1. Ocracle data type
- 칼럼에 적을 수 있는 datatype 은 VARCHAR2, NUMBER, Date가 대표적이고 그 외에 사실은 많이 있다.
1-1. 데이터 타입
- 데이터 타입이란 컬럼이 저장되는 데이터 유형을 말한다.
- 기본 데이터 타입은 문자형, 실수, 소수, 자료형등의 여러 데이터를 식별하는 타입이다.
1-2. 문자 데이터 타입

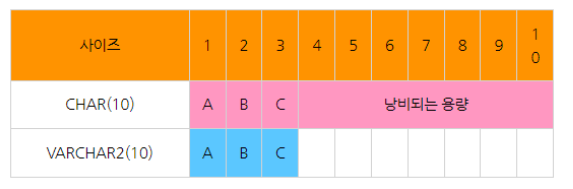
- character VS varchar2 : varchar2는 가변길이로 저장된다.
1-3. 숫자형 데이터 타입

- 대부분 NUMBER형을 사용한다.
- P는 소숫점을 포함한 전체 자릿수를 의미하고, S는 소숫점 자릿수를 의미한다.
- NUMBER는 가변숫자이므로 P와S를 입력하지 않으면 저장데이터의 크기에 맞게 자동으로 조절된다.
- 메모리 너무 아낄 필요는 없다.
- 하지만 그럼에도 불구하고 알고는 있어야 하므로 몇가지 P,S예제를 보자.
입력값 타입 저장되는 값
123.89 NUMBER 123.89
123.89 NUMBER(3) 124 //자연스럽게 반올림을 해서 넘겨준다.
123.89 NUMBER(3,2) 오류
123.89 NUMBER(4,2) 오류
123.89 NUMBER(5,2) 123.89
123.89 NUMBER(6,1) 123.9
123.81 NUMBER(6,1) 123.8? //직접 해봐라.. 1-4. 날짜 데이터 타입

- 대부분의 날짜 데이터 타입은 DATE타입이다.
1-5. LOB데이터 타입

- LOB : Large Object의 약자로 대용량 데이터를 처리할 수 있는 데이터타입이다. 하지만 사용하는 경우가 드물다.
2. DDL(Data Definition Language) 데이터 명령어
데이터의 구조를 정의하기 위한 테이블 생성, 삭제와 같은 명령어
- create : 테이블 생성
- drop : 테이블 삭제
- alter : 데이블 수정
- turncate : 테이블에 있는 모든 데이터 삭제
3. DML(Datat Manipulation Language) 데이터 조작어
-
데이터 조회 및 변형을 위한 명령어
-
select : 데이터 조회
-
insert : 데이터 입력
-
update : 데이터 수정
-
delete : 데이터 삭제
-
insert into 테이블명 values (값1, 값2,---) : 전체칼럼
-
insert into 테이블명 values (칼럼1, 칼럼2,---) values(값1, 값2) : 특정 킬럼
-
update 테이블 명 set 칼럼1 = 값1, 칼럼2 = 값2,...
보통은 이런 식으로 WHERE 절과 같이 쓰임 -
delete 테이블명 where 조건...;
4. drop VS truncate vs delete
4-1. drop
- drop table 테이블명
- 존재 자체가 삭제
- 로그를 남기지 않는다.
4-2. truncate
- 데이터만 통 삭제
trunate 는 테이블이 삭제되는 며영어는 아니고 안에 들어있던 모든 레코드들을 제거하는 명령어이다.
작동 메커니즘 : 테이블을 drop 했다가 - 로그를 남기지 않는다.
(필기)옮겨적야아함 - 로그를 남기지 않는다.
4-3. delete
- delete는 조건에 해당하는 것만 지울 수도 있고 전체를 지울수도 있는 이유가 한 줄 한 줄 삭제하기 때문이다.
조건에 해당하는 것만 지울 두 있다. - 로그를 남긴다.
