saving while working
state1 = tf.Variable(0, name="state1")
state2 = tf.Variable(10, name="state2")
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
save_path = saver.save(sess, "/tmp/model.ckpt")
print("Model saved in file: ", save_path)what if you want to save just one parameter
state1 = tf.Variable(0, name="state1")
state2 = tf.Variable(10, name="state2")
init_op = tf.global_variables_initializer()
saver = tf.train.Saver({"mys2": state2})
with tf.Session() as sess:
sess.run(init_op)
save_path = saver.save(sess, "/tmp/model1.ckpt")
print("Model saved in file: ", save_path)write and read exam
state1 = tf.Variable(1, name="state1")
state2 = tf.Variable(10, name="state2")
one = tf.constant(1)
new_value = tf.add(state2, one)
update = tf.assign(state2, new_value)
init_op = tf.global_variables_initializer()
saver = tf.train.Saver({"mys2": state2})
with tf.Session() as sess:
sess.run(init_op)
sess.run(update)
save_path = saver.save(sess, "/tmp/model1.ckpt")
print("Model saved in file: ", save_path)
print(sess.run(state1))
print(sess.run(state2))import tensorflow as tf
state1 = tf.Variable(0, name="state1")
state2 = tf.Variable(5, name="state2")
init_op = tf.global_variables_initializer()
saver = tf.train.Saver({"mys2": state2})
with tf.Session() as sess:
saver.restore(sess, "/tmp/model1.ckpt")
print("Model restore")
# sess.run(init_op)
# sess.run(update)
# print(sess.run(state1))
print(sess.run(state2))it is not double speed when you use two gpu.
tensorflow version2 command :
sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v45 "tensorflow==2.3.1"tensorflow 2.x mse way1
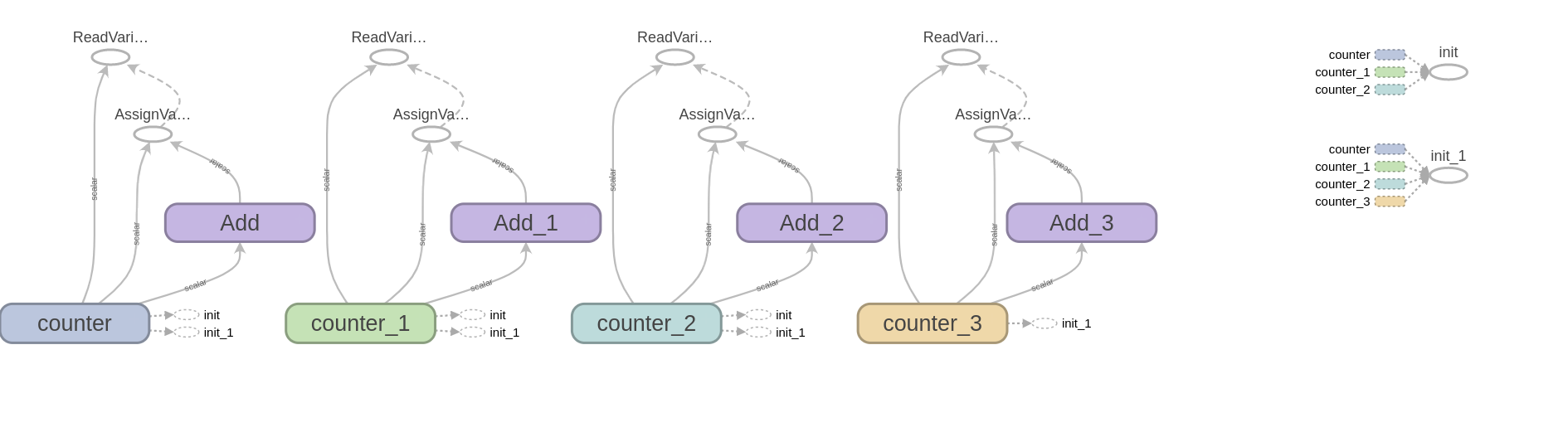
import tensorflow as tf
import tensorflow.compat.v1 as tf1
tf1.disable_eager_execution()
state = tf.Variable(0, name='counter')
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf1.assign(state, new_value)
init_op = tf1.global_variables_initializer()
writer = tf1.summary.FileWriter(
'/tmp/log', graph=tf1.get_default_graph())
with tf1.Session()as sess:
sess.run(init_op)
print(sess.run(state))
for _ in range(3):
sess.run(update)
print(sess.run(update))add_graph
.png)
import tensorflow as tf
import tensorflow.compat.v1 as tf1
import numpy as np
tf1.disable_eager_execution()
tf1.reset_default_graph()
x_data = np.random.rand(100).astype('f')
y_data = x_data * .1 + .3
W = tf.Variable(tf.random.uniform([1], -1., 1.))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
writer = tf1.summary.FileWriter('/tmp/log1', graph=tf1.get_default_graph())
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf1.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
init = tf1.global_variables_initializer()
sess = tf1.Session()
sess.run(init)
