출처
제목: "내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? - 3편(DB Connection Pool)"
작성자: tistory(Hooligans)
작성자 수정일: 2021년1월14일
링크: https://hyuntaeknote.tistory.com/12
작성일: 2022년8월13일Connection Pool 이란?
- 여기서 말하는 Connection는 WAS와 DB 사이의 연결이다.
- DB 서버와 연결을 위해서는 아래와 같이 3-way-handshaking이라는 작업이 필요하다
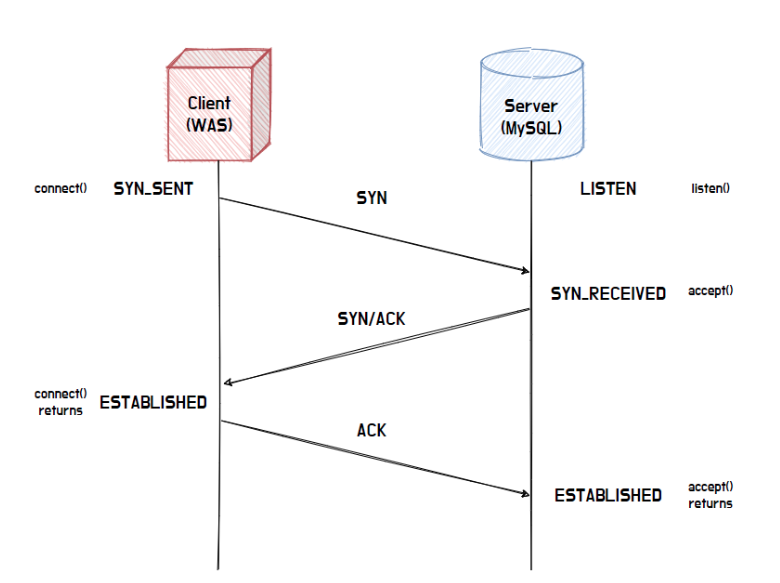
3-way-handshaking은 3번의 패킷 교환을 통해 소켓을 형성하고 통신을 준비하는 과정을 의미하는데 이 과정이 쿼리를 요청할 때마다 반복적으로 실행된다면 이 또한 네트워크 구간에서 병목의 원인이 될 수 있다.
아래 내용은 MySQL 8.0 기준으로 INSERT문을 수행하는 과정을 나타낸다. 괄호 안의 숫자는 각 과정을 수행하는 데 필요한 비용의 비율을 의미한다.
-
MySQL 8.0 Documentation : https://dev.mysql.com/doc/refman/8.0/en/insert-
optimization.html -
Connecting: (3)
-
Sending query to server: (2)
-
Parsing query: (2)
-
Inserting row: (1)
-
Inserting index: (1)
-
Closing: (1)
가장 비용이 많이 드는 작업이 보이나?
바로 서버가 DB 접속하기 위해서 Connection을 생성하는 작업이 가장 큰 비용을 차지한다.
즉, Connection을 반복적으로 생성하는 것은 그만큼 비효율적이다.
이를 해결하기 위해서 사용하는 것이 Connection Pool 방식이다.
Connection Pool 방식은 매번 소켓을 생성하는 것이 아니라 미리 정해진 개수의 Connection을 생성해서 Pool에 보관하다가 재사용하여 데이터를 교환하는 방식이다.
이러한 방식은 이미 형성된 Connection을 재사용한다는 점에서 반복적인 3-way-handshaking 과정을 제거할 수 있으므로 훨씬 더 빠르게 통신할 수 있다.
