
1. Multitasking
멀티태스킹: 하나의 프로세서에 여러 프로세스를 실행하는 것. 동작되는 프로세스들이 모두 동시에 실행되는 환상을 제공한다.
- 협동형 멀티태스킹: 프로세스가 자발적으로 중단할 때까지 기다리는 방식
- 선점형 멀티태스킹: 타임슬라이스 등의 관리로 실행 중인 프로세스를 중지시키는 방식
2. Process Scheduler in Linux
리눅스 첫 버전부터 v2.4까지 간단하게 구현된 스케줄러는 v2.5 이후 O(1) 스케줄러를 사용했다. 그러나 유저와 상호작용이 많은 대화형 어플리케이션이 동작할 때는 성능이 낮은 문제가 발생하여, v2.6에는 Rotating Staircase Scheduler 등의 개선된 스케줄러가 도입되었다. 이후 v2.6.23에서는 CFS가 O(1)을 대신하게 됐다.
3. Policy
스케줄러가 무슨 프로세스를 언제 사용하는가를 정하는 것은 정책에 따라 다르다.
I/O Bound vs. Processor Bound
- I/O Bound Process: 입출력 요청을 하고 기다리는데 대부분의 시간을 사용
- Processor Bound Process: 대부분의 시간을 코드를 실행하는데 사용
3.1. Process Priority
리눅스 커널은 nice, 실시간 우선순위 2가지의 우선순위 단위를 가진다.
- nice: -20~19의 값을 가지며, 클수록 우선순위가 낮다. nice 값이 낮을수록 더 많은 프로세서 사용 시간을 할당받는다. Mac OS X 등 Unix 기반 OS는 nice 값에 따라 타임슬라이스의 절대적인 크기를 조절하지만, Linux는 nice 값으로 타임슬라이스의 비율을 조절한다.
- 실시간 우선순위: 0~99까지의 범위를 가지며, 클수록 우선순위가 높다. 모든 실시간 프로세스는 일반 프로세스보다 우선순위가 높고, nice 값과는 별도이다.
3.2. Timeslice
Timeslice는 선점되기 전까지 CPU를 사용할 수 있는 시간을 말한다. 타임슬라이스 값이 크면 사용자와 상호작용하는 대화형 프로세스의 성능이 떨어지고, 반면에 타임슬라이스 값이 작으면 문맥 교환이 빈번하게 발생하여 이에 대한 overhead가 발생한다.
CFS는 프로세스마다 별도로 타임슬라이스를 직접 할당하지 않고 할당 비율을 조정한다. 이 비율은 nice값의 영향을 받는데, nice 값이 작을수록 높은 가중치로 인해 높은 비율의 프로세서 사용 시간을 할당받고, nice 값이 높을수록 그 반대가 된다.
CFS에서는 선점 스케줄러로, 실행 가능한 프로세스가 할당된 프로세서 시간 중 사용한 시간의 비율을 고려하여 선점 여부를 결정한다. 만약 실행중인 프로세스보다 사용한 비율이 낮다면 선점 후 CPU를 사용하게 된다.
3.3. Scheduling Policy in Action
만약 대화형 프로그램인 문서 편집기와 Processor Bound인 동영상 인코더가 있다고 가정하자. 대다수의 운영체제에서는 문서 편집기에 더 높은 우선순위를 부여하여 더 많은 타임슬라이스를 할당하므로써 편집기가 깨어날 때마다 선점 가능하도록 한다.
그러나 문서 편집기와 동영상 인코더가 같은 nice값을 가진다면, 각각의 프로세스는 50%의 프로세서 시간 비율을 할당받는다. 그러나 인코더는 주로 CPU를 많이 사용하므로 할당받은 50%의 프로세서 사용 시간을 많이 사용할 것이고, 문서 편집기는 사용자의 입력을 기다리는 시간이 대부분이므로 할당받은 프로세서 시간 중 조금밖에 사용하지 않을 것이다. 이 상황에서 만약 문서 편집기가 깨어나면, CFS는 문서 편집기가 할당받은 시간 중 사용한 시간의 비율이 동영상 인코더보다 작다는 것을 파악한 후 바로 선점하게 된다.
4. Linux Scheduling Algorithm
4.1. Scheduler Class
리눅스의 스케줄링 알고리즘은 모듈화modularization되어 있어 프로세스별로 다양한 스케줄링 알고리즘을 적용할 수 있는데, 이 모듈화된 스케줄링 알고리즘을 Scheduler Class라고 한다. 리눅스에서는 각 클래스를 이용하여 알고리즘을 교체하여 사용하고, 각 클래스마다 우선순위를 부여하여 어느 클래스의 스케줄링 알고리즘을 먼저 실행할 지 정한다(v2.6 /kernel/sched.c). 실행 가능한 프로세스가 있는 클래스들 중 가장 높은 우선순위의 클래스가 실행된다.
완전 공정 스케줄러CFS는 6.4 kernel 기준 /kernel/sched/fair.c에 구현되어 있는 일반 프로세스용 스케줄러 클래스로, SCHED_NORMAL로 정의되어 있다.
4.2. Process Scheduling in Unix
전통적인 유닉스 스케줄링에서는 timeslice, priority 개념을 이용하여 구현되는데, 더 높은 우선순위의 프로세스는 더 긴 타임슬라이스를 할당받아 실행된다. 그리고 우선순위는 nice값으로 사용자가 조절할 수 있고, 각 nice 값에 따라 타임슬라이스의 절대 값을 정하게 된다. 그러나 이 방식은 다음과 같은 문제를 야기한다.
- 작업 전환의 최적화가 어렵다. 만약 가장 낮은 나이스 값(+20)인 두 프로세스가 타임슬라이스를 5ms로 받았다고 하자. 그리고 105ms동안 실행되었을 때, 최적화가 된다면 이 시간 동안 두 프로세스의 문맥 교환은 2번 발생했을 것이지만, 타임슬라이스를 5ms로 고정되었기 때문에 10ms마다 문맥 교환이 2번 발생한다(너무 빈번히 발생). 또 다른 예로 기본 나이스 값(0)인 두 프로세스의 타임슬라이스가 100ms라고 할 때 100ms마다 작업 전환이 일어나게 되어, 응답 속도가 매우 느려지게 된다. 특히 대화형 프로세스인 경우에는 치명적이다.
- 현재 나이스 값에 따라, 나이스 값을 변동하는 일이 스케줄링에 큰 영향을 줄 수 있다. 나이스 값이 0과 1인 프로세스가 있다고 하면, 이들의 타임슬라이스는 100ms와 95ms로 둘의 차이는 미미하다. 반면 나이스 값이 18, 19인 프로세스의 타임슬라이스는 10ms, 5ms로 전자가 후자보다 두배만큼 할당받게 된다.
- 타임슬라이스가 시스템 타이머에 의존적이게 된다. 타임슬라이스의 값은 타이머 틱을 기준이 되므로 이 값의 배수로 정해져야 하며, 타임슬라이스의 최소 값은 타이머 틱보다 작을 수 없다. 따라서 시스템 타이머의 틱이 변하면 타임슬라이스의 값도 변동될 수 있다.
- 한 프로세스에게만 우대적일 수 있다. 이 경우는 대화형 프로세스를 최적화할 때 발생하는 문제인데, 해당 프로세스가 깨어났을 경우 타임슬라이스를 모두 사용하여도 작업을 즉시 실행될 수 있도록 우선순위를 올려주고 싶을 수 있다. 이때 이 프로세스가 잠들었다 깼다를 반복하면 해당 프로세스만을 계속 우대해주게 되어 다른 프로세스들에게 불공정하게 된다.
위 문제의 해결 방법은, 나이스 값에 해당하는 타임슬라이스를 선형이 아닌 기하학적인 값을 사용하거나, 타임슬라이스 단위를 틱에 영향을 받지 않도록 설정하는 것이다. CFS에서는 타임슬라이스 값을 무시하고 프로세스 별로 프로세서 시간 할당 비율을 정한다.
4.3. Fair Scheduling
<리눅스 커널 내부구조>를 참고하여 작성했다.
CFS는 시간 단위 내에 시스템 내의 프로세스에 공평하게 CPU 시간을 할당한다. 만약 n개의 실행 가능한 프로세스가 있을 경우 각 프로세스마다 시간단위 / n의 프로세스 시간을 할당한다.
리눅스는 vrumtime 개념을 도입하여 각 프로세스들이 공평하게 CPU를 사용할 수 있도록 하였다. 각 프로세스는 vruntime 값을 가지며, 해당 프로세스가 스케줄링될 때마다 실행 시간과 우선순위를 고려하여 vruntime 값이 증가한다.

