
텍스트 유사도 Text Similarity
유사도 사용이유
각 문장 간의 유사도를 계산해야 적절한 답변이 출력 가능하기에 유사도를 알아본다.
n-gram 유사도
정의
주어진 문장 n개의 연속적인 단어 시퀀스를 의미한다.
n-gram은 문장에서 n개의 단어를 토큰으로 사용하고,
비교시 단어 출현 빈도에 기반하여 유사도를 계산한다.
사용처
주로 인용, 도용 조사할 때 사용
n에 따른 명칭
n = 1: 유니그램 unigram
n = 2: 바이그램 bigram
n = 3: 트라이그램 trigram
n >= 4: n-그램 n-gram
계산식
similarity = tf(A, B)/tokens(A)
tf: A, B에서 동일한 토큰의 출현 빈도
tokens: 해당 문장에서 전체 토큰 수
마치며
n-gram은 전체 문장을 고려한 언어 모델보다 정확도가 떨어질 수 있다.
n을 크게 잡으면 카운트를 놓칠 수 있고, 작게 잡으면 문맥을 파악하는 정확도가 낮아진다.
=> n-gram 모델에서 n 설정은 매우 중요하다.
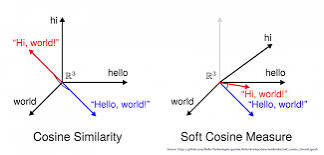
코사인 유사도
정의
두 벡터 간 코사인 각도를 이용해 유사도를 측정하는 방법
벡터의 크기가 중요하지 않을 때 거리를 측정하기 위하여 사용 => 안정적
예제 코드
Link: Text Similarity Code
당신의 시간이 헛되지 않는 글이 되겠습니다.
I'll write something that won't waste your time.

원하는 것을 창조하고 창조한 것을 의미있게 사용하자