Connection Pool 동작
스프링의 default JDBC Connection Pool인 Hikari CP가 동작하는 방식을 통해서 Connection Pool이 동작하는 원리에 대해 간단히 알아보자 (우아한 형제들 기술 불로그 참고 : https://woowabros.github.io/experience/2020/02/06/hikaricp-avoid-dead-lock.html)
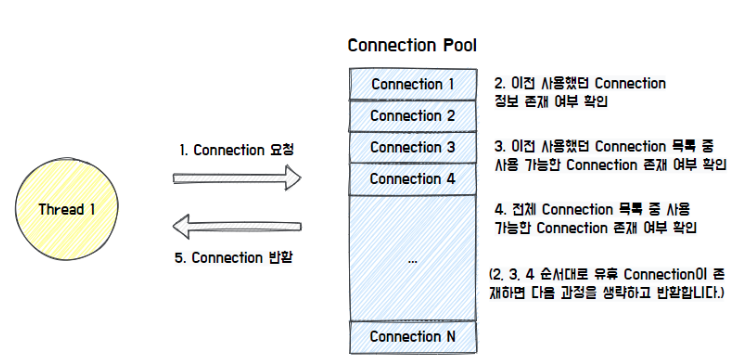
그림에서 볼 수 있듯이 Thread가 Connection을 요청하면 Connection Pool의 각자의 방식에 따라 유휴 Connection을 찾아서 반환한다. Hikari CP의 경우, 이전에 사용했던 Connection이 존재하는지 확인하고, 이를 우선적으로 반환하는 특징을 가지고 있다.
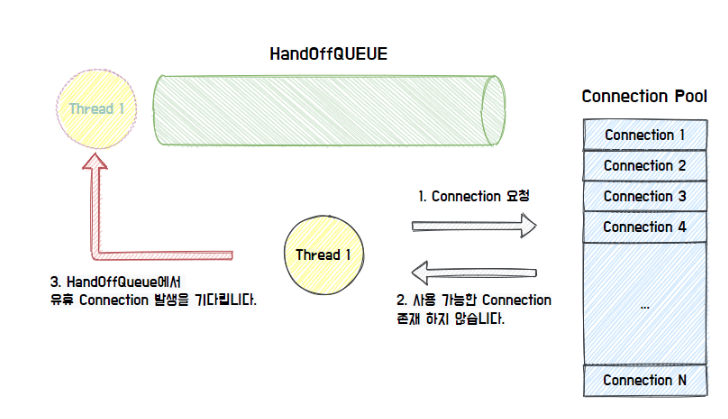
만약에 가능한 Connection이 존재하지 않으면 HandOffQueue를 Polling하면서 다른 Thread가 Connection을 반납하기를 기다린다.
이를 지정한 TimeOut 시간까지 대기하다가 시간이 만료되면 Exception을 던진다.
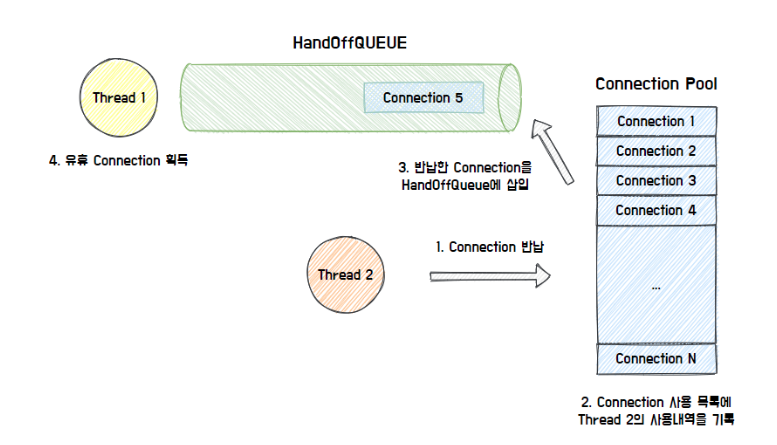
최종적으로 사용한 커넥션을 반납하면 Connection Pool이 사용내역을 기록하고, HandOffQueue에 반납된 Connection을 삽입한다.
이를 통해 HandOffQueue를 Polling 하던 Thread는 Connection을 획득하고 작업을 이어나갈 수 있게 된다.
이렇게 쓰레드들은 트랜잭션을 처리하기 위해서 커넥션을 획득하고, 이를 반납함으로써 상대적으로 비싼 Connection 생성을 줄일 수 있게 되었다.
그러나, 만약 커넥션 풀의 크기가 작으면 커넥션을 획득하기 위해 대기하는 쓰레드가 많아지고, 이에 따라 성능적인 저하를 발생시킬 수 있다.