5. commit 과 rollback
5-1. commit
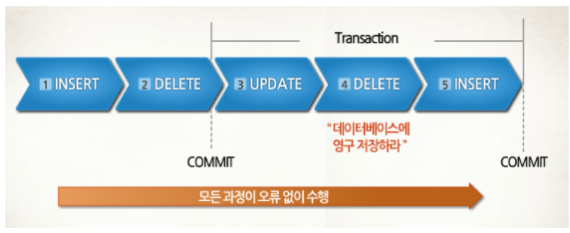
- 모든 작업을 정상적으로 처리하겠다고 확정하는 명령어이다.
- 트랜잭션의 처리 과정을 데이터 베이스에 반영하기 위해서 변경된 내용을 모두 영구저장한다.
- commit을 수행하면, 하나의 트랜잭션 과정을 종료하게 된다.
- transaction 작업 내용을 실제 DB에 저장.
- 모든 사용자가 변경한 데이터의 결과를 볼 수 있다.
5-2. rollback
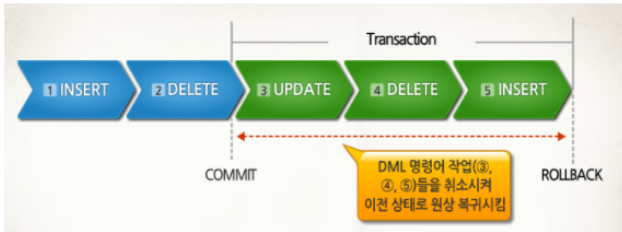
- 작업 중 문제가 발생했을 때, 트랜잭션의 처리과정에서 변경사항을 취소하고, 트랜잭션 과정을 종료시킨다.
- 트랜잭션으로 인한 하나의 묶음 처리가 시작되기 이전의 상태로 되돌린다.
- 이전 commit한 곳까지만 복구한다.
- 트랜잭션 작업 중 하나라도 문제가 발생하면, 모든 작업을 취소해야 하기 때문에 하나의 논리적인 작업 단위로 구성해 놓아햐 한다.
- 문제가 발생하면, 논리적인 작업의 단위를 모두 취소해 버리면 되기 때문이다.
5-3. 명령어의 장점
- 데이터 무결성이 보장된다.
- 논리적으로 연관된 작업을 그룹화할 수 있다.
5-4. 자동 rollback되는 경우
- 비정상적인 종료
5-5. 자동 commit이 되는 경우
- DDL문( create, alter, drop, truncate)
- DCL문(grant, revoke) 사용권한
- insert, update, delete 작업 후 commit하지 않고 오라클을 정상 종료시에 commit명령어 입력하지 않아도 정상 commit후 오라클 종료
6. 컬럼속성(무결성 제약조건)
- not null : null값이 입력되지 못하게 하는 조건
- unique : 중복된 값이 입력되지 못하게 하는 조건
- check : 주어진 값만 허용하는 조건
- primary key : not null + unique + index 의 의미
- foreign key: 다른 테이블의 필드(컬럼)를 참조해서 무결성을 검사하는 조건
6-1. 외래키 삭제 옵션
- on delete cascade
: 참조되는 부모 테이블의 행에 대한 delete를 허용한다. 즉, 참조되는 부모 테이블 값이 삭제되면 연쇄적으로 자식 테이블 값역시 삭제된다. - on delete set null
: 참조되는 부모 테이블의 행에 대한 delete를 허용한다. 이건 cascade와 다른데, 부모 테이블의 갑시 삭제되면 해당 참조하는 자식테이블의 값들은 null값으로 설정된다.
