1. jpa프로젝트 환경 설정
DB를 포커스를 둔 프로젝트를 할 것이다.
기본 셋팅은 똑같고
Lombok, Spring Web, Spring Data JPA, Thymeleaf, Oracle Driver
5개 해준다.
똑같이 임포트해주고 애플리케이션 프로퍼티즈는 웹에있던걸로 복붙.
core2에 있던 애플리케이션 프로퍼티즈 #DB Connection 부분 5줄 복붙
서버가동해서 index.html파일 만든거 잘 나오는지 확인하기
2. JPA
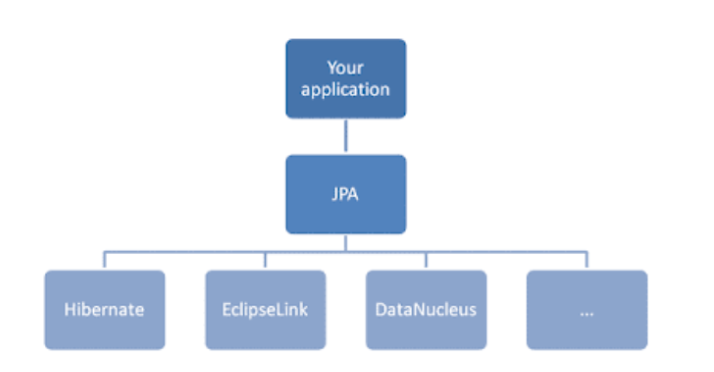
2-1. JPA란
- Java Persistence API
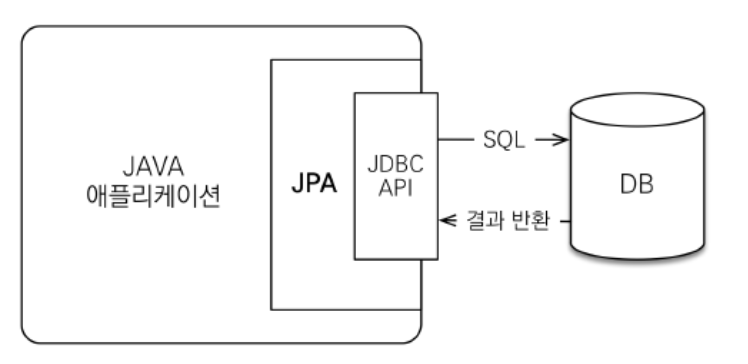
- java 진영에서 ORM(Object-Relateinal Mapping) 기술 표준으로 사용하는 인터페이스 모음
- 자바 어플리케이션에서 관계형 데이터 베이스를 사용하는 방식을 정의한 인터페이스
2-2. ORM(Object-Relateinal Mapping)
- 우리가 일반적으로 알고있는 애플리케이션 class와 RDB(Relational DataBase)의 테이블을 매핑(연결)한다는 뜻이며, 기술적으로는 어플리케이션의 객체를 RDB테이블에 자동으로 영속화 해주는 것이라고 보면 된다.
- 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말한다.
- 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용한다.
- 객체 모델과 관계형 모델 간에 불일치가 존재한다.
- ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결한다.
- 데이터베이스 데이터 <----mapping----> object 필드
- 객체를 통해 간접적으로 데이터베이스의 데이터를 다룬다.
우리는 Hibernate라는 곳에서 구현해놓은 기술을 가져다 쓸 것이다.
보통 Hibernate를 많이 사용한다.
2-3. 장점
- SQL문이 아닌 method를 통해 DB를 조작할 수 있어, 개발자는 객체 모델을 이용하여 비지니스 로직을 구성하는 데만 집중할 수 있다.
- 내부적으로는 쿼리를 생성하여 DB를 조작함. 하지만 개발자는 이를 신경쓰지 않아도된다.
- Query와 같이 필요한 선언문, 할당 등의 부수적인 코드가 줄어들어, 각종 객체에 대한 코드를 별도로 작성하여 코드의 가독성을 높인다.
