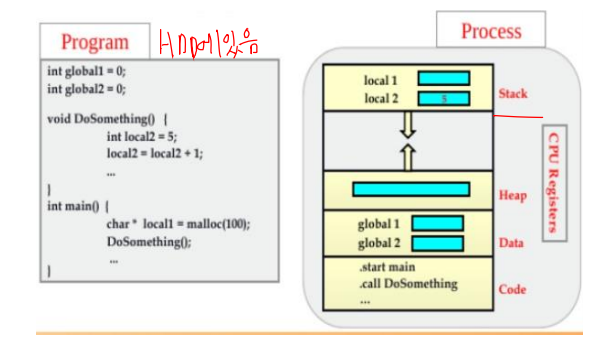
Process Concepts (프로세스 개념)
- 일괄처리 시스템 (Batch system) = jobs
- 시분할 시스템 (Time-shared systems) - user programs or tasks
- 프로세스와 잡을 동일한 개념을 병행 사용한다.
- 실행중인 프로그램은 순차적으로 진행되어야 한다.
- 실행 가능 파일이 메모리에 올라가면 프로그램이 프로세스가 된다.
Process State (프로세스 상태)
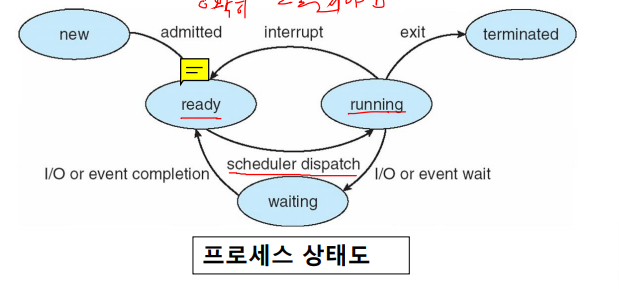
- new : 프로세스가 생성된다.
- running : 명령이 실행된다.
- wating : 프로세스에서 이벤트가 발생하기를 기다린다.
- ready : 프로세스가 (CPU)에 할당되기를 기다리고 있다.
- terminated : 프로세스가 실행을 마친다.
Process Control Block(PCB, 프로세스 제어 블록)

- Process state : running, waiting 등등
- Program counter : 다음 수행할 명령어 주소
- CPU registers : 프로세스 중심의 모든 레지스터의 내용
- CPU scheduling information (CPU 스케줄링 정보) : 우선순위, 큐 포인터 스케줄링
- Memory-management information (메모리 할당 정보) - 프로세스에 할당된 메모리
- Accounting information (회계 정보) - CPU사용, 시작시간부터의 시간 , 시간제한
- I/O Status inforamtion : 입출력 장치들 프로세스 할당, 열려있는 파일 목록
Process Scheduling (프로세스 스케줄링)
- 다중 프로그래밍의 목적은 프로세스를 항상 실행하여 CPU 이용을 최대화 하는 것
- CPU 사용 극대화 , 시간 공유를 위해 시분할 프로세스를 CPU로 신속하게 전환(교체)
- CPU에서 다음 실행을 위해 준비 완료된 프로세스 중에서 프로세스 스케줄러가 선택
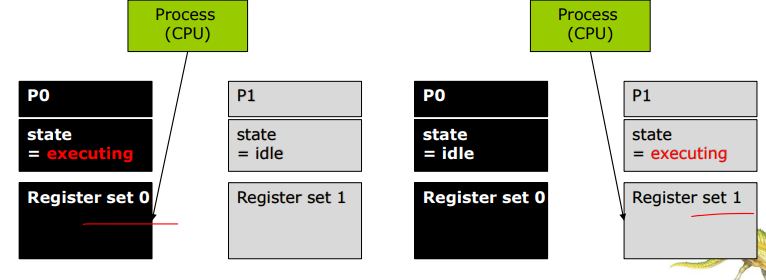
Context Switch (문맥 교환)
CPU가 다른 프로세스로 전환되면
- 시스템은 현재 프로세스의 상태를 저장(백업)해야 한다.
- 전환하려고 하는 새로운 프로세스를 찾아서 로딩해야 한다.
- 이러한 과정을 문맥 교환이라고 한다.