SELECT * FROM EMPLOYEES e;
--DDL 명령어
CREATE TABLE EMPLOYEES2(
employee_ID number(10),
name varchar2(20),
salary number(7,2)
)
;
--기존 테이블과 동일하게 작성
CREATE TABLE EMPLOYEES3
AS
SELECT * FROM EMPLOYEES e
;
-- 테이블에 컬럼 추가
SELECT *
FROM EMPLOYEES2 e
;
ALTER TABLE EMPLOYEES2 add(
manager_id varchar2(10)
);
--컬럼 수정
ALTER TABLE EMPLOYEES2 modify(
manager_id varchar2(20)
);
--컬럼 삭제
ALTER TABLE EMPLOYEES2 drop(
manager_i
);
--테이블 삭제
DROP TABLE EMPLOYEES3 ;
SELECT * FROM EMPLOYEES3 e ;
--테이블 삭제나 컬럼삭제 같은 경우는 매우 위험한?작업이기에 주석처리해두는 것도 좋음
--데이터 입력 INSERT
SELECT * FROM EMPLOYEES2 e;
-- 모든 데이터에 넣을 때는 상관이 없지만, 하나라도 비면 null이라도 채워야한다.
-- 혹은 칼럼을 지정해야한다.
INSERT INTO EMPLOYEES2 VALUES (1, '테스트', 30000)
;
SELECT * FROM EMPLOYEES2 e ;
--TRUNCATE
TRUNCATE TABLE EMPLOYEES2 ;
CREATE TABLE Sample (
deptNo number(20),
deptName Varchar2(15),
deptLoc Varchar2(15),
deptMaNager Varchar2(10)
);
SELECT * FROM SAMPLE ;
INSERT INTO SAMPLE(depNo, DEPTNAME, DEPTLOC, DEPTMANAGER)
VALUES (10, '기획실', '서울', '홍길동');
--INSERT INTO SAMPLE VALUES (10, '기획실', '서울', '홍길동');
INSERT INTO SAMPLE VALUES (20, '전산실', '부산', '길말똥');
INSERT INTO SAMPLE VALUES (30, '영업부', '광주', null);
;
-- update
update sample set deptno = 50
where DEPTno = 30;
;
UPDATE sample SET DEPTLOC = '인천'
WHERE DEPTNAME = '영업부';
;
SELECT * FROM SAMPLE s ;
--영업부 삭제
DELETE sample
WHERE deptname = '전산실';
SELECT * FROM SAMPLE s ;
--commit;
SELECT * FROM SAMPLE s ;
DELETE sample;
ROLLBACK;
--컬럼속성
--not null
CREATE TABLE null_test(
col1 varchar2(10) NOT NULL,
col2 varchar2(10) NULL,
col3 varchar2(10)
);
INSERT INTO NULL_TEST (col1, col2) VALUES ('aa', 'bb');
SELECT * FROM NULL_TEST nt
;
INSERT INTO NULL_TEST (col1, col3) VALUES ('aa', 'bb');
SELECT * FROM NULL_TEST nt
;
--nuique
CREATE TABLE unique_test(
col1 varchar2(20) UNIQUE NOT null,
col2 varchar2(20) UNIQUE,
col3 varchar2(20) NOT NULL,
col4 varchar2(20) NOT NULL,
CONSTRAINT temp_unique UNIQUE (col3, col4)
);
INSERT INTO UNIQUE_TEST (col1, col2, col3, col4 )
VALUES ('aa', 'bb', 'cc', 'dd')
;
INSERT INTO UNIQUE_TEST (col1, col2, col3, col4 )
VALUES ('aa2', 'bb2', 'cc2', 'dd2')
;
SELECT* FROM UNIQUE_TEST ut ;
UPDATE UNIQUE_TEST SET col1 = 'aa' WHERE col2 = 'bb2';
INSERT INTO UNIQUE_TEST (col1, col2, col3, col4 )
VALUES ('aa3', null, 'cc3', 'dd3')
;
INSERT INTO UNIQUE_TEST (col1, col2, col3, col4 )
VALUES ('aa4', null, 'cc4', 'dd4')
;
--null 값은 중복에 대해 예외이므로 unique에 null값은 여러 개 들어갈 수 있다.
