
23.03.17 금 7일차
오늘의 수업내용
- 스키마 만들기
- 시퀀스 활용하기(복습)
- 오라클 페이지 나누기(rownum)
- SQL 쿼리문
- Sample 구문
- delete, drop, truncate 차이
- number 데이터 형
- CLOB과 BLOB
- 새로 이해한 내용(데이터형)
> 스키마(= 사용자 = 데이터베이스) 만들기
create user sqlDB identified by 1234;
grant connect , resource, dba to sqlDB; -- 역할 부여
select * from userTBL;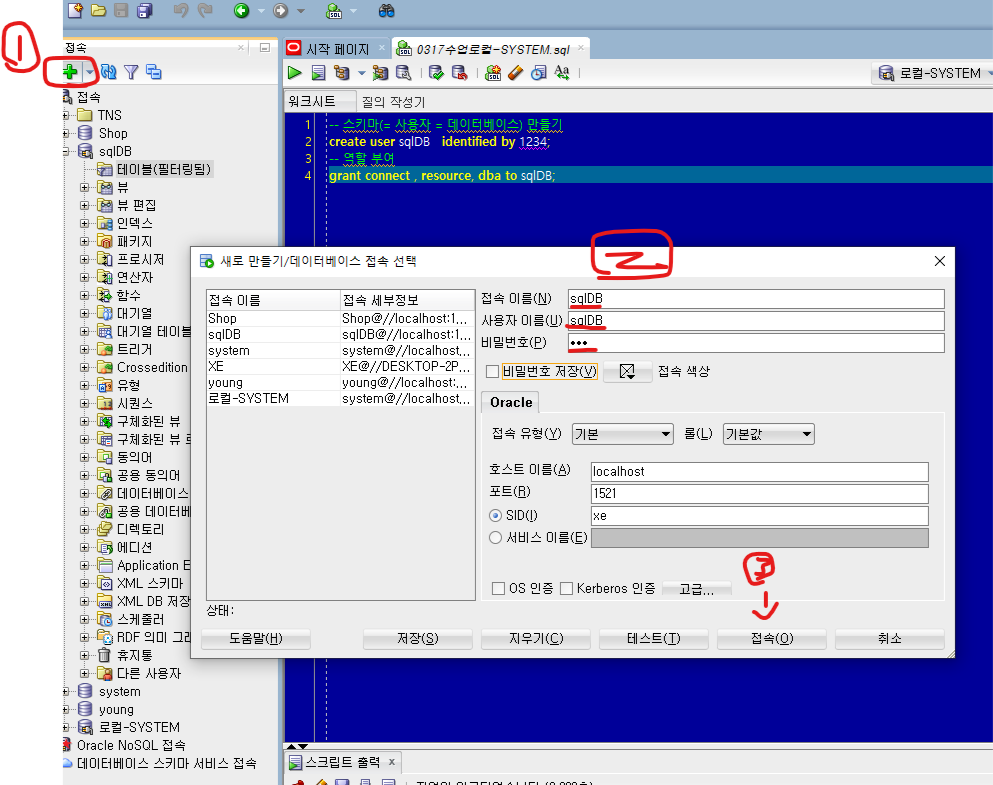
seqeunce 활용하기
방법 1
- 테이블 생성
create table userTBL1
as
select 순번 IDX, 고객이름 userName,
출생년도 birthYear, 주소 addr, 연락처 tel
from userTBL;테이블 생성 확인
select * from userTBL1;시퀀스(sequence) 생성
create sequence id_seq;해당 시퀀스의 값을 증가
update userTBL1 set idx=id_seq.nextval;- where, having 조건문 차이점
where 레코드에 조건을 줌
having 집계함수에 조건을 줌> 오라클 페이지 나누기(rownum) SQL 쿼리문 설명
--범위 출력
select rownum, username from userTBL1
where rownum between 1 and 7;
-- between 시작 범위값을 1에서만 입력 가능- 정렬
select rownum, username from userTBL1
order by username desc;- 삭제
delete from buyTBL1
where username Like '김%'; -- 김으로시작되는 이름delete from buyTBL1
where username Like '성%'; -- 성으로 시작되는 이름- 삭제 확인
select rownum, emp_no,
First_name, last_name from bigdata;특이사항
중간 값이 사라져도 rownum의 값은 변경 없이 내림차순
이유 : rownum은 레코드가 생성된 이후에 만들어지기 때문
범위 삭제
delete from bigdata where EMP_no between 1 and 7;rownum 1번 삭제
delete from bigdata where rownum = 1;rownum 2번 삭제
delete from bigdata where rownum = 2;- rownum 정렬기준
-- rownum 정렬(비순차적)
select rownum rnum, emp_no, First_name,
last_name from bigdata
order by first_name desc;
