최소 공통 조상 LCA(Lowest Common Ancestor)
-
개요
LCA (Lowest Common Ancestor) : 주어진 두 노드의 최소 공통 조상을 찾는 알고리즘 -
예시
예를 들어, 아래의 트리 5와 6번 노드의 LCA는 2번 노드
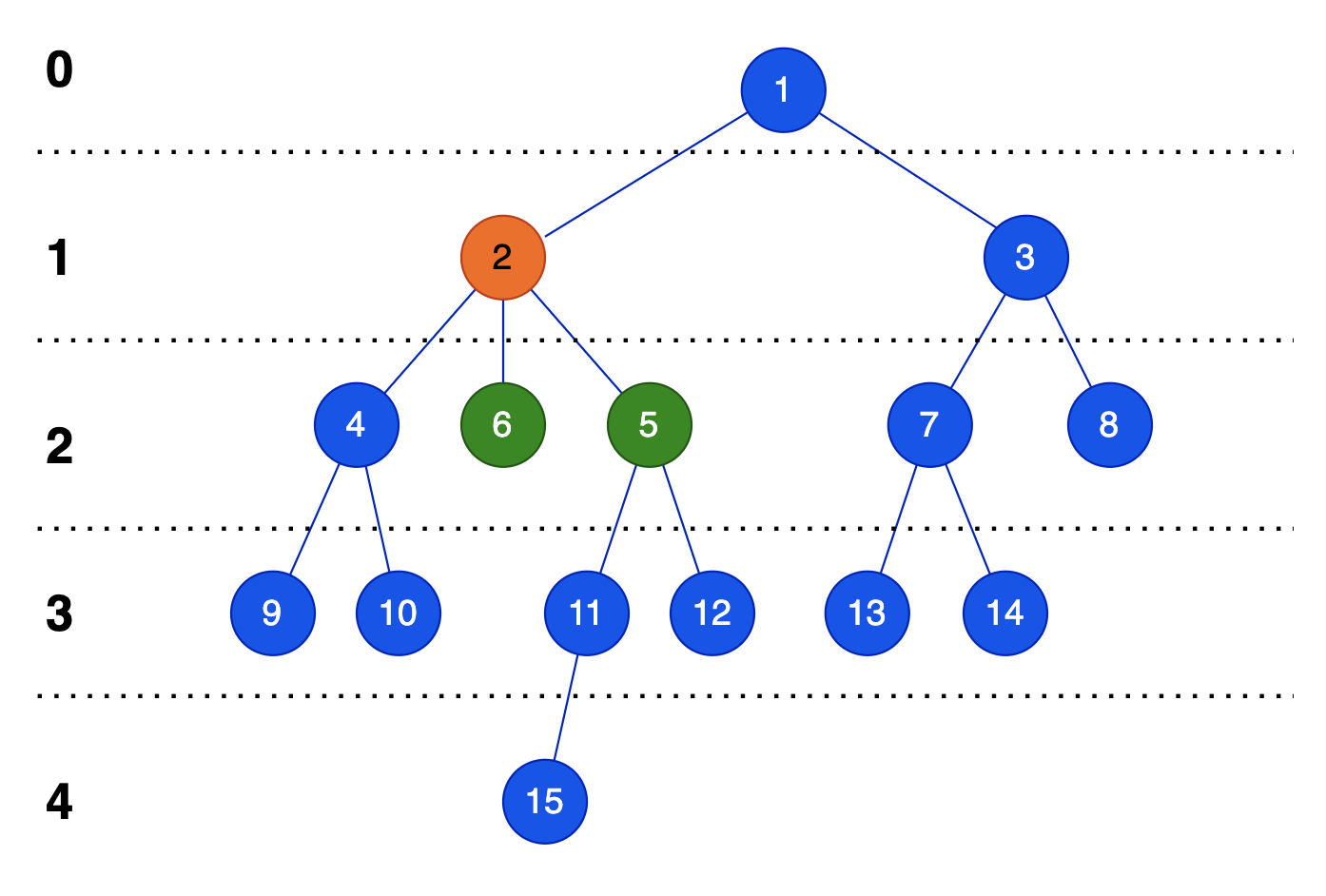
-
일반적인 LCA 풀이
a. 1번 루트 노드를 기준으로, DFS탐색을 하며 각 노드의 트리의 depth와 부모노드parnet를 저장.
b. LCA를 구하기 위한 a,b번 노드가 주어지면, 해당 두 노드의 상위 노드(부모)를 조회하며 의 h를 같은 높이로 맞춘다.
c. 각 부모노드가 일치할 때까지 비교하며 구한다. (최상위 LCA는 루트노드인 1)만약, 이러한 풀이를 매우 편향된 트리에 적용하게 되면, 엄청나게 많은 반복 횟수로 값을 구해야 한다. 이렇게 되면 O(NM)의 시간복잡도를 가질 수 있기 때문에, 범위가 매우 클 경우 효율적인 계산을 할 수 없다.
