MAE(Mean Absolute Error) 값을 찾는다면?
-> mean
왜 오차에 절대값을 적용해 줄까요?
-> 음수가 있으면 정확한 오차를 구할 수 없어서
MAPE 의 값은 작을 수록 잘 예측했다
사용했던 측정 공식 중에 1에 가까울 수록 좋은 모델이고 0에 가까울 수록 잘못 예측한 측정공식은 무엇일까요?
-> r2 score
square 를 해주는 이유?
-> 절댓값을 씌우는 것과 마찬가지로, 부호를 무시할 수 있다
분산은 어떨때 사용할까요?
-> 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자이다
mse 는 분산과 유사한 공식이었어요. rmse 는 어떤 공식과 유사할까요?
-> 표준편차
MAE(Mean Absolute Error)
->
# 예측값과 실제값의 차이에 대한 절대값의 평균
# mae
mae = abs(y_train - y_predict).mean()
maeMAPE(Mean Absolute Percentage Error)
->
# (실제값 - 예측값 / 실제값)의 절대값에 대한 평균
# mape
mape = (abs(y_train - y_predict)/y_train).mean()
mapeMSE(Mean Squared Error) -> 큰 값일수록 패널티 증가
->
# 실제값 - 예측값의 차이의 제곱의 평균
# MAE와 비슷해 보이나 제곱을 통해 음수를 양수로 변환함
# 분산과 유사한 공식
# mse
mse = ((y_train - y_predict) ** 2).mean()
mseRMSE(Root Mean Squared Error)
->
# RMSE
rmse = np.sqrt(mse)
rmse표준 편차(standard deviation)는 분산을 제곱근한 것이다.
분산과 MSE의 차이?
-> 분산은 관측값에서 평균을 뺀 값을 제곱, MSE는 실제값에서 예측값을 뺀 값을 제곱
회귀에서 Accuracy를 사용하지 않는 이유?
-> 소수점 끝자리까지 정확하게 예측하기 어려워서
지금 배우는 MSE와 MAE 같은 지표는 "내가 만든 모델이 잘 예측했나?"라는 질문에서 시작합니다. 그럼 잘 예측했다라고 표현하고 싶은데 어떻게 표현할 수 있을까요?!
-
분류
분류의 경우에는 잘 정답값과 비교해서 많이 맞으면 잘 예측했다라고 말할 수 있겠죠. 이게 accuracy입니다. -
회귀
회귀는 잘 예측했다! 라고 말하기에는 정답값에 딱 맞출 수가 없습니다. 그래서 오차가 적을수록 모델이 잘 예측했다! 라는 가정을 하고 그 오차를 MAE, MSE, RMSE와 같은 지표들이 나온겁니다.
이 맥락을 이해하시고 MAE, MSE, RMSE 등등 지표의 차이를 이해하시는 것이 좋을 것 같습니다.
Subplots
- 칸이 2개인 도화지를 긞
- plt.subplots 결과가 튜플로 나오기 때문에 앞에 것은 Figure, 다음 내용은 AxesSubplot 을 의미.
- fig 는 도화지, axes는 도화지의 갯수 (행,열)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,2))
sns.countplot(x=y_train, ax=axes[0]).set_title("train")
sns.countplot(x=y_test, ax=axes[1]).set_title("test")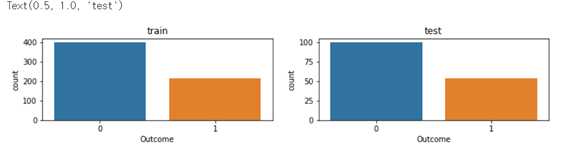
하이퍼파라미터 튜닝
하이퍼파라미터 (Hyper Parameter)
- 머신러닝 모델을 생성할 때 사용자가 직접 설정하는 값으로, 이를 어떻게 설정하느냐에 따라 모델의 성능이 달라집니다.
GridSearchCV()
- 시도할 하이퍼파라미터들을 지정하면, 모든 조합에 대해 교차검증 후 가장 좋은 성능을 내는 하이퍼파라미터 조합을 찾음
RandomizedSearchCV()
- GridSearch 와 동일한 방식으로 사용하지만 모든 조합을 다 시도하지는 않고, 각 반복마다 임의의 값만 대입해 지정한 횟수만큼 평가
GridSearchCV()와 RandomizedSearchCV()에 똑같이 Random 값을 넣었을 때의 다른 점
-> GridSearchCV => 조합의 수 만큼 실행, RandomizedSearchCV => k-fold 수 * n_iter 수 만큼 실행
