실습환경 세팅
실습환경은 groomide로 진행하였다.
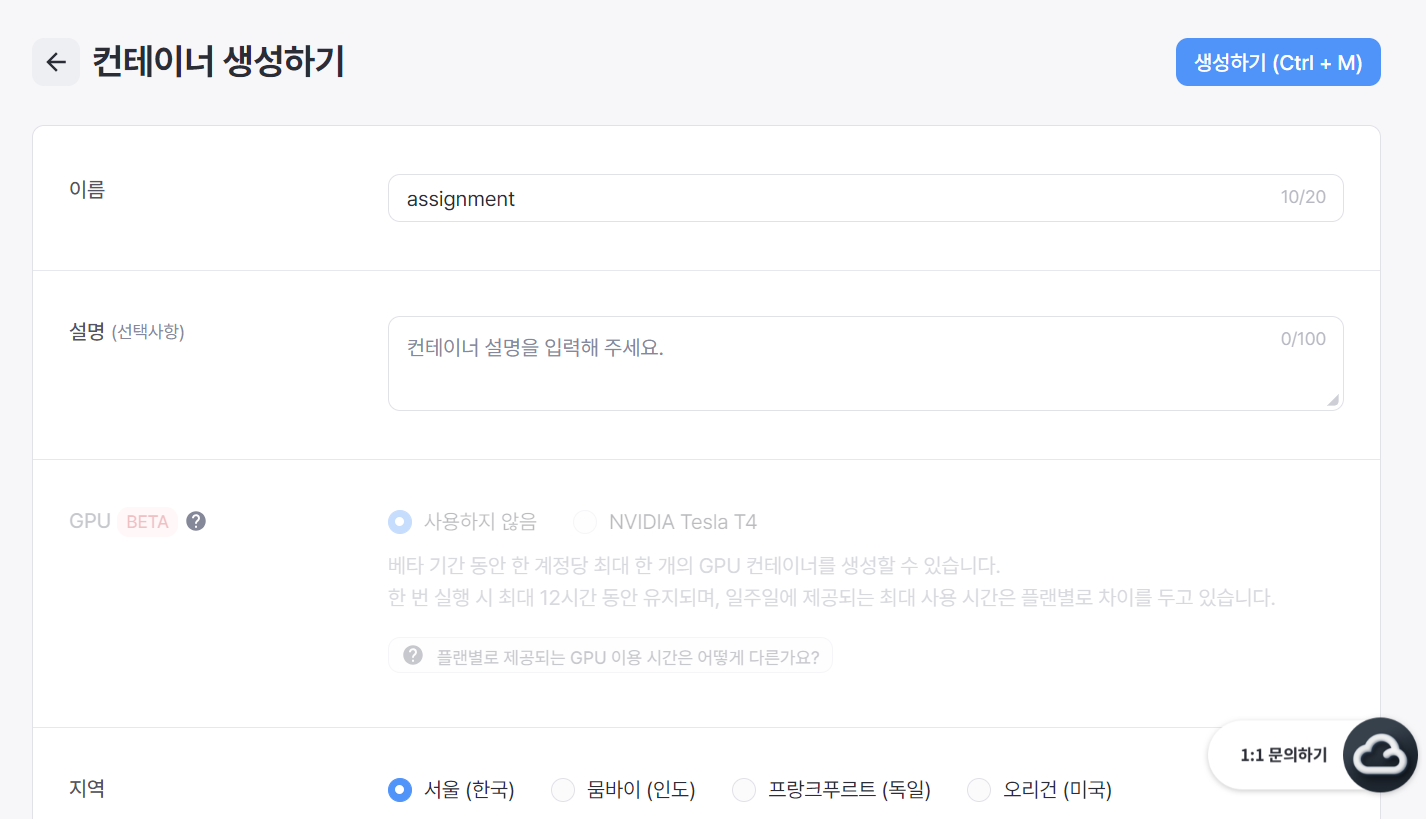
컨테이너 생성하기 메뉴에서 이름, 지역, 공개 범위, 소프트웨어 스택, vs code 등을 설정해준다.
groomide는 따로 vs code를 설치하지 않아도 사용할 수 있다는 장점이 있다.
생성이 끝나면 다음 화면을 볼 수 있다.
데이터 표현 실습
자료형 표현
먼저 자료형 표현 실습을 했다. c언어에 sizeof라는 함수를 사용하면 자료형에 대한 크기를 알 수 있다.
