비정상 상태의 POD 정리
evicted 된 POD가 아닌 다른 원인으로 POD가 비정상 종료되는 경우
24시간이 지나도 상태정보가 남는경우가 발생한다.
(예, Readiness/Liveness Probe failed, 스케줄링 실패, ImagePullBackOff 등)
이런 garbage 를 정리하기위해 POD를 삭제할 수 있는 권한의 ServiceAccount를 이용해
job을 통해 삭제하도록 한다.
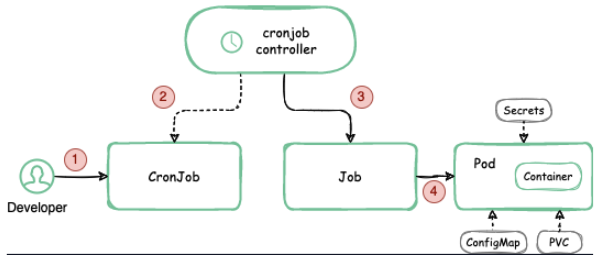
Cronjob 생성
먼저 job POD에서 사용할 서비스 어카운트를 생성해준다.
(* dry-run 을 이용해 yaml 샘플 참고)
kubectl create sa sa-1 --dry-run=client -n default -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: sa-1
namespace: default두번째로 POD를 삭제할 권한을 가진 role을 만들어준다.
kubectl create role delete-pod --verb=delete,get,list --resource=pod --dry-run=client -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
creationTimestamp: null
name: delete-pod
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- delete
- get
- list다음으로 앞서 만든 Role을 서비스 어카운트에 바인딩 시켜준다.
kubectl create rolebinding sa-1-delete-pod --role=delete-pod --serviceaccount=default:sa-1 --dry-run=client -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
creationTimestamp: null
name: sa-1-delete-pod
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: delete-pod
subjects:
- kind: ServiceAccount
name: sa-1
namespace: default
마지막으로 cronjob을 만들어준다. 테스트로 매분 동작하도록 하였으며
bitnami의 kubectl 컨테이너 이미지를 사용한다.
POD의 상태가 Failed인 POD만 삭제 시킨다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: pod-clean
namespace: default
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
serviceAccountName: sa-1
containers:
- name: pod-cleaner
image: bitnami/kubectl:1.23.5
imagePullPoliicy: IfNotPresent
command:
- /bin/sh
- -c
- echo "$(date "+%Y%m%d_%H%M") Delete failed pods";kubectl delete pod --field-selector=status.phase=Failed -n default
restartPolicy: Never결과 확인
[root@410installer eviction]# kubectl get pod
NAME READY STATUS RESTARTS AGE
stress-7c779bc6bc-27pkg 0/1 ContainerStatusUnknown 0 5s
stress-7c779bc6bc-5slrm 0/1 ContainerStatusUnknown 0 12s
stress-7c779bc6bc-6hm7r 1/1 Terminating 0 12s
stress-7c779bc6bc-6lc6r 0/1 ContainerStatusUnknown 0 8s
stress-7c779bc6bc-6msn8 0/1 ContainerStatusUnknown 0 6s
stress-7c779bc6bc-7j5tr 1/1 Terminating 0 12s
stress-7c779bc6bc-8b67r 0/1 ContainerStatusUnknown 0 5s
stress-7c779bc6bc-bk8n2 0/1 ContainerStatusUnknown 0 10s
stress-7c779bc6bc-d4vfg 0/1 ContainerStatusUnknown 0 10s
stress-7c779bc6bc-dnbkn 0/1 ContainerStatusUnknown 0 12s
stress-7c779bc6bc-frjlf 0/1 ContainerStatusUnknown 0 12s
stress-7c779bc6bc-k744j 0/1 ContainerStatusUnknown 0 5s
stress-7c779bc6bc-l472b 0/1 ContainerStatusUnknown 0 10s
stress-7c779bc6bc-l7rt6 0/1 ContainerStatusUnknown 0 8s
cronjob, job 확인
[root@410installer cronjob]# kubectl get cronjob,job
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/pod-clean * * * * * False 0 21s 15m