vruntime이 증가하는 가중치는 위와 같이 우선순위에 따라 다르며, 해당 값은 task_struct->se->load->weight에 저장된다. 위 배열에 따르면 우선순위 -20의 가중치는 88761, 우선순위 0의 가중치는 1024이다.
vruntime은 vrumtime += physicalrumtime x weight(0) / weight(curr)에 따라 증가한다. 만약 우선순위 -20인 프로세스가 1초동안 실행했다면 1 x 1024 / 88761 = 0.0115초가 증가된다. 다른 예시로 우선순위 10인 프로세스가 1초동안 실행했다면 1 x 1024 / 110 = 0.3091초만큼 vrumtime이 증가된다. 이처럼 우선순위가 높은 프로세스는 1초를 실행했을 때 0.0115초가 실행된 것처럼 보이고, 반면에 우선순위가 낮은 프로세스는 동일한 1초를 실행했을 때 약 9초가 수행된 것처럼 보이도록 하여, 높은 우선순위의 프로세스가 시간 단위 내에서 더 많이 실행될 수 있도록 한다.
다음으로 CPU를 사용하게 되는 프로세스는 가장 작은 vruntime을 갖는 프로세스가 된다. 리눅스에서는 vruntime이 가장 작은 프로세스를 쉽게 찾기 위해 Red-Black Tree를 사용한다.
CFS는 시간 단위를 쪼개어 각 프로세스들에게 동일한 비율로 할당한다고 하였다. 이때 우선순위가 적용되는 방식은, 할당되는 비율을 우선순위에 따른 가중치의 값을 이용하여 조정하는 것이다. 예를 들어, 우선순위가 -20, 0인 두 프로세스가 있다면 각각의 타임슬라이스는 시간 단위 x 88761 / (88761+1024), 시간단위 x 1024 / (88761+1024)가 된다. 그러나 만약 프로세스의 수가 무한히 증가하여 타임슬라이스가 0에 가까워지면 오버헤드로 인한 문제가 극대화되므로 타임슬라이스의 최소 한도를 정했는데, 이를 minimum granualarity라 하며 기본 값은 1ms이다.

Linux Kernel Development에서는 CFS를 위 /Documentation/scheduler/sched-design-CFS.rst에 근거하여 기술한다.
5. Linux Scheduling Implementation
5.1. Time Accounting
Unix에서는 타임슬라이스를 이용하여 스케줄링하므로 프로세스의 실행 시간을 기록한다. 그리고 타임슬라이스가 0이 되면, 타임슬라이스가 남아 있는 다른 프로세스가 실행하게 된다.
5.1.1. Scheduler Entity Structure

타임슬라이스를 사용하지 않는 CFS 또한 프로세스의 실행 시간을 기록한다. 따라서 6.4 kernel 기준 /include/linux/sched.h에 정의된 sched_entity에 프로세스와 관련된 스케줄러의 정보를 저장한다. 이 구조체를 스케줄러 단위 구조체라고 한다.

