📋 개요
원티드 프리온보딩 두번째 날이다. 어제 NLP의 대략적인 Task들에 대해 알아본데에 이어, 오늘은 NLU task에 대해 알아보았다. 그 중 하나의 Sub task인 STS(Semantic Textual Similarity)에 대해 글을 작성하겠다.
- 들어가기에 앞서
- NLU ?
- 성능 평가를 부탁해 : Benchmark GLUE
- STS (Semantic Textual Similarity)
- 문제 정의
- 데이터셋 소개
- SOTA 모델 소개
- Reference
🙋♀️ 들어가기에 앞서
STS에 대해 알아보기 전에, 오늘 배운 내용을 간단하게 요약한다.
NLU ?
NLU(Natural Language Understanding), 자연어 이해란 무엇일까?
이해라는 추상적인 개념을 조금 구체적으로 적어보았다.
자연어 이해에는 다음이 속한다.
- syntactic = 문법적으로 옳은 문장인가?
- semantic = 문장의 의미를 아는가?
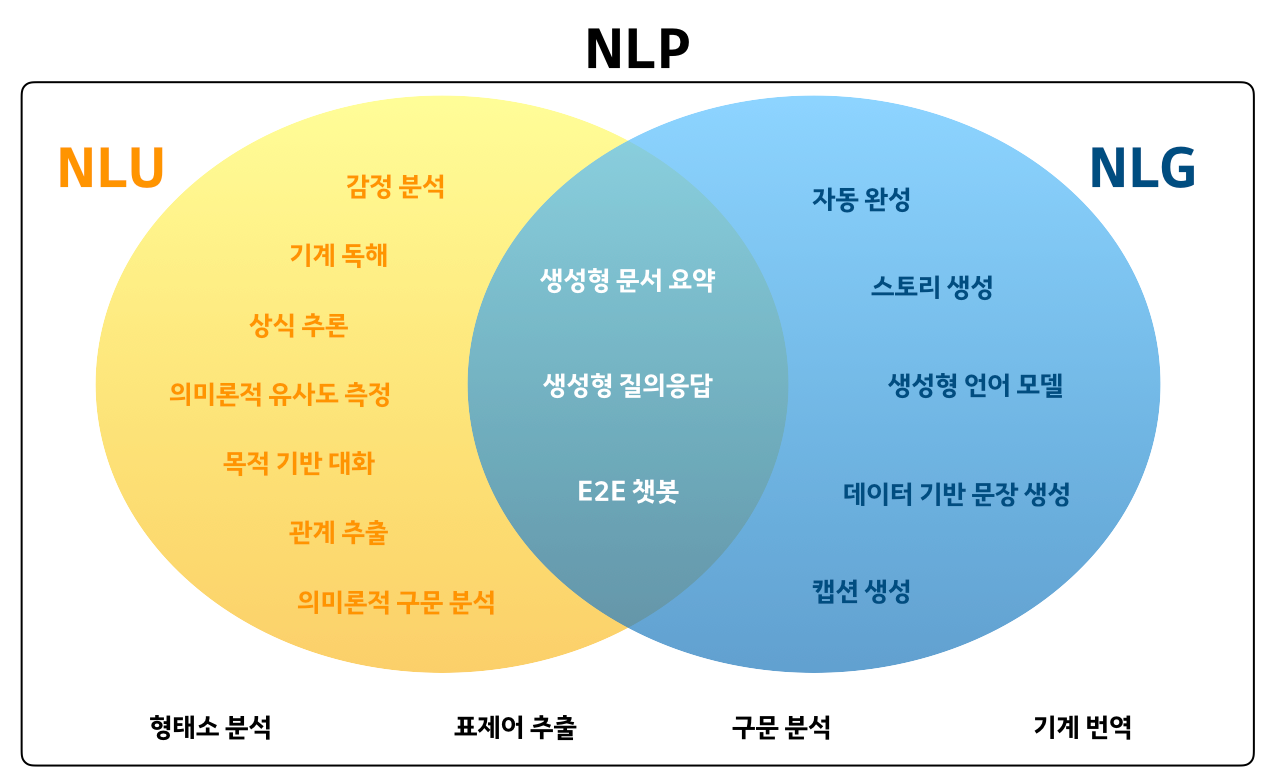
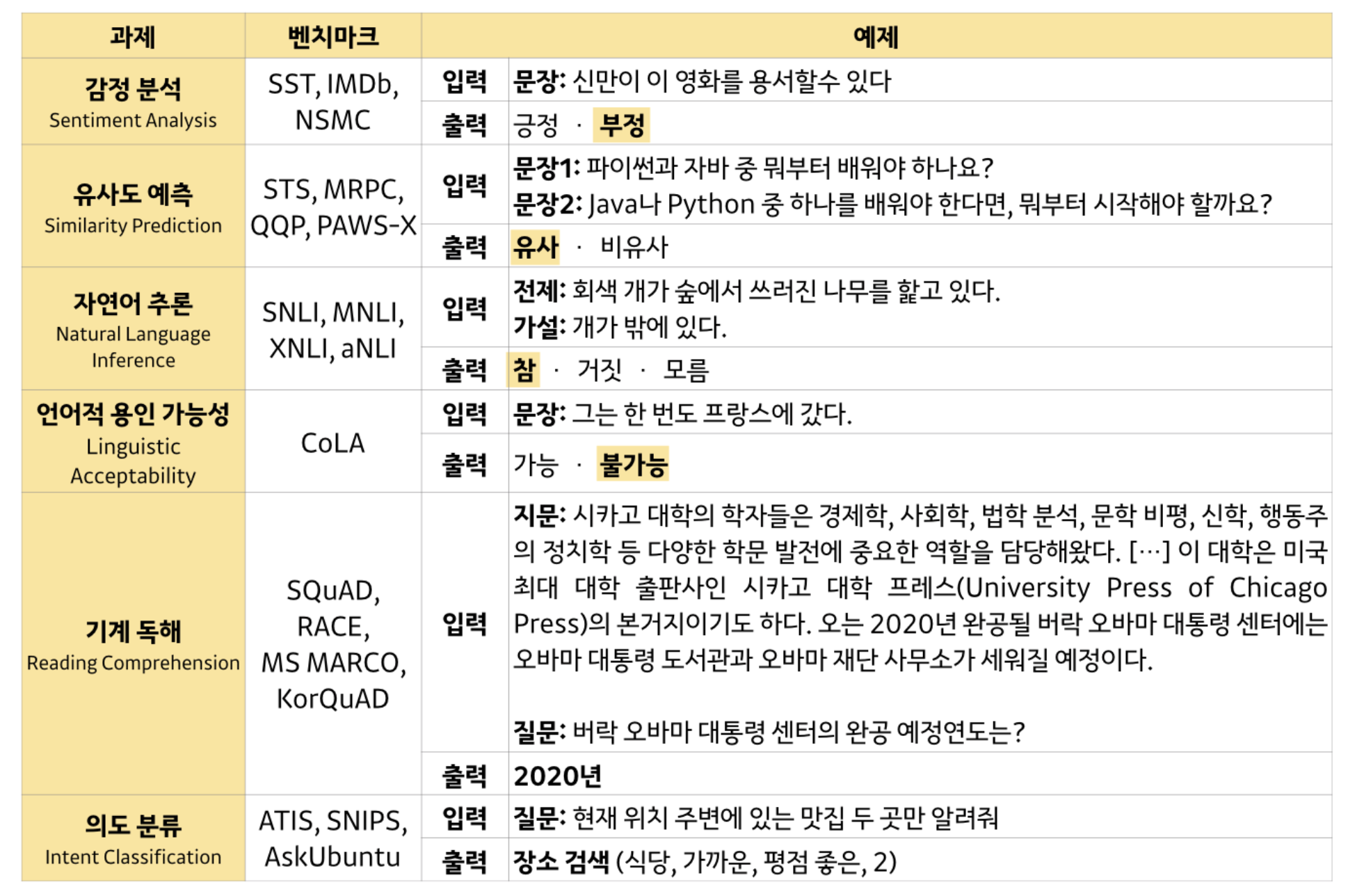
의미 : 감정 분석, 문장간 유사도, 의도 파악, 질의응답, 추론 등...
