Linear regression란?
Linear regression은 선형회귀라는 뜻으로, 통계학과 머신러닝에서 가장 간단하면서도 널리 사용되는 회귀 분석 기법 중 하나이다.
주로, 종속 변수와 하나 이상의 독립 변수 간의 선형 관계를 모델링하는 데 사용된다.
선형 회귀는 주어진 데이터를 가장 잘 설명하는 직선을 찾는 것으로, 이 직선은 종속 변수와 독립 변수 간의 관계를 나타낸다. 선형 회귀 모델은 보통 다음과 같은 형태의 선형 방정식으로 표현할 수 있다.

여기서 y는 종속 변수, x1, x2 같은 애들은 독립 변수들이며 n은 변수의 수를 나타낸다. 베타1, 2..모델의 계수이며 각 독립변수의 가중치를 나타낸다. ϵ는 모델의 오차를 나타낸다.
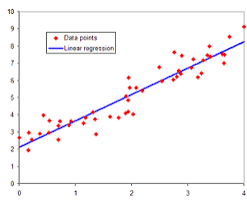
선형 회귀 모델의 목표는 주어진 데이터를 가장 잘 설명하는 직선의 방정식을 찾는 것이며, 이를 위해 최소 제곱법(Least Squares Method)이 주로 사용된다.
CNN
CNN은 Convolutional Neural Network의 약어로, 컨볼루션 신경망을 의미한다. CNN은 이미지 인식, 음성 인식, 자연어 처리 등의 다양한 컴퓨터 비전 및 인공 지능 작업에 사용되는 강력한 신경망 아키텍처 중 하나다.
CNN은 이미지 처리에서 특히 효과적이며, 이는 컨볼루션 레이어(Convolutional Layer)와 풀링 레이어(Pooling Layer)가 번갈아가며 구성되어 있어 이미지의 공간적인 구조를 보존하면서도 차원을 줄이고 중요한 특징을 추출할 수 있기 때문이다.
주요 특성
1. 컨볼루션 레이어: 입력 이미지를 필터(커널)와 합성곱하여 특징 맵을 생성합니다. 이를 통해 이미지의 주요 특징을 추출할 수 있습니다.
2. 풀링 레이어: 특징 맵의 크기를 줄이고 계산량을 감소시키기 위해 특정 영역에서 최댓값 또는 평균값을 추출합니다.
3. 활성화 함수: 비선형성을 도입하여 네트워크의 표현력을 향상시킵니다. 주로 ReLU(Rectified Linear Unit) 함수가 사용됩니다.
4. 완전 연결 레이어: 마지막에 하나 이상의 완전 연결 레이어가 추가되어 최종 출력을 생성합니다.
5. 학습: 역전파 알고리즘을 사용하여 네트워크의 가중치를 조정하여 입력에 대한 출력을 최적화합니다.
전이학습과 예제
전이학습
전이 학습은 한 작업에서 학습한 지식을 다른 관련 작업에 적용하는 것을 의미한다. 이는 새로운 작업에 대해 데이터가 제한되어 있거나 모델을 처음부터 학습하는 것이 현실적이지 않을 때 매우 유용하다.
전이 학습의 핵심 아이디어는 기존에 훈련된 모델(원본 모델)을 가져와서 이 모델의 일부 레이어를 새로운 작업에 맞게 재사용하거나 수정하여 새로운 작업에 대해 훈련시키는 것이다. 이렇게 하면 새로운 작업에 대한 데이터가 적거나 제한적인 경우에도 좋은 성능을 얻을 수 있다.
예제 코드
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
model = torchvision.models.vgg16(pretrained=True)
num_features = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_features, num_classes)
train_data = datasets.ImageFolder('train_dir', transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_data, batch_size=32, shuffle=True)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss / len(train_loader)}")
print("Finished Training")
torch.save(model.state_dict(), 'trained_model.pth')
미디어 파이프 손가락 욕 모자이크
import cv2
import mediapipe as mp
import numpy as np
max_num_hands = 1
gesture = {
0:'fist', 1:'one', 2:'two', 3:'three', 4:'four', 5:'five',
6:'six', 7:'rock', 8:'spiderman', 9:'yeah', 10:'ok', 11:'fy'
}
# MediaPipe hands model
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
hands = mp_hands.Hands(
max_num_hands=max_num_hands,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
# Gesture recognition model
file = np.genfromtxt("C:\\Users\\user\\Downloads\\gesture_train_fy.csv", delimiter=',')
angle = file[:,:-1].astype(np.float32)
label = file[:, -1].astype(np.float32)
knn = cv2.ml.KNearest_create()
knn.train(angle, cv2.ml.ROW_SAMPLE, label)
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, img = cap.read()
if not ret:
continue
img = cv2.flip(img, 1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = hands.process(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if result.multi_hand_landmarks is not None:
for res in result.multi_hand_landmarks:
joint = np.zeros((21, 3))
for j, lm in enumerate(res.landmark):
joint[j] = [lm.x, lm.y, lm.z]
# Compute angles between joints
v1 = joint[[0,1,2,3,0,5,6,7,0,9,10,11,0,13,14,15,0,17,18,19],:] # Parent joint
v2 = joint[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],:] # Child joint
v = v2 - v1 # [20,3]
# Normalize v
v = v / np.linalg.norm(v, axis=1)[:, np.newaxis]
# Get angle using arcos of dot product
angle = np.arccos(np.einsum('nt,nt->n',
v[[0,1,2,4,5,6,8,9,10,12,13,14,16,17,18],:],
v[[1,2,3,5,6,7,9,10,11,13,14,15,17,18,19],:])) # [15,]
angle = np.degrees(angle) # Convert radian to degree
# Inference gesture
data = np.array([angle], dtype=np.float32)
ret, results, neighbours, dist = knn.findNearest(data, 3)
idx = int(results[0][0])
if idx == 11:
x1, y1 = tuple((joint.min(axis=0)[:2] * [img.shape[1], img.shape[0]] * 0.95).astype(int))
x2, y2 = tuple((joint.max(axis=0)[:2] * [img.shape[1], img.shape[0]] * 1.05).astype(int))
fy_img = img[y1:y2, x1:x2].copy()
fy_img = cv2.resize(fy_img, dsize=None, fx=0.05, fy=0.05, interpolation=cv2.INTER_NEAREST)
fy_img = cv2.resize(fy_img, dsize=(x2 - x1, y2 - y1), interpolation=cv2.INTER_NEAREST)
img[y1:y2, x1:x2] = fy_img
# mp_drawing.draw_landmarks(img, res, mp_hands.HAND_CONNECTIONS)
cv2.imshow('Filter', img)
if cv2.waitKey(1) == ord('q'):
break