NAME COMPLETIONS DURATION AGE
job.batch/pod-clean-28768721 1/1 11s 2m21s
job.batch/pod-clean-28768722 1/1 5s 81s
job.batch/pod-clean-28768723 1/1 6s 21s
[root@410installer cronjob]#
## Failed 상태의 POD가 모두 삭제되었음.
[root@410installer eviction]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-clean-28768709-6b7gh 0/1 Completed 0 2m57s
pod-clean-28768710-klfxf 0/1 Completed 0 117s
pod-clean-28768711-2gfzc 0/1 Completed 0 57s
test 1/1 Running 2 2d1h
## log 확인
[root@410installer ~]# kubectl logs -f pod-clean-28768709-6b7gh
20240912_0629 Delete failed pods
pod "stress-7c779bc6bc-4jng7" deleted
pod "stress-7c779bc6bc-4wvpq" deleted
pod "stress-7c779bc6bc-b7zwv" deleted
pod "stress-7c779bc6bc-dxxjj" deleted
pod "stress-7c779bc6bc-kv2h8" deleted
pod "stress-7c779bc6bc-nlwmn" deleted
pod "stress-7c779bc6bc-tn77s" deleted
pod "stress-7c779bc6bc-v9np7" deleted
pod "stress-7c779bc6bc-vqqlc" deleted
pod "stress-7c779bc6bc-w2h7k" deleted
[root@410installer ~]#
cronjob 에 별도 jobhistory 설정을 하지 않는경우 기본값인 3이 적용된다.
( successfulJobsHistoryLimit: 3 )
## complete 된 job은 최대 3개까지만 남고 자동으로 정리된다.
NAME COMPLETIONS DURATION AGE
job.batch/pod-clean-28768733 1/1 15s 3m7s
job.batch/pod-clean-28768734 1/1 14s 2m7s
job.batch/pod-clean-28768735 1/1 20s 67s
job.batch/pod-clean-28768736 0/1 7s 7s
## 4번째 job이 complete 되고나서 가장 오래된 job이 삭제된다.
NAME COMPLETIONS DURATION AGE
job.batch/pod-clean-28768734 1/1 14s 2m31s
job.batch/pod-clean-28768735 1/1 20s 91s
job.batch/pod-clean-28768736 1/1 10s 31s
[yang@410installer ~]$ kubectl describe cronjob pod-clean
Name: pod-clean
Namespace: default
Labels: <none>
Annotations: <none>
Schedule: * * * * *
Concurrency Policy: Allow
Suspend: False
Successful Job History Limit: 3
Failed Job History Limit: 1
Starting Deadline Seconds: <unset>
Selector: <unset>
Parallelism: <unset>
Completions: <unset>
Pod Template:
Labels: <none>
Service Account: sa-1
Containers:
pod-cleaner:
Image: bitnami/kubectl:1.23.5
Port: <none>
Host Port: <none>
Command:
/bin/sh
-c
echo "$(date "+%Y%m%d_%H%M") Delete failed pods"; kubectl delete pod --field-selector=status.phase=Failed -n default
Environment: <none>
Mounts: <none>
Volumes: <none>
Last Schedule Time: Thu, 12 Sep 2024 06:57:00 +0000
Active Jobs: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 28m cronjob-controller Created job pod-clean-28768709
Normal SawCompletedJob 28m cronjob-controller Saw completed job: pod-clean-28768709, status: Complete
Normal SuccessfulCreate 27m cronjob-controller Created job pod-clean-28768710
Normal SawCompletedJob 27m cronjob-controller Saw completed job: pod-clean-28768710, status: Complete
Normal SuccessfulCreate 26m cronjob-controller Created job pod-clean-28768711
Normal SawCompletedJob 26m cronjob-controller Saw completed job: pod-clean-28768711, status: Complete
Normal SuccessfulCreate 25m cronjob-controller Created job pod-clean-28768712
Normal SuccessfulDelete 25m cronjob-controller Deleted job pod-clean-28768709
Normal SawCompletedJob 25m cronjob-controller Saw completed job: pod-clean-28768712, status: Complete
Normal SuccessfulCreate 24m cronjob-controller Created job pod-clean-28768713
Normal SawCompletedJob 24m cronjob-controller Saw completed job: pod-clean-28768713, status: Complete