스케줄러 단위 구조체는 task_struct 내의 se field에 있다.
5.1.2. Virtual Runtime
vruntime의 상세한 설명은 Fair Scheduling에서 기술했다.
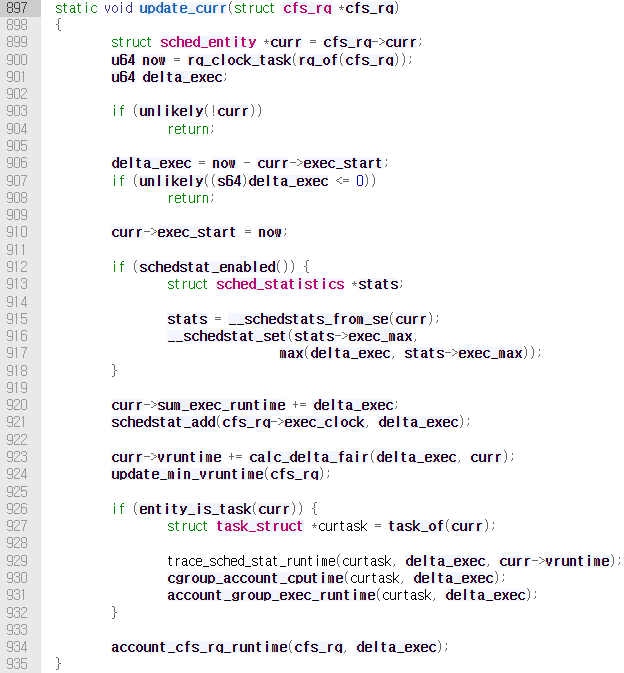
vruntime을 업데이트하는 함수는 /kernel/sched/fair.c의 update_curr()이다(6.4 kernel). 현재 시간 now에서 run queue에서 실제로 running하는 entity curr의 실행 시작 시각 curr->exec_start을 뺀 값을 delta_exec에 저장한다. 그리고 이 값을 curr->sum_exec_runtime에 더하고 있다. 프로세스의 총 실행 시간을 계산하는 것으로 추측된다.
그 후 calc_delta_fair()의 호출로 vruntime이 증가한다. 해당 함수는 아래와 같이 정의되어 있다.

se->load.weight는 struct sched_entity se->struct load_weight load->unsigned long weight을 가리키는 것으로, 현재 vruntime이 계산되어야 하는 프로세스의 가중치를 저장한다. 만약 가중치가 nice 0의 가중치가 아니라면 __calc_delta()를 호출하여 physicalrumtime x weight(0) / weight(curr)을 계산하고, 그렇지 않으면 weight(0) / weight(curr)은 1이므로 delta만 반환한다.
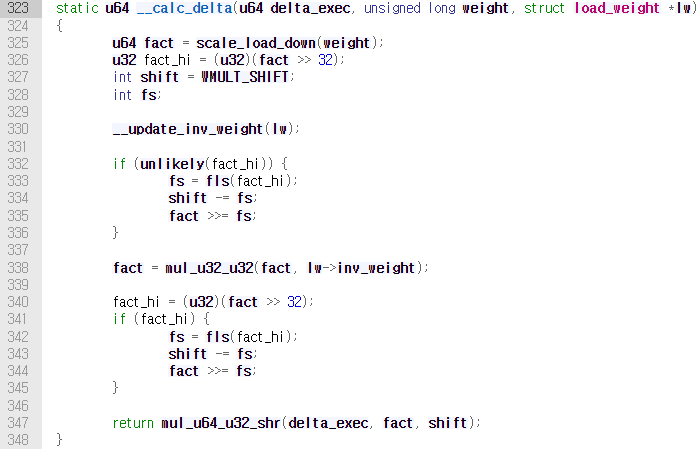
나눗셈 연산을 구현하기 위해 shift 연산을 사용한 것으로 보인다.
update_curr()은 시스템 타이머에 의해 주기적으로 호출되거나, 프로세스의 상태가 실행 가능/대기 상태로 변화하였을 경우에도 호출된다.
5.2. Process Selection
앞서 기술했듯이, CFS는 vruntime이 가장 작은 프로세스를 다음에 실행할 프로세스로 선택한다. 이를 위해 리눅스에서는 rbtree라고 하는 Red-Black Tree로 각 프로세스들의 vruntime을 관리하여, vruntime 값이 가장 작은 프로세스를 효율적으로 탐색할 수 있도록 한다.
5.2.1. Picking the Next Task
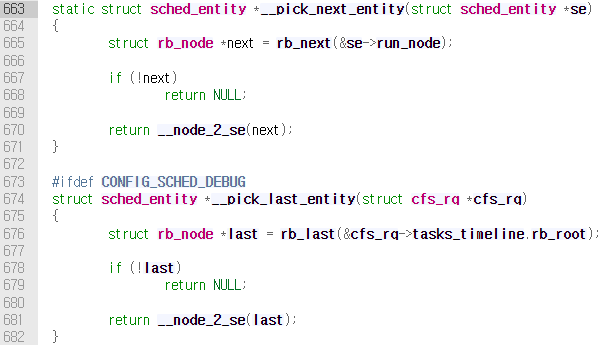
CFS에서 다음 프로세스를 선택하기 위해서는 /kernel/sched/fair.c에 정의되어 있는 __pick_next_entity()를 호출한다. 이 함수는 직접 rbtree를 탐색하지 않고 캐시되어 있던 left most node에 접근하여 반환한다. 만약 접근한 노드가 NULL이면 트리에 노드가 존재하지 않는 것이므로 실행 가능한 프로세스가 없다는 뜻이다. 따라서 이 경우 CFS는 비가동idle 작업을 실행한다.
5.2.2. Adding Processes to the rbtree
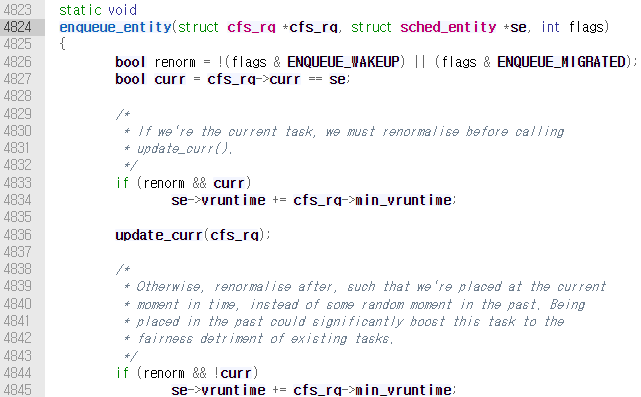
rbtree에 프로세스를 추가하는 경우는 프로새스가 새로 생성되거나 wakeup되어 실행 가능한 상태가 될 때이다. rbtree에 추가하는 작업은 /kernel/sched/fair.c의 enqueue_entity()가 담당한다.
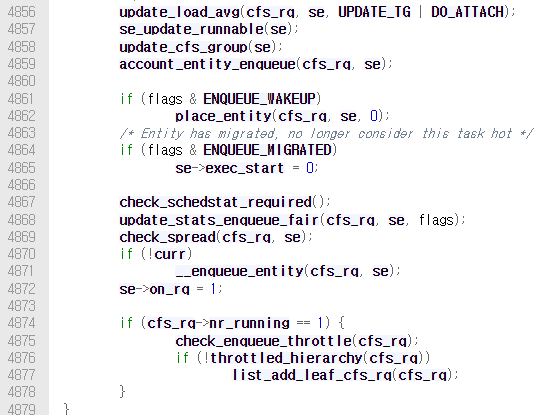
실제로 rbtree에 프로세스가 추가되는 작업은 enqueue_entity() 내에서 __enqueue_entity()->rb_add_cached()를 호출하여 진행된다.