CREATE TABLE UNIQUE_TEST2(
col1 varchar2(20),
col2 varchar2(20),
CONSTRAINT temp_unique2 unique(col1, col2)
);
//CONSTRAINT 에서 unique제약 조합이 유니크해야하므로 각각이 같은것은 괜찮다.
SELECT * FROM UNIQUE_TEST2
;
INSERT INTO UNIQUE_TEST2 (col1, col2)
VALUES ('aa', 'aa');
INSERT INTO UNIQUE_TEST2 (col1, col2)
VALUES ('aa', 'bb');
INSERT INTO UNIQUE_TEST2 (col1, col2)
VALUES ('aa', 'cc');
--check : 체크 제약조건은 특정한 값으로 그 컬럼을 채우기 때문에 문자로 설정해야한다.
CREATE TABLE check_test(
gender varchar2(10) NOT NULL
CONSTRAINT check_gender CHECK (gender IN ('남성', '여성'))
);
insert INTO CHECK_TEST VALUES ('여성');
insert INTO CHECK_TEST VALUES ('남성');
insert INTO CHECK_TEST VALUES ('F');
insert INTO CHECK_TEST VALUES ('M');
SELECT * FROM CHECK_TEST ct ;
--기본 키 (Primary Key)
/*
* 기본키 역시 기본적인 제약조건들을 테이블 생성할 때 같이 정의한다.
* 테이블당 하나만 정의 가능하다.
* 기본키, 식별자, PK 등으로 불리고 있다.
* not null + unique + index
*/
-- pk 선언방법
CREATE TABLE constTest(
pkCol1 varchar2(10) PRIMARY KEY, --이게 가장 많이씀. 다른 2가지방법도 가능은 하다.
pkCol2 varchar2(10) CONSTRAINT pk_test1 PRIMARY KEY,
pkCol3 varchar2(10) CONSTRAINT pk_test2 PRIMARY KEY(okCo13);
)
;
CREATE TABLE primary_test(
student_id NUMBER(10) PRIMARY KEY,
name varchar2(20)
);
--개인 숙제 -- primary key를 다른걸로 바꿔보자
--Foreign Key(외래키)
/* 외부키, 외래키, 참조키, fk, 외부식별자라고 불린다.
* FK가 정의된 테이블을 자식 테이블이라고 칭한다.
* 참조가 되는 테이블을 즉, PK가 있는 테이블을 부보테이블이라한다.
* 부모 테이블의 PK칼럼에 존재하는 데이터만 자식 테이블에 입력할 수 있다.
* 부모 테이블은 자식의 데이터나 테이블이 삭제된다고 영향을 받지 않는다.
* 참조하는 데이터 컬럼과 데이터 타입이 반드시 일치해야 한다.
* 참조할 수 있는 컬럼은 기본키이거나 unique만 가능하다.
* (보통은 pk랑 엮는다)
*/
-- NTT관계도만을 보고 Join을 할 수 있어야 한다.
CREATE TABLE foreign_key(
department_id varchar2(10)
CONSTRAINT dept_fk REFERENCES departments(department_id), --인라인 방식 : 만들자마자 외부키를 더함.
