
Hash(해시)가 뭔데?
알고리즘이나 자료구조 공부를 하다보면 해시(Hash)에 대해 자주 들었을 거에요.
해당 분야가 아니더라도 해시 브라운… (맛있죠?) 으로도 익숙한 그 이름!
도대체 뭐길래 이렇게 자주 들릴까요?
적을 알면 백전백승. hash는 한국어로 고기와 감자를 잘게 다져 섞어 요리한 것이라고 해요!
해시 브라운을 제가 괜히 이야기한 게 아닙니다.
여러분 위 사전의 뜻 잘 기억하세요!
Hash의 정의
Hash는 유일한 값을 (key, value)값으로 저장하기 위한 자료구조에요.
보통 key가 string일 때 주로 사용합니다. (다른 type들일때도 물론 사용됩니다!)
그렇다면 왜 유일한 값 을 저장하기 위한 자료구조가 생겼을까요?
유일한 값이라면 값을 빨리 찾을 수 있기 때문이죠.
서울에서 김서방 찾는 것 보다 빡서방 찾는 게 더 낫잖아요.
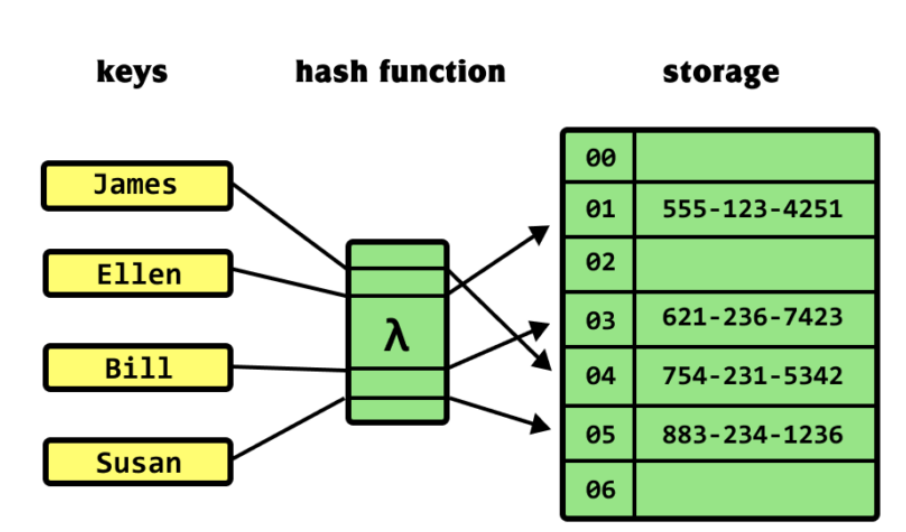
이때, 위 사진과 같이 key들을 유일한 값으로 변환하는 역할을 하는 것이 바로 해시함수 hash function 입니다.
해시함수로 인해 index가 된 key들은 HashTable(=버킷) 안에 인덱스로 이용됩니다.
다시 한 번 더 반복하자면,
잘게 다져준다는 영단어 hash의 뜻처럼, String이나, 등등 index로 만들어지지 않은 값들을 해시 함수가 잘게 hash 시켜서 색인(indexed)된 값으로 바꿔줘요.
그 과정을 hashing이라고 합니다.
Hashing 과정의 필요성
자, 그러면 hashing은 잘 아셨을테고, 왜 필요한지 알아야 쓸 수 있겠죠?
그냥 key를 다시 index로 바꾸고 막 그러지말고 우리 그냥 그걸 index로 쓰면 안될까?
앞에서 제가 뭐라고 했죠.
string이 key일 때 주로 사용한다고 했죠.
string은 배열의 키로 쓸 수 없습니다.
그리고 무엇보다, JS의 Object와 Map도 내부는 Hash로 이루어져있답니다.
Therefore, it could be represented internally as a hash table (with O(1) lookup), a search tree (with O(log(N)) lookup), or any other data structure, as long as the complexity is better than O(N). - Map MDN 공식문서
제 글을 여기까지 본 분들은 모두 필요성을 아셨을거라 믿습니다.
해시 함수 (Hash Function)
해시 함수 기법은 아래와 같이 크게 4가지 종류가 있어요.
-
나누기(Division)의 나머지(%)
function hashFunction(key, bucketSize) { return key % bucketSize; }위 코드 블럭과 같이, key를 버킷 사이즈로 나눈 나머지가 buckey의 index가 되게 하는 방법이에요.
key를 bucket 사이즈로 나눈 나머지는 항상 버킷 사이즈 내의 인덱스가 되는 것을 보장하기 때문입니다.
key를 bucket 사이즈로 나누는 게 이해가 안돼요!