이는 Connection Pool의 크기를 늘려주면 쉽게 해결할 수 있다.
Connection Pool이 커지면 성능은 무조건 좋아질까?
정답은 아니다.
우선, WAS에서 커넥션을 사용하는 주체는 쓰레드이다. 그렇다면 쓰레드 풀의 크기보다 커넥션 풀의 크기가 크면 어떨까?
쓰레드 풀에서 트랜잭션을 처리하는 쓰레드가 사용하는 커넥션 외에 남는 커넥션은 실질적으로 메모리 공간만 차지하게 된다.
그러면 쓰레드 풀의 크키와 커넥션 풀의 크기를 둘 다 늘려주면 되지 않을까라고 생각할 수 있지만, 쓰레드의 증가는 Context Switching으로 인한 한계가 존재하고, 커넥션 풀을 늘려서 많은 쓰레드가 커넥션을 받더라도 다양한 원인으로 성능적인 한계가 존재한다.
-
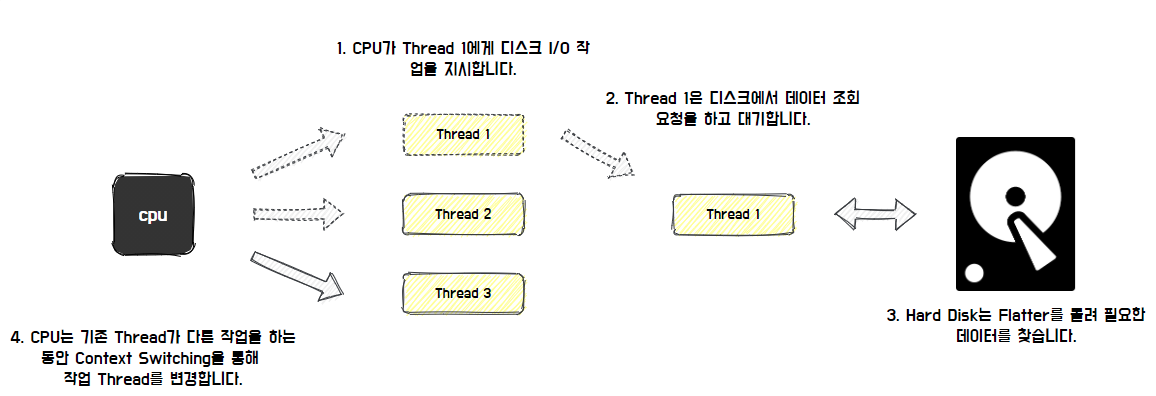
먼저, 디스크 경합 측면에서 성능적인 한계가 존재한다. 데이터베이스는 하드 디스크 하나당 하나의 I/O를 처리하기 때문에 Blocking이 발생한다. SSD를 사용하면 일부 병렬 처리가 가능하지만 이 또한 한계가 존재한다.
- 즉,특정 시점부터는 성능적인 증가가 Disk 병목으로 인해 미비해진다.
-
다음은 DB에서도 Context Swithcing으로 인한 성능적인 한계가 존재한다.
- 컨텍스트 스위칭에 대해 간단히 살펴보면 멀티 쓰레드 환경에서 CPU가 수 십, 수 백개의 쓰레드를 동시에 동시에 실행하는 것처럼 보이지만, 실제 CPU 코어는 한 번에 쓰레드 하나의 작업만 처리할 수 있다.
- 다음 쓰레드의 작업을 수행하기 위해서 컨텍스트 스위칭이 발생하는데 이 순간 작업에 필요한 쓰레드의 스택 영역 데이터를 로드하는 등 추가적인 작업이 필요하기 떄문에 오버헤드가 발생하게 된다.
그러므로 이상적인 쓰레드의 수는 CPU의 코어 수와 동일 할 떄, 컨텍스트 스위칭이 발생하지 않기 때문에 가장 빠른 성능을 보인다.
DB 입장에서 커넥션은 쓰레드와 어느 정도 일치한다고 볼 수 있따.