- PCB에 컨텍스트가 하나씩 있다.
- 문맥 교환 동안은 일을 안하는 것과 같기 때문에 오버 헤드에 해당한다.
- 문맥 교환은 현행 레지스터 집합에 대한 포인터를 변경
Process Creation (프로세스 생성)
새로운 프로세스의 주소 공간
- 자식이 부모와 동일한 프로그램과 데이터 사용
- 자식에게 새 프로그램 로드
UNIX 예시
fork system call은 새로운 프로세스를 생성
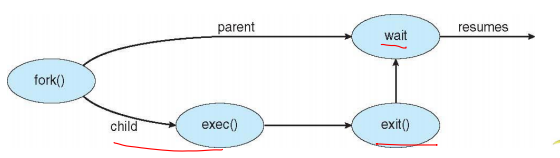
- 부모와 자식 프로세스는 fork후의 명령문에서부터 실행
- fork()의 반환 값 : [부모 - 자식 프로세스의 PID] / [자식 - 0]
- 새로운 실행 파일을 메모리에 적재하고 적재된 프로그램을 실행
Process Termination (프로세스 종료)
- 부모 프로세스는 wait() System call을 이용하여 자식 프로세스의 종료를 대기할 수 있고, 호출은 종료된 프로세스의 상태 정보 및 pid(프로세스 식별자)를 반환한다.
pid_t pid, int status; pid = wait(&status); (회수를 하기 위해 status의 주솟값이 필요하다.)
- 부모가 wait()을 call 하지 않는 상태로 종료된 프로세스는 좀비(zombie)가 된다.
- 부모가 기다리지 않고 종료되면 자식들은 고아(orphan)이 된다.
Interprocess Communication( IPC , 프로세스간 통신)
- 시스템 내의 프로세스는 독립적이거나 협력적일 수 있다.
- 협력 프로세스는 sharing data 등 다른 프로세스에 영향을 미치거나 영향을 받을 수 있음
- 협력 프로세스를 사용하는 이유
- 정보 공유
- 연산 속도 향상
- 모듈화
- 편의성
- 협력 프로세스는 프로세스 간의 상호통신이 필요하다.
- IPC의 두가지 모델
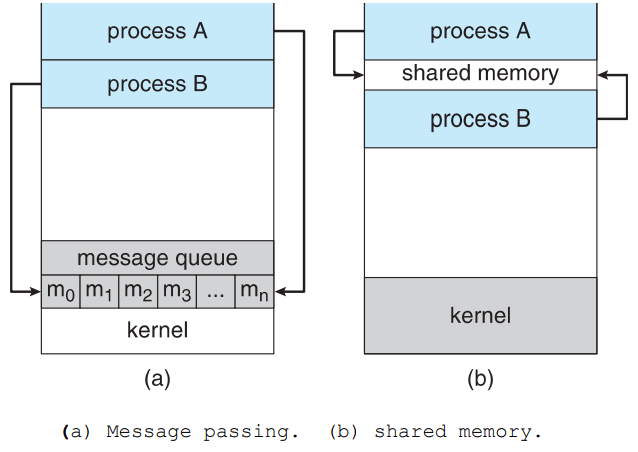
- Shared memory (공유 메모리)
- Message passing (메시지 전달)
Message passing은 커널이 메시지를 처리한다.
Shared memory는 빠르고 커널에 부담이 없다. A가 쓰고 shared영역에서 B에서 가져간다.
IPC - Message Passing (메시지 전달)
- 프로세스가 의사소통하고 작업을 동기화하는 메커니즘
- 메시지 시스템 – 프로세스가 공유 변수에 의존하지 않고 서로 통신한다.
- 메시지 크기가 고정되거나 가변적이다.
- IPC facility는 두 가지 작업을 제공한다.
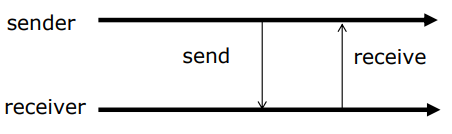
send(message) , receive(message)
직접 통신 (Direct Communication)
- 프로세스는 서로에게 명시적으로 이름을 붙여야 한다
- send(P, message) – process P로 메시지 보내기
- receive(Q, message) – process Q에서 메시지 받기
통신 링크의 속성
- 자동 링크 연결
- 한 쌍이 통신 프로세스만 연관되어 있다.