comment에 명시되어 있듯이 rb_add_cached()는 leftmost cached tree에 node를 추가하는 함수이다. 인자로 전달된 &cfs_rq->tasks_timeline은 struct rb_root_cache*이다.
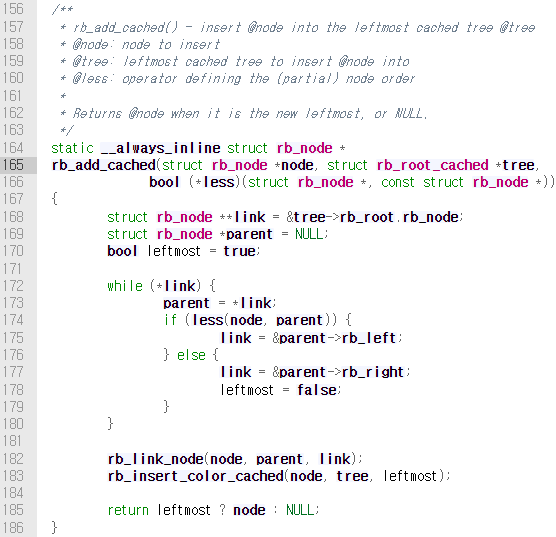
5.2.3. Remove Processes from the rbtree

rbtree에서 프로세스를 제거하는 함수는 dequeue_entity()이다. 이 함수 내부에서 __dequeue_entity()함수가 호출되어 rbtree에서 노드가 제거된다.

__enqueue_entity()함수와 마찬가지로 leftmost cached tree 관련 함수를 호출한다.
5.3. Scheduler Entry Point
scheduler가 스케줄링하도록 하는 함수는 v6.4.3 kernel 기준 /kernel/sched/core.c에 정의되어 있는schedule() 함수다. 이 함수를 통해 커널 내부에서 스케줄링을 동작시켜 다음 실행할 프로세스를 선택할 수 있다.

위 함수에서는 __schedule()함수를 호출하고, 이 함수에서 다시 pick_next_task()함수를 호출한다.

pick_next_task()는 가장 높은 우선순위의 스케줄러 클래스부터 순서대로 가장 높은 우선순위의 태스크를 선택한다. 이 함수에서 __pick_next_task()를 호출한다.
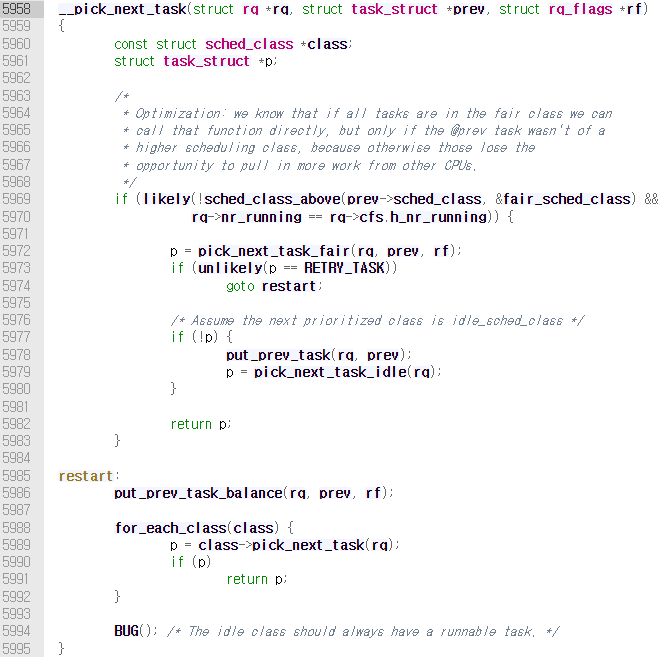
5969번째 줄에서, 전체 시스템에서 동작하는 프로세스 수와 cfs가 관리하는 프로세스의 수가 동일하다면 pick_next_task_fair()함수를 이용하여 효과적으로 태스크를 찾는다. 그리고 5988번째 줄에서 각 클래스를 순서대로 태스크를 선택하도록 하는 코드가 있다.
5.4. Sleeping and Waking Up
프로세스는 특정 이벤트가 발생할 때까지 대기하게 되는데, 이때의 상태는 TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE이 있다.
태스크가 대기 상태에 진입하기 위해 다음 과정을 거친다.
- 대기 상태로 상태 값 설정
- 대기열에 태스크 추가
rbtree에서 태스크 삭제schedule()을 호출하여 실행 가능한 태스크를 실행
반대로 태스크가 깨어날 경우 위 과정을 역순으로 진행한다.
- 실행 가능 상태로 상태 값 설정
- 대기열에서 태스크 제거
rbtree에 태스크 추가
5.4.1. Wait Queues
대기열은 이벤트가 발생하기를 기다리는 태스크들의 리스트이고 /include/kernel/wait.h에서 wait_queue_head_t로 type defined되어 있다. 대기열을 정적으로 생성하는가, 혹은 동적으로 생성하는가에 따라 대기열 생성 방법이 나뉜다.