name varchar2(10),
salary number(10)
);
CREATE TABLE foreign_key(
department_id varchar2(10), // 위에꺼는 외래키가 정해져있지만 아래거는 아니므로
name varchar2(10),
salary number(10),
CONSTRAINT dept_fk;
FOREIGN KEY department_id;
REFERENCES departments(department_id); //아웃라인 방식
);
--test
CREATE TABLE daddy(
idx number(10),
mID number(10) PRIMARY KEY
);
CREATE TABLE daughter(
idx number(10) PRIMARY KEY ,
mID number(10),
CONSTRAINT fk_DA FOREIGN KEY (mID)
REFERENCES daddy(mID) ON DELETE cascade
);
INSERT INTO daddy values(1,10);
INSERT INTO daddy values(2,20);
SELECT * FROM daddy;
INSERT INTO DAUGHTER values(100,10);
INSERT INTO DAUGHTER values(101,10);
INSERT INTO DAUGHTER values(200,20);
-- INSERT INTO DAUGHTER values(201,30);
SELECT * FROM DAUGHTER ;
DELETE FROM DAUGHTER d WHERE idx =100;
DELETE FROM Daddy d WHERE idx =1;- Quiz
/*
* 테이블 이름 : TB_TEAM
* 컬럼 명 데이터 타입 및 제약조건
팀 아이디 NUMBER(10), PK
지역 VARCHAR2(10), NOT NULL
팀 명 VARCHAR2(10), NOT NULL
전화번호 VARCHAR2(15)
홈페이지 VARCHAR2(60)
테이블 이름 : TB_PLAYER
컬럼 명 데이터 타입 및 제약조건
선수 번호 NUMBER(10), PK
선수 이름 VARCHAR2(10), NOT NULL
포지션 VARCHAR2(10) (투수, 타자, 포수, .. 등등)
신장 NUMBER(3)
팀 아이디 NUMBER(10)
* TB_TEAM 테이블의 팀 아이디에 정의되어 있는 값만이,
TB_PLAYER 테이블의 팀 아이디에 정의 될 수 있다.(FK, 삭제 옵션 임의 지정)
* TB_TEAM 임의의 팀 2팀 입력
* TB_PLAYER 테이블에 임의의 선수 10명 입력
* 선수 번호, 선수 이름, 포지션, 신장, 팀 명, 홈페이지 조회
* TB_TEAM, TB_PLAYER 테이블 삭제
*/
CREATE TABLE TB_TEAM(
팀아이디 number(10) PRIMARY KEY,
지역 VARCHAR2(10) NOT NULL,
팀명 VARCHAR2(10) NOT NULL,
전화번호 VARCHAR2(15),
홈페이지 VARCHAR2(60)
);
CREATE TABLE TB_PLAYER(
선수번호 NUMBER(10) PRIMARY KEY,
선수이름 VARCHAR2(10) NOT NULL,
포지션 VARCHAR2(10)
CONSTRAINT check_포지션 CHECK (포지션 IN ('투수', '야수', '포수')),
신장 NUMBER(3),
팀아이디 NUMBER(10),
CONSTRAINT fk_er FOREIGN KEY (팀아이디)
REFERENCES TB_TEAM(팀아이디) ON DELETE SET NULL
);
INSERT INTO TB_TEAM values(1, '대전', '한화', '042', 'www.hanwhaeagles.co.kr');
INSERT INTO TB_TEAM values(2, '서울', '두산', '02', 'www.doosanbears.co.kr');
INSERT INTO TB_PLAYER VALUES (1,'문동주', '투수', 188, 1);
INSERT INTO TB_PLAYER VALUES (5,'윤대경', '투수', 179, 1);
INSERT INTO TB_PLAYER VALUES (32,'윤산흠', '투수', 188, 1);
INSERT INTO TB_PLAYER VALUES (8,'노시환', '야수', 185, 1);
INSERT INTO TB_PLAYER VALUES (13,'최재훈', '포수', 178, 1);
INSERT INTO TB_PLAYER VALUES (65,'정철원', '투수', 192, 2);
INSERT INTO TB_PLAYER VALUES (2,'박치국', '투수', 177, 2);
INSERT INTO TB_PLAYER VALUES (25,'양의지', '포수', 180, 2);
INSERT INTO TB_PLAYER VALUES (3,'로하스', '야수', 183, 2);
INSERT INTO TB_PLAYER VALUES (31,'정수빈', '포수', 175, 2);
SELECT * FROM TB_TEAM tt ;
SELECT * FROM TB_PLAYER tp ;
SELECT tp.선수번호, tp.선수이름, tp.포지션, tp.신장, tt.팀명, tt.홈페이지 조회
FROM TB_PLAYER tp
LEFT OUTER JOIN TB_TEAM tt
ON tt.팀아이디 = tp.팀아이디
;
drop TABLE TB_TEAM ;
drop TABLE TB_PLAYER ;