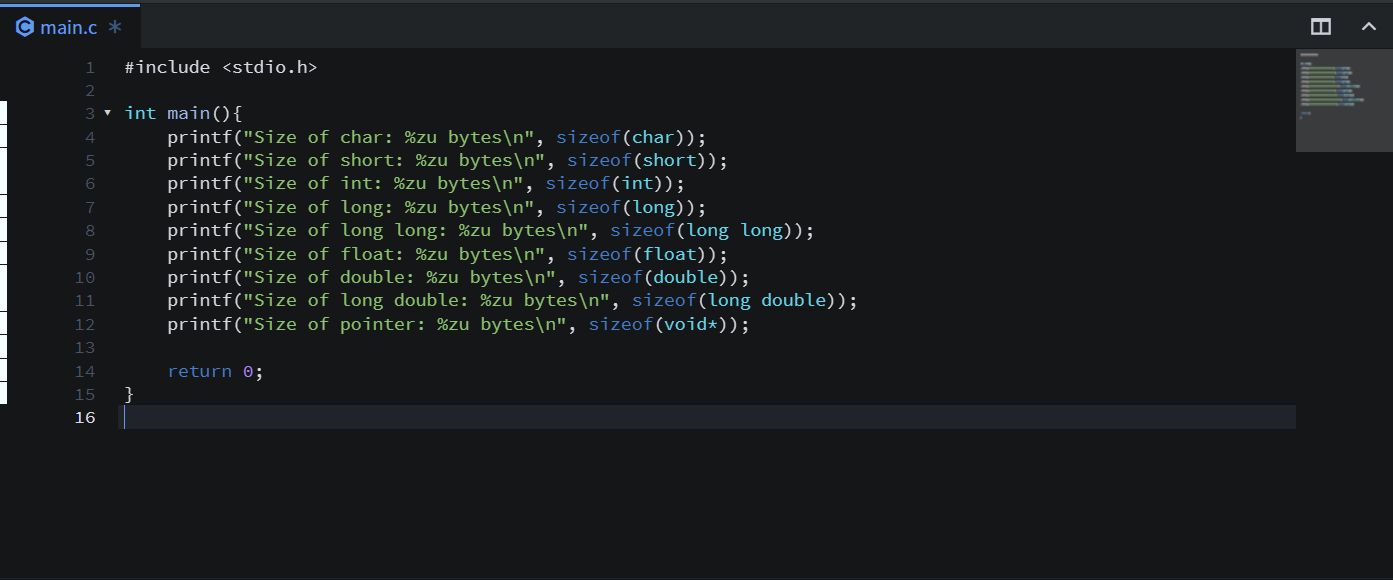
코드를 위와 같이 작성하고 결과를 확인한다.
리눅스 명령어를 입력하면 코드가 실행되어 결과를 볼 수 있다.

이외에도 자료형의 크기를 확인하려면 MSDN, cplusplus.com 사이트를 이용할 수 있다.
오버플로우, 언더플로우
오버플로우는 메모리의 표현범위를 초과하는 값을 저장시켰을 때 오류가 나면서 의도하지 않은 동작을 일으킬 수 있는 상황을 의미한다. 언더플로우는 오버플로우와 반대로 메모리가 표현할 수 있는 값보다 더 작은 값을 저장했을 때 발생하는 상황이다.
언더플로우를 재현했고 코드는 다음과 같다.
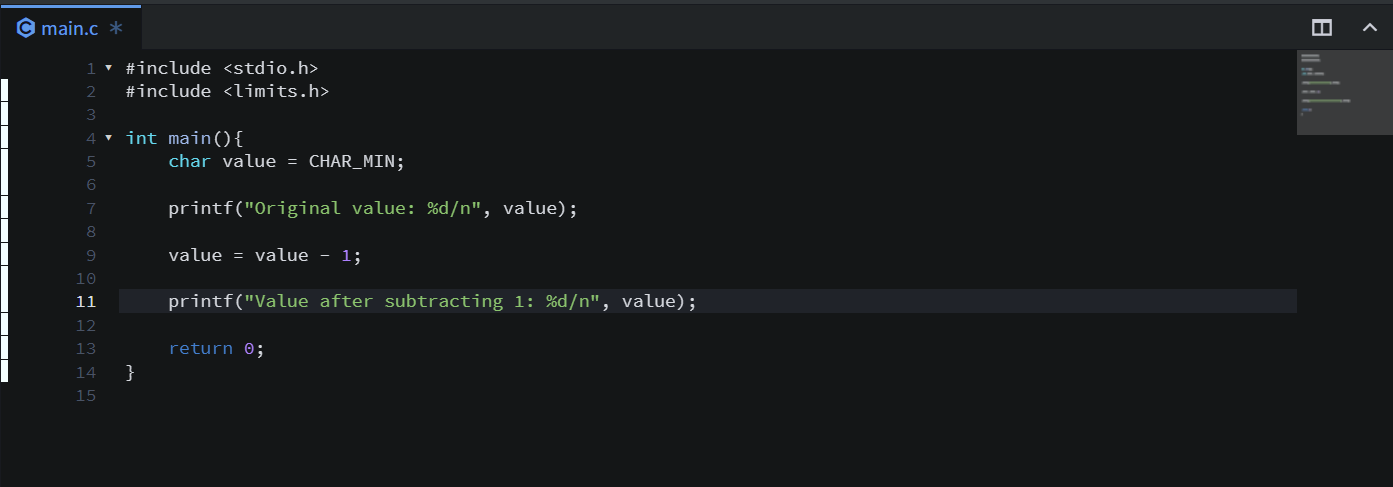
위 코드를 컴파일하고 gdb를 이용해서 main함수를 분석했다.
