this time...
⚫Supervised learning – 1
⚫ Classification performance : 정확도 측정 방법
⚫ Decision Tree : 스무고개 놀이
⚫ Training generalization
⚫ Parameter vs. Hyper-parameter
⚫ Ensemble model, Random forest
⚫ Supervised learning – 2
⚫ Linear classifier
Supervised learning – 1
Performance Measure
Precision/Recall
- Recall : TP/(TP+FN)
맞는 것을 맞다고 추측한 비율 - Precision : TP/(TP+FP)
맞다고 추측한 것 중 맞는 비율
Precision-Recall Curve
- recall과 precision은 반비례이다.
- 동일한 recall 수치일때, precision이 높을수록 더 좋은 알고리즘
- 동일한 precision에서 recall이 높을수록 더 좋은 알고리즘
- 오른쪽 위로 붙을수록 좋음
ROC Curve
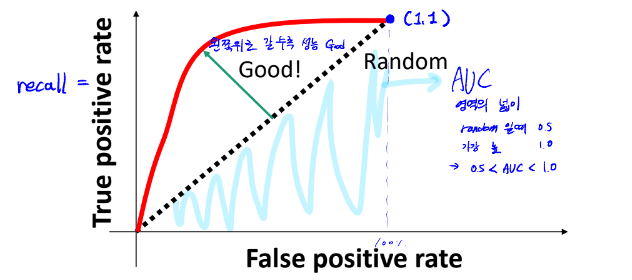
- 기울기 1 - 랜덤한 수치
- 왼쪽 위로 갈수록 좋은 성능
- Area under Curve (AUC) - 그래프 아래 영역의 넓이.
랜덤일 때 0.5
F1 Score
- 그래프 안 그려도 하나의 수치로 비교가능
- 리콜과 프리시즌의 조화평균 -> 커브보다는 별로임
Weighted F1 score
- 여러개 클래스가 있을떄
- 클래스별로 갯수가 다를때 사용
- 갯수가 크면 더 큰 weight를 할당하여 평균
Decision Tree
주의할점 : Decision Tree는 정해져있는게 없음
Supervised learning
모든 데이터가 카테고라이즈, 라벨링 되어있을 경우 사용하는 머신러닝
- Features (input) : Quantities of various ingredients
- Labels (output) : Whether or not the dog eats
Decision Tree란
- if-else 문으로 구성되어있는 노드 구성, 스무고개와 비슷
- 예, 아니요로만 구성- 질문은 feature attribute(기준) 과 threshold(범위)로 구성된다.
ex)Peanut>0.2
- 질문은 feature attribute(기준) 과 threshold(범위)로 구성된다.
- leaf-node : 결론을 내리는 노드
- shifting node : 질문
결정해야할 것
- feature types (attribute)의 종류
- threshold
- 질문 횟수 제한
좋은 질문에 대한 고민
- balanced sets : 현재 샘플을 반으로 갈라주는 질문 -> 질문의 가짓수를 줄여준다.
- 가장 높은 정확도 -> 불가능한 경우가 많다.
- 한쪽을 완벽한 leaf로 -> 질문을 너무 많이 해야할수도
가장 balanced한 질문 찾기
n개의 샘플, d개의 피쳐 타입, k개의 discrete threshold (별개의 한계치)
-> 계산량 = ndk
-> 연산량이 너무 큼
-> 적절 피쳐만 랜덤하게 사용, threshold만 비꾸면서 or threshold를 적게
질문을 많이 할수록 정확도가 올라갈까? 아님
Training Generalization
깊이가 무한대 -> 정확도는 무조건 100퍼 -> 원리 이해가 없다는 소리, 외운것
-> 새로운 문제에 대응할 능력이 없음
--> Overfitting : training data만 보고 있어서 새로운 데이터에 낮은 정확도를 보여준다.
-
training/testing data
- 서로 비슷하지만 독립적이다.
IID : independent & identically
- 서로 비슷하지만 독립적이다.