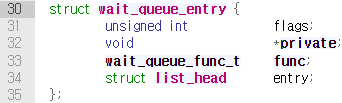
대기열을 정적으로 생성할 경우 DECLARE_WAITQUEUE() 매크로 함수를 사용하면 된다. 해당 매크로에서는 또 다른 매크로 함수 __WAITQUEUE_INITIALIZER()을 호출하여 struct wait_queue_entry를 생성한다. 대기열의 head node를 초기화하는 코드인 듯 하다.


init_waitqueue_head()를 매크로 함수를 사용하여 동적으로 생성할 수 있다. 해당 매크로 함수에서는 __init_waitqueue_head()함수를 호출한다.
대기와 깨우기를 실행하는 인터페이스가 존재하지만 이를 사용할 경우, 혹은 대기/깨우기 작업이 잘못 구현되는 경우 경쟁 상태Race Condition가 발생할 수 있고, 특정 이벤트가 발생하여 깨워져야 하는 태스크가 계속 대기 상태에 걸릴 수 있다. 따라서 커널에서는 아래와 같은 휴면 처리 과정을 권장하므로, 커널 내에서 대기/깨우기 로직을 구현할 때는 이 권장 사항을 따르도록 한다.

DEFINE_WAIT()매크로 함수를 사용하여 대기열에 추가할 노드struct wait_queue_entry를 생성한다. 이 매크로는 또 다른 매크로 함수DEFINE_WAIT_FUNC를 이용하여 노드를 생성한다.

