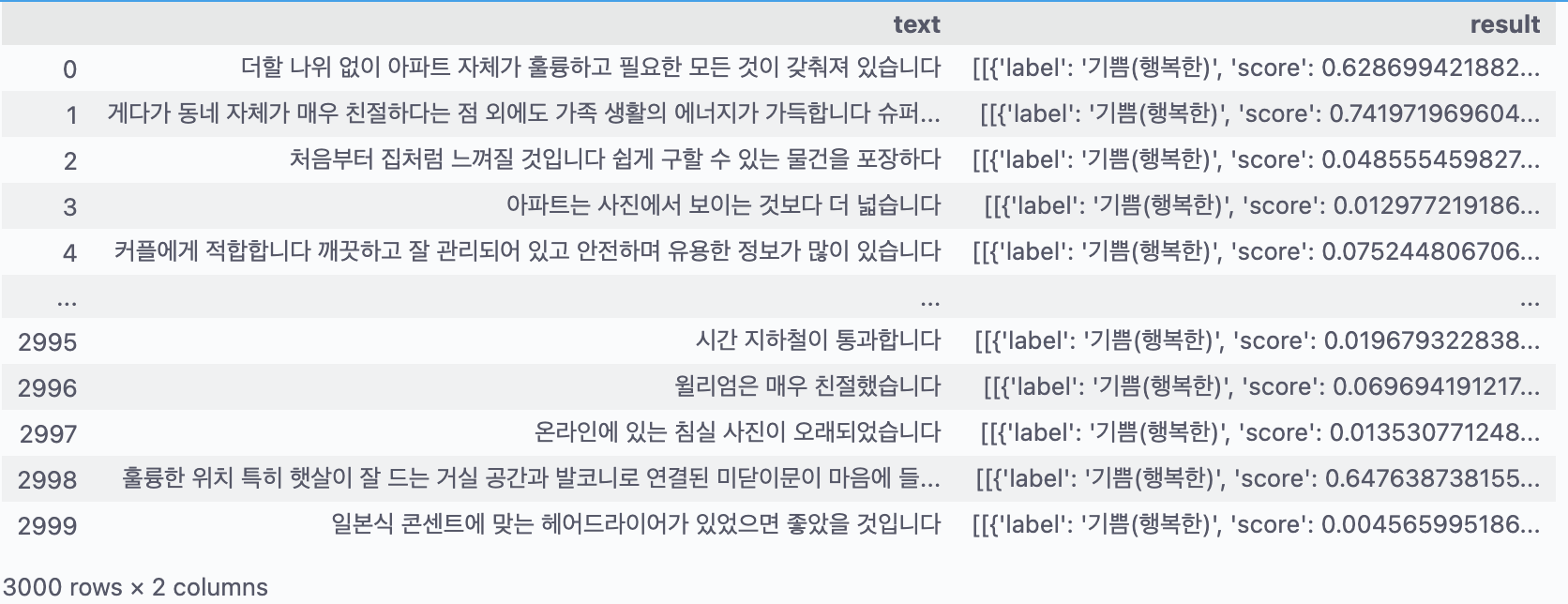
가장 높은 확률의 감정을 추출한다.
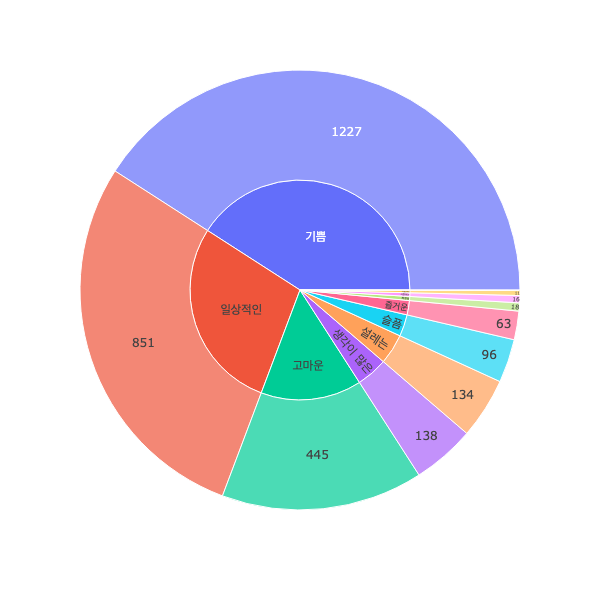
다음은 리뷰에 존재하는 감정 종류 분포에 따른 시각화이다.
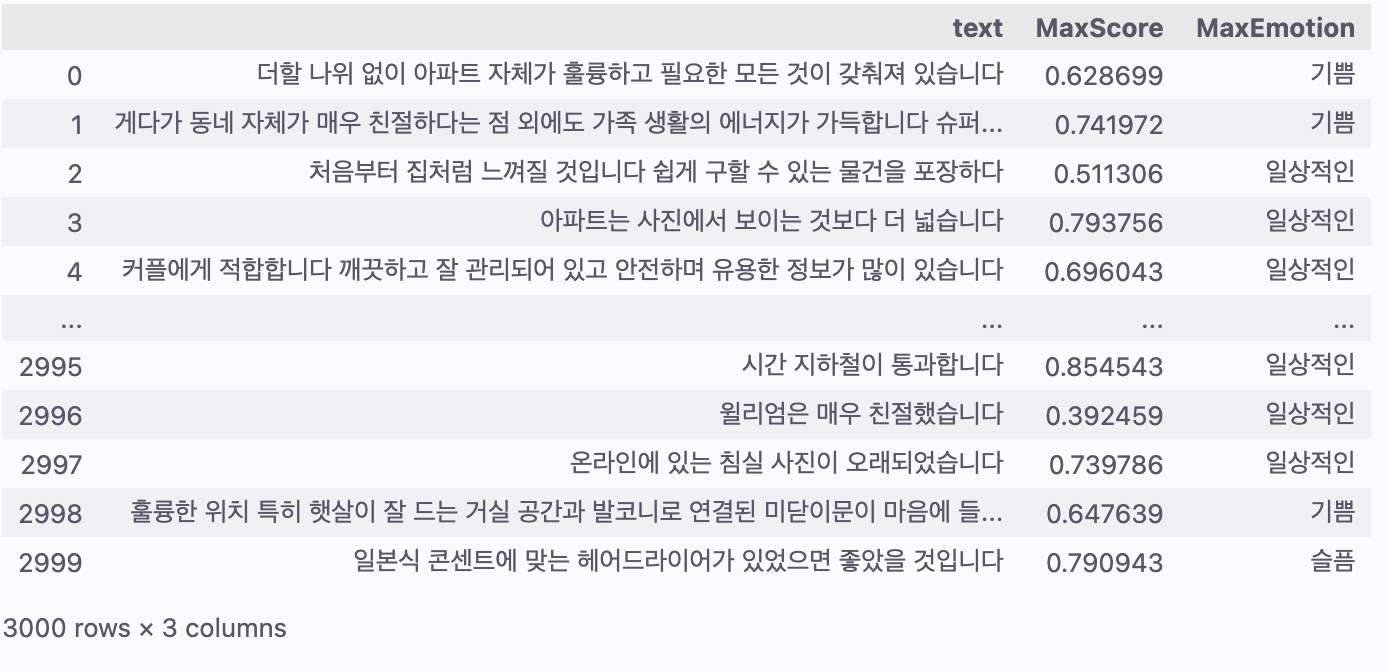
가장 높은 확률의 감정에 대하여 Label Encoding 하였다.

