1. 교착 상태(데드락, DeadLock)
두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태
🔎 예시.png)
2. 교착 상태의 조건
다음의 조건들을 모두 충족할 경우 발생한다.
- 상호배제(Mutual exclusion)
프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
- 점유대기(Hold and wait)
프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
- 비선점(No preemption)
프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다.
- 순환대기(Circular wait)
각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
3. 교착 상태의 관리
현재 대부분의 운영 체제들은 교착 상태를 막는 것이 불가능하며, 교착 상태가 발생할 경우 제각기 다른 비표준 방식들로 교착 상태에 대응한다.
3.1 교착 상태의 예방
-
상호배제 조건의 제거
교착 상태는 두 개 이상의 프로세스가 공유가능한 자원을 사용할 때 발생하는 것이므로 공유 불가능한, 즉 상호 배제 조건을 제거하면 교착 상태를 해결할 수 있음 -
점유와 대기 조건의 제거
- 한 프로세스에 수행되기 전에 모든 자원을 할당시키고 나서 점유하지 않을 때에는 다른 프로세스가 자원을 요구하도록 하는 방법
- 문제점
- 자원 과다 사용으로 인한 효율성
- 프로세스가 요구하는 자원 파악 비용
- 자원에 대한 내용을 저장 및 복원하기 위한 비용
- 기아 상태
- 무한대기
-
비선점 조건의 제거
비선점 프로세스에 대해 선점 가능한 프로토콜을 만들어 줌 -
환형 대기 조건의 제거
- 자원 유형에 따라 순서를 매김
- 대부분의 접근들은 이 조건을 막음으로써 동작
✅ 문제점
자원 사용의 효율성이 떨어지고 비용이 많이 소모됨
3.2 교착 상태의 회피
- 자원 요청 방법에 대한 추가 정보를 제공하도록 요구
- 시스템에 순환 대기가 발생하지 않도록 자원 할당 상태 검사