이러한 문제점을 개선한 알고리즘이 DP와 세그먼트 트리를 활용한 LCA 알고리즘이다.
DP를 활용한 LCA 풀이
-
DP 값의 할당
일반적인 방식으로 어떤 노드의 모든 부모노드들을 구하게 된다고 하면, 깊이가 100인 노드인 경우 100번의 반복을 통해 구해야만 한다.
하지만, 2^h의 부모를 알고 있다면, 64+32+4 = 100으로 총 3번만에 부모 노드를 구할 수 있다.DP를 활용하게 되면 편향트리로 연산을 하더라도 그 횟수가 훨씬 줄어들고, 시간복잡도를 O(MlogN)으로 단축시킬 수 있다.
dp 2차원 배열에 각 노드의 2^h번째 부모노드를 저장해준다. 이는 중복되는 연산 횟수를 줄여줌으로써 훨씬 효율적인 연산이 가능하다.
-> DP[node][h] -> node의 h번째 부모 노드a. 트리의 최대 높이(h)
// N은 노드 개수 int h = (int)Math.ceil(Math.log(N)/Math.log(2))+1;b. DFS탐색으로 각 노드의 깊이(depth)와 1번째 부모노드의 값으로 초기화
-> dp[node][0] = node의 1번째 부모노드static void dfs(int node, int d, int p) { depth[node] = d; for(int next : edge[node]) { if(next != p) { dfs(node, d+1, p); parent[next][0] = node; // next의 부모 = node } } }c. 나머지 2^0, 2^1, ... 2^h-1번째 부모노드도 구하기.
static void fillParents() { for(int i=1;i<h;i++) { for(int j=1;j<n+1;j++) parent[j][i] = parent[parent[j][i-1]][i-1]; } }- 시뮬레이션
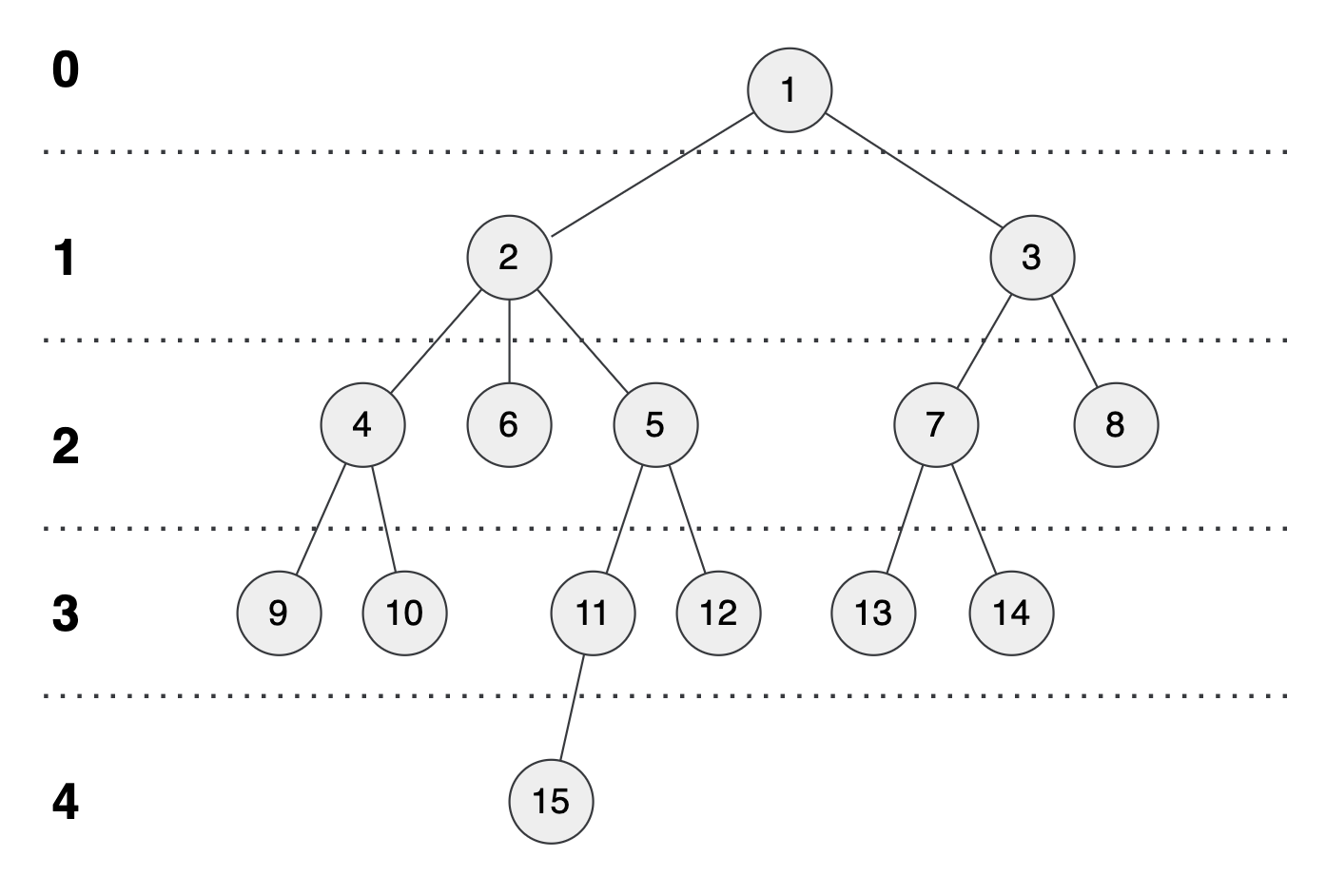
dp[node][log(d)]는 다음과 같이 저장된다.
⬆️ 행 (노드번호의 n번째 부모노드번호), 열(노드번호)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 0 1 1 2 2 2 3 3 4 4 5 5 7 7 11 2 0 0 0 1 1 1 1 1 2 2 2 2 3 3 4 3 0 0 0 0 0 0 0 0 1 1 1 1 1 1 2 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
- 시뮬레이션
-
LCA 구하기
각 노드의 n번째 부모노드가 담긴 배열(dp)을 모두 할당해 주었으면, 이를 바탕으로 LCA를 구해주면 된다.
a. a와 b노드가 주어지면 해당 노드의 높이가 낮은 노드를 기준으로 높이를 맞춰준다.
dp에 저장된 2^h부모노드의 정보를 활용하여 연산 횟수를 단축시킨다.
이때, a==b이면 LCA = a이므로 바로 출력한다.