이는 자연어 처리에서 NLG(자연어 생성)과 비교되는 분야이기도 하다.
자세한 사항은 이 링크를 참고하면 정리가 잘 되어 있다.
성능 평가를 부탁해 : Benchmark GLUE
한가지 task에 맞춰 end-to-end 모델을 만들었던 옛날과는 달리 현재에는 전이학습(transfer learning)모델을 task에 맞게 fine-tuning 해서 사용하는 방식이 많이 사용된다.
GLUE는 이러한 모델(사전 학습된 모델)을 여러가지 NLP task에 대해 시험하여 해당 모델이 얼마나의 성능을 이뤘는지 확인 할 수 있는 지표라고 할 수 있다.
GLUE를 통해 확인할 수 있는 task (출처)
GLUE에 대한 자세한 사항은 이 링크를 참고하면 정리가 잘 되어 있다.
✍️ STS (Semantic Textual Similarity)
그럼 지금부터 STS (Semantic Textual Similarity), 문장이 유사한지를 구하는 task에 대해 글을 써보도록 하겠다.
문제 정의
STS는 바로 위에서 말했다 싶이, 텍스트가 서로 유사한지를 구하는 task이다.
저는 어거스트 러쉬라는 영화를 가장 좋아합니다.
제가 제일 재미있게 본 영화는 어거스트 러쉬입니다.
위의 두가지 문장은 다르지만, 유사하다. 이러한 유사도를 판별해 내는 것이 바로 STS의 목적이다.
실사용 예시
Q&A 코퍼스에서 의미적으로 유사한 질문을 추출한 후, 데이터베이스에서 유사한 문서를 검색하고, 의미적으로 유사한 뉴스 기사를 추천
텍스트의 유사도 판별에는 Jaccard 유사도, cosine 유사도 등의 여러 방법이 있지만, 오늘은 딥러닝을 이용한 유사도 판별 기법에 초점을 맞춰 글을 쓰려고 한다.
데이터셋 소개
데이터셋은 이곳에서 다운받을 수 있다.
나는 STS task를 다루는 중이므로 Name이 Semantic Textual Similarity Benchmark에 해당하는 데이터셋을 다운로드 받았다.
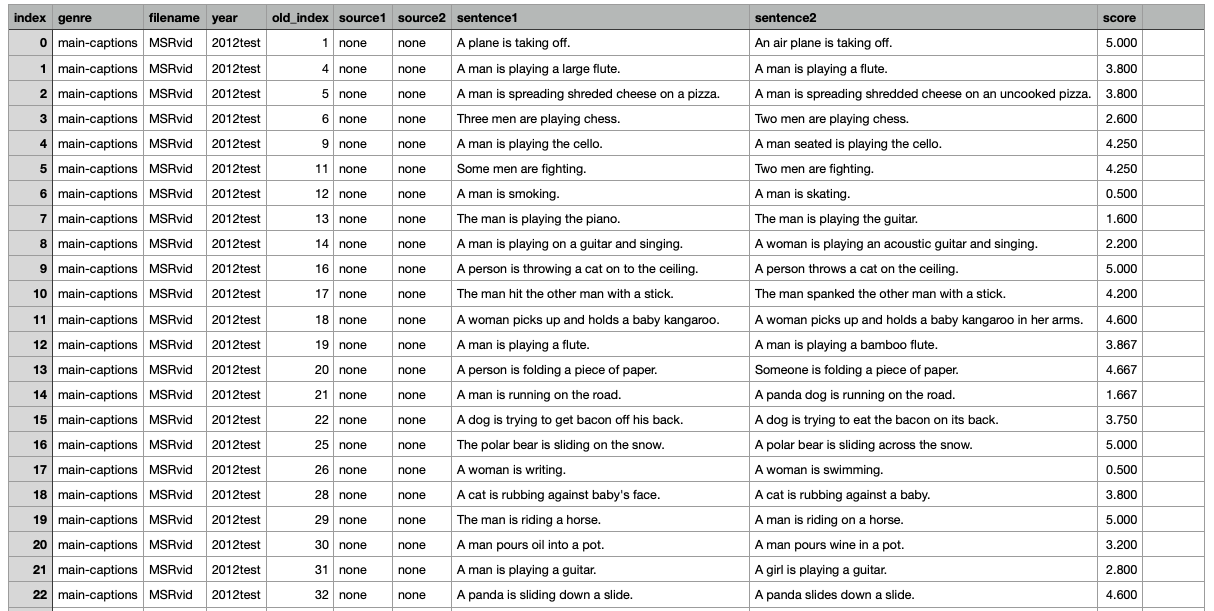
데이터셋을 살펴보면 두개의 문장을 놓고 얼마나 유사한지를 0~5점 사이로 수치화하여 나타내고 있다.