위 사실이 이해가 바로 되지 않는 분들도 있을 거라고 생각해요.
너무 어렵게 생각하지 마시고 직관적으로 생각해보세요.
내가 가진 사과가 n개가 있는데, 바구니가 7개 있어요. 7개의 바구니에 무조건! 나눠 담을 때, 나머지는 항상 0~6이에요. (0을 나누는 경우는 없겠죠..ㅎㅎ)
그렇지 않나요? 한 번 상상해보세요! 생각보다 쉽게 이해가 될 거에요
-
접기 (Folding)
키를 몇 개의 부분으로 나누어 더하는 방법입니다.
접기의 종류에는 아래와 같이 2가지 방법이 있어요.
첫 번째는, 이동 폴딩 (shift folding)입니다.
이동 폴딩은 키를 여러 부분으로 나눈 값들을 더해 해시 주소로 사용해요.
123-45-6789 → 123 + 456 + 789 123과 456, 789를 접어서 더한 값이 버킷의 index가 됩니다.
// 해시 함수 ( 접기법 ) #hashFunction(key) { const chunkSize = 5; let hashIndex = 0; // 1. key를 0, i, i+1, length-1 . .. 이런 식으로 쪼갠다. for (let i = 0; i < key.length; i += chunkSize) { let chunkedValue = 0; let chunkedKey = key.slice(i, i + chunkSize); // 2. 쪼갠 chunkedKey를 아스키코드로 변환한다. for (let j = 0; j < chunkedKey.length; j++) { chunkedValue += chunkedKey.charCodeAt(j) << (j * 8); } hashIndex += chunkedValue; } return hashIndex % this.bucketSize; }실제로 위와 같이 이동 폴딩을 구현해보았어요.
매개변수로 받은 String key를 이동 폴딩 방식으로 쪼개고, 쪼갠 문자열을 아스키 코드로 반환했습니다.두 번째는, 경계 폴딩 (boundary folding)입니다.
키의 이웃한 부분을 거꾸로 더해 해시 주소로 사용해요.
123-45-6789 → 123 + 654 + 789
위와 같은 접기 방법은 키가 해시 테이블(버킷)의 크기보다 더 큰 정수일 때 주로 사용합니다.
-
중간 제곱 (Mid-Square)
먼저 키를 제곱하고 중간의 몇 비트를 해시 주소로 생성하는 방법입니다.
3121 → 9740641 → 406 (테이블 크기가 1000인 경우)
-
추출 (Extraction)
키의 일부만 사용해서 결과로 사용하는 방법입니다.
충돌(Collision)
여러분. 근데 key가 엄청나게 많은데, key보다 해시 테이블(버킷)의 숫자가 적으면 어떤일이 생길까요?
직관적으로 생각했을 때, 충돌이 발생할 것같지 않나요?
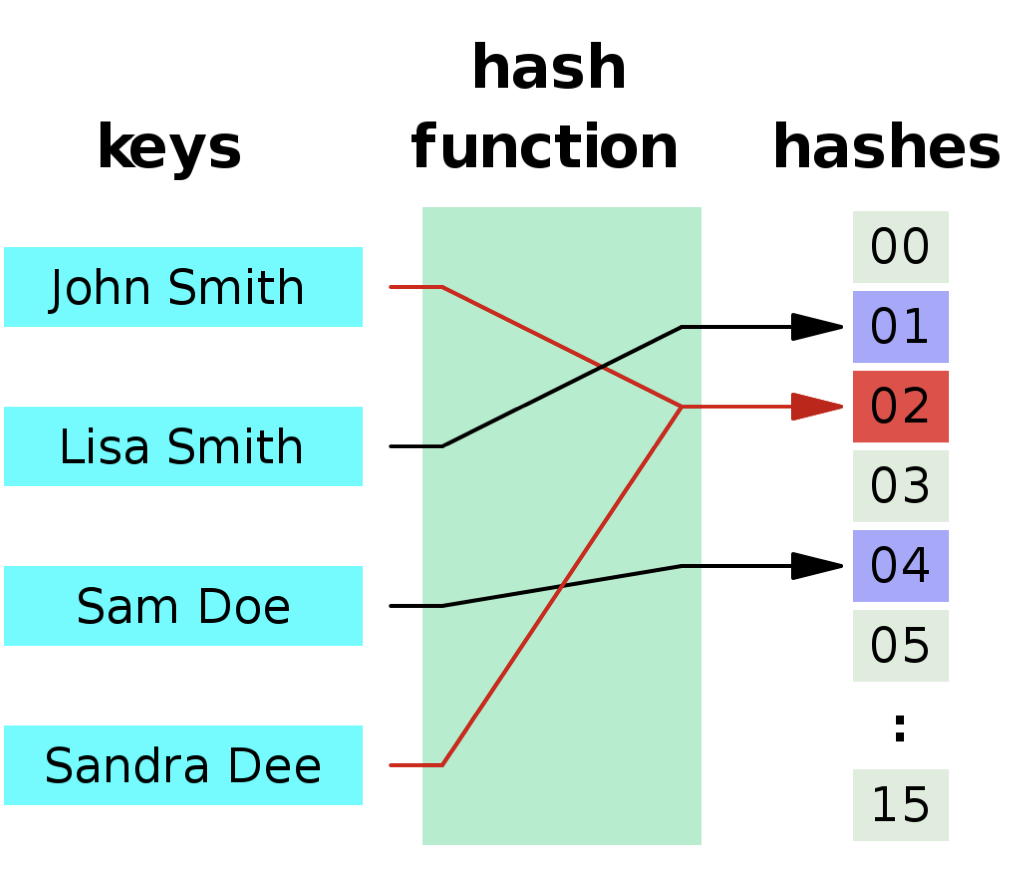