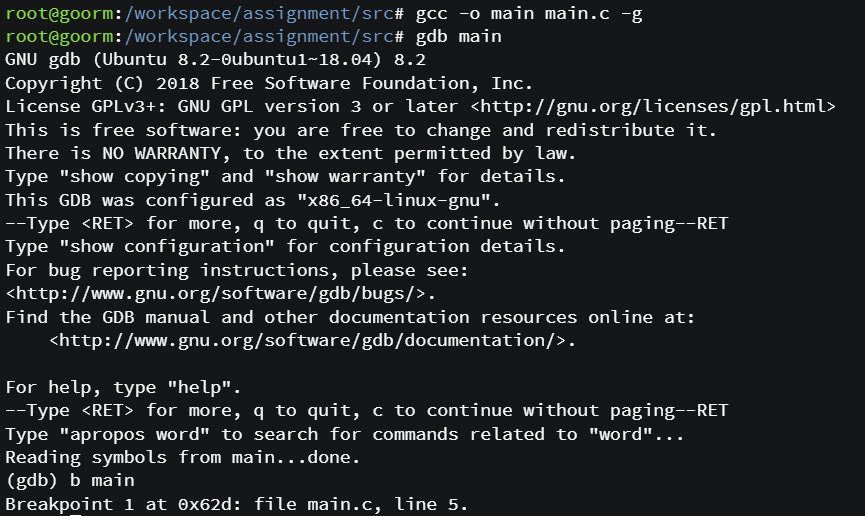
gdb에서 b main은 중단점을 설정하는 명령어이다.
이후에 r명령어로 프로그램을 실행시킨 후 n 명령어로 한 중단점 이후부터 한줄씩 실행한다.
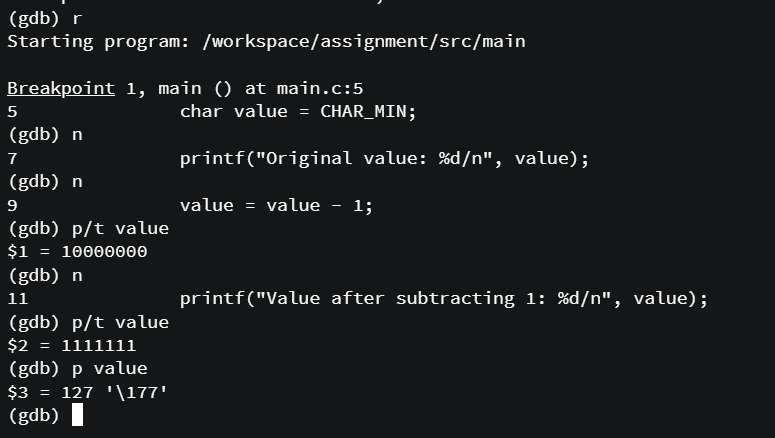
p/[출력형식][변수명] 명령어는 출력형식에 맞추어 변수값을 출력하는데, 여기서는 p/t value를 사용했으므로 value의 값을 2진수로 출력하라는 뜻이다. 처음 나온 10000000은 -128이고 1111111은 127이다.
p [변수명] 명령어는 변수의 값을 출력하라는 명령어로 여기서는 value의 값인 127을 출력하였으며 '\177'이 8진수로 127이다.
따라서 CHAR_MIN -1 에서 언더플로우가 발생한다는 것을 알 수 있다.
비트연산
특정 위치의 비트만 끄는, 1 -> 0으로 바꾸는 코드를 작성해본다.

