XLNet
BERT + GPT
AE(Auto Encoder) + AR(Auto Regressive)
- Factorization order고려하여 양방향 학습
- AR formula를 통해 BERT한계 극복
Auto Encodeing과 Auto Regressive

XLNet은 AE(BERT)와 AR의 장점을 취함으로써 단점으로 보완했다.
- AE의 문제점
- [MASK] token이 독립적으로 예측(independent assumption)되기 때문에 token 사이의 dependency는 학습 할 수 없음 (한 문장안에 2개의 [MASK] token이 있다고 했을때, 각자 예측되므로 서로의 dependency는 학습되지 않음)
- finetuning 과정에서 [MASK] token이 등장하지 않기 때문에 pretraining과 finetuning사이에 discrepancy 발생 - AR의 문제점
- 단일 방향(uni-direction) 정보만 이용하여 학습 가능함
단점을 어떻게 보완했는가?
1. Permutation Language Modeling Objective
Permutation 집합을 통해 다양한 sequence고려
AR Objective function에 대입
특정 token에 양방향 context 고려할 수 있음
아래의 그림은 세번째 token(x3)을 예측할때, permutation 집합을 통해 앞, 뒤(x1, x2, x4)가 모두 고려되는 모습를 설명했다.
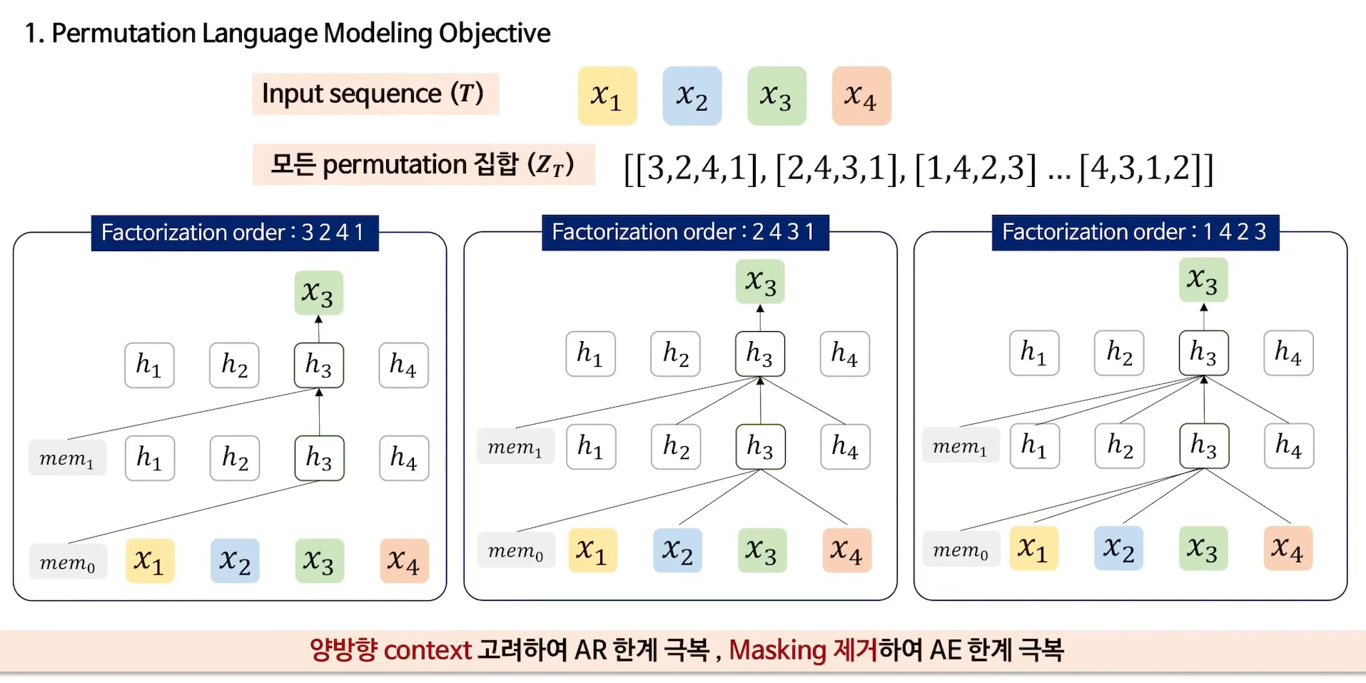
첫번째를 보면 factorization order가 3 2 4 1이며, 세번째 토큰을 예측하므로 다른 토큰을 고려하지 않고, memory(이전 context에서 가져온 정보)만 고려했다.
이로써 양방향의 context를 고려함으로 AR의 한계와, Masking을 제거하여 AE의 한계를 극복했다.
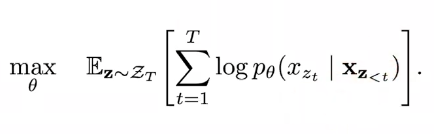
앞서 permutation으로 뒤섞인(?) 순서(sequence)가 주어졌을때, 다음 token이 무엇이 나올지 예측하는 것이 permuctation language modeling이라고 생각하면 된다.
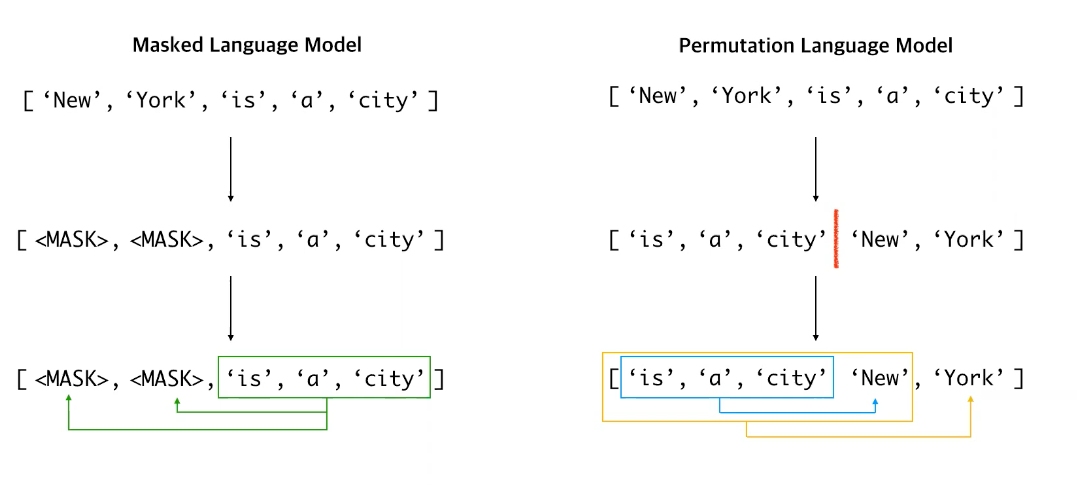
MLM과 PLM의 차이를 한눈에 볼 수 있는 예시가 있어 가져왔다.
MLM은 두개의 마스크 토큰이 독립적으로 예측되지만, PLM은 (빨간선을 기준으로) 마지막 두개의 토큰을 예측할때, 두개의 토큰이 독립적이라는 가정이 없다. 한마디로 York이라는 단어를 예측할때는 New와 그 앞의 모든 토큰을 다 고려하여 예측하는 것이다.
2. Target-Aware Representation for Transformer
PLM의 치명적인 단점 !