John Smith와 Sandra Dee가 같은 hash(버킷의 인덱스)에 접근하려다 꽝하고 충돌이 생긴것, 보이시나요!
어떻게보면 당연한 이 논리를, 비둘기집의 원리라고도 합니다.
충돌을 줄이자!
충돌이 나면 안되니까, 충돌을 최대한 줄이거나 대처를 잘 하고자하는 다양한 방법들이나 방법론들이 생겼어요.
1. 좋은 해시 함수를 설계하자.
애초에 해시 함수가 해시를 만들지 않습니까? 그러니까, 애초에 겹치지 않도록 균등하게 분산시키는 함수를 구현하면 되겠죠?
- 서로 유사한 키라도 해시값이 분산되도록!
💡 참고로, 아래와 같은 유명한 해시 함수들이 있어요
- DJB2
- FNV-1a
- MurmurHash
- SHA 시리즈 (암호학적 목적)
2. 버킷 수를 소수(prime number)로 선택하자.
소수 버킷 크기는 해시 결과를 나눌 때 충돌 확률을 낮춰줘요.
많은 해시 함수는 내부적으로 곱셈, 덧셈, 비트 이동 등을 수행하고 결국 hash % bucketSize로 버킷 인덱스를 정합니다.
// 해시값이 100, 200, 300, 400 이런 식으로 나온다고 가정
hash % 100 → 전부 0
hash % 10 → 전부 0그런데 이때, bucketSize가 2나 10, 100 같은 합성수일 경우,
위와 같이 특정 해시값 패턴들이 같은 나머지를 계속 만들 가능성이 높아져요.
100 % 211 → 100
200 % 211 → 200
300 % 211 → 89
400 % 211 → 189하지만 소수로 나눌 경우, 패턴을 만들어도 나머지 값이 더 고르게 분포됩니다
→ 즉, 특정 해시값들이 하나의 버킷에 몰리지 않도록 분산돼요.
3. 리해싱(rehashing) 또는 동적 리사이징
해시 테이블에 아이템이 많아져서 충돌이 자주 일어나면, 그에 따라 속도도 느려지기 시작해요.
그래서 특정 조건을 만족하면, 버킷 크기를 두 배로 늘리고, 모든 아이템을 다시 해시해서 옮겨요.
자바스크립트, 특히 V8엔진을 사용하는 환경에서도 이 리해싱을 한다고 해요.
(더 궁금하신 분들은 여기 링크를 봐주세요!)
V8 엔진에 대해 자세히 설명한 여러 문서들이 많은데, 오늘 다 얘기하긴 너무 길 거 같아서 시간이 되면
V8 엔진의 동작 원리나 방법에 대해서만 한 번 열심히 공부해서 글을 써보도록 할게요! 😊
4. 탐사 또는 체이닝 전략
Open Addressing
- 충돌하고 난 뒤, 인덱스를 선택하는 전략은 아래와 같아요.
-
선형 탐사법
function hashFunction(key) { let hash = key % 10; } const hashKey = hasFunction(9) //9 const hashKey2 = hashFunction(99) //9
인덱싱 해야할 공간이 비어있지 않으면, 한 칸씩 이동하여 빈 공간을 찾아나서는 방법이에요.