커넥션이 많다는 의미는 DB 서버가 쓰레드를 많이 사용한다는 것을 의미하고, 이에 따라 DB 서버의 컨텍스트 스위칭으로 인한 오버헤드가 더 많이 발생하기 때문에 Connection Pool을 아무리 늘리더라도 성능적인 한계가 존재한다. 이외에도 다양한 이유가 존재한다. (PostgreSQL Wiki : https://wiki.postgresql.org/wiki/Number_Of_Database_Connections)
그렇다면 Connection Pool의 적절한 크기는 어떻게 결정할까?
Connection Pool의 크기는 얼마가 적절할까?
Hikari CP의 공식문서에 따르면 connections = ((core_count * 2) + effective_spindle_count)라고 명시되어 있다.(여기서 말하는 core_count는 현재 사용하는 Cloud 서버 환경에서는 논리 CPU 개수와 동일하다.)
이는 PostgreSQL에서 Connection Pool Size를 선정하는 방식이지만 여러 DB에도 적용될 수 있다고 적혀있는 것을 보아 MySQL에서도 참고해볼 수 있을 것이라고 생각한다.
(core_count X 2) 를 하는 이유는 위에서 설명한 컨텍스트 스위칭 및 디스크 I/O 와 관련이 있다.
컨텍스트 스위칭으로 인한 오버헤드를 고려하더라도 DB에서 Disk I/O 혹은 DRAM이 처리하는 속도보다 CPU 속도가 월등히 빠르기 때문에 쓰레드가 Disk와 같은 작업에서 Blocking 되는 시간에 다른 쓰레드의 작업을 처리할 수 있는 여유가 생기게 된다.
이러한 여유 정도에 따라 멀티 스레드 작업을 수행할 수 있게 되고, Hikari CP가 제시한 공식에서는 계수를 2로 선정하여 Thread 개수를 지정하였다.
effective_spindle_count는 하드 디스크와 관련이 있다. 하드 디스크 하나는 spindle 하나를 가진다.
이에 따라 spindle의 수는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수를 말한다.
디스크가 16개 있는 경우 시스템은 동시에 16개의 I/O 요청을 처리할 수 있다. 물론 RAID 구성 방식에 따라서 달라질 수 있다. 해당 공식에서 디스크의 효율을 고려하여 spindle_count를 더해준 것으로 보인다.
최종적으로 CPU의 처리 효율과 디스크 처리 효율을 고려한 결과, ((core_count * 2) + effective_spindle_count) 공식을 통해 Connection의 개수를 추정할 수 있다고 알게 되었다.
이러한 공식이 무조건 성립하진 않지만 서버의 최초 pool size를 선정하는 기준으로써 사용한다면 유용할 것 같다.
실제 서비스에서 Connection Pool을 얼마나 영향을 미칠까?
MySQL 서버는 vCPU 2개와 SSD 1개를 가진 서버라고 가정해보자.
SSD를 사용하기 때문에 공식이 완벽하게 성립하지는 않지만 공식에 대입해보면 (2*2) + 1 이 되어 5개의 Connection Pool 크기를 도출해낼 수 있다. 그럼 Connection Pool의 개수를 5개로 지정한 후 성능을 측정해보자
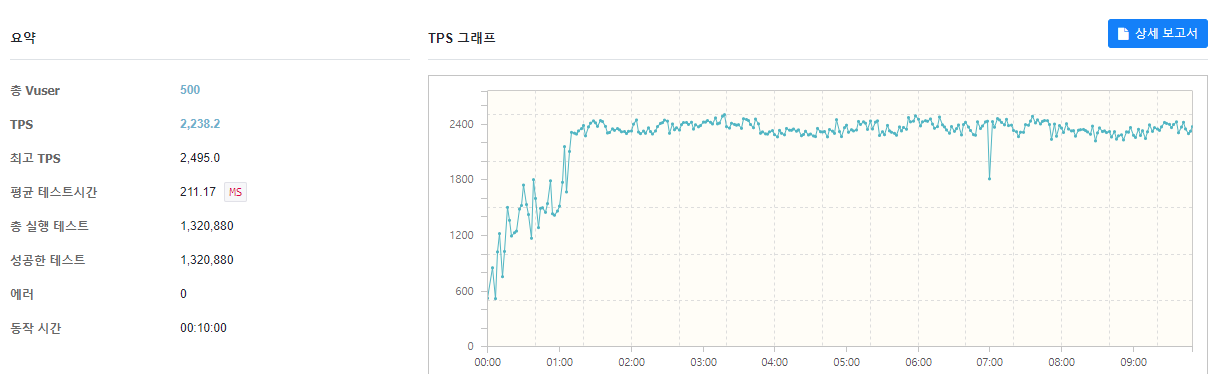
결과를 보면 약 2200 TPS 정도의 처리량과 210ms의 지연시간이 발생하는 것을 알 수 있다.