# Fit the line.
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
sess.close()
#learns best fit is W: [0.1], b: [0.3]tensorflow 2.x SKcode
way = 3 is the best
import tensorflow as tf
import numpy as np
import tensorflow.compat.v1 as tf1
tf1.enable_eager_execution()
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * .1 + .3
init = lambda : (tf.Variable(tf.random.uniform([1],-1.,1.), name='Weight'), tf.Variable(tf.zeros([1])))
W, b = init()
lr = lambda x: W * x + b
mse = lambda yp, yt : tf.reduce_mean(tf.square(yp - yt))
way = 3
if way == 1:
for step in range(201):
with tf.GradientTape() as tape:
y = lr(x_data)
loss = mse(y, y_data)
grads = tape.gradient(loss, [W,b])
if step % 20 == 0:
print('\n\rW =', W.numpy(), '\n\rb =', b.numpy(), '\n\rg[0] =', grads[0].numpy(), '\n\rg[1] =', grads[1].numpy())
W.assign(W - 0.01 * grads[0].numpy())
b.assign(b - 0.01 * grads[1].numpy())
elif way == 2:
optimizer = tf.optimizers.SGD(learning_rate=0.1)
for step in range(201):
with tf.GradientTape() as tape:
y = lr(x_data)
loss = mse(y, y_data)
grads = tape.gradient(loss, [W, b])
process_grads = [g for g in grads]
grads_and_vars = zip(process_grads, [W,b])
if step % 20 == 0:
print('\n\rW =', W.numpy(), '\n\rb =', b.numpy(), '\n\rg[0] =', grads[0].numpy(), '\n\rg[1] =', grads[1].numpy())
W.assign(W - 0.01 * grads[0].numpy())
b.assign(b - 0.01 * grads[1].numpy())
optimizer.apply_gradients(grads_and_vars)
elif way == 3:
yp, yt = lr(x_data), y_data
optimizer = tf.optimizers.SGD(learning_rate=0.1)
for step in range(201):
if step % 20 == 0:
print('\n\rW =', W.numpy(), '\n\rb =', b.numpy())
mse_min = lambda : tf.reduce_mean(tf.square((W * x_data + b) - yt))
optimizer.minimize(mse_min, var_list=[W,b]) train
import tensorflow as tf
import numpy as np
import tensorflow.compat.v1 as tf1
tf1.enable_eager_execution()
X = [1., 2., 3.]
Y = [1., 2., 3.]
init = lambda : (tf.Variable(tf.random.uniform([1],-1.,1.), name='Weight'), tf.Variable(tf.zeros([1])))
W, b = init()
lr = lambda X: W * X + b
optimizer = tf.optimizers.SGD(learning_rate=0.1)
for step in range(201):
if step % 40 == 0:
print('\n\rW =', W.numpy(), '\n\rb =', b.numpy())
mse_min = lambda : tf.reduce_mean(tf.square(lr(X) - Y))
optimizer.minimize(mse_min, var_list=[W,b])Test
write test code below train
print('\n\rx = 2.5 : ', lr(2.5).numpy(), '\n\rx = 10 : ', lr(10).numpy(), '\n\rx = 2.5, 10 : ', lr([2.5, 10]).numpy(),)Sigmoid
import tensorflow as tf
import numpy as np
import tensorflow.compat.v1 as tf1
xy = np.loadtxt('../../train.csv', delimiter=',', unpack=True, dtype='float32')
print(xy)
x_data = xy[:-1]
y_data = xy[-1]
W = tf.Variable(tf.random.uniform([1, len(x_data)], -1.0, 1.0))
h = lambda X: tf.matmul(W, X)
hx = lambda X: tf.math.divide(1., 1.+ tf.math.exp(-h(X)))
cost = lambda Y: -tf.reduce_mean(Y * tf.math.log(hx(x_data)) + (1 - Y) * tf.math.log(1 - hx(x_data)))
rate = tf.Variable(.1)
opt = tf.optimizers.SGD(rate)
for step in range(2001):
with tf.GradientTape() as tape:
y = hx(x_data)
loss = cost(y_data)
grads = tape.gradient(loss, [W])
process_grads = [g for g in grads]
grads_and_vars = zip(process_grads, [W])
opt.apply_gradients(grads_and_vars)
if step % 200 == 0:
print(step, grads[0].numpy(), '\n\rW =', W.numpy())
print('-'*60)
print('[1, 2, 2] :' , hx([[1.], [2.], [2.]]))
print('[1, 2, 5] :' , hx([[1.], [2.], [5.]]))
print('[1, 2, 2], [1, 5, 5] :' , hx([[1., 1,], [2., 2.], [2., 5.]])>.5)
JH.velog