- 객체지향적인 코드 작성이 가능하다. 즉 생산성이 증가한다.
- 매핑하는 정보가 Class로 명시되었기 때문에 ERD를 보는 의존도를 낮출 수 있고, 유지보수 및 리팩토링에 유리하다.
- 예를들어 기존 방식에서 MySQL 데이터베이스를 사용하다가 PostgreSQL(대용량 DB를 처리할 때 좋음. 제일 빠르다)로 변환한다고 가정해보면, 새로 쿼리를 짜야하는 경우가 생긴다. 이런 경우에 ORM기술을 사용하면 쿼리를 수정할 필요가 없다.
- 프로젝트와 DB 간에 JPA가 중간에 필터마냥있는데 DB가 바뀌는 거에 상관없이 JPA가 알아서 데이터를 찾아와준다.
2-4. 단점
- 프로젝트의 규모가 크고 복잡하여 설계가 잘못된 경우에 속도 조하 및 일관성을 무너뜨리는 문제점이 생길 수 있다.
- 복잡하고 무거운 Query는 속도를 위해 별도의 튜닝이 필요하기 때문에 결국엔 SQL문을 써야할 수도 있다.
- 학습비용이 비싸다.(배우기 어렵다)
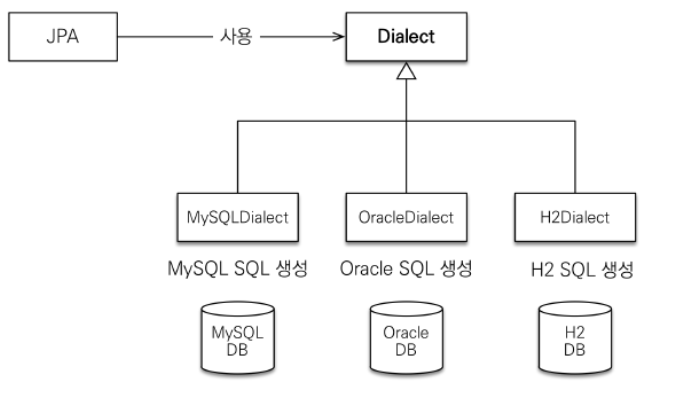
- 데이터베이스 방언
- JPA는 특정 데이터베이스에 종속 되지 않는다.
- 각각의 데이터베이스가 제공하는 SQL문법과 함수는 조금씩 다르다.
- 가변문자 :
Oracle 에서는 varchar2
MySQL 에서는 vharchar - 문자열을 자르는 함수 :
Oracle에서는 substr()
SQL표준 에서는 substring() - JPA를 쓴다는 것은 Oracle 이라는 사투리를 써서 쿼리를 작성해 라는 뜻이다.
프로젝트로 들어가서
애플리케이션 프로퍼티즈
#DB Connection 부분 주석처리하고
리소스 밑에다가 META-INF라는 폴더 만들고 XML형식의 파일을만든다.
persistence.xml
밑에 디자인보기 방식 말고 Source보기 방식의 탭을 고른다.
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver" value="oracle.jdbc.driver.OracleDriver" />
<property name="javax.persistence.jdbc.user" value="jpa" />
<property name="javax.persistence.jdbc.password" value="jpa" />
<property name="javax.persistence.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.dialect" value="org.hibernate.dialect.Oracle10gDialect" />
<!-- <property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQL10Dialect"/> -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- 옵션 -->
<!-- 콘솔에 하이버네이트가 실행하는 SQL문 출력 -->
<property name="hibernate.show_sql" value="true" />
<!-- SQL 출력 시 보기 쉽게 정렬 -->
<property name="hibernate.format_sql" value="true" />
<!-- 쿼리 출력 시 주석(comments)도 함께 출력 -->
<property name="hibernate.use_sql_comments" value="true" />
</properties>
</persistence-unit>
</persistence>이거 복붙한다.