(단, Thread Pool의 개수는 default로 Connection Pool의 크기에 따라 변화만 측정하기 위해 변경하지 않았다.)
MySQL 서버의 CPU 사용량을 한 번 보면
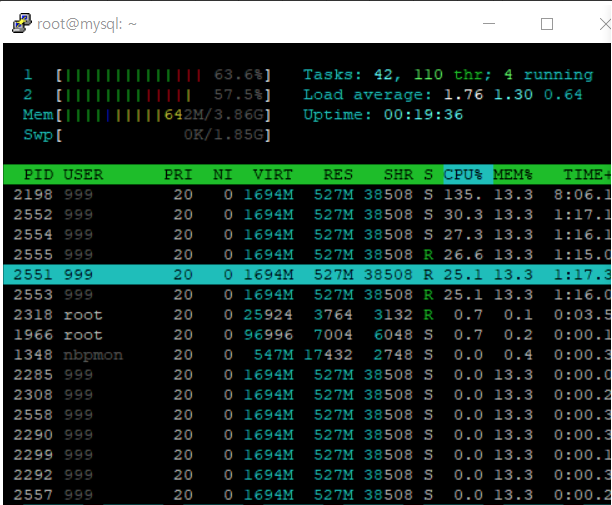
60퍼센트 정도의 CPU를 사용하는 것으로 볼 수 있다.
그렇다면 Connection Pool을 HickariCP의 default 크기인 10개로 늘려서 테스트해보자.
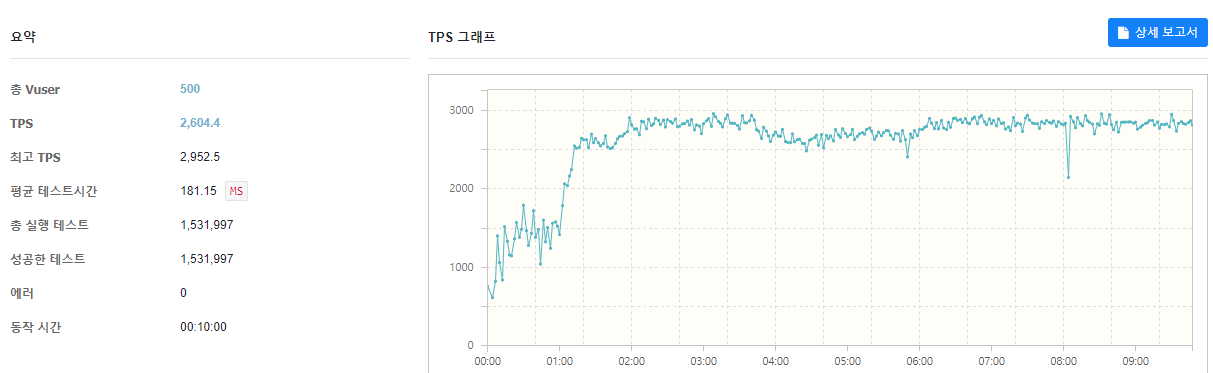
공식과는 다르게 10개로 늘리니 2600TPS로 증가하고, Latency도 180ms로 감소함을 볼 수 있다. (다양한 원인이 있겠지만 SSD를 사용하기 때문에 동시 I/O가 일부 가능해서 공식과 차이가 발생한 것이 아닐지 조심스레 추측해본다)
MySQL 서버의 CPU 사용량을 한 번 보면
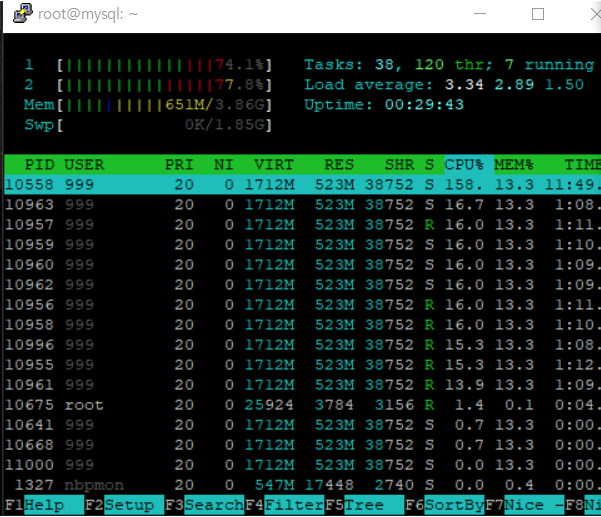
약 75% 정도로 증가함을 볼 수 있다. 그만큼 MySQL 서버가 더 많은 작업을 처리하고 있음을 알 수 있다.