✅ 자원 할당 그래프 알고리즘(Resource Allocation Graph Algorithm)
- 교착 상태를 보다 정확하게 설명하기 위한 방향성 그래프
- 정점 집합 𝑉과 edge 집합 𝐸로 구성
G = (V, E) - V의 노드 유형
- 𝑇 = {𝑇1, 𝑇2, ⋯, 𝑇𝑛}
→ 시스템의 모든 활성 스레드 집합 - 𝑅 = {𝑅1, 𝑅2, ⋯, 𝑇𝑚}
→ 시스템의 모든 리소스 집합
- 𝑇 = {𝑇1, 𝑇2, ⋯, 𝑇𝑛}
- directed edge
- request edge : Ti → Rj
=> 스레드 Ti가 Rj의 인스턴스를 요청 - assignment edge : Rj → Ti
=> Rj의 인스턴스가 스레드 Ti에 할당
- request edge : Ti → Rj
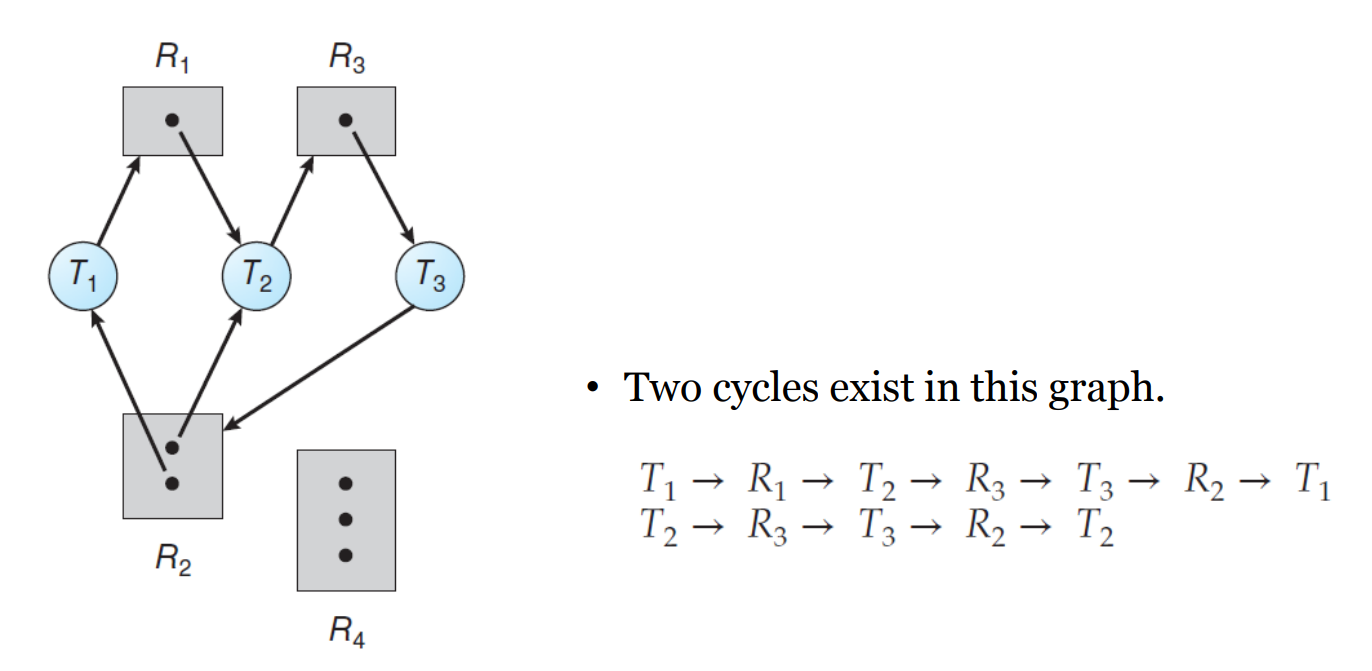
- cycle에 따른 교착 상태 판별
- cycle이 없는 경우 → 교착 상태 X
- cycle이 있는 경우 → 교착 상태 O or X
✅ 은행원 알고리즘(Banker's Algorithm)
- 프로세스의 안정/불안정 상태를 사전에 검사하여 교착 상태를 회피
- RAG는 각 리소스 타입의 여러 인스턴스가 있는 리소스 할당 시스템에 적용할 수 없음
→ Banker의 알고리즘은 적용 가능 - 단점 : RAG보다 덜 효율적이고 복잡함
📝 자료 구조
- Available : 사용 가능한 자원의 수(𝑨𝒗𝒂𝒊𝒍𝒂𝒃𝒍𝒆[𝒎])
𝐴𝑣𝑎𝑖𝑙𝑎𝑏𝑙𝑒[𝑗] == 𝑘 → 𝑅𝑗의 𝑘개의 인스턴스 사용 가능
- Max : 프로세스 별 최대 자원의 요구(𝑴𝒂𝒙[𝒏 × 𝒎])
𝑀𝑎𝑥[𝑖][𝑗] == 𝑘 → 𝑇𝑖가 𝑅𝑗의 최대 𝑘개의 인스턴스 요청 가능
- Allocation : 현재 프로세스 별 할당되어 있는 자원의 수(𝑨𝒍𝒍𝒐𝒄𝒂𝒕𝒊𝒐𝒏[𝒏 × 𝒎])
𝐴𝑙𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛[𝑖][𝑗] == 𝑘 → 𝑇𝑖가 현재 𝑅𝑗의 𝑘개의 인스턴스를 현재 할당받고 있음
- Need : 프로세스 별 남아있는 자원의 수(𝑵𝒆𝒆𝒅[𝒏 × 𝒎])