Normal SuccessfulDelete 24m cronjob-controller Deleted job pod-clean-28768710
Normal SuccessfulCreate 23m cronjob-controller Created job pod-clean-28768714
Normal SuccessfulDelete 23m cronjob-controller Deleted job pod-clean-28768711
Normal SawCompletedJob 23m cronjob-controller Saw completed job: pod-clean-28768714, status: Complete
Normal SuccessfulCreate 22m cronjob-controller Created job pod-clean-28768715
Normal SawCompletedJob 22m cronjob-controller Saw completed job: pod-clean-28768715, status: Complete
Normal SuccessfulDelete 22m cronjob-controller Deleted job pod-clean-28768712
Normal SuccessfulCreate 21m cronjob-controller Created job pod-clean-28768716
Normal SawCompletedJob 21m cronjob-controller Saw completed job: pod-clean-28768716, status: Complete
Normal SuccessfulDelete 21m cronjob-controller Deleted job pod-clean-28768713
Normal SuccessfulCreate 20m cronjob-controller Created job pod-clean-28768717
Normal SawCompletedJob 20m cronjob-controller Saw completed job: pod-clean-28768717, status: Complete
Normal SuccessfulDelete 20m cronjob-controller Deleted job pod-clean-28768714
Normal SawCompletedJob 8m7s (x12 over 19m) cronjob-controller (combined from similar events): Saw completed job: pod-clean-28768729, status: Complete
Normal SuccessfulCreate 3m28s (x17 over 19m) cronjob-controller (combined from similar events): Created job pod-clean-28768734
[yang@410installer ~]$
[yang@410installer ~]$ kubectl get cronjob pod-clean -o yaml
apiVersion: batch/v1
kind: CronJob
metadata:
creationTimestamp: "2024-09-12T06:28:04Z"
generation: 1
name: pod-clean
namespace: default
resourceVersion: "78292079"
uid: da970f29-4442-4af3-95d6-43420dd0f3d7
spec:
concurrencyPolicy: Allow
failedJobsHistoryLimit: 1
jobTemplate:
metadata:
creationTimestamp: null
spec:
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- /bin/sh
- -c
- echo "$(date "+%Y%m%d_%H%M") Delete failed pods"; kubectl delete pod
--field-selector=status.phase=Failed -n default
image: bitnami/kubectl:1.23.5
imagePullPolicy: IfNotPresent
name: pod-cleaner
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
serviceAccount: sa-1
serviceAccountName: sa-1
terminationGracePeriodSeconds: 30
schedule: '* * * * *'
successfulJobsHistoryLimit: 3
suspend: false
status:
active:
- apiVersion: batch/v1
kind: Job
name: pod-clean-28768738
namespace: default
resourceVersion: "78292078"
uid: 4c9c00e4-6100-44f5-a066-f8af384085b2
lastScheduleTime: "2024-09-12T06:58:00Z"
lastSuccessfulTime: "2024-09-12T06:57:05Z"
[yang@410installer ~]$
별도로 TTL 을 적용하여 수행이 완료된 job을 원하는 주기로 정리도 가능하다.
ttlSecondsAfterFinished: 10
job complete 10초후 삭제.
(“ttlSecondsAfterFinished: 0” 으로 설정하면 job이 완료된 이후 바로 정리된다.)
apiVersion: batch/v1
kind: CronJob
metadata:
name: pod-clean
namespace: default
spec:
schedule: "* * * * *"
jobTemplate:
spec:
ttlSecondsAfterFinished: 10
template:
spec:
serviceAccountName: sa-1
containers:
- name: pod-cleaner
image: bitnami/kubectl:1.23.5
imagePullPoliicy: IfNotPresent
command:
- /bin/sh
- -c
- echo "$(date "+%Y%m%d_%H%M") Delete failed pods";kubectl delete pod --field-selector=status.phase=Failed -n default
restartPolicy: NeverEvicted pod lifetime 확인
Evicted 된 POD 는 24시간 지나면 삭제된다.