--order by정렬시 rownum순서 비순차적으로 정렬됨
--rownum은 레코드가 생성된 이후에는 유지되기 때문-- rownum 정렬(순차적)
select rownum rnum, k.* from -- 쿼리에 별칭 지정
(select frist_name, last_name from bigdata order by bigdata.first_name desc) k;
-- rownum는 순차적으로 정렬
-- 쿼리가 안에서 먼저 동작 후 rownum가 생성되었기 때문- 내부 쿼리 선처리
select rownum rnum, emp_no, First_name, last_name from
(select * from bigdata);- 쿼리문 별칭처리
select rownum rnum, k.* from
(select * from bigdata) k;
--정렬 추가
select rownum rnum, k.* from
(select first_name, last_name from bigdata order by bigdata.first_name desc) k;
-- 범위 추가
select rownum rnum, k.* from
(select rownum rn , first_name, last_name from bigdata
order by bigdata.first_name desc ) k
where rownum between 1 and 7;
-- rownum 범위 설정 추가
select rownum rnum, p.*
from
(
select rownum rn, emp_no, first_name, last_name
from (
select * from bigdata
where First_name like '%shin%'
order by emp_no desc
) k -- 별칭
where rownum <= 10 -- 큰숫자 (RN 칼럼의 끝범위)
) p -- 별칭
where rn >= 1; -- 작은숫자 (RN 칼럼의 시작범위)> sample 구문
select * from buyTBL1 sample(20); -- (퍼센트)
-- 대략적으로 계산되어 나온다
-- 일정한 출력값이 아니므로 정확하지 않음> delete, drop, truncate 차이점
delete from t1
commit; -- 테이블 내부만 삭제 / 삭제내역 ↑, 삭제시간↑
drop table t2; --테이블 전부 삭제 / 삭제시간 ↓
truncate table t3;--테이블 내역 잘라내기(delete와 동일) / 삭제시간 ↓> 숫자(number) 데이터 형식
- number 형 범위 값 선언시 출력값 확인
create table p239
(
id number (5,2) -- (정수, 소수점)범위 자릿수를 나타낸다
);- 정상
insert into p239(id)
values(123.45);
insert into p239(id)
values(123.00);