- 링크는 일반적으로 양방향이지만 단방향일 수도 있다.

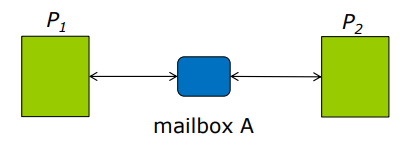
간접 통신 (Indirect Communication)
- 메시지가 메일박스(mailbox), port(포트)라고도 함)에서 지시되고 수신된다.
- 각 메일박스에는 고유 ID(식별자)가 있다.
- 프로세스들은 메일박스를 공유하는 경우에만 통신할 수 있다.
통신 링크의 속성
- 프로세스가 공통 메일박스를 공유하는 경우에만 링크 설정
- 링크는 많은 프로세스와 연관되어 있을 수 있다.
- 각 프로세스 쌍은 여러 개의 통신 링크를 공유할 수 있다.
- 링크는 단방향(단방향) 또는 양방향(양방향)일 수 있다.
Operations (연산)
- 새로운 메일박스를 만든다. (port - 주소 세분화)
- 메일박스를 통해 메시지를 받거나 보낸다.
- 메일박스를 파괴한다.
Mailbox sharing (메일박스 공유)
- P1, P2, P3 공유 메일박스A
P1, 전송;
P2, P3 수신 누가 메시지를 받을까? 라는 문제가 발생한다.해결책
- 링크를 최대 두 개의 프로세스와 연결할 수 있도록 허용
- 한 번에 하나의 프로세스만 수신 작업 실행 허용
- 시스템이 임의로 수신자를 선택할 수 있도록 허용


생산자 소비자 문제
- 협동 프로세스의 일반적인 패러다임
- 공유 메모리의 생산자 프로세스와 소비자 프로세스의 데이터 불일치
- 이를 해결하기 위해 무한 버퍼와 유한 버퍼가 있다.
- 무한 버퍼는 손실은 없지만 무한대기가 발생하고 버퍼의 크기에 제한이 없다고 가정한다.
- 유한 버퍼는 손실은 있지만 무한대기가 발생하지 않고 버퍼의 크기가 고정되어있다고 가정한다.
유한 버퍼 - 공유메모리 해결책
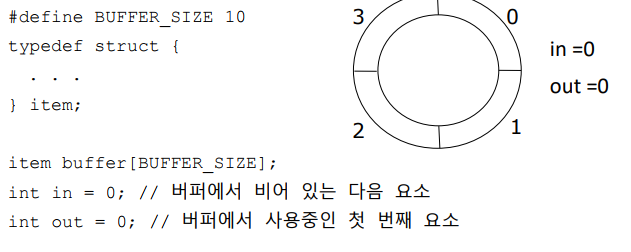
in == out : empty ((in + 1) % BUFFER_SIZE) == out : buffer full
- in과 out이 같으면 버퍼가 빈상태
- in 다음의 위치가 out과 같으면 버퍼가 꽉 찬상태
- 최대 BUFFER_SIZE - 1 개 요소만 저장 가능
유한 버퍼 - Producer(생산자)
item next_produced;
while (true) {
/* produce an item in next produced */
while (((in + 1) % BUFFER_SIZE) == out) //buffer full; /* do nothing */
buffer[in] = next_produced; // 비어 있는 곳에 item 삽입
in = (in + 1) % BUFFER_SIZE; // 다음 비어 있는 원소를 가리킴
} BUFFER_SIZE - 1만큼 사용가능한 이유는?
- 버퍼가 원형(Circular) 구조로 동작하기 때문이다.
- 버퍼가 가득 차 있을 때와 완전히 비어있을 때를 구분하기 위해 한 칸을 항상 비워두어야 한다. 만약 모든 칸이 꽉 차게 되면(in = out), 버퍼가 비어 있는 상태와 헷갈릴 수 있기 때문에 생산자가 불필요하게 데이터를 덮어쓰거나, 소비자가 아직 작성되지 않은 데이터를 읽으려 할 수 있는 것을 방지하기 위해 BUFFER_SIZE -1 만큼 사용가능하다.