## Evicted pod 확인
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-695c997db9-bb7kt 1/1 Running 0 23h 10.254.7.233 infra-node01.cluster01.test.local <none> <none>
nginx-695c997db9-g9mpl 0/1 ContainerStatusUnknown 1 147m 10.254.14.3 monitoring-node01.cluster01.test.local <none> <none>
nginx-695c997db9-x6xmq 1/1 Running 0 132m 10.254.8.7 worker-node01.cluster01.test.local <none> <none>
nginx-695c997db9-xtcsl 1/1 Running 0 23h 10.254.7.230 infra-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-279jx 0/1 Error 0 25m 10.254.8.26 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-2lck5 0/1 Error 0 4m56s 10.254.8.41 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-2ppvc 1/1 Running 0 17m 10.254.8.30 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-69sjx 0/1 Error 0 8m51s 10.254.8.39 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-7p2kh 0/1 Error 0 18m 10.254.8.29 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-85slc 0/1 ContainerStatusUnknown 1 13m 10.254.8.35 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-8mvjc 0/1 Error 0 16m 10.254.8.31 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-c5vpj 0/1 Error 0 25m 10.254.8.27 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-f2pdb 0/1 ImagePullBackOff 0 71s 10.254.8.45 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-flsdl 0/1 ContainerStatusUnknown 1 15m 10.254.8.32 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-kwz2x 1/1 Running 0 2m43s 10.254.8.43 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-mv2qm 0/1 ContainerStatusUnknown 1 12m 10.254.8.37 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-q6j7t 0/1 ContainerStatusUnknown 1 15m 10.254.8.33 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-qzndx 0/1 ContainerStatusUnknown 1 12m 10.254.8.36 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-t856d 0/1 ContainerStatusUnknown 1 6m39s 10.254.8.40 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-tjhnb 0/1 ContainerStatusUnknown 1 14m 10.254.8.34 worker-node01.cluster01.test.local <none> <none>
stress-7896dcc7c5-vwjkb 0/1 Error 0 10m 10.254.8.38 worker-node01.cluster01.test.local <none> <none>
## Deployment는 유지한채 replica만 0으로 줄여 놓고 모니터링
[root@410installer stresstest]# kubectl scale deploy/stress --replicas=0
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
worker-node01.cluster01.test.local 152m 4% 1121Mi 10%
[root@410installer stresstest]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-695c997db9-bb7kt 1/1 Running 0 44h
nginx-695c997db9-g9mpl 0/1 ContainerStatusUnknown 1 23h
nginx-695c997db9-x6xmq 1/1 Running 0 23h
nginx-695c997db9-xtcsl 1/1 Running 0 44h
stress-7896dcc7c5-279jx 0/1 Error 0 21h
stress-7896dcc7c5-2lck5 0/1 Error 0 21h
stress-7896dcc7c5-69sjx 0/1 Error 0 21h
stress-7896dcc7c5-7p2kh 0/1 Error 0 21h
stress-7896dcc7c5-85slc 0/1 ContainerStatusUnknown 1 21h
stress-7896dcc7c5-8mvjc 0/1 Error 0 21h
stress-7896dcc7c5-c5vpj 0/1 Error 0 21h
stress-7896dcc7c5-f2pdb 0/1 ContainerStatusUnknown 1 21h
stress-7896dcc7c5-flsdl 0/1 ContainerStatusUnknown 1 21h
stress-7896dcc7c5-kwz2x 0/1 Error 0 21h
stress-7896dcc7c5-mv2qm 0/1 ContainerStatusUnknown 1 21h
stress-7896dcc7c5-q6j7t 0/1 ContainerStatusUnknown 1 21h
Evicted 된 POD 는 24시간 지나면 삭제됨. (default 24h)
https://docs.okd.io/4.10/nodes/scheduling/nodes-descheduler.html
PodLifeTime: evicts pods that are too old.
By default, pods that are older than 24 hours are removed. You can customize the pod lifetime value.
“Descheduler” 이용하여 evicted 된 pod를 24시간이내 삭제도 가능함.
https://github.com/kubernetes-sigs/descheduler