필수 속성 부분에 jpa가 아이디 비번이라 우리같은 경우에는 spring으로 바꿨다.
주석 처리된 부분에는 PostgreSQL할때 바꾸는 것을 할거라 나중에 해볼것임
com.codingbox.jpa패키지 밑에다가 Member라는 클래스를 만들었다.
4. JPA 사용
- @Entity : JPA가 관리할 객체
- @Id : 데이터 베이스 PK와 매핑
JpaMain을 만들었는데 오랜만에 메인 메서드가 있는 채로 만든다.
하다가 갑자기
xml파일에서
<property name="hibernate.hbm2ddl.auto" value="none" />으로 바꾼다
create면 새로만드는 거고 none면 있던거에서 덮어쓰는기능이다.
-----day08끝----09시작--- 너무많으니까 그냥 1부터 다시가자.
-
JpaMain.java에서 페이징 처리하는 부분과 select부분을 추가해주었다.
-
persistence.xml 에서 어제잠깐이야기했던 오라클다이얼렉 주석처리하고 포스트그레스 sql주석풀어서 확인만 해보았다. 하지만 우린 postgresql을 설치안했으니까 에러가 날것이다. 그냥 다시 오라클로 바꿨다.
1. JPQL
- JPA를 사용하면 엔티티 객체를 중심으로 개발
- 문제점은 검색 쿼리이다.
- 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
- 모든 DB데이터를 객체로 변환해서 검색하는 것은 불가능
- 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL 이 필요
- JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어 제공
- SQL과 문법이 유사, select, from, where, group by, having, join 지원한다.
- JPQL은 엔티티 객체를 대상으로 쿼리를 작성한다.
- SQL은 데이터 베이스 테이블을 대상으로 쿼리를 작성한다.
- 한마디로 정의하자면 객체 지향 SQL문이다.
2. JPA에서 가장 중요한 2가지
2-1. 객체와 관계형 데이터베이스 매핑하기(Object Relational Mapping)
3. 영속성 컨텍스트
- JPA를 이해하는데 가장 중요한 용어
- "엔티티를 영구 저장하는 환경"이라는 뜻
- EntityManager.persist(entity);
-> "entity"에 들어가는 객체를 DB에 저장하는 구나 싶은데 좀 더 깊은 의미가 있다.
-> 처음부터 DB에 저장하는 것이 아니라 영속성 컨텍스트라는 곳에 저장한다.
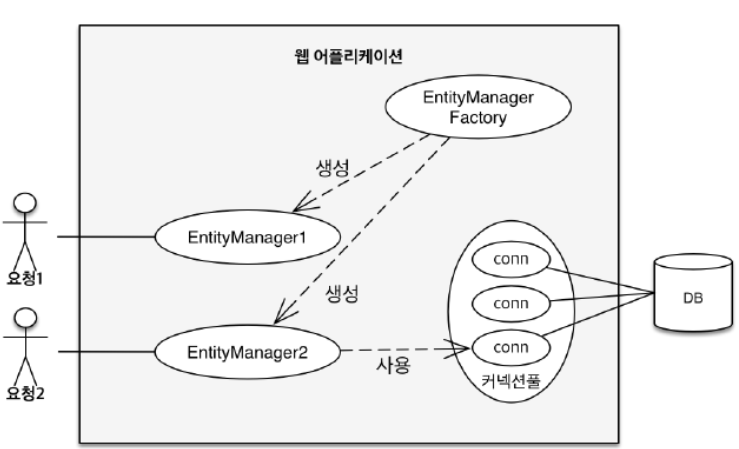
4. 엔티티메니저 vs 영속성 컨텍스트
- 엔티티 매니저를 통해서 영속성 컨텍스트라는 공간에 접근할 수가 있다.
- 영속성 컨텍스트는 논리적인 개념
- 눈에 보이지 않는다.