𝑁𝑒𝑒𝑑[𝑖][𝑗] == 𝑘 → 𝑇𝑖가 𝑅𝑗의 인스턴스를 𝑘개 더 요청할 것임
📝 safety algorithm
현재 system의 snapshot이 safety한가를 판별

📝 Resource-Request Algorithm

- 위의 과정이 끝나면 request를 받아줬다 치고 다시 safety algorithm을 돌려봄
- safety algorithm이 safe하면 승인해주고, not safety하다면 거절
📝 예시
💡 조건
- 5개의 스레드 집합: 𝑇 = {𝑇0, 𝑇1, 𝑇2, 𝑇3, 𝑇4}
- 세 가지 리소스 집합: 𝑅 = {𝐴, 𝐵, 𝐶}
- 각 자원 유형의 인스턴스 갯수: 𝐴 = 10,𝐵 = 5, 𝐶 = 7
-
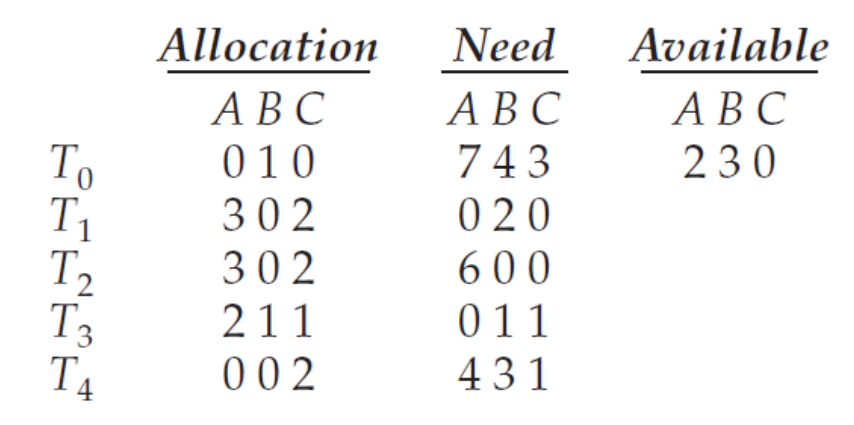
현재 시스템의 snapshot
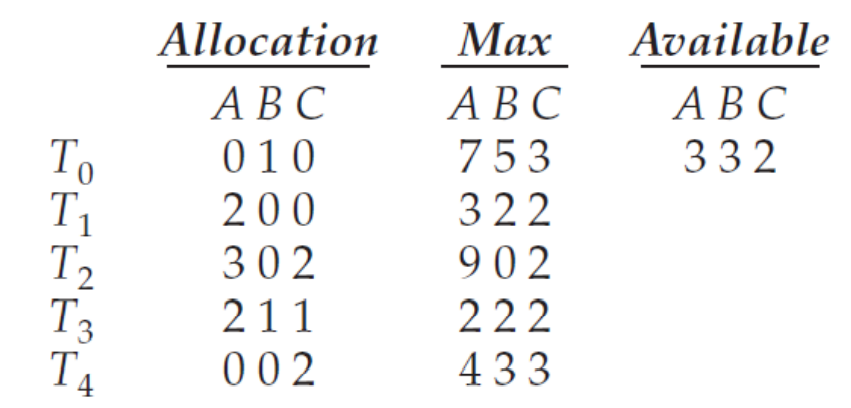
ex)A- 현재 allocation 된 리소스 갯수 7
- 총 10개
- 현재 available한 자원 = 10 - 7 = 3개
-
Need[i][j] = Max[i][j] - Allocation[i][j]
(앞으로 요청할 자원 = 최대 갯수 - 이미 할당된 자원의 갯수)
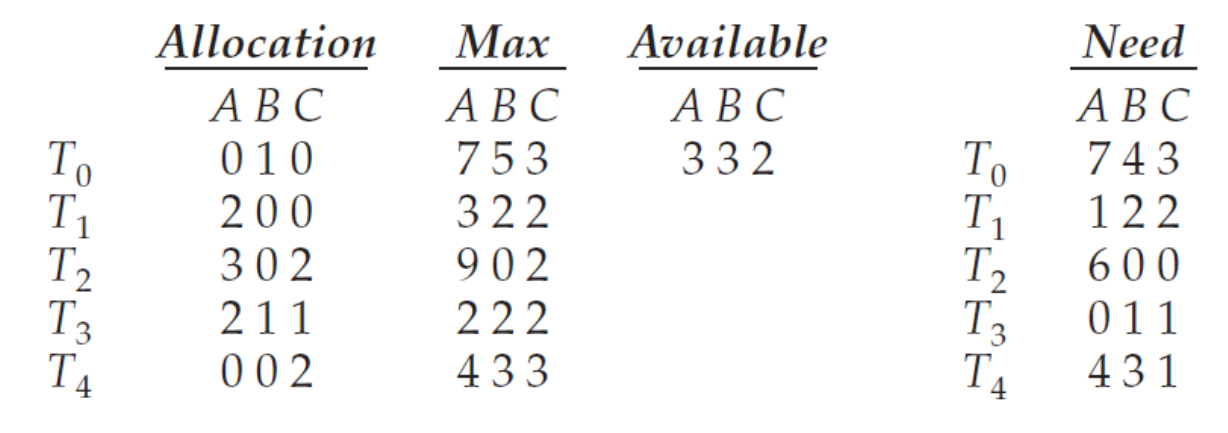
-
시스템이 현재 안전한 상태(safe state)임을 증명
→ 실제로 〈𝑇1, 𝑇3, 𝑇4, 𝑇0, 𝑇2〉 또는 〈𝑇1, 𝑇3, 𝑇4, 𝑇2, 𝑇0>시퀀스가 안전 기준을 만족
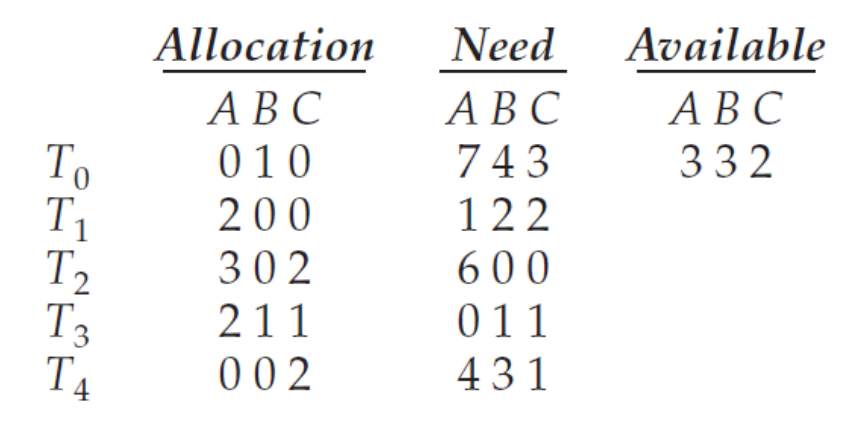
-
Safety Algorithm을 이용하여 증명
1. 초기화- work = safety
(3, 3, 2)
- Finish → 𝑇[i] 모두 false로 초기화
𝑇1=false, 𝑇3=false, 𝑇4=false, 𝑇2=false, 𝑇0=false
2. Finish[i] == false && 𝑁𝑒𝑒𝑑𝑖 <= Work (모든 항목에 대해)
-
1바퀴
- i=0, Need[0] = (7, 4, 3) <= (3, 3, 2) ∴ X
- i=1, Need[1] = (1, 2, 2) <= (3, 3, 2) ∴ O