다음은 Connection Pool을 50으로 늘려서 확인해보자
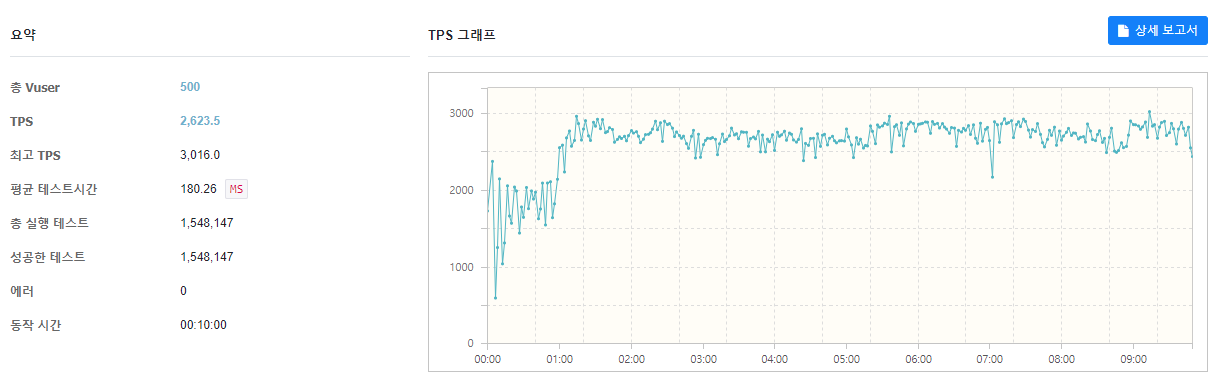
위의 결과에 따르면 처리량과 지연시간이 큰 변화가 없는 것으로 보아, Thread Pool의 크기가 default인 조건에서 현재 Connection Pool의 개수는 10개가 적절하다고 판단할 수 있다.
결과적으로 실제 Connection Pool의 크기를 조절하고 성능 테스트를 해봄으로써 현재 서비스에서 적절한 Connection Pool의 크기를 찾을 수 있다.
공식을 사용하는 것도 좋지만 실제 성능 테스트를 해봄으로써 적절한 Connection Pool Size를 찾는 과정이 더 중요함을 알 수 있었다.
결론
- Connection을 생성하는 과정은 3-way-handshaking을 해야 하기 때문에 시간상 비용이 비싼 작업이다.
- 반복되는 Connection 생성을 줄이기 위해서 Connection Pool 방식을 활용한다.
- Connection Pool이 적으면 Thread의 대기시간이 길어져 성능 저하가 발생하고, Connection Pool의 크기 증가에도 Context Switching, Disk I/O 등 다양한 원인에 의해서 한계가 존재한다.
- Connection Pool의 크기를 공식을 통해 추정할 수 있지만, 정확한 측정을 위해서는 성능 테스트를 진행해서 확인하는 과정이 필요하다.