5. 엔티티 생명주기
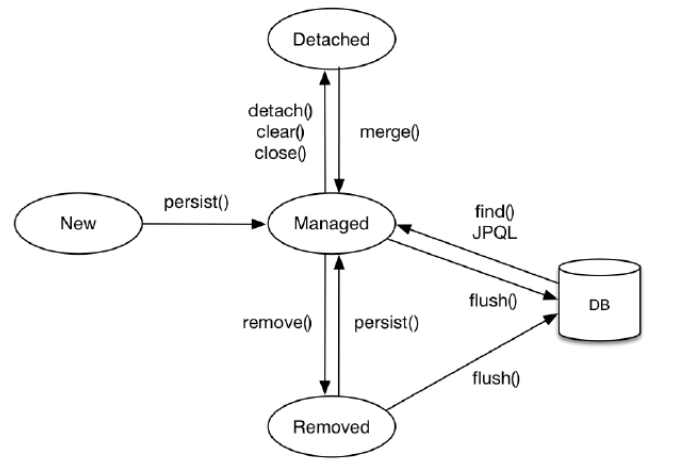
-
비영속(new/transient)
영속성 컨텍스트와 전혀 관계가 없는 새로운 상태

-
영속(managed)
영속성 컨텍스트에 관리되는 상태

-
준영속(detached)
영속성 컨텍스트에 저장되었다가 분리된 상태 -
삭제(removed)
삭제된 상태
6. 영속성 컨텍스트의 이점
- 1차 캐시
- 동일성(identity)보장
- 트랜잭션을 지원하는 쓰기 지연(Transacional write-behind)
- 변경감지(Dirty Checking)
- 지연로딩(Lazy Loading)
6-1. 1차 캐시
-
영속성 컨텍스트와 식별자 값
-> 엔티티를 식별자 값(@Id로 테이블의 기본 키와 미핑한 값)으로 구분
-> 영속 상태는 식별자 값이 반드시 있어야 한다.
-> 식별자 값이 없으면 예외 발생
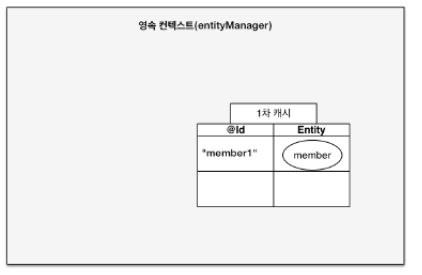
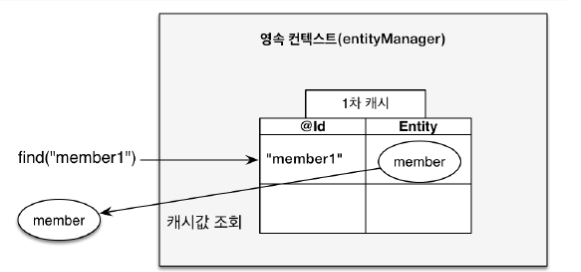
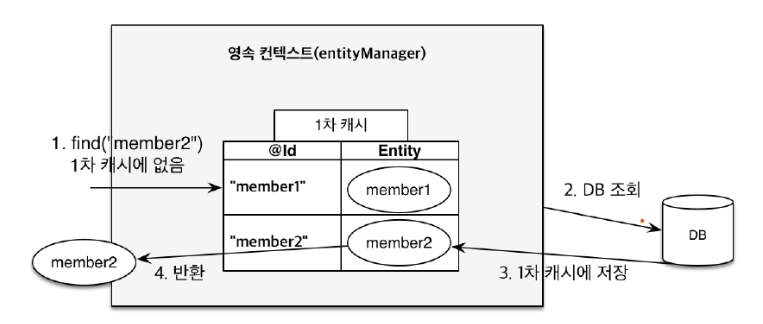
-
영속성 컨텍스트와 데이터베이스 저장
-> JPA는 보통 트랜젝션을 커밋하는 순간 영속성 컨텍스트에 새로 저장된 엔티티를 데이터베이스에 반영
-> 플러쉬(flush)
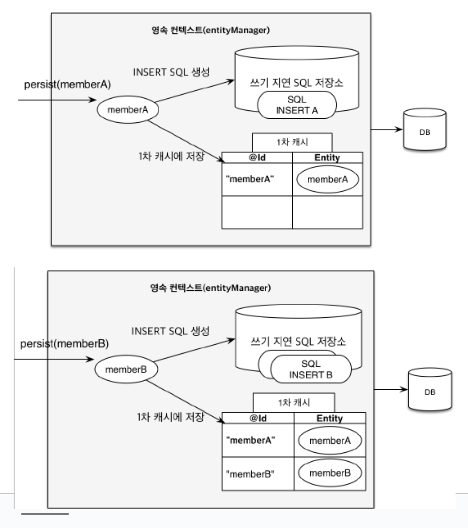
6-2. 트랜잭션을 지원하는 쓰기 지연(Transacional write-behind)
tx.begin();
em.persist(memberA);
em.persist(memberB);
// 여기까지 insert SQL을 데이터베이스에 보내지 않는다.