유한 버퍼 - Consumer(소비자)
item next_consumed;
while (true) {
while (in == out) // in과 out이 같으면
; /* do nothing */ // 아무것도 하지 않음
next_consumed = buffer[out]; out = (out + 1) % BUFFER_SIZE; // out의 위치를 다음 칸으로 이동
/* consume the item in next consumed */ }동기화(Synchronization)
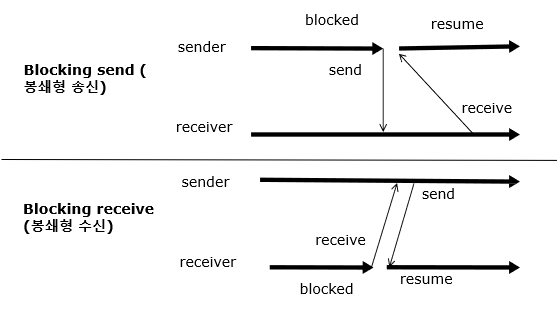
- 메시지 전달(message Passing)은 봉쇄형(blocking)이거나 비봉쇄형(nonblocking) 방식으로 전달, 이 두방식은 동기, 비동기식이라고 부른다.
봉쇄형(Blocking) = 동기식(Synchronous)
- 봉쇄형 송신(Blocking Send)
송신자는 메시지가 수신될 때까지 차단(또는 대기 상태)
송신자가 메시지를 보내고 나면, 그 메시지가 목적지에 도착하고 수신되기 전까지 다른 작업을 진행 하지 않고 기다림- 봉쇄형 수신(Blocking Receive)
수신자는 메시지가 사용 가능할 때까지 차단(또는 대기 상태)
수신자가 메시지를 받을 준비가 되면, 실제로 메시지를 받을 때까진 다른 작업을 진행하지 않고 기다림- 프로세스 간의 통신이 완전히 이루어질 때까지 해당 프로세스의 실행이 일시 중단되므로, 데이터의 일관성과 순서를 보장하는데 유용
- 한 프로세스가 다른 프로세스의 작업 완료를 기다리게 되므로 효율성이 저하될 수 있음
비봉쇄형(Non-Blocking) = 비동기식(asynchronous)
- 비봉쇄형 송신(Non-Blocking Send)
송신자는 메시지를 보내고 대기없이 진행한다.- 비봉쇄형 수신(Non-Blocking Receive)
수신자는 수신하면 유효한 메시지 또는 Null 메시지를 수신한다.
다른 조합이 가능하다.
만약 송신과 수신이 모두 차단되어 있으면 랑데뷰현상이 발생한다.랑데뷰(rendezvous)
- 송신 프로세스가 메시지 보내고 수신 프로세스가 수신되고 처리될 때까지 대기하며 두 프로세스는 특정 시점(메시지 교환 지점)에서 서로를 기다리게 되는 시점
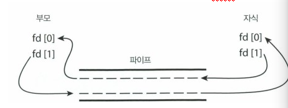
Pipes (파이프)
- 두 프로세스가 통신할 수 있게 하는 통로
- 초기 UNIX에서 제공한 IPC기법으로 현재 윈도우에서도 사용
- 일반 파이프(Ordinary pipes) = 익명 파이프
- 생산자-소비자 형태로 두 프로세스 간의 통신 허용
- 생산자와 소비자는 각 종단으로 나뉘어 쓰고 읽는다.
- 단방향 통신만 가능하며 양방향 통신을 위해 두 개의 파이프를 사용해야 한다.
- 프로세스들이 통신을 마치고 종료하면 일반 파이프는 없어진다.
- 지명 파이프(Named Pipes) = FIFO
- 관련 없는 프로세스 간에도 통신을 가능하게 함
- 양방향 통신이 가능해서 부모,자식 관계가 필요하지 않음
- 프로세스 통신이 종료되어도 보통 파일처럼 존재
Threads (쓰레드)
- 스레드는 프로세스 내에 잇는 것으로 CPU이용의 기본 단위다.