〔Work = Work + 𝐴𝑙𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛[i], Finish[i] = true〕
(5, 3, 2) = (3, 3, 2) + (2, 0, 0), T[1] = true - i=2, Need[2] = (6, 0, 0) <= (5, 3, 2) ∴ X
- i=3, Need[3] = (0, 1, 1) <= (5, 3, 2) ∴ O
〔Work = Work + 𝐴𝑙𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛[i], Finish[i] = true〕
(7, 4, 3) = (5, 3, 2) + (2, 1, 1), T[3] = true - i=4, Need[4] = (4, 3, 1) <= (7, 4, 3) ∴ O
〔Work = Work + 𝐴𝑙𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛[i], Finish[i] = true〕
(7, 4, 5) = (7, 4, 3) + (0, 0, 2), T[4] = true
-
2바퀴(아직 T[0], T[2]가 false)
- i=0, Need[0] = (7, 4, 3) <= (7, 4, 5) ∴ O
〔Work = Work + 𝐴𝑙𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛[i], Finish[i] = true〕
(7, 5, 5) = (7, 4, 5) + (0, 1, 0), T[0] = true - i=2, Need[2] = (6, 0, 0) <= (7, 5, 5) ∴ O
〔Work = Work + 𝐴𝑙𝑙𝑜𝑐𝑎𝑡𝑖𝑜𝑛[i], Finish[i] = true〕
(10, 5, 7) = (7, 5, 5) + (3, 0, 2), T[2] = true
=> 모든 Finish[i]가 true → safety하다
- i=0, Need[0] = (7, 4, 3) <= (7, 4, 5) ∴ O
-