tx.commit();
// commit하는 순간 데이터베이스에 Insert SQL을 보낸다.
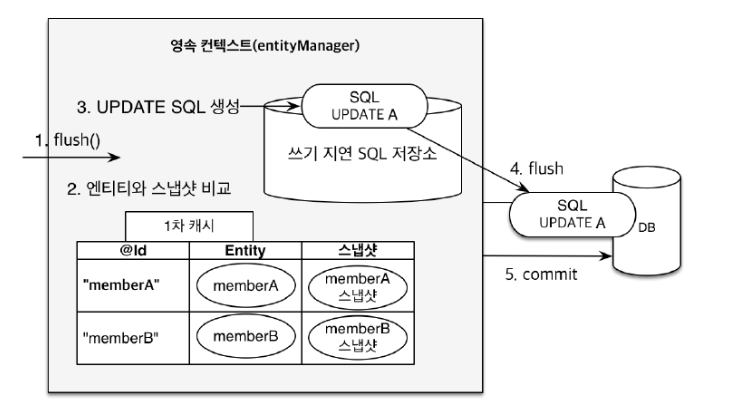
6-3. 변경감지(Dirty Checking)
tx.begin();
//조회
Member memberA = em.find(Member.class, "memberA");
//영속 엔티티 데이터 수정
memberA.setUsername("hi");
memberA.setAge(10);
//em.update(member); // 뭐 이런 코드가 있어야할 느낌인데 이런 코드 없이도 update가능하다.
tx.commit();
- flush()가 호출되는 시점에 Entity와 스냅샷을 전부 비교 후 변경이 된 것을 감지(Dirty Checking)한 후에 update쿼리를 작성한다.
update 쿼리를 날린다.
6-4. 지연로딩(Lazy Loading)
이건 나중에~
- 쓰기 지연 여기가 맞나?
7. flush
7-1. flush란
- 영속성 컨텍스트의 변경내용을 데이터베이스에 반영
7-2. flush 발생
- 변경 감지
- 수정된 엔티티 쓰기 지연 SQL저장소에 등록
- 쓰기 지연 SQL저장소의 쿼리를 데이터베이스에 전송
7-3. 영속성 컨텍스트를 플러시 하는 방법
- em.flush() -> 직접 호출
- 트랜잭션 커밋 -> 플러시 자동호출
- JQPL 쿼리 실행 -> 플러시 자동호출
7-4. 플러시의 역할
- 영속성 컨텍스트를 비우지 않음
- 영속성 컨텍스트이 변경 내용을 데이터 배이스에 동기화
7-5. 준영속 상태
(영속상태: 1차 캐시 상태)
- 영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)
- 영속성 컨텍스트가 제공하는 기능을 사용 못함
7-6. 준영속 상태로 만드는 방법(알아만 둘 것)
- em.detach(entity) : 특정 엔티티만 준영속 상태로 전환
- em.clear(); : 영속성 컨텍스트를 완전히 초기화
- em.close(); : 영속성 컨텍스트를 종료
8. 엔티티 매핑 소개
- 객체와 테이블 매핑 : @Entity, @Table
- 필드와 컬럼 매핑 : @Column
- 기본 키 매핑 : @Id
- 연관관계 매핑 : @ManyToOne, @JoinColumn
9. @Entity
- @Entity 가 붙은 클래스는 JPA가 관리, 엔티티라고한다.
- JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 가 필수 이다.
- 주의 사항
-> 기본생성자가 필수이다(파라미터가 없는 public 또는 protected 생성자) - 저장필드에 final 사용할 수 없다.
- final 클래스, enum, interface클래스는 사용할 수 없다.
9-1. 속성
- name속성
- JPA에서 사용할 엔티티 이름을 지정한다.
- 기본값 : 클래스 이름을 그대로 사용한다. 같은 클래스 이름이 없으면 가급적 기본값을 사용한다.
10. @Table
- @Table 엔티티와 매핑할 테이블을 지정하는 것이다.
+사진
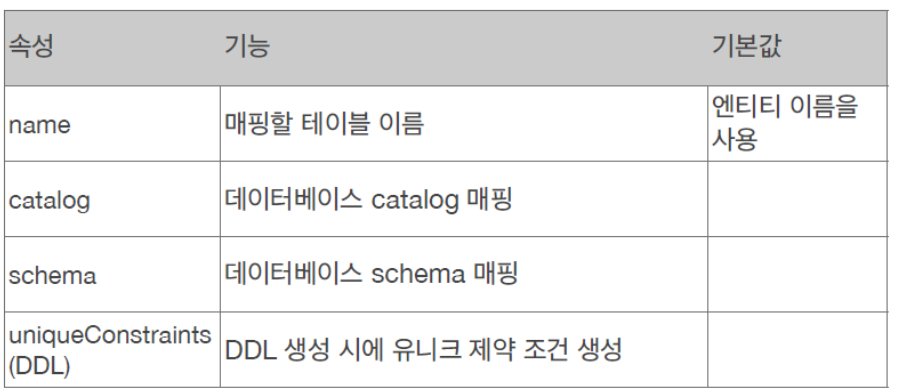
STS로 돌아와서 Member.java에
@Table(name="MBR")
를 추가했다.
import javax.persistence.Table;
이거를 임포트해야한다.
11. hibernate.hbm2ddl.auto
persistence.xml을 본다.
hibernate.hbm2ddl.auto라는 속성이 있다.
- DDL명령어에 대한 자동생성 여부
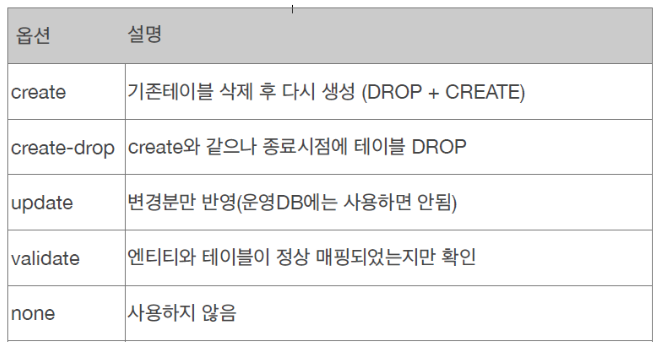
개발단계에서는 보통 create을 사용한다. create와 none을 많이 사용한다.