is_bit_set 함수 : 주어진 비트값이 1인지 확인
set_bit 함수 : 특정 위치의 비트를 1로 설정하는 함수
여기까지는 예제에서 주어진 함수 그대로이고 내가 새로 작성한 코드는 clear_bit 함수이다.
어떤 비트들이 있을 때 비트를 끄고 싶은 위치까지 1로 밀어주고(나머지 비트는 모두 0) not 연산으로 모든 반전시킨 다음, 기존의 비트와 and 연산을 해주면 나머지 위치의 비트는 다 그대로이지만 원하는 위치의 비트만 1에서 0으로 전환해 줄 수 있다.
이 clear_bit 함수롤 삽입하고 결과를 확인해도 올바르게 작동한다. 출력 화면은 다음과 같다.

프로그램 실행과정 실습
c언어가 기계어로
우리는 코드를 우리가 이해하기 쉬운 언어들, 여기서는 c언어와 같은 언어로 작성하지만, 이를 실행시킬 때에는 컴퓨터가 이해할 수 있는 언어인 기계어로 전환해 주어야 한다.
이 과정을 실습해 보았다.
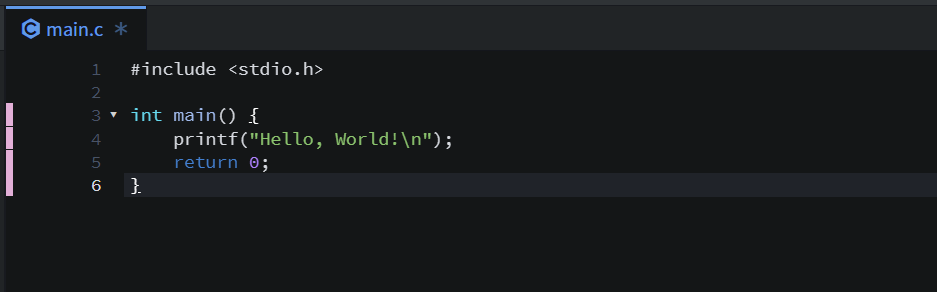
간단한 코드를 먼저 작성하고 리눅스 명령어를 입력해준다.
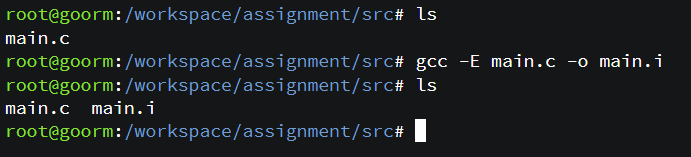
gcc 명령어로 main.i 파일을 생성해준다. .i 파일은 전처리 된 소스 코드 파일을 의미한다. 컴파일 되기 전 단계이다.
확인해보면 다음과 같다.
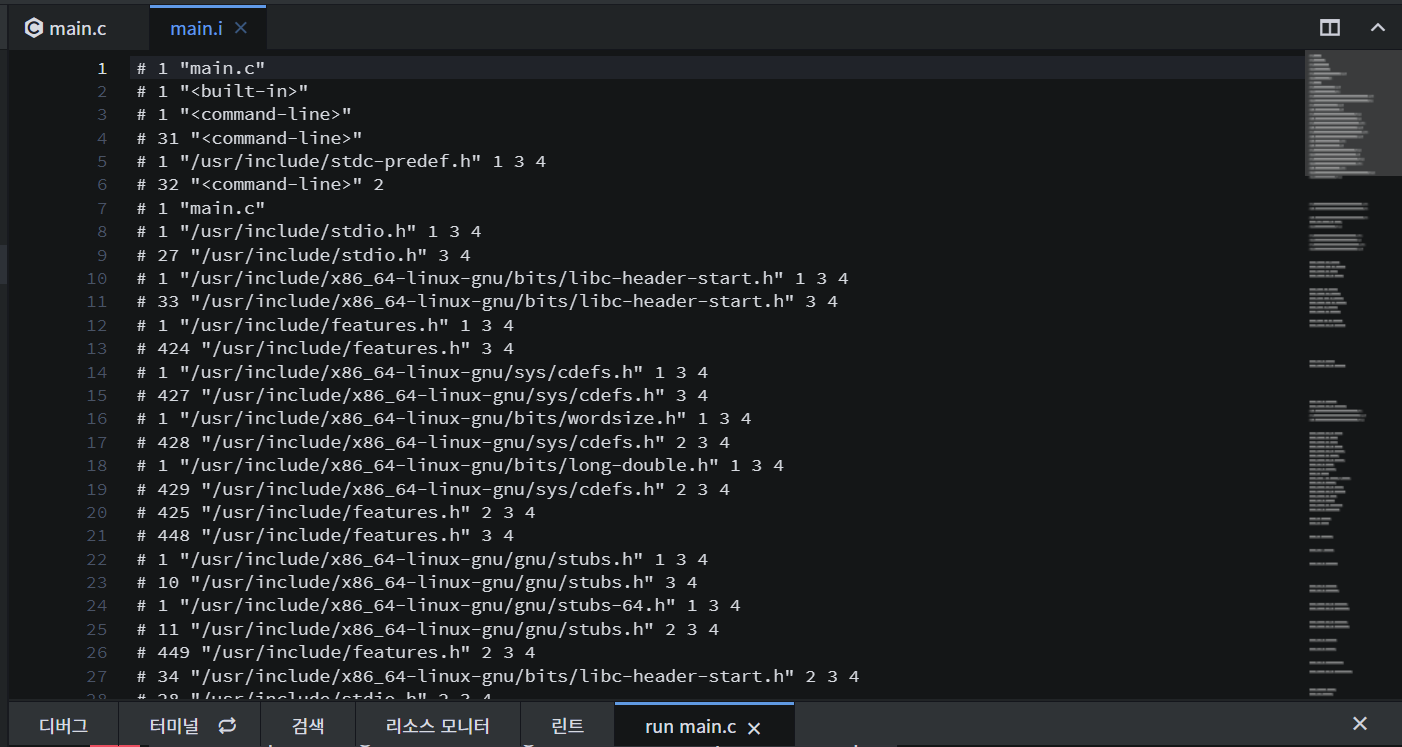
다음으로 컴파일 된 후 생성되는 어셈블리어 파일인 .s 파일을 생성해보았다.

이 때 주의할 점은 gcc 명령어 마다 뒤에 붙은 옵션이 다르고, 대소문자를 잘 구분해야 한다.
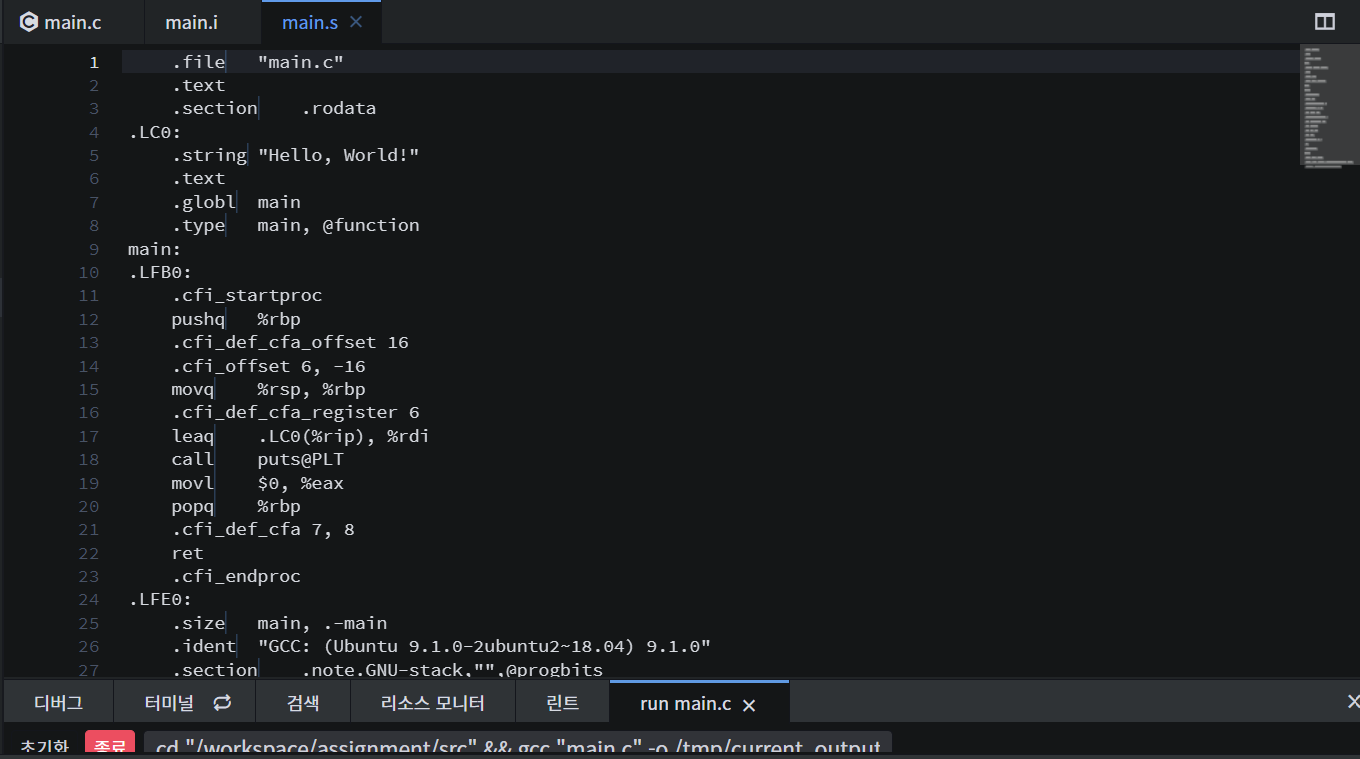
생성된 파일에서 어셈블리어를 확인할 수 있다.