b. a!=b 이면, a와 b노드의 dp값을 비교해가며 LCA를 찾아준다.
static int LCA(int a, int b) {
int ah = depth[a];
int bh = depth[b];
// ah > bh로 세팅
if(ah < bh) {
int tmp = a;
a = b;
b = tmp;
}
// a, b 높이 맞추기
for (int i=h-1; i>=0; i--) {
if(Math.pow(2, i) <= depth[a] - depth[b]){
a = parent[a][i];
}
}
if(a==b) return a;
// a!=b이면, LCA찾기
for(int i=h-1; i>=0; i--) {
if(parent[a][i] != parent[b][i]) {
a = parent[a][i];
b = parent[b][i];
}
}
return parent[a][0];
}-
전체 코드
코드보기import java.io.*; import java.util.*; // https://www.acmicpc.net/problem/11438 // DP를 활용한 풀이 public class Main { static int N, h; static ArrayList<Integer>[] edge; static int[] depth; // 노드별 깊이 static int[][] parent; // 높이별 부모 public static void main(String[] args) throws Exception { System.setIn(new FileInputStream("res/n11438.txt")); BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); StringTokenizer st = null; N = Integer.parseInt(br.readLine()); edge = new ArrayList[N+1]; for(int i=1;i<=N;i++) edge[i] = new ArrayList<>(); for(int i=0;i<N-1;i++) { st = new StringTokenizer(br.readLine()); int a = Integer.parseInt(st.nextToken()); int b = Integer.parseInt(st.nextToken()); edge[a].add(b); edge[b].add(a); } h = (int) Math.ceil(Math.log(N)/Math.log(2))+1; // 최대 트리 높이 depth = new int[N+1]; parent = new int[N+1][h]; dfs(1, 0, 0); fillParents(); StringBuilder sb = new StringBuilder(); int M = Integer.parseInt(br.readLine()); for(int i=0;i<M;i++) { st = new StringTokenizer(br.readLine()); sb.append(LCA(Integer.parseInt(st.nextToken()), Integer.parseInt(st.nextToken()))+"\n"); } System.out.println(sb.toString()); } // 어떤 노드의 직속 부모 구하기 static void dfs(int node, int h, int p) { depth[node] = h; for(int next : edge[node]) { if(next != p){ dfs(next, h+1, node); parent[next][0] = node; // next의 직속 부모는 node } } } // 나머지 2^0, 2^1, ..., 2^h-1번째 부모 노드 채워주기 static void fillParents() { for(int i=1;i<h;i++) { for(int j=1;j<N+1;j++) parent[j][i] = parent[parent[j][i-1]][i-1]; } } static int LCA(int a, int b) { int ah = depth[a]; // a의 깊이 int bh = depth[b]; // b의 깊이 // ah > bh로 setting if(ah < bh) { int temp = a; a = b; b = temp; } // 높이 맞추기 for(int i = h-1;i>=0;i--) { if(Math.pow(2, i) <= depth[a]-depth[b]) a = parent[a][i]; } if(a==b) return a; // a==b라는 뜻은 동일한 부모 노드라는 뜻 // a!=b 이면 LCA 찾기 for(int i=h-1; i>=0;i--){ if(parent[a][i] != parent[b][i]){ a = parent[a][i]; b = parent[b][i]; } } return parent[a][0]; } }
Segment Tree를 활용한 LCA 풀이
-
Segment Tree 초기화
a. 트리를 전위 순회로 탐색한다. 탐색 순으로 세그먼트 리프 노드에 (트리 높이, 노드 번호)를 갱신해준다. 이때, 배열에 각 트리의 노드에 해당하는 리프 노드 번호를 기록해준다.
b. 자식노드에서 부모 노드로 돌아왔을 때 다시 세그먼트 리프에 (트리높이, 부모노드번호)를 삽입해준다. 이때, 배열에 리프 노드 번호를 기록할 필요는 없다.
c. 두 노드간 LCA는 발견된 순서에 따른 쿼리를 통해 구할 수 있게 된다.
예시)
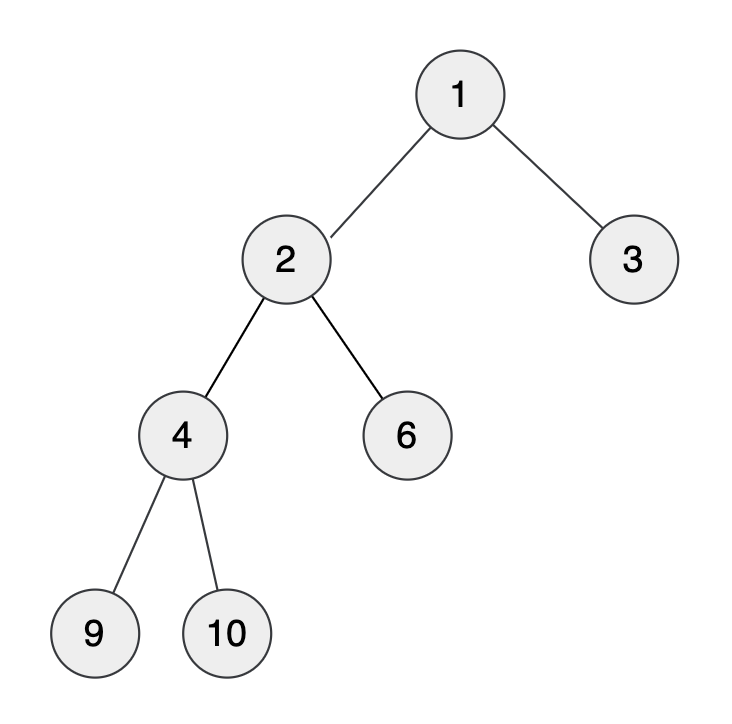
전위 순회를 하게 되면
(높이, 노드 번호)
(0,1) (1,2) (2,4) (3,9) (2,4) (3,10) (2,4) (1,2) (2,6) (1,2) (0,1) (1,3) (0,1)의 순서로 전위 순회를 한다.