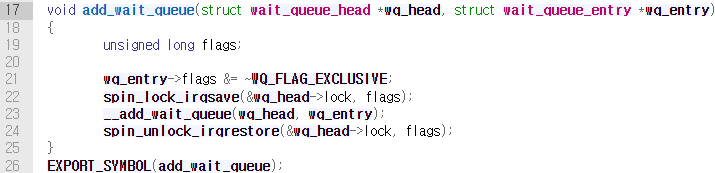
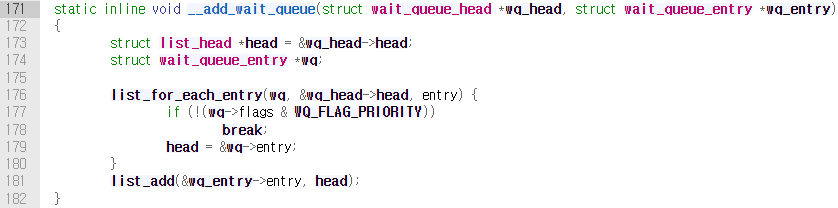
add_wait_queue()함수를 호출하여 대기열에 노드를 추가한다. 해당 함수 내부에서는__add_wait_queue()를 호출하여 대기열에 추가하는 작업을 진행한다.
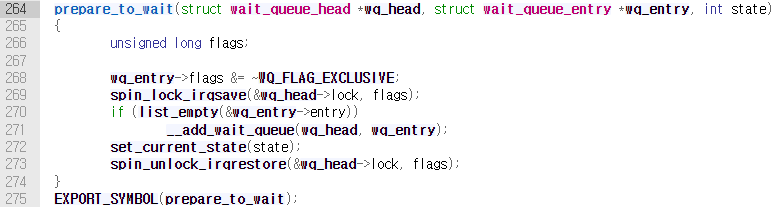
prepare_to_wait()함수를 호출하여 태스크의 상태를TASK_UNINTERRUPTIBLE또는TASK_INTERRUPTIBLE로 변환한다. 이 함수 내에서는 태스크에 해당하는 엔트리 노드의flag에서WQ_FLAG_EXCLUSIVE를 disable하며, 이 노드가 대기열에 없을 경우__add_wait_queue()를 호출하여 대기열에 다시 넣는 작업을 진행하기도 한다. 또한set_current_state()매크로 함수를 이용하여 현재 태스크의 상태를 state 변수 값으로 바꾼다. 이 state에 들어가는 변수의 값은TASK_INTERRUPTIBLE이나TASK_UNINTERRUPTIBLE일 것이다.
- 태스크의 대기 상태가
TASK_UNINTERRUPTIBLE이면 시그널을 수신하여 깨어날 수 있다. 이를 의사 각성Spurious Wake Up이라 한다. 그러므로 수신받은 시그널에 대한 처리를 진행한다. - 태스크가 깨어나면, 의사 각성으로 깨어났을 수도 있으므로 다시 한 번 조건이 만족되는지 확인 후 loop에서 벗어난다. 그렇지 않다면
schedule()을 호출한다. - 조건이 만족되었을 경우
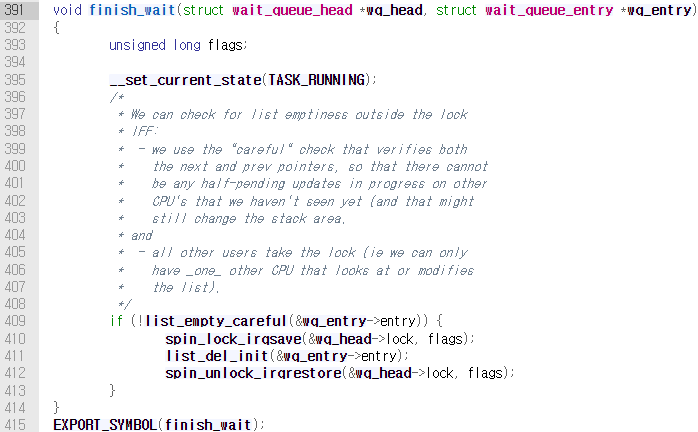
finish_wait()함수를 호출한다. 이 함수에서는 태스크의 상태를TASK_RUNNING으로 변경하고,/include/linux/list.h에서 정의된list_del_init()→list_del_entry()→__list_del()의 호출로 리스트에서 해당 태스크의 엔트리 노드를 제거한다.
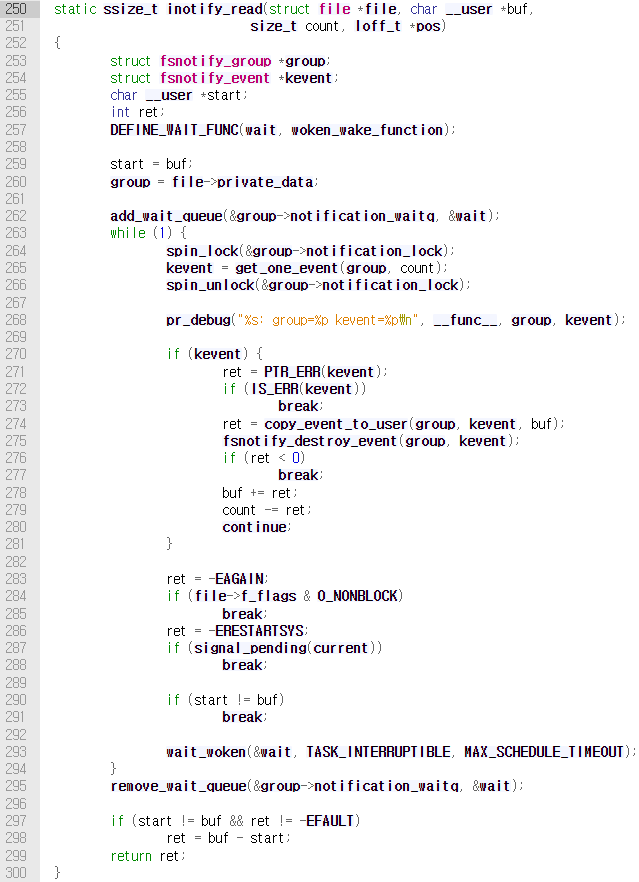
책에서 들고 있는 예시 코드는 v6.4.3 kernel의 /fs/notify/inotify/inotify_user.c이다.
in v6.4.3 kernel
최신 stable 커널인 v6.4.3 kernel에서는 위와 같은 휴면, 깨우기의 구현 방법을 권장한다. 이는 Nested Sleeping Problem으로 v3.19-rc에서 발견된 문제로 수정된 결과이다.
The problem with nested sleeping primitives: https://lwn.net/Articles/627930/
5.4.2. Waking Up

태스크가 깨어나도록 하는 일은 wake_up() 매크로 함수가 담당한다. 이 함수는 대기열의 모든 태스크를 깨운다. 이 매크로 함수는 __wake_up() 함수를 호출하고, 이 함수에 의해 __wake_up_common_lock()→__wake_up_common()이 호출된다.

해당 함수의 내부에서는 대기열을 순회하면서 각 엔트리의 func를 호출하는데, 이 함수 포인터는 위의 inotify_read()에서는 woken_wake_function()으로 설정되어 있다. 해당 함수는 default_wake_function() 함수의 반환 값을 반환하는데, 이 함수 내부에서는 try_to_wake_up()의 반환 값을 리턴한다.



따라서 결국에는 try_to_wake_up()이 호출되는데, 해당 함수는 태스크의 상태를 TASK_RUNNING으로 바꾼다.

또한 이 함수에서 ttwu_queue() 함수를 호출하는데, 해당 함수에서는 ttwu_do_activate()를 호출한다.
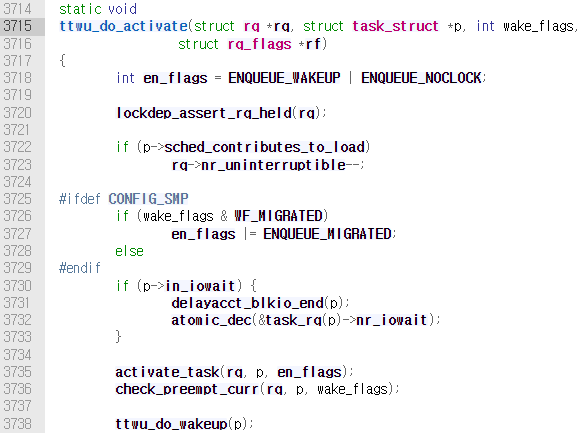
해당 함수에서는 check_preempt_curr()와 activate_task()를 호출한다.

