
정보처리기사
요구사항확인과 DATA입출력구현작업
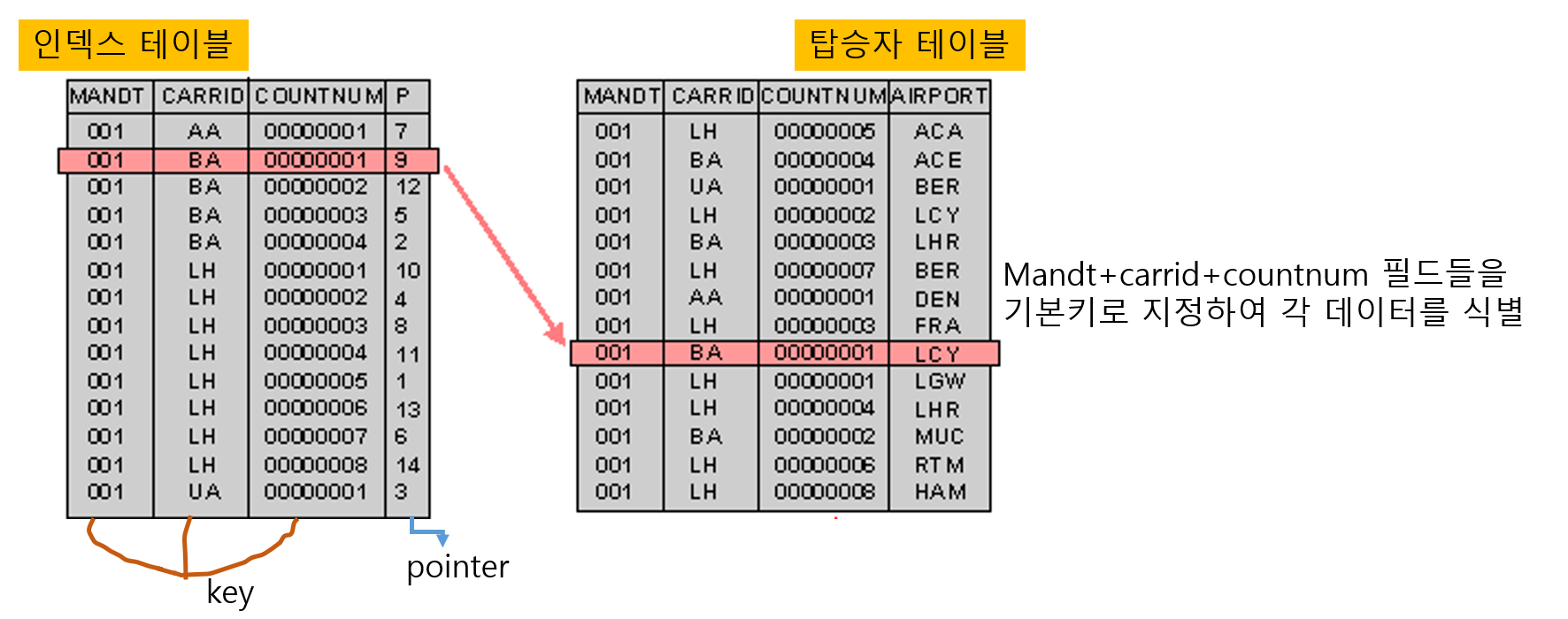
인덱스(INDEX)
- 데이터 레코드에 빠르게 접근하기 위해 <키 값, 포인터>로 구성되는 데이터 구조
- 레코드가 저장된 물리적 구조에 접근하는 방법을 제공
- 레코드의 삽입과 삭제가 수시로 일어나는 경우에는
인덱스의 개수를 최소로 하는 것이 바람직
- 기본키를 위한 인덱스를 기본 인덱스라고 하고
그 외의 인덱스들을 보조 인덱스라고 함인덱스 사용 예시
인덱스 순서 일치 여부에 따른 분류
clustered index
- 인덱스 키의 순서에 따라 데이터가 정렬되어 저장
- 실제 데이터가 순서대로 저장되어 있어서 인덱스를
검색하지 않아도 신속한 데이터 검색이 가능
- 하나의 릴레이션에 하나의 인덱스만 생성가능
non-clustered index
- 인덱스 키 값만 정렬되어 있고 실제 데이터는 정렬되어 있지 않음
- 데이터 검색시 인덱스 먼저 검색한 후 실제 데이터 위치를
확인해야하므로 검색속도는 clustered에 비해 떨어짐
- 하나의 릴레이션에 여러 개 인덱스 생성가능클러스터드 인덱스 예시
인덱스 구조에 따른 분류
트리기반(B-tree) index
- 루트 노드로부터 하위 노드로 키 값의 크기를 비교해 가면서
찾고자 하는 데이터를 검색하는 구조로 일반적인 인덱스 방식
- 데이터 양에 상관없이 모든 데이터 인덱스 탐색시간은 동일
bitmap index
- 인덱스 컬럼의 데이터를 bit값인 0 또는 1로 변환하여 인덱스 키로 사용하는 방법