-
overfitting 수치화
오버피팅 = 테스트 에러 - 트레이닝 에러
-> 테스트 에러가 작고, 트레이닝 에러가 클수록 오버피팅이 떨어진다모델이 데이터를 외우지 않고 학습해야한다. -> large dataset: 큰 데이터 주기 (데이터가 많으니까 외우기보다 이해하려고 함) -> small depth : 간단한 모델을 준다. (모델이 복잡할수록 외우려고 한다.) -
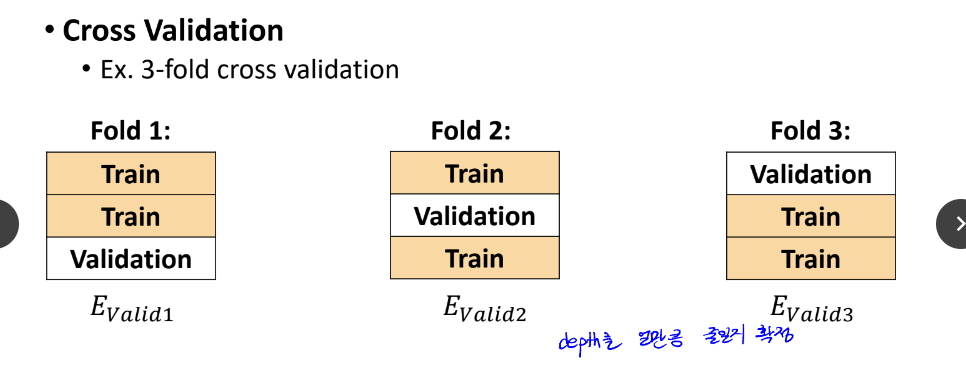
validation error
학습용 데이터를 트레이닝 셋과 밸리데이션 셋으로 나눈다.
Parameter & Hyper-parameter
- Parameter
- 머신러닝에서 자동으로 찾아주는 것
- 피쳐와 threshold
- Hyper-parameter
- 사용자가 임의로 결정
- depth
Ensemble Models
Definition
classifier 같이 쓰기
ex) knn (정확, 빠르지X)
디시즌 트리 (빠름, 정확X)
-> 같이 쓰기 - 앙상블(meta classifier)
-> 높은 정확도
Averaging
여러 classifier 결과 평균내기
- stacking
모든 classifier가 독립적이여야지 성능이 오른다.
Random Forest
-
디시즌 트리를 여러개 합친 모델, 딥러닝 이전 가장 좋은 성능
-
트리가 여러개, 트리는 모두 독립적 -> 빠르다
-
트리가 단순히 같으면 성능 안 올라감
-> 트릭 사용트릭 1. Bootstrap sampling
각 decision tree 별로 training data를 서로 다르게 가져간다
Bagging : Bootstrap 학습한 것을 개별 Classifier 학습에 사용하는 과정트릭 2. Random trees

feature type을 랜덤하게 줄인다. -
랜덤 트리 학습
-> 독립적 학습
-> 독립적 classifier가 합쳐진 앙상블 모델
-> 학습 성능 향상
Boosting
Cascade classifier
확실히 하는 것을 서서히 걸러내는 것 (직렬 연결)
Supervised learning – 2
Standardizing Features
피쳐 분포 비슷하게 만들기
전체 scale을 맞춰 주는 것
Linear Classifier
- 부호를 기준으로 예측값을 결정할 수 있다 (-1 or +1)
- decision boundary : 이 기준으로 부호 결정
1D : x축 - feature, y축 - 라벨값
- Least Squares : 오류 발생
-> 아래의 방법들로 보완한다.
0-1 Loss Function
- 예측이 같이 됨 -> 0
- 조금이라도 차이가 남 -> 1 (Loss 발생)
- 최적화하는 것이 목적이라 미분값이 필요하다, 하지만 가장 이상적인 모델이지만 기울기가 모두 1이기 떄문에 사용 불가능하다.
Stationary/Critical Points
- critical point 찾기
gradient Descent
- 랜덤한 w 찾기
- 그 지점 기울기 계산
- 줄어드는 방향으로 이동 -> 기울기 계산 (반복)
- local min에 대한 수렴성 100퍼 확보 but global min은 아님
-> f 두 번 미분시 0보다 크면 global min - 기울기가 0에 수렴하면 반복을 멈춘다.
- Degenerate Convex Approximation of 0-1 Loss
-> 원하는 결과 아님
-> hinge loss and logistic loss#### hinge loss 최소한 1보다는 커야 loss가 0이 된다. 미분 불가능 #### logistic loss 미분 가능하다. 0이 아니라 log2가 남는다.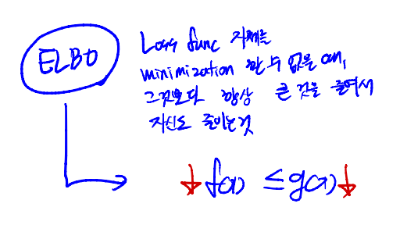
Controlling Complexity
Regularization : w제곱을 더해서 크기를 제한
람다 를 키울수록 모델 복잡도 줄어듬 ( overfitting 조절)