먼저 호출되는 check_preempt_curr() 내에서는, sched_class_above() 매크로 함수를 통해 wakeup된 태스크와 현재 실행중인 태스크의 우선순위를 비교하고, wakeup된 태스크의 우선순위가 더 높으면 resched_curr()를 호출한다.
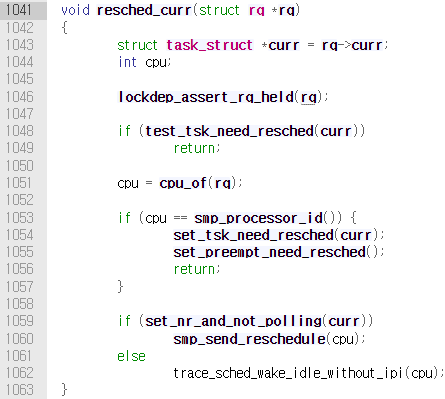
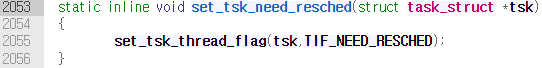

이 함수에서는 set_tsk_need_resched()→set_tsk_thread_flag()를 호출하여 태스크의 flag에 TIF_NEED_RESCHED를 set한다. 그리고 set_preempt_need_resched()를 호출하여 선점한다.
TIF_NEED_RESCHED는 struct thread_info→flag의 특정 bit이다.
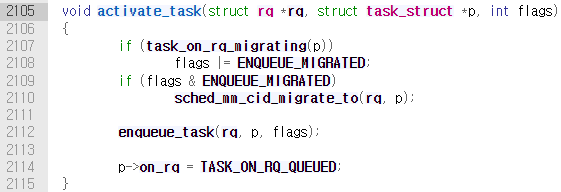
그 다음 호출되는 activate_task()를 보겠다. activate_task()함수 내에는 enqueue_task()를 통해 wakeup된 태스크를 런 큐인 rbtree에 추가한다.
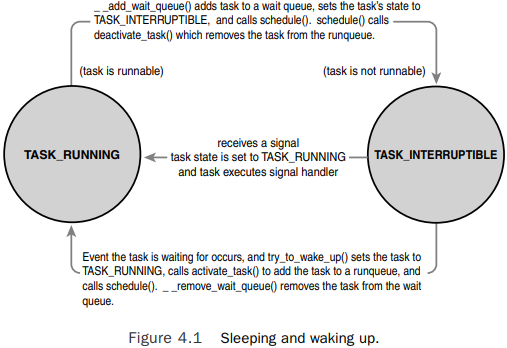
책에서는 위와 같이 휴면/깨우기 과정을 도시했다.
sleep하고자 하는 태스크는 위 예시들에서 보았듯이 schedule()를 호출하게 되는데, 이 함수는 __schedule()→deactivate_task()를 호출한다.

이 함수에서는 rbtree에서 태스크를 제거하는 담당을 한다.
대기열에서 추가/제거 및 rbtree에 추가되는 과정은 위에 기술한 내용과 동일하다.
6. Preemption & Context Switch
태스크가 다른 태스크에게 CPU를 양도하면 문맥 교환Context Switch이 발생하는데, 이는 기존 태스크의 가상 메모리 매핑과 프로세서 정보Hardware Context를 실행될 태스크의 것으로 교체한다.
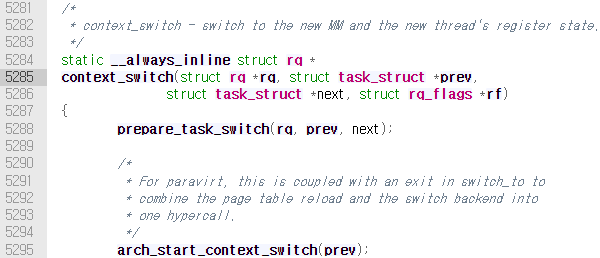
문맥 교환을 진행하는 작업은 /kernel/sched/core.c의 context_switch()함수가 담당한다.

메모리 맵을 스위칭하는 기존 태스크와 새로 실행될 태스크가 user 또는 kernel task인지에 따라 로직을 구현한 것을 확인할 수 있는데, task_struct→mm field가 null일 경우 kernel task이다(3장 참고). 이 로직에서 membarrier_switch_mm()을 호출해 메모리 배리어를 스위칭하고, switch_mm_irqs_off()를 호출해 메모리 맵을 교환하는 것으로 보인다.

그리고 /arch/x86/include/asm/swtich_to.h의 switch_to() 매크로 함수를해 스택과 프로세서 정보 등의 하드웨어 정보를 스위칭한다.


switch_to() 매크로는 /arch/x86/entry/entry_x64.S의 __switch_to_asm 어셈블리 코드를 실행한다. 이 코드는 기존 태스크인 %rdi의 스택에 레지스터 세트를 push하여 백업한 후, 실행될 태스크인 %rsi의 스택과 스위칭한다. 그리고 %rsi에서 다시 pop하여 이 태스크의 레지스터 세트를 복원한다.
TASK_threadsp 매크로는 task descriptor 기준으로 stack pointer의 offset을 나타낸다. 정확히는
task_struct→thread_struct thread→spfield를 나타낸다.
Austin Kim님의 답변: https://kldp.org/node/161302