- 데이터가 bit로 구성되어 있어서 효율적인 논리 연산이 가능하고 저장공간을 적게 차지
- 다중 조건을 만족하는 튜플의 개수 계산에 적합하고 동일한 값이 반복되는 경우가 많아서 압축효율이 좋음
함수 기반 index
- 컬럼의 값 대신 컬럼에 특정 함수나 수식을 적용하여 산출된 값을 사용
- 데이터 입력하거나 수정시 함수를 적용해야 하므로 부하가 발생
특히, 사용자 정의함수 일 경우 부하가 더 심함
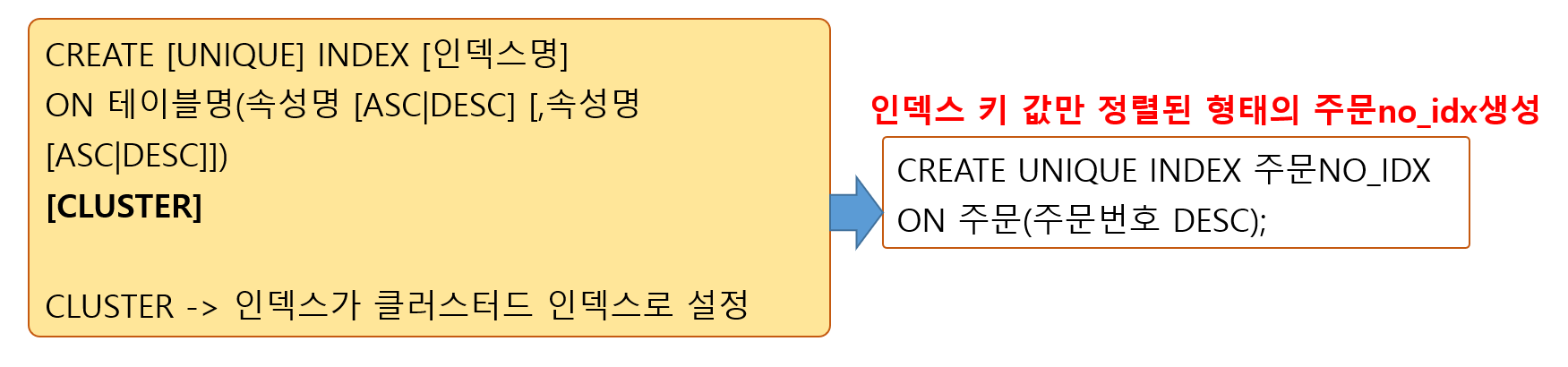
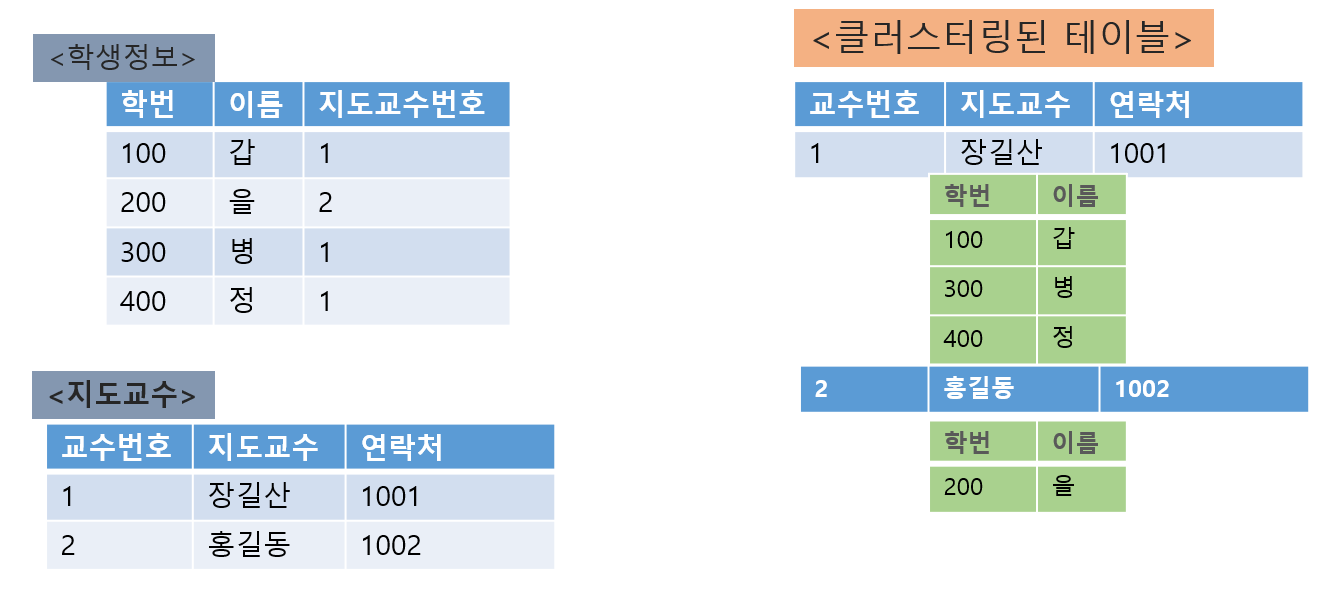
- 대소문자, 띄어쓰기 등에 관계없이 데이터 조회할 때 유용하게 사용클러스터(CLUSTER)
- 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나
자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법
- 클러스터링키 컬럼 값의 순서대로 저장되고 여러 개의 테이블이 하나의 클러스터에 저장
- 클러스터링 된 테이블은 데이터 조회 속도는 향상시키지만
데이터 입력, 수정, 삭제에 대한 성능은 저하됨
- 클러스터된 테이블 사이에 조인이 발생할 경우 처리시간이 단축
- 클러스터링키 열을 공유하여 한 번만 저장하므로 저장 영역의 사용을 줄임
- 대용량을 처리하는 트랜잭션은 전체 테이블을 스캔하는 일이
자주 발생하므로 클러스터링을 하지 않는 것이 바람직
- 파티셔닝된 테이블에는 클러스터링을 사용 불가
- 처리범위가 넓은 경우에는 단일 테이블 클러스터링을 사용
조인이 많이 발생하는 경우에는 다중 테이블 클러스터링을 사용클러스터링된 테이블 예시