하지만 제 필기에 적혀있는 것처럼, 일차 군집화에 취약하다는 단점이 있어요.
-
제곱 탐사법
선형 탐사법처럼 한 칸씩 옮기는게 아니라 제곱만큼 옮기는 것을 의미해요.
하지만, 같은 값이 나오면 이차 군집화를 야기할 수도 있어요.
Separate Chaining (체이닝)
Linked List, Array, Tree 등을 사용해서 버킷 하나에 여러 개를 저장하는 것을 말해요.
앞에서의 방법들은 해시값 하나에 주인이 있으면 다른 곳을 찾아가는 방식이었는데, 체이닝은 기차놀이 처럼 그 뒤에 줄줄이 엮여있는 방법이라고 생각하면 이해가 쉬울 것 같아요.
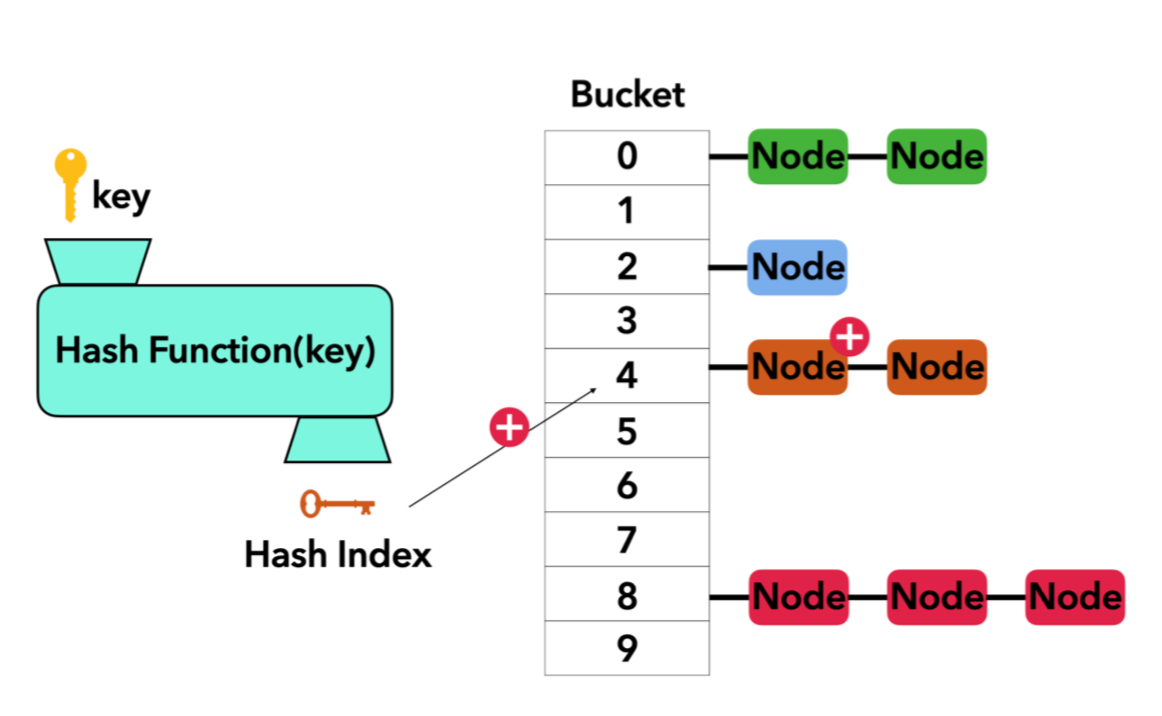
하나의 인덱스에 충돌이 나면 충돌된 index의 값 뒤에 next 포인터로 연결해 연결리스트로 만드는 방법입니다.
참고 문헌
https://www.spiceworks.com/it-security/data-security/articles/what-is-hashing/
https://itnext.io/v8-deep-dives-understanding-map-internals-45eb94a183df
https://www.geeksforgeeks.org/javascript/separate-chaining-hash-table-collisions-in-javascript/
https://velog.io/@huurray/%ED%95%B4%EC%8B%9C-Hash-in-Javascript
https://velog.io/@kangyul/JS-Hash-Map-Hash-Function
https://velog.io/@ubin_ing/custom-hash
위 참고 문헌들 모두 다 잘 작성이 되어 있으니 한 번씩 들어가보셔도 좋을 것 같습니다!
