

< Scrapy란? >

- python을 이용한 데이터 수집 framework
pip install scrapy로 설치 후 사용
Scrapy의 구조
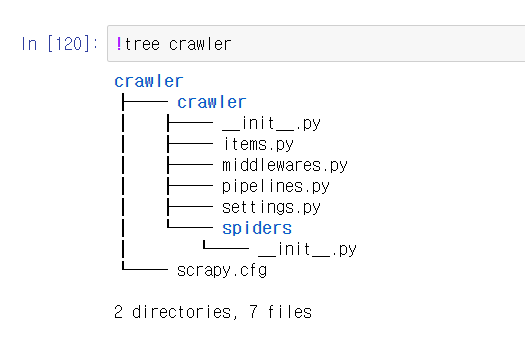
!scrapy startproject #scrapy이름을 하면 만들어지는 scrapy의 기본 구조
1. items.py
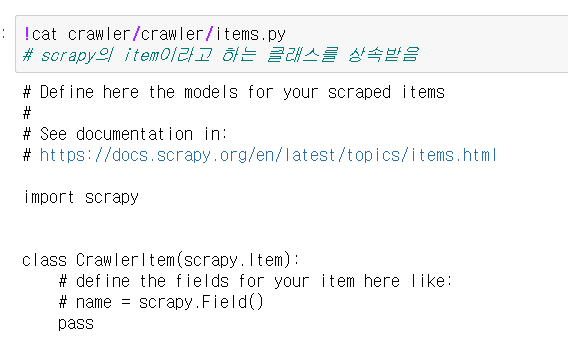
- 저장할 데이터의 자료구조 설정
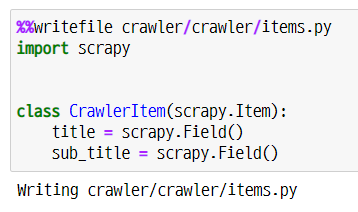
- #name 부분에 데이터의 종류 이름을 설정한다
2. spiders
- scrapy의 디렉토리
- spiders 하위에 python 코드로 작성
%%writefile crawler/crawler/spiders/spider.py - 어떤 웹서비스를 어떻게 크롤링할 것인지에 대한 코드를 작성
- 기본적인 변수명들을 지켜어야함
3. pipelines.py
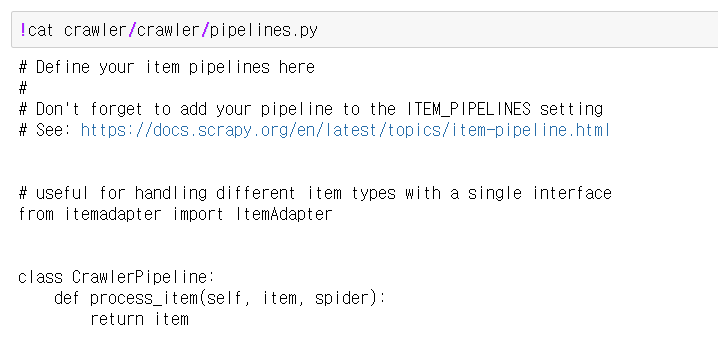
- 스크래핑한 데이터를 처리하는 방법을 설정
- ex) csv로 저장, mongodb에 저장 등
- items를 출력하기 전에 실행됨
4. settings.py
- 스크래핑할 때의 설정값
- ex) robots.txt를 따를지 등
Scrapy 생성 과정
- 프로젝트 생성
- items.py 작성해서 자료구조 틀 만듦
- 어떻게 크롤링할 것인지 spiders 작성
- pipelines.py에 데이터 처리 방법 작성
- settings.py에 설정값 수정
Scrapy 실행과정
- !./run.sh로 실행
- starturls가 requests, responsne (callback함수로 상세 페이지 스크래핑)
- item이 생성
- pipeline 대로 item 처리 됨