- 스레드 ID, 프로그램 카운터, 레지스터 집합, 스택으로 구성되어 있다.
- 보다 가벼운 프로그램을 위해 프로세스 내부의 쓰레드를 여러개 만들어서 쓴다.
- context switching(문맥 교환)을 통해 보다 더 경제성있게 프로세스를 운용하고 멀티코어를 이용해 병렬실행과 병행실행이 가능하다.
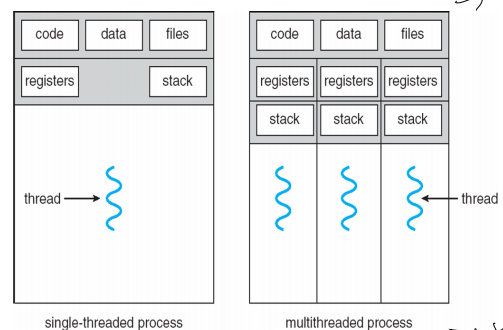
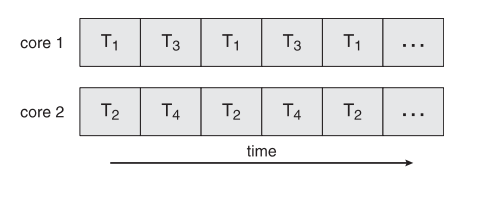
병렬 실행과 병행 실행
- Parallelism(병렬 실행) - 한시점에 여러 개 작업을 동시에 실행한다.
- Concurrency(병행 실행) - 한 개 이상의 작업이 수행되게 한다.

암달 법칙(Amdahl's Law)
- 병렬화된 시스템에서 순차적으로 실행되어야 하는 구성요소가 있는 경우, 코어를 추가해 얻을 수 있는 잠재적인 성능 향상을 나타내는 공식
- Speedup은 전체 응용의 실행 시간 감소 비율 또는 성능 향상 비율을 나타냄
- P는 병렬화 가능한 부분의 비율(0 ≤ P ≤ 1)로, 전체 작업 중 실제로 병렬화할 수 있는 부분의 비율
- N은 시스템에 사용 가능한 총 처리 코어의 개수
- N이 무한대에 가까워지면 속도는 1/S에 수렴
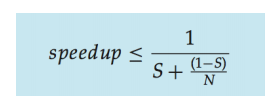
- if application is 75% parallel / 25% serial, moving from 1 to 2 cores results in speedup of 1.6 times
- 해당 응용 프로그램은 75% 병렬화 가능하고 25%는 순차적으로 실행되어야 하는 구성요소로 구성, 1개의 코어에서 2개의 코어로 이동할 경우 속도 향상이 1.6배가 발생
- 계산 : Speedup = 1 / [(1 - P) + (P / N)]
= 1 / [(1 - 0.75) + (0.75 / 2)]
= 1 / [0.25 + (0.75 /2)]
= 1 / [0.25 + 0.375]
= 1 / [0.625]
≈ 1.6- 코어 개수가 1개에서 2개로 증가한다면, 속도 향상은 약 "1.6배"
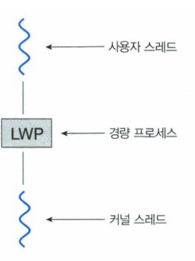
LWP(lightweight process)
- LWP 혹은 경량 프로세스라고 부르는 자료구조는 사용자와 커널 스레드 간의 중간 자료구조로서 동작하고, 가상프로세스처럼 보여지며 사용자 스레드를 실행할 수 있도록 예약할 수 있다.
- 스케줄러 액티베이션(Scheduler Activation)은 사용자 스레드 라이브러리와 커널 스레드 간의 통신 방법이다.
- 커널은 응용에 가상 처리기(LWP)의 집합을 제공
- 응용은 사용자 스레드를 가상 처리기에 스케줄링
- 커널은 특정 이벤트가 발생할 때 응용에게 알림 -> 이때 사용되는 프로시저 "업콜(upcall)“
- 업콜은 스레드 라이브러리의 업콜 처리기에 의해 처리되며, 해당 처리기는 가상 처리기에서 실행

학생의 자세로 살아가는 개발자