0번 index 문장을 보면
sentence1 : A plane is taking off.
sentence2 : An air plane is taking off.
라는 두가지 문장이 있고, 유사도 score은 5점 만점이다.
6번 index 문장을 보면
sentence1 : A man is smoking.
sentence2 : A man is skating.
이라는 두가지 문장이 있는데 누가 봐도 다른 문장이다. 그래서 그런지 유사도 score은 0.5점이다.
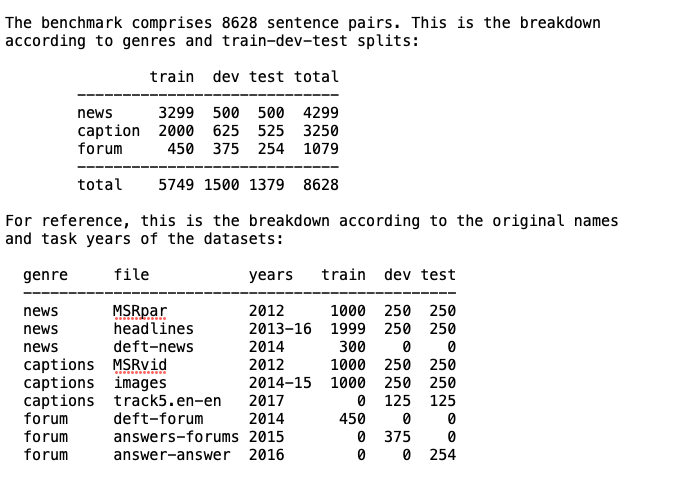
데이터 폴더 안의 README파일을 확인해보니 텍스트는 뉴스나 캡션(자막), 그리고 포럼이 출처임을 알 수 있었다.
SOTA 모델 소개
두가지의 딥러닝 모델을 다룰 것이다. 기본 BERT모델과 GLUE의 STS task에서 현재 기준 랭킹 1위를 달성한 SMART-RoBERTa Large모델(SOTA)이다.
BERT
BERT는 Transformer의 구조를 변형 시켜 만든 사전 학습된 언어 모델이다. 오늘 이야기할 다른 한가지 모델 역시 BERT를 기반으로 하는 모델이므로, 모델에 대해 간단하게 이야기 하고자 한다.