파티션(Partition)
- 대용량의 테이블이나 인덱스를 작은 논리적 단위로 나누는 것을 의미
- 작은 단위로 나눠서 분산시키면 성능저하 방지 뿐 아니라 데이터 관리도 수월해짐
- 테이블, 인덱스를 파티셔닝하면 파티션키 또는 인덱스 키에 따라
물리적으로 별도의 공간에 데이터가 저장
- 데이터 접근시 엑세스 범위를 줄여 쿼리 성능이 향상
- 파티션별로 데이터가 분산되어 저장되므로 디스크 성능이 향상
- 파티션 단위로 입출력을 분산시킬 수 있음- 파티션 분할 방법에 따른 분류
- 범위 분할(Range Partitioning)
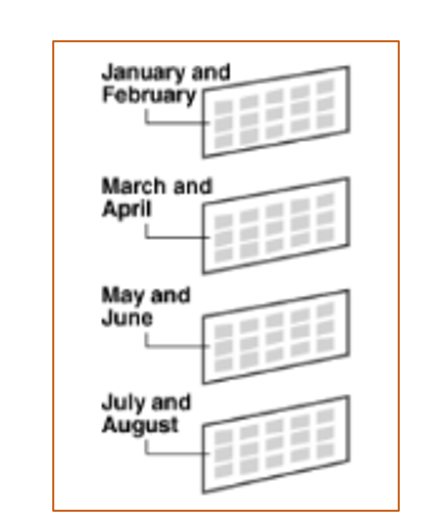
분할 키 값이 범위 내에 있는지 여부로 구분
예) 일별, 분기별, 월별 파티셔닝- 해시분할(hash partitioning)

해싱함수를 적용한 결과 값에 따라 데이터를 분할
데이터를 고르게 분산할 때 유용- 조합분할(composite partitioning)

범위 분할로 분할한 다음 해싱 함수를 적용하여 다시 분할하는 방식
파티션이 너무 클 경우 유용체크포인트
문제 1
정답)
인덱스 키의 순서에 따라 데이터가 정렬되어 저장
실제 데이터가 순서대로 저장되어있어 인덱스를 검색하지 않아도 신속한 데이터 검색 가능
하나의 릴레이션에 하나의 인덱스만 생성 가능
★인덱스키의 순서에 따라 데이터가 정렬되어 저장되고
실제 테이블의 데이터가 순서대로 저장되어있는 구조문제 2
정답)
범위분할, 해시분할, 조합분할
Back-end Developer Preparation Students