다음은 오브젝트 파일인 .o 파일을 생성한다.

마찬가지로 main.o 파일도 확인하고 싶지만, 이는 기계어라 파일 내용을 확인할 수 없다.
파일 정보를 확인해보면 다음과 같다.

ELF(Executable and Linkable Format)에 64비트 아키텍처용이며, LSB에서 little endian 방식을 사용하고 relocatable하며 ELF 포맷의 버전과 변형은 version1(SYSV) 임을 알 수 있다. not stripped는 디버깅 정보나 심볼 테이블 등의 추가 정보가 오브젝트 파일에 포함되어 있다는 것을 알 수 있다.
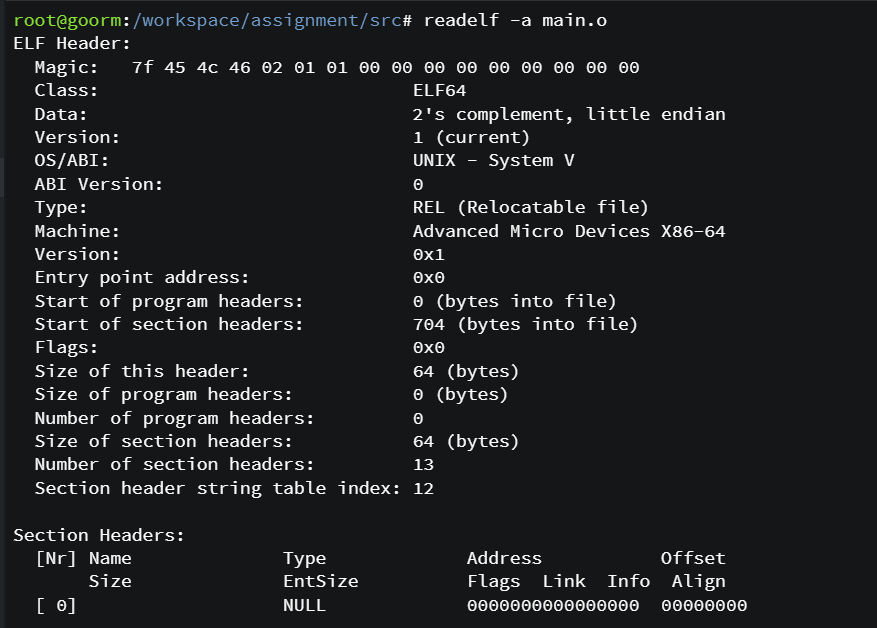
readelf 명령어로 main.o 파일을 자세하게 확인할 수 있으며hex editor나 objdump 명령어로도 확인 가능하다.
