
Struct operator overloading
다음과 같은 구조체가 있다고 가정.
#include <string>
struct player{
string name;
int score;
int index;
};이때, rank구조체간의 연산을 연산자 오버로딩을 통해서 정의해보자.
operator <
만약 score는 큰 것이 작고 score 값이 서로 같을 시,
index는 빠른(적은)것이 작다 라고 규정하려면 다음과 같다
struct player{
//...
bool operator<(const rank& rhs)const
{
if(score == rhs.score) // 스코어 값이 같다면
return index < rhs.index //인덱스가 빠른것이 작다
else
return score > rhs.score // 스코어가 큰 것이 작다
}
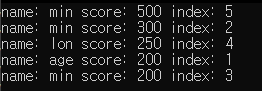
};확인해 보기 위해 std::sort 로 구조체 배열을 정렬해 보았다.
int main() {
player a = { "age",200,1 };
player b = { "min",300,2 };
player c = { "min",200,3 };
player d = { "lon",250,4 };
player e = { "min",500,5 };
vector<player> v;
v.push_back(a);
v.push_back(b);
v.push_back(c);
v.push_back(d);
v.push_back(e);
sort(v.begin(), v.end());
for (auto& i : v)
cout << "name: " << i.name << " " << "score: " << i.score << " " << "index: " << i.index << endl;출력결과
operator =
이번엔 대입연산자인 = 를 사용하여 새로운 구조체에 기존 구조체 값을 대입해보자
player& operator=(const player& rhs) {//player ref 반환
name = rhs.name;
score = rhs.score;
index = rhs.index;
return *this; //ref 반환해서 대입 연산 이후 불필요한 복사 방지
}player f를 생성하고 player a의 값을 대입해 보았다.
player f;
f = a;
cout << "name: " << f.name << " " << "score: " << f.score << " " << "index: " << f.index << endl;출력결과

❗위 경우 멤버변수가 heap 공간을 차지하지 않아 얕은 복사에 따른 문제점이 없다.
따라서 =를 재정의 하지 않고 디폴트 복사 생성자를 사용해도 무방하다.
operator ==
이번엔 비교 연산자를 구현해보자.
score나 index가 달라도 name이 같다면 같은 player로 취급하려 한다.
bool operator ==(const player& rhs) {
return name == rhs.name;
}이름이 같은 player b와 player c 를 비교하여 서로 같은지 비교연산을 해서 검증한다.
//player b = { "min",300,2 };
//player c = { "min",200,3 };
if (b == c)
cout << "b와c는 서로 같습니다." << endl;
else
cout << "b와c는 서로 다릅니다." << endl;출력결과

구조체 연산자 overloading을 이용한 std::set 정렬
문제상황
stl::set은 중복을 허용하지 않으면서 내부 원소들을 삽입과 동시에 정렬한다.
그렇다면 위의 == 연산자와 <연산자 재정의로 인해 set<player> 에 삽입하기만 하면 중복된 이름이 제거될까?
(위에서 player는 name만 같으면 같은 구조체로 재정의 하였다.)
//v 는 player a부터 e까지를 담은 vector<player> 컨테이너
set<player> s;
for (auto& i : v)
s.insert(i);
for(auto it=s.begin();it!=s.end();it++)
cout << "name: " << it->name << " " << "score: " << it->score << " " << "index: " << it->index << endl;
결론은 안된다.
출력결과1

min으로 중복된 이름이 여전히 구조체 내부에 존재하는 것을 알 수 있다.
그렇다면 삽입 전에 set.find()로 중복된 이름값을 미리 필터링 할수 있을까?
//코드수정
for (auto& i : v) {
auto it = s.find({ i.name, 0,0 }); //임시 구조체의 i.name 을 찾는다.
if(it==s.end()) // 중복 없으면
s.insert(i); //삽입
}출력결과2
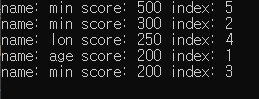
이것도 안된다.
트리기반 구조체 로직
원인은 std::set이 동일(equivalent) 한 원소를 판별하는 방법에 있다.
...Two elements of a set are considered equivalent if the container's comparison object returns false reflexively (i.e., no matter the order in which the elements are passed as arguments).
즉, 두 원소를 대소비교 (a<b, b<a) 하여 연속적으로 false값이 도출된다면 두 원소는 서로 같다고 판별한다.
(a는 b보다 작지 않다 + b는 a보다 작지 않다...따라서, a=b)
이제 위 사실을 바탕으로 기존 struct를 재구성해보자
struct player {
string name;
int score;
int index;
//자동 생성자 : find(i.name)할시 나머지 빈값을 여기에 설정한대로 채워줌
player(const string& strkey = "", const int& strData = INT_MAX, const int& strIdx = -1) : name(strkey), score(strData), index(strIdx) {} //맨 위까지 탐색 가능하도록 초기화 조건 설정
bool operator<(const player& rhs)const {
if (name != rhs.name) { //이름이 다르다면 대소 비교
if (score == rhs.score)
return index < rhs.index;
else
return score > rhs.score;
}
return false; // 이름이 같다면 false 리턴
}
//...
};struct 생성자를 추가하여 s.find(i.name) 호출시 score과 index값을 사전 설정한 값으로 자동 초기화 하도록 하였다.
이때, score 값이 높을수록, index값이 낮을수록 상위에 정렬되어 있기에, 각각 최대값(INT_MAX)과 최소값(-1)을 설정하여 구조체 index의 최상위까지 탐색 가능하도록 하였다. (구조 자체는 균형 이진트리 임으로 최상위 노드는 틀린말)
출력결과

중복값이 제거되어 set에 삽입된 것을 확인 할 수 있다.