위에 기술한 대기/깨우기 과정에서, 깨어난 태스크가 현재 실행되는 태스크보다 우선순위가 클 경우 TIF_NEED_RESCHED flag가 설정되었다. 이런 방식으로 선점이 필요할 경우 해당 flag가 설정되는데, 커널에서는 유저 공간으로 복귀하거나 인터럽트 처리를 완료할 때마다 이 flag bit을 확인하고, 설정되어 있으면 schedule()을 호출한다.
이 flag를 제어하는 함수는 아래와 같다.
set_tsk_need_resched():TIF_NEED_RESCHED설정clear_tsk_need_resched():TIF_NEED_RESCHED해제need_resched():TIF_NEED_RESCHED확인 후, 설정되어 있으면 true, 아니면 false 반환
6.1. User Preemption
사용자 선점은 커널 공간인 시스템 콜에서 유저 공간으로 복귀하거나 인터럽트 처리를 완료했을 때, TIF_NEED_RESCHED flag를 확인하고, 설정되어 있을 경우 schedule()을 호출하여 선점할 새 프로세스를 선택한다.
6.2. Kernel Preemption
커널 선점은 태스크의 preempt_count의 값이 0이거나, 커널이 대기 상태 혹은 명시적으로 schedule()을 호출했을 경우 발생한다. preempt_count는 태스크의 lock 카운트 변수이며, x86 기준 /arch/x86/include/asm/current.h의 pcpu_hot에, aarch64 기준 /arch/arm64/asm/thread_info.h의 thread_info에 정의되어 있다.
7. Real Time Scheduling Policy
실시간성 태스크를 위해 리눅스는 일반적인 스케줄링 클래스SCHED_NORMAL과 별개로 두 가지의 실시간 스케줄링을 제공한다.
SCHED_FIFO: 이 스케줄러는 타임슬라이스가 없어 현재 실시간 태스크가 양보하지 않는 이상 무한히 실행 가능하다.SCHED_NORMAL의 태스크보다 항상 먼저 실행되며, 선점이 가능한 태스크는 우선순위가 높은SCHED_FIFO,SCHED_RR이다. 그리고 선입선출 스케줄러이므로,SCHED_FIFO클래스 내에 우선순위가 동일한 태스크가 여러 개 존재한다면 순차적으로 실행한다.SCHED_RR:SCHED_FIFO에 타임슬라이스 개념을 추가한 이 스케줄러는 태스크가 할당된 타임슬라이스를 모두 사용할 때까지 우선순위가 높은 태스크를 제외한 나머지 태스크는 선점하지 못한다. 우선순위가 낮은 태스크는 현재 실행되는 실시간 태스크가 타임슬라이스를 모두 사용해도 선점하지 못한다.
실시간 우선순위는 0~MAX_RT_PRIO-1 사이의 값을 가질 수 있고, -20~19의 값을 갖는 nice의 범위는 MAX_RT_PRIO~MAX_RT_PRIO+40 사이의 값을 가진다.
8. Scheduler-Related System Calls
리눅스에서는 스케줄러를 설정할 수 있는 인터페이스를 제공하는데, 제공되는 시스템 콜은 아래와 같다.

8.1. Scheduling Policy and Priority-Related System Calls
sched_getscheduler(),sched_setscheduler(): 태스크의 스케줄링 정책 및 실시간 우선순위를 읽거나 설정

sched_getparam(),sched_setparam():task_struct의rt_priority를sched_param로 변환하며 태스크의 실시간 우선순위를 읽거나 설정

sched_get_priority_max(),sched_get_priority_min(): 태스크가 스케줄링되는 스케줄링 정책에서 우선순위의 최대, 최소값

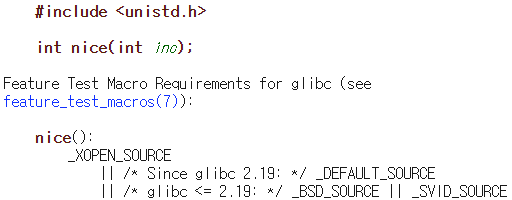
nice(): 일반 태스크의 정적 우선순위를 주어진 값만큼 증가. root user만이 음수를 전달하여 우선순위의 값을 낮출 수 있다.task_struct의prio,static_prio를 변경한다.
8.2. Processor Affinity System Calls
리눅스는 지속성Affinity를 지향하며 태스크가 되도록 같은 프로세서를 사용할 수 있도록 노력한다. 그러나 일부 태스크는 특정 프로세서에 실행되도록 설정할 수 있다. 태스크가 어느 프로세서에 실행될 수 있는지 나타내는 값은 task_struct의 cpus_mask이다. 이 필드의 각 비트들은 시스템에서 사용되는 프로세서 각각에 대응된다.
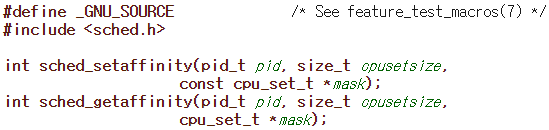
sched_getaffinity(),sched_setaffinity(): 태스크의cpus_mask를 읽거나 설정한다.
리눅스에서 새로 생성된 프로세스는 부모의 processor affinity를 물려받는다. 만약 processor affinity가 변경되면 migration thread가 태스크를 다른 프로세서로 옮긴다. 마지막으로 load balancer을 통해 태스크가 실행될 프로세서를 적절하게 선택한다.
8.3. Yielding Processor Time


현재 태스크가 CPU를 양보하기 위해 sched_yield() 시스템 콜을 사용할 수 있다. 해당 시스템 콜을 호출하면 호출한 태스크가 있는 activate array에서 제거하여 expired array에 추가한다. 이런 방식으로 선점을 유발하고 우선순위 목록의 뒤에 둘 뿐만 아니라 일정 시간동안 실행하지 않음을 보장한다. 애플리케이션이나 커널에서 이 함수를 사용하기 전에 양보할 수 있는 환경이 되는지 확인해야 한다.
커널에서는 yield() 함수를 호출하여 양보하는데,이 함수는 해당 태스크의 상태가 TASK_RUNNING일 경우 sched_yield()를 호출한다.

아주 중요한 정보를 얻었습니다, 감사합니다.