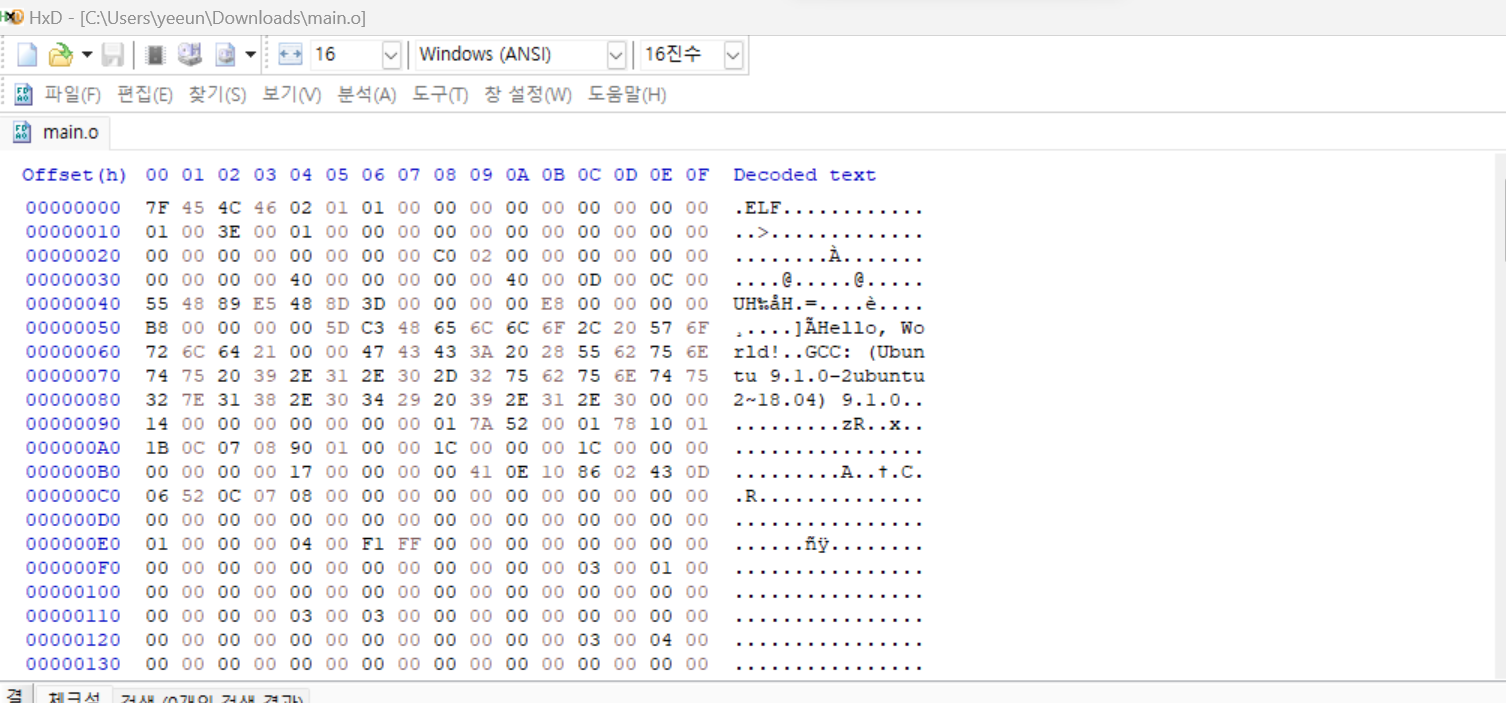
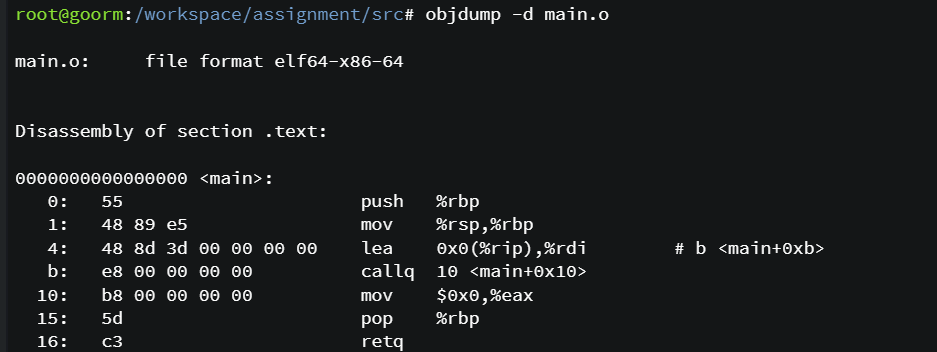
다음으로 마지막 링킹과정을 실습해 보았다.

main 파일이 생긴 것을 확인할 수 있다.

실행하면 입력한 코드가 잘 동작한다.

오브젝트 파일과 실행 파일의 차이도 확인할 수 있다.
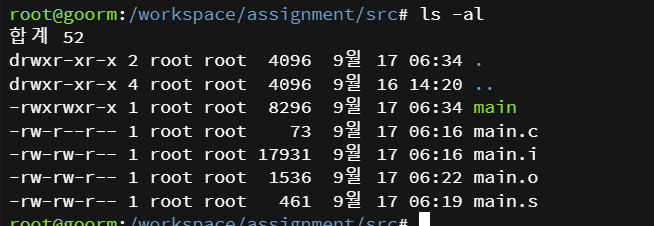
각 단계별 파일의 크기도 다르다.