----------------점심
다시 create로 만들어주고 Member테이블에 추가했던 name을 주석처리해주었다
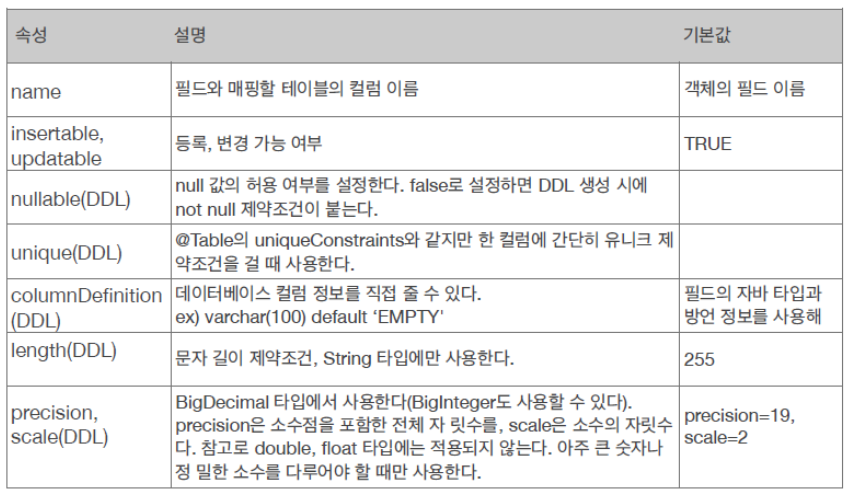
12. DDL생성 기능
- 제약 조건 추가 : 회원이름을 필수, 10자 초과되지않도록 하자
=> @Column(nullable=false, length=10)
- 유니크 제약 조건 추가
-> @Table(uniqueConstraints={
@UniqueConstraint(name="NAME_AGE_UNIQUE", columnNames={ "NAME", "AGE" })
})
DDL생성기능은 DDL을 자동 생성할 때만 사용되고, JPA의 실행 로직에는 영향을 주지 않는다.
- Member.Class 에서 어노테이션넣어서 추가해준다.
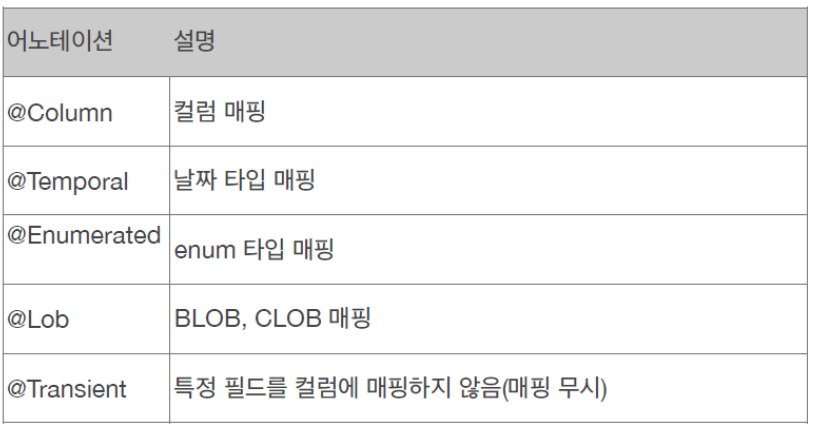
13. @Column
- 이건 많이 사용하니까 알아두자
14. @Transient
- 필드 매핑 X
- 데이터 베이스에 저장X, 조회X
- 주로 메모리상에서만 임시로 어떤 값을 보관하고 싶을 떄 사용한다.
Member2.java만들었다.
15. 기본 키 매핑
-
@Id : 직접 할당
-
@GeneratedValue : 자동 생성
-> IDENTITY : 데이터베이스에 위임
-> SEQUENCE : 데이터베이스 시퀀스 오브젝트 사용
ORACLE(@SequenceGenerator 라는 어노테이션이 필요하다)
-> TABLE : 키 생성용 테이블 사용, 모든 DB에서 사용 가능
@TableGenerator 라는 어노테이션이 필요하다
-> AUTO : 방언에 따라 자동 지정, 디폴트 즉 기본값이다.
JPA가 그러려고 쓰는거니까 그냥 AUTO로 하면되지않냐? ㅇㅇ맞다 AUTO가 위 3개중 하나를 선택해줌
AUTO는 DB방언에 맞춰서 IDENTITY, SEQUENCE, TABLE 세개 중 하나가 선택이 된다.
