
Query Processing 의 기본 단계
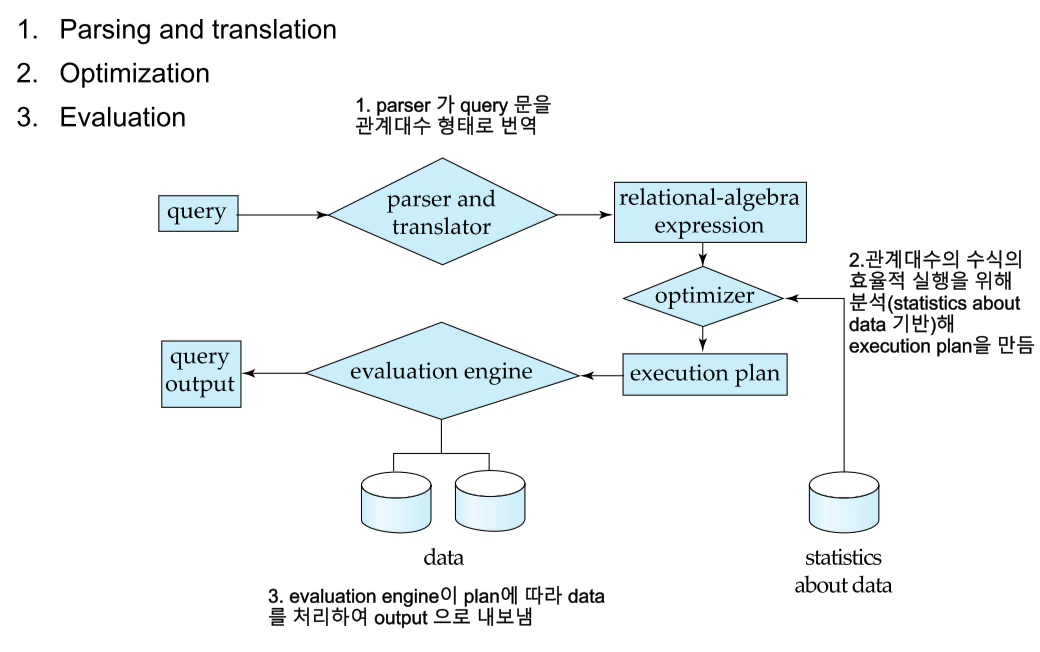
Parsing and transalation
- 사용자가 작성한 syntax 체크, relations 유효성 검사 포함
Optimization
예를 들어 아래 sql문의 경우,
SELECT salary FROM instructor WHERE salary < 75000sql은 순서에 상관없는 선언적 ·비절차적 언어이고
관계대수 수식은 순서가 있는 절차적 언어이기 때문에
위 Query문은 여러 관계대수 식으로 번역 가능한다.
1.) , 또는
2.) 로 표현 가능하다.
1)은 salary를 제외한 나머지 열을 날리고, 75000보다 적은 행을 뽑아내지만,
2)의 경우 75000보다 작은 salary를 가진 행을 뽑아낸 뒤, salary 열만 남긴다.
두 방법은 순서가 다르지만 결과값은 같다. (동등(ㅇ),동치(X))
그러나, 코딩의 관점에서 보면 1)의 방법이 더 효율적이다.(메모리사용량)
이 동등한 여러 수식중 가장 효율적(lowest cost)인 execution plan을 세우는 것이 Query Optimization 이다.
- 이 cost를 정확하게 측정할 방법은 없고,
statistics about data(DB의 상태에 따라서 추정)를 기반으로 추측을 하게 된다.
Query Cost 측정하기
time cost에 관계되는 요소는 많다.
- disk 엑세스 시간, CPU 연산시간, 네트워크 통신 시간 ...
이때 Cost는
- response time (query에 응답하기까지 걸린 총 시간)
- total resource consumption (총 자원 소모량)
으로 추정할 수 있는데, 다음과 같은 특징을 지닌다.
-
response time 은 HDD의 데이터 저장상태, 버퍼상태, 네트워크 지연 등 일정하지 않게 만드는 (운적인) 요소가 많다.
따라서, 각 자원의 소모량을 기반으로 측정하는 resource sonsumption을 cost metric으로 삼는다. -
또, 알고리즘의 시간복잡도 측정과는 달리 CPU cost를 무시한다. (disk access에 드는 시간이 훨씬 크기 때문, 병렬시스템(빅데이터 등의 경우) 에서는 network communication 비용도 측정에 포함된다.) 즉, 일반적인 DB시스템의 cost 효율성 계산에는 Disk cost 가 사용된다.
-
동등한 수식의 계산 결과값을 비교하는 것이기 때문에, 결과값을 output에 내보내는것(쓰는것)은 cost에 포함 하지 않는다.
Disk cost 측정
Disk cost는 다음과 같은 항목으로 측정 될 수 있다.
- Number of seeks (평균 탐색 횟수)
- Number of blocks read (평균 디스크 블록 read 횟수)
- Number of blocks written (평균 디스크 블록 write 횟수)

- HDD의 경우 물리적인 arm이 파일을 탐색하면서 움직이고, (파일 조각난 경우 심해짐)
SSD 의 경우 입·출력 요청을 받았을때, 실제 입·출력이 실행되는 시간사이의 delay가 있어 이를 seek time으로 정의하고 있다.

- 또, 읽는 블록의 개수, 쓰는 블록의 개수 가 서로 다르기 때문에 엄밀히 하면 구분하는 것이 맞지만, 측정의 편의성을 위해 읽고 쓰는것을 따로 구분하지는 않고 number of block transfers 로 통칭하여 측정한다.
- 한 블록(one block)을 전송하는데 걸리는 시간
- (read cost 와 write cost 같다고 가정)
- 한번 탐색(one seek) 하는데 걸리는 시간
b블록 읽어오는데,S번 seek 해야 되는 경우,
- 한 블록(one block)을 전송하는데 걸리는 시간
예를 들어 한 블록이 4KB 라고 하면,
- High end magnetic disk : = 4msec(밀리세컨) , = 0.1msec
- SSD : = 20-90microsec(마이크로세컨) , = 2-10microsec
참고사항
-
이미 버퍼에 data가 올라간 경우, disk I/O를 거치지 않기 때문에 cost estimation이 정확하지 않을 수 있다. 디스크마다 버퍼 정책이 다르기 때문에 사전 고려하기 어려운 사항이다.
-
일부 알고리즘들이 extra buffer space를 적극적으로 활용하여 disk I/O 사용을 줄이는데, 이 버퍼를 다른 쿼리들과 OS processes 과 경쟁하며 사용하기 때문에, 영향력 또한 실행시에만 알 수 있다.
-
따라서 버퍼 안에 data가 없는 초기상태(Worst case)를 가정하여 Query cost를 측정하는 것.