이들은 세그먼트 트리의 리프 노드가 되며, 이 값을 토대로 min세그먼트리를 만들면 된다.
각 노드번호(node)에 대해서 전위순회를 할 경우 처음 발견되는 시점(segLeafId)은 다음과 같다.node 1 2 3 4 6 9 10 segLeafId 1 2 12 3 9 4 6 이제, node에 해당하는 segleafIdx로 minQuery를 구하면 LCA를 구할 수 있다.
전위 탐색 + 자식에서 부모노드로 돌아올 때, 부모노드 삽입을 해주면 2N-1개의 리프를 갖게 된다.
부모-자식 간 연결을 한 번씩 하고 올라오기 때문에, 트리에 지수 N-1*2라 2N-2개의 정점과 루트(+1)까지 포함해서 2N-1개가 된다.
이때, U에서 V사이의 세그먼트 트리에서 min쿼리가 LCA가 된다. U를 포함하는 서브트리에서 V를 포함하는 서브트리로 넘어가려면 LCA(U,V)를 반드시 거쳐야 한다. 탐색 과정에서 LCA위의 다른 조상의 경로를 가는 건 불가능하기 때문에, 반드시 LCA값이 나온다.만약 노드 4와 6의 LCA를 구한다면 4의 세그 리프 인덱스 3, 6의 세그 리프 인덱스 9 사이의 값을 찾아주면 된다.
(0,1) (1,2) (2,4) (3,9) (2,4) (3,10) (2,4) (1,2) (2,6) (1,2) (0,1) (1,3) (0,1)
파란색 글자로 표시된 부분에서 노드 번호가 최소인 것을 찾는다. 즉, 여기서 LCA는 2라는 것을 알 수 있다.시간복잡도는 트리 구성에 O(N), 세그먼트 트리 구성에 O(NlogN), 실행 횟수에 따라 O(MlogN)이므로
약 O(NlogN+MlogN)이다. -
전체 코드
코드보기import java.io.*; import java.util.*; public class Main { static int N; static ArrayList<Integer>[] edge; static int[] firstVisitCnt, segMinTree; static ArrayList<Integer> visitRoute; public static void main(String[] args) throws Exception { System.setIn(new FileInputStream("res/n11438.txt")); BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); StringTokenizer st = null; N = Integer.parseInt(br.readLine()); edge = new ArrayList[N+1]; for(int i=1;i<=N;i++) edge[i] = new ArrayList<>(); for(int i=0;i<N-1;i++) { st = new StringTokenizer(br.readLine()); int a = Integer.parseInt(st.nextToken()); int b = Integer.parseInt(st.nextToken()); edge[a].add(b); edge[b].add(a); } firstVisitCnt = new int[N+1]; visitRoute = new ArrayList<>(); dfs(1, 0, 0); int h = (int)Math.ceil(Math.log(visitRoute.size())/Math.log(2)); int size = 1 << (h+1); segMinTree = new int[size]; init(1, 0, visitRoute.size()-1); StringBuilder sb = new StringBuilder(); int M = Integer.parseInt(br.readLine()); for(int i=0;i<M;i++) { st = new StringTokenizer(br.readLine()); int a = firstVisitCnt[Integer.parseInt(st.nextToken())]; int b = firstVisitCnt[Integer.parseInt(st.nextToken())]; if(a>b){ int tmp = a; a = b; b = tmp; } sb.append(getMin(1, 0, visitRoute.size()-1, a, b)+"\n"); } System.out.println(sb.toString()); br.close(); } static void dfs(int node, int p, int d) { if(firstVisitCnt[node] == 0) firstVisitCnt[node] = visitRoute.size(); visitRoute.add(node); for(int child : edge[node]) { if(child != p) dfs(child, node, d+1); } if(p != 0) visitRoute.add(p); } static int init(int node, int start, int end) { if(start == end) return segMinTree[node] = visitRoute.get(start); int mid = (start+end)/2; return segMinTree[node] = Math.min(init(node*2, start, mid), init(node*2+1, mid+1, end)); } static int getMin(int node, int start, int end, int left, int right) { if(end < left || start > right) return Integer.MAX_VALUE; if(left <= start && end <= right) return segMinTree[node]; int mid = (start+end)/2; return Math.min(getMin(node*2, start, mid, left, right), getMin(node*2+1, mid+1, end, left, right)); } }
- 활용문제
- 백준 - LCA, LCA2
- SWEA - 영준이의 진짜 BFS