BERT(Bidirectional Encoder Representations from Transformers)라는 이름에서도 알 수 있듯이 Transformer의 Ecoder를 양방향(Bidirectional)으로 이용하는 모델이다. 관련 논문 : BERT
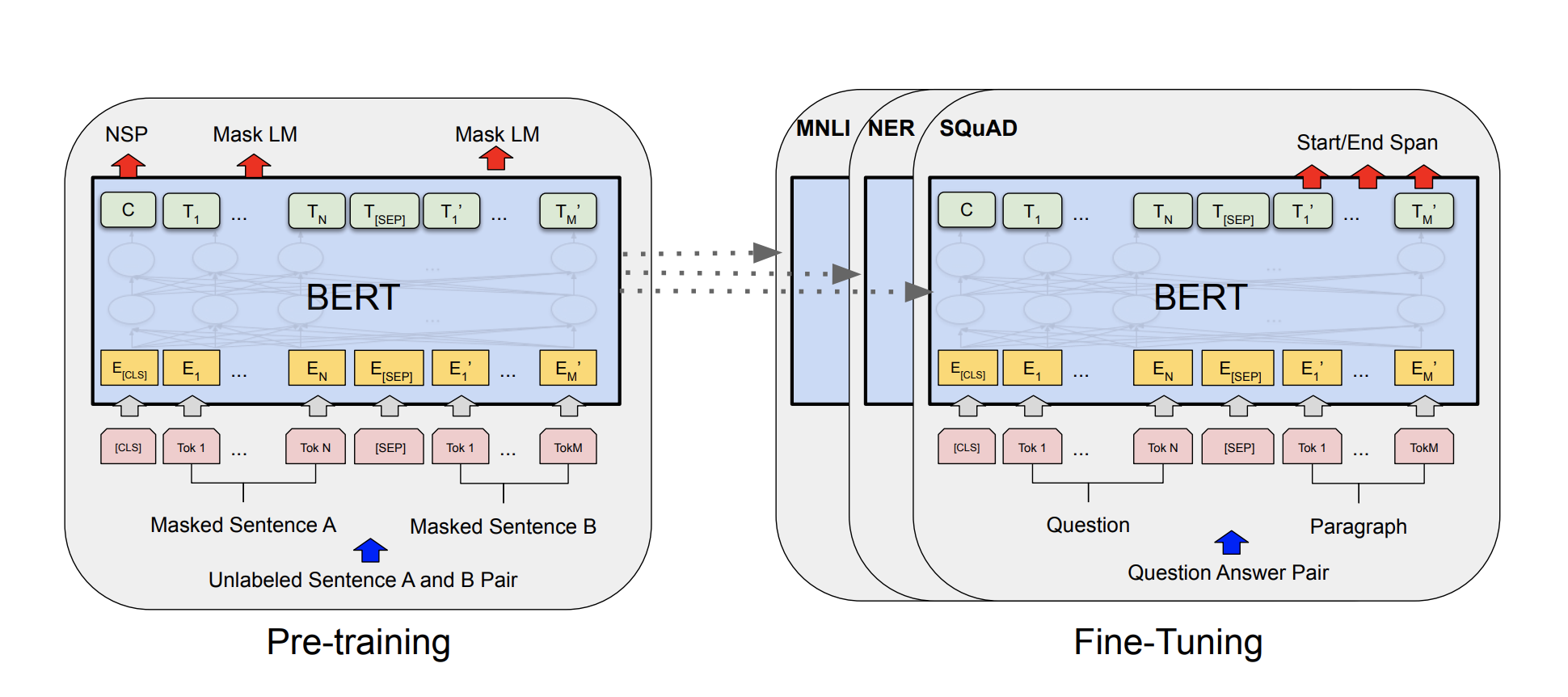
BERT의 구조를 보면 이처럼 임의의 token이 Masked된 문장을 넣어주고 그것을 맞추는 것을 통해 학습을 진행한다.
input값에는 한문장이 들어갈 경우, token간의 상관관계를 구하겠지만, 만약 두문장이 들어갈 경우, 문장간의 상관관계도 구할 수 있다. 이때 input으로 들어가는 두 문장은 모두 masked sentence이다.
참고
이미지의 [cls]와 [sep]은 스페셜 token이다.
[cls]는 classification task를 위한 token
[sep]은 문장을 나눠주기 위한 token
아래 이미지는 STS task에서 BERT를 어떻게 fine-tuning하는지에 대한 정보이다.
