
정규화
✍️개념
✳️정규화란 테이블의 속성들이 상호 종속적인 관계를 갖는 특성을 이용하여 테이블을 무손실 분해 하는 과정이다.
✳️무손실 분해 란, 임의의 테이블 R 의 프로젝션인 R1, R2가 NATURAL JOIN 을 통해 원래의 테이블R로 정보 손실 없이 복귀되는 경우, R은 R1과 R2로 '무손실 분해'되었다고 쓴다.
정규화는 보통 BCNF 정규화를 포함하여, 총 6가지 정규형을 의미한다.

정규화의 목적
정규화의 목적은 기본적으로 중복 데이터를 최소화하여, (제거하여)
무결성 제약조건 달성이 용이하고,
논리적/직관적 테이블 구성을 갖춰 각종 이상현상을 방지하기 위함이다.
✳️무결성 제약조건 이란,
데이터베이스의 정확성, 일관성을 보장하기 위해 저장, 삭제, 수정 등을 제약하기 위한 조건을 말한다.
대표적인 무결성 제약조건으론
✳️개체 무결성 (각 릴레이션의 기본키를 구성하는 속성은 널(NULL) 값이나 중복된 값을 가질 수 없다),
✳️참조무결성 (각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다)
등이 있다.
✳️이상현상 으론, 대표적으로 삽입/삭제/갱신 이상등이 있다.
❓파생질문
질문 1: 정규화를 하면 성능이 좋아지나요? 성능이 좋아지는 경우와 아닌 경우를 예시를 기반으로 설명해주실 수 있나요?
🔽정규화의 목적은 성능향상이 아닌, 테이블을 분해하여 데이터 일관성과 정합성을 유지하는 것에 있다.
성능 향상이 목적이 아님으로, 정규화 이후의 성능차이는 부가적인 것으로 봐야한다.
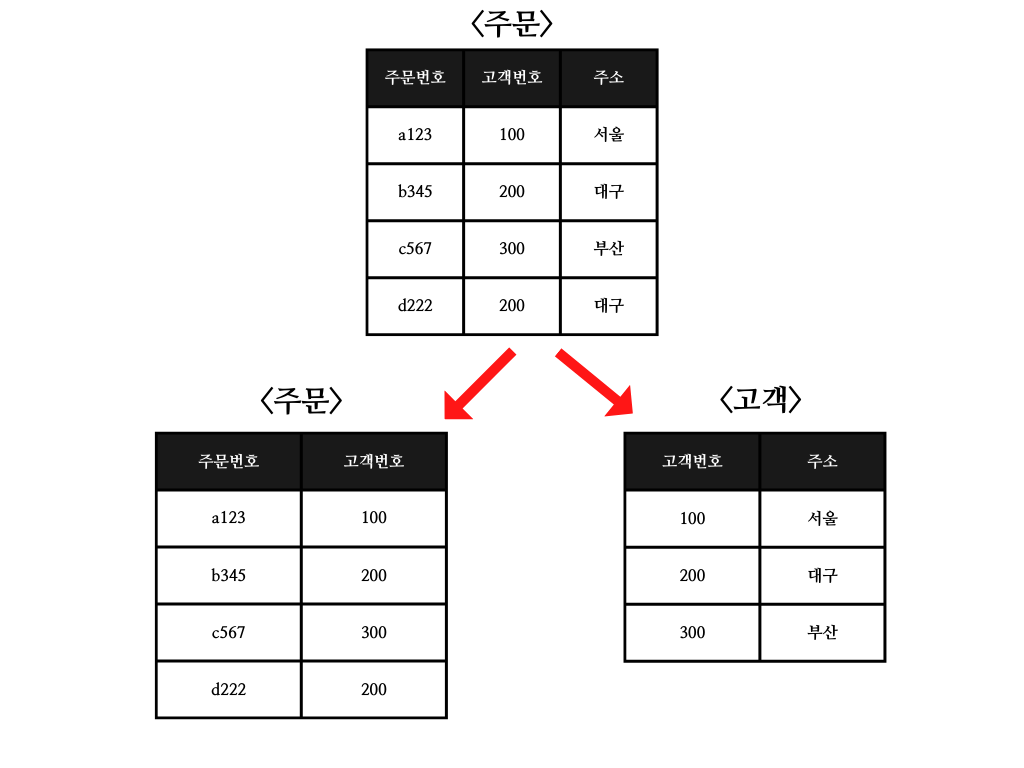
🔽 예로, 주문번호와 고객번호, 주소가 적혀있는 '주문' 테이블을 가정해보자. 주문테이블에서 기본키는 '주문번호' 인데, 주문번호가 고객번호의 결정자이면서, 고객번호가 주소의 결정자인 이행적 함수적 종속이 발생한다. (A->B->C)
따라서 제3정규형을 만족시키려면, 주문번호와 고객번호가 있는 주문 테이블과 고객번호와 주소가 있는 고객 테이블로 테이블을 분리한다.
🔽 이때, 고객의 주소만 조회하는 상황이라면 적은 레코드를 지닌 <고객> 테이블을 조회함으로써 쿼리 성능이 이전보다 더 빨라질 수 있다.
그러나 주문번호를 통해 고객의 주소로 물품을 배달해야하는 상황이라면, 두 테이블을 조인해야 함으로 정규화 이전보다 오히려 성능 하락이 예상된다.
🔽 이런 경우, 오히려 정규화 원칙을 위배하여, 데이터 모델을 통합하거나, 분리, 중복시키는 것이 유리하며 이를 ✳️반정규화 라고 한다.
질문 2: 2차 정규형의 조건과 이것이 1차 정규형에서 일어날 수 있는 오류?를 어떻게 해결할 수 있는지 예시를 들어 설명해주세요
🔽제 2 정규형은 테이블이 제1 정규형을 만족하면서, 기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족하는 정규형을 의미한다.
이를 제1 정규형에서 부분적 함수 종속을 제거한다 라고 한다.

🔽예를 들어, 주문번호, 제품번호, 주문수량, 고객번호, 주소 가 있는 테이블 <제품주문>을 생각해보자. 한번에 여러 제품을 주문 가능하여, 이 테이블의 기본키는 주문번호 와 제품번호이다.
🔽이때, 제품 번호와는 무관하게고객번호 와 주소는 기본키중 주문번호에 의해서만 결정되는 것을 추론할 수 있다. 따라서 이 속성들을 분리하면 부분 함수적 종속성을 제거할 수 있다.
질문 3: 정규화를 실제로 DB에서 어떻게 응용할 수 있을까요?
🔽DB설계시, 사용처에서 잦은 테이블 확장이 예상되는 경우, 정규화된 DB를 설계하여 전체 테이블 변경보단 일부 테이블 변경/추가 하도록 설계할 수 있다.
🔽또한, 정규화의 과정이, 속성들 간의 종속성을 분해하여 기본적으로 하나의 릴레이션에 하나의 종속성이 표현되도록 분해 하는 것임으로, 삽입,삭제,갱신등의 이상 발생을 최소화 하는 DB 설계시 사용할 수 있다.