📌 Goolge Colab 환경 세팅
필요 라이브러리 설치 및 불러오기
#https://github.com/SKTBrain/KoBERT 의 파일들을 Colab으로 다운로드
!pip install 'git+https://github.com/SKTBrain/KoBERT.git#egg=kobert_tokenizer&subdirectory=kobert_hf'
!pip install transformers
!pip3 install kobert-transformers
!pip install gluonnlp
!pip install mxnet# Transformers
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
# Setting Library
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
import pandas as pd
device = torch.device("cuda:0")📌 Kobert 학습 및 추론 결과

# 학습 코드 생략
model.eval()
def predict(sentence):
dataset = [[sentence, '0']]
test = BERTDataset(dataset, 0, 1, tok, vocab, max_len, True, False)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=batch_size, num_workers=4)
model.eval()
answer = 0
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_dataloader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
for logits in out:
logits = logits.detach().cpu().numpy()
answer = np.argmax(logits)
return answer
내가 임의로 작성한 문장에 대한 테스트 결과이다.
"숙소가 좁고 벌레가 나왔다." - 전반적으로 부정적인 경험 (9)짜증남
"냄새는 안났지만 숙소는 좁았다." - 앞부분은 긍정적이지만 숙소가 좁다는 부분이 부정적 (6)슬픔
"카페모카는 너무 맛있었는데 추웠다." - 앞부분은 긍정적이지만 날씨가 추웠다는 부분이 부정적 (6)슬픔
"병원의 주요 커버 범위를 시각화하였다." - 전반적으로 긍정적이고 일상적인 내용 (7)일상적인
문장 당 높은 확률의 감정으로 비교적 정확도가 높게 분류되었다.

꾸준한 개발자를 꿈꿈