뒤섞은 다음에 다음 단어를 예측하려면, 그 다음 단어가 어느 위치에 있는 단어인지 모른다..! 이 정보를 사전에 모델에 입력할 수 없다. 이를 해결하기 위한 방법이 two-stream self-attention
- 새로운 objective function은 standard Transformer에서 작동하지 않음
- 따라서 Transformer에 XLNet의 Objective function을 적용하기 위해 Target-Aware Reapresentation 제안


target을 알고 있는 상태로 학습?
두가지의 예측할 representation과 target token을 함께 학습하고자 하는 것이 여기서 추구하는 target aware representation
3. Two-Stream Self-Attention
위에서 바꾼 representation에 self attetion을 적용하기 위해 두가지 stream으로 나눠서 생각
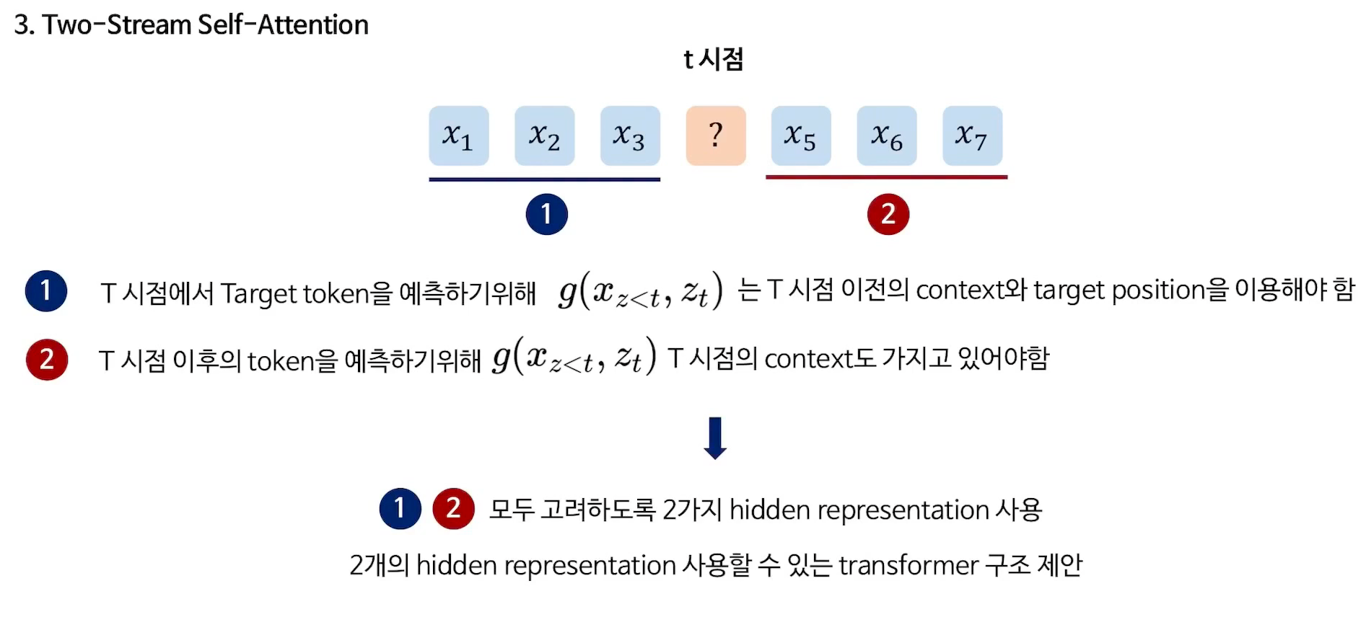
Content stream에서는 예측하고자 하는 token의 정보를 함께 사용
띠용....예측하고자 하는 token이 있는데 그 정보를 같이 활용한다? 말이 안된다..!라고 생각할 수 있지만 우리에겐 Query stream도 있다.

x1, x2, x3, x4 : 어떤 토큰의 임베딩 값
w : 위치정보
factorization order가 3 2 4 1인 상황에서,
position 3을 예측한다고 하면 : position 3의 위치정보만 고려하여 학습
position 2를 예측한다고 하면 : position 2의 위치정보와 x3 token의 정보를 고려하여 학습
...
=> 예측하고자 하는 토큰의 전 시점까지의 토큰 정보 & 예측하고자 하는 토큰의 위치정보 & initialize된 vector 사용

Query stream에서는 토큰의 정보만을 활용하여 학습을 진행한다. (예측하고자하는 토큰의 정보까지 포함) (Query stream은 fine-tuning시에 사용하지 않음)
Reference
https://www.youtube.com/watch?v=v7diENO2mEA
https://www.youtube.com/watch?v=koj9BKiu1rU