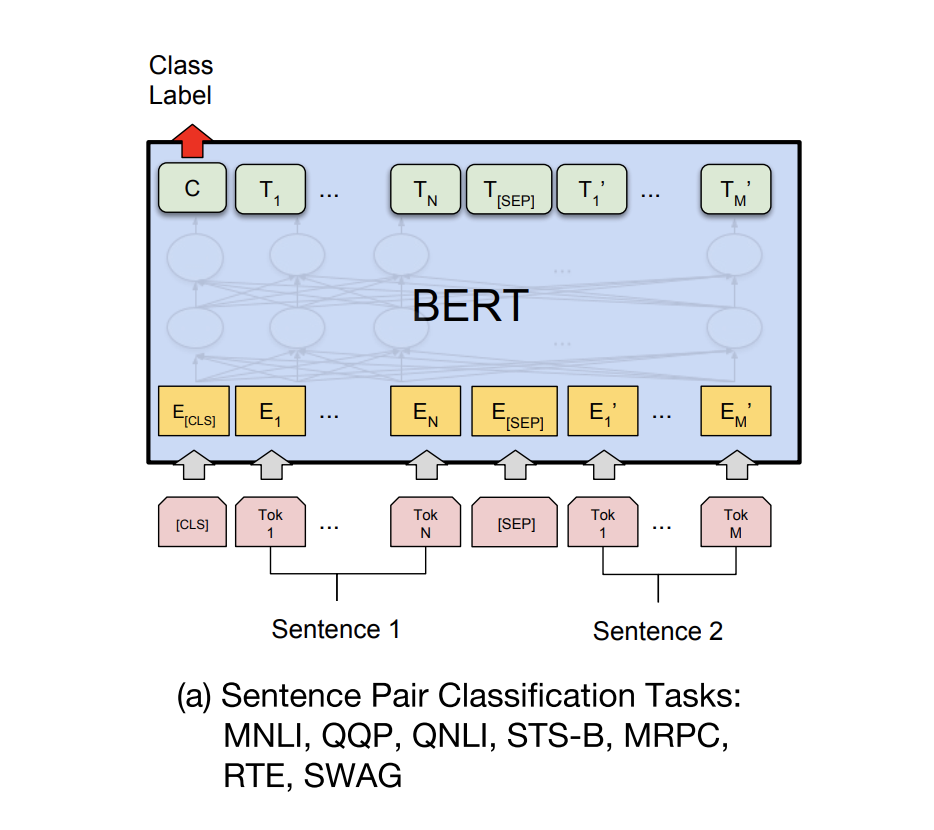
두개의 문장을 [sep]으로 구분하여 input에 넣어주고, 출력값의 첫번째 token인 [cls]에서 두 문장의 관계를 나타내도록 학습시킨다.
다음은 BERT 논문의 keyword이다.
- Transformer
- Attention
- Bidirectional Encoder
- Unsupervised
- masked token
SMART-RoBERTa Large
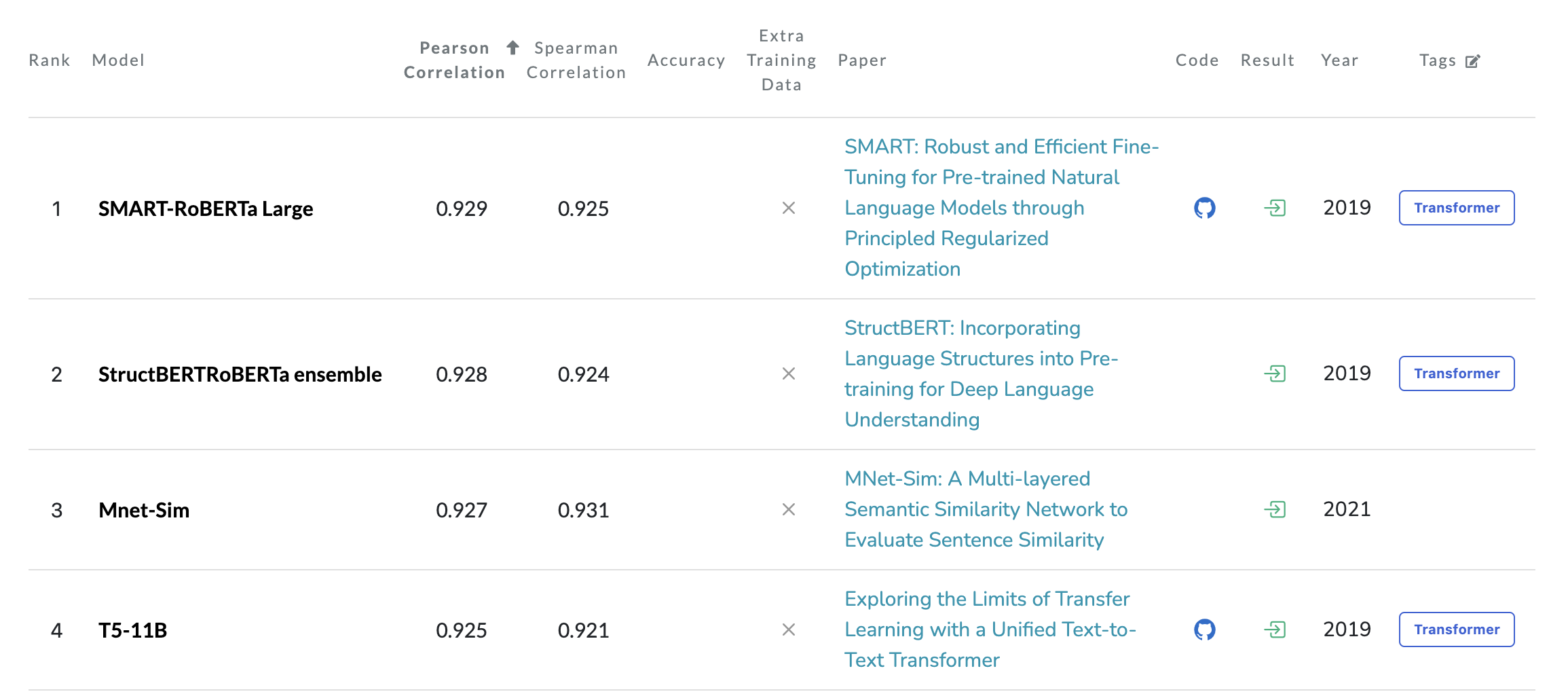
해당 모델은 BERT가 응용된 모델로 GLUE의 STS benchmark에서 가장 높은 순위를 차지한 모델이다. 관련 논문 : SMART-RoBERTa Large
aggressive한 fine-tuning은 모델에게 사전 학습된 지식을 잊게 한다. 이 논문에서는 그에 대한 해결 방안으로 Smoothness-inducing Adversarial Regularization와 Bregman Proximal Point Optimization이 적용된 SMART-RoBERTa Large 모델을 제안했다.
사실 이에 대한 정확한 내용은 구체적으로 파악하지 못했으나, 대략 이해한 바로는 fine-tuning 과정에서 사전 학습된 지식을 덜 잃게 하는 효율적인 방향으로 개선된 모델인 것 같다.
BERT와 응용 모델인 RoBERTa에 대한 비교는 이곳을 참고 바란다.
다음은 SMART-RoBERTa Large 논문의 keyword이다.
- Transfer learning
- control the extremely high complexity
- Smoothness-inducing Adversarial Regularization
- prevent aggressive updating
- Bregman Proximal Point Optimization
🌈 Reference

4개의 댓글

데이터에서 유사도 측정 하는 방법부터 BERT에서 사용하기 위해서 튜닝하는 법까지 알려주셔서 전반적으로 STS를 이해하는데 도움됐습니다~

BERT 모델의 설명을 읽고 SMART-RoBERTa Large 까지 다루어 주셔서 더 연관성 있게 잘 읽었어요
특히 fine-tuning 방법도 추가해 주신게 도움이 되네요!
아까 유사도 관심있다고 하셨는데 아니나 다를까 이 주제로 정리해 주셨네요~! 기업과제랑 직접적으로 연관이 되어있어서 되게 중요한 주제같아요. SOTA 모델들 보니까 성능 차이가 소수점 차이라서, 저는 나중에 모델을 고르게 되면 parameter 수랑 같이 고려해서 고르면 좋을 것 같다는 생각을 했어요. 감사합니다.