-- 소수점 .00 = 0 출력값은 123으로 표기- 오류
insert into p239(id)
values(1234);
--소숫점 2자리포함 정수형은 3자리까지 입력 가능으로 오류- number 형 범위 값 미선언 출력값 확인
create table p239(
id number
);- 값 입력
insert into p239(id)
values(12345678901234567890123456789012345678901234567890);
-- 40번자리까지 정상입력
-- 이후 큰값은 0으로 통일되어 출력- 값 확인
select * from p239;> CLOB , BLOB
movieTBL 만들기
Create table movieTbl (
movie_id number(4),
movie_title nvarchar2(30),
movie_director nvarchar2(30),
movie_star nvarchar2(30),
movie_script clob, --텍스트파일
movie_film BLOB -- 바이너리파일(mp3,동영상 등)
);- movieTBL 데이터 불러오기
명령프롬포트 cmd 이용
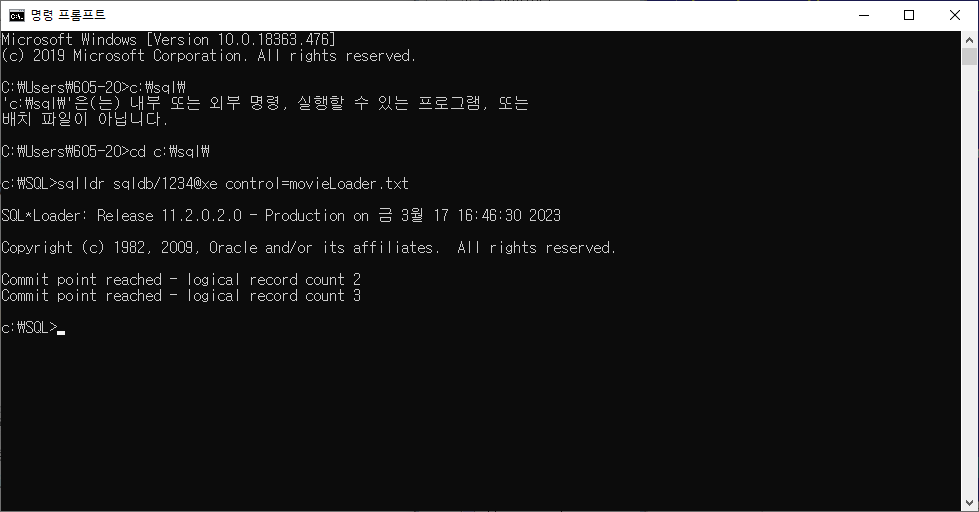
- 입력 형식
sqllde 스키마명/비밀번호@호스트 control=입력한 테이터 문서- 테이블 값 확인
select * from movieTBL;imgTBL 만들기
create table imgTBL(
idx number(4),
imgtitle nvarchar2(30),
imgCLOB CLOB, -- 텍스트 파일
imgBLOB BLOB -- 바이너리 파일
);- imgTBL 데이터 불러오기
명령프롬포트 cmd 이용
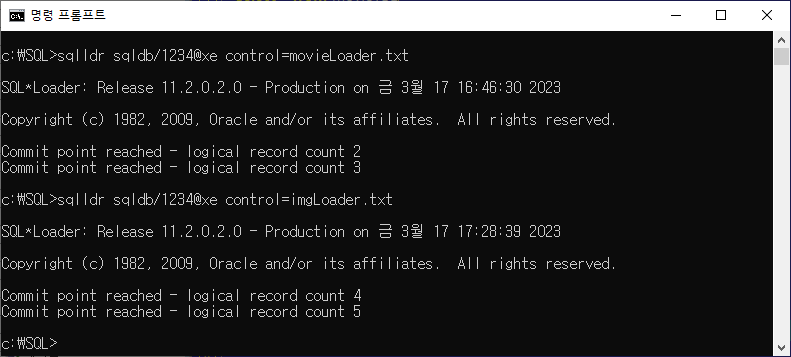
- 입력 형식
sqllde 스키마명/비밀번호@호스트 control=입력한 테이터 문서- 테이블 값 확인
select * from imgTBL;CLOB, BLOB 데이터 삽입 방법
- insert -> 비어있는 테이블에 데이터 삽입
replace -> 기존 행 삭제 후 삽입
append -> 새로운 행을 기존의 데이터에 추가(연속적으로 사용가능)
truncate -> 테이블의 기존 데이터를 모두 삭제하고 삽입
새로 이해한 내용(데이터형)
- 데이터형 char 와 nchar 차이
char(5) = 5개의 데이터블록중 3개의 블록을 유니코드가 차지
EX)
( | | | | |) -5개의 칸중 유니코드 '가'입력시
(ㄱ|ㅣ|ㅏ| |) 3개의 칸을 차지
nchar(5) = 5개의 데이터블록 중 1개의 블록이 유니코드가 차지
EX)
( | | | | | ) - 5개의 데이터블록 중 유니코드 '가'입력시
(가| | | | ) 1개의 칸에 개별로 유니코드가 입력 1개의 칸만 차지
Back-end Developer Preparation Students