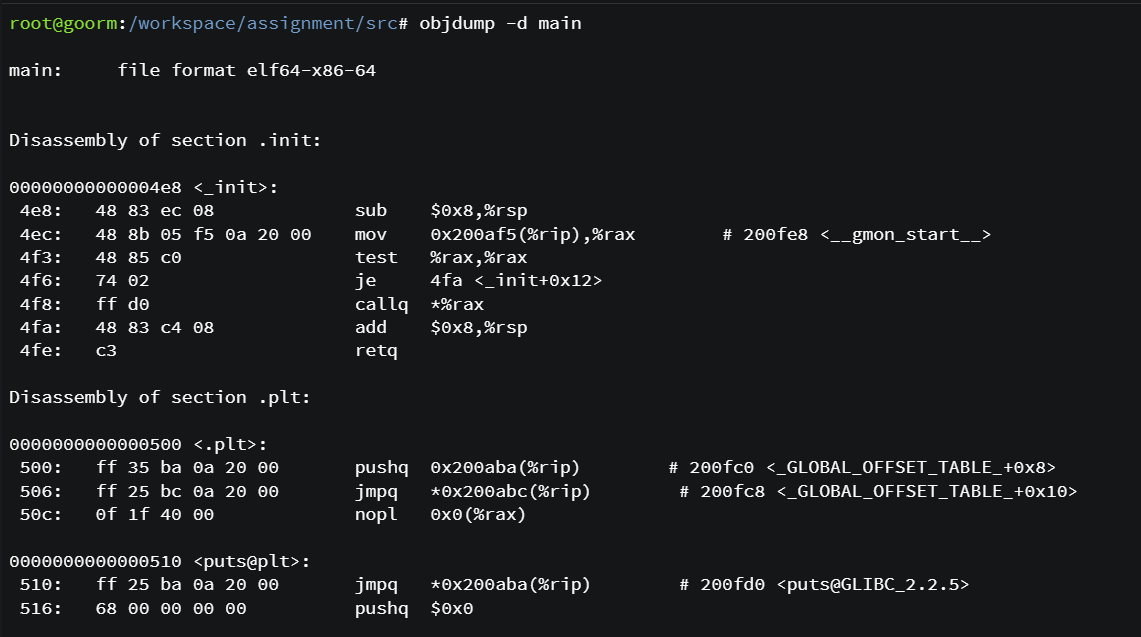
objdump 명령어로 확인해 보아도 함수들이 많이 생성된 것을 확인할 수 있다.
gdb로도 확인해보았다.
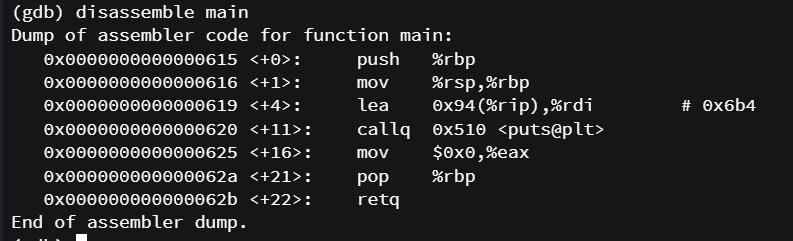
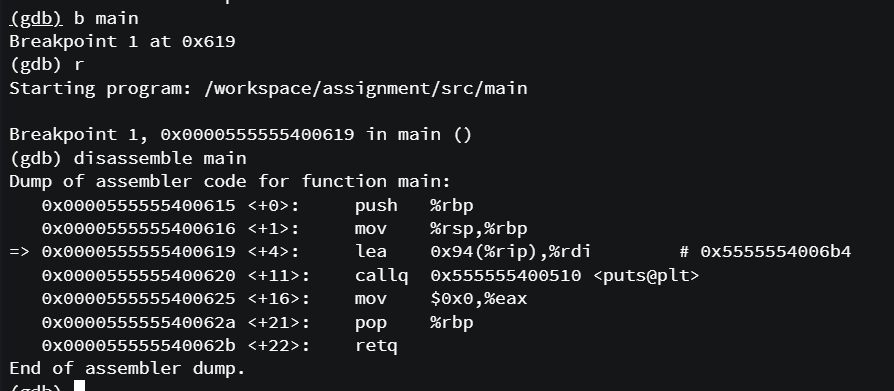
프로세스의 상태가 메모리에 올라가 있어 실제 메모리 주소를 확인할 수 있다.
따라서 우리는 C언어가 기계어가 되는 과정을 다음과 같이 정리할 수 있다.
소스코드(.c)+헤더파일(.h) -> (전처리) -> 전처리 된 소스코드 파일(.i) -> (컴파일) -> 어셈블리어 파일(.s) -> (어셈블리) -> 오브젝트 파일(.o) -> (링킹) -> 오브젝트 파일(.o) + 라이브러리(.a, so) -> 실행파일