T[1] → T[3] → T[4] → T[0] → T[2] 또는 T[1] → T[3] → T[4] → T[2] → T[1]순으로 실행하면 thread safety가 보장됨
-
위의 순서가 바로 safe sequence
- work = safety
-
- 새로운 request가 들어온 경우
- 𝑇1이 𝐴 인스턴스 1개와 𝐶 인스턴스 2개를 요청한다고 가정
→ 𝑅𝑒𝑞𝑢𝑒𝑠𝑡1 = (1, 0, 2) - 요청을 승인할지 말지를 결정
- Resource-Request Algorithm 이용
- 𝑇1이 𝐴 인스턴스 1개와 𝐶 인스턴스 2개를 요청한다고 가정
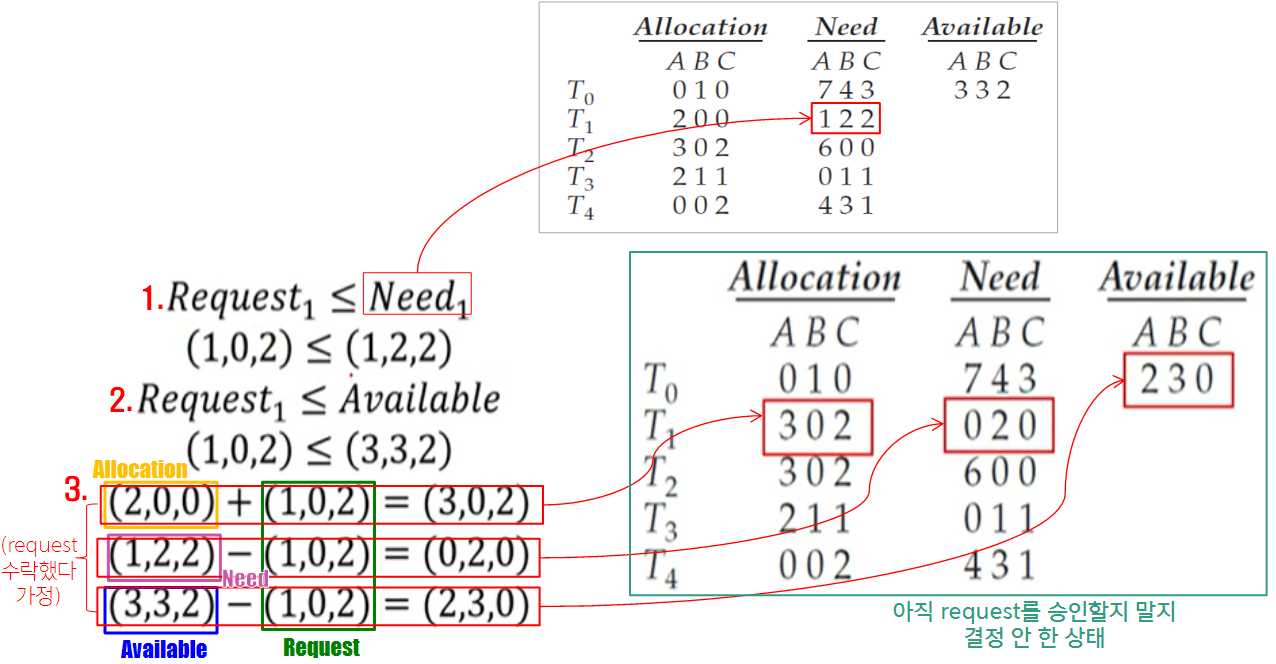
- 새로운 시스템 state의 안정성 확인
- 현재 System의 snapshot
- Safety Algorithm이 〈𝑇1, 𝑇3, 𝑇4, 𝑇0, 𝑇2〉가 안전을 만족하는지 검색
- 𝑇4가 (3, 3, 0)을 claim edge로 보낸다면
→ 𝑅𝑒𝑞𝑢𝑒𝑠𝑡4 = (3, 3, 0)

- 결론적으로 𝑇0를 제외한 나머지 모두 unsafety하므로 reject 됨
- 𝑇4가 (3, 3, 0)을 claim edge로 보낸다면
- 현재 System의 snapshot
3.3 교착 상태의 무시
- 예방이나 회피 기법은 성능에 큰 영향을 미칠 수 있음
- 데드락의 발생 확률이 비교적 낮은 경우 별다른 조치를 취하지 않음
💡 교착 상태를 무시했을 때 프로그램에서 발생하는 일
- 교착상태 문제를 무시하고 교착상태가 발생하지 않는다고 가정
- 문제를 무시하고, 교착상태가 시스템에서 결코 발생하지 않은 척 함
- 성능저하 → 시스템 중단 → 인위적인 재시작
- 유닉스와 윈도우를 포함한 대부분의 OS에서 사용하고 있는 방법
3.4 교착 상태의 발견
- 감시/발견을 하는 detection 알고리즘
- Deadlock 발생 체크
- 성능에 큰 영향을 미칠 수 있음
✅ single instance
- wait-for graph를 유지
💡 wait-for graph
resource-allocation graph에서 변형된 형태
- 주기적으로 알고리즘을 돌려서 wait-for graph에서 cycle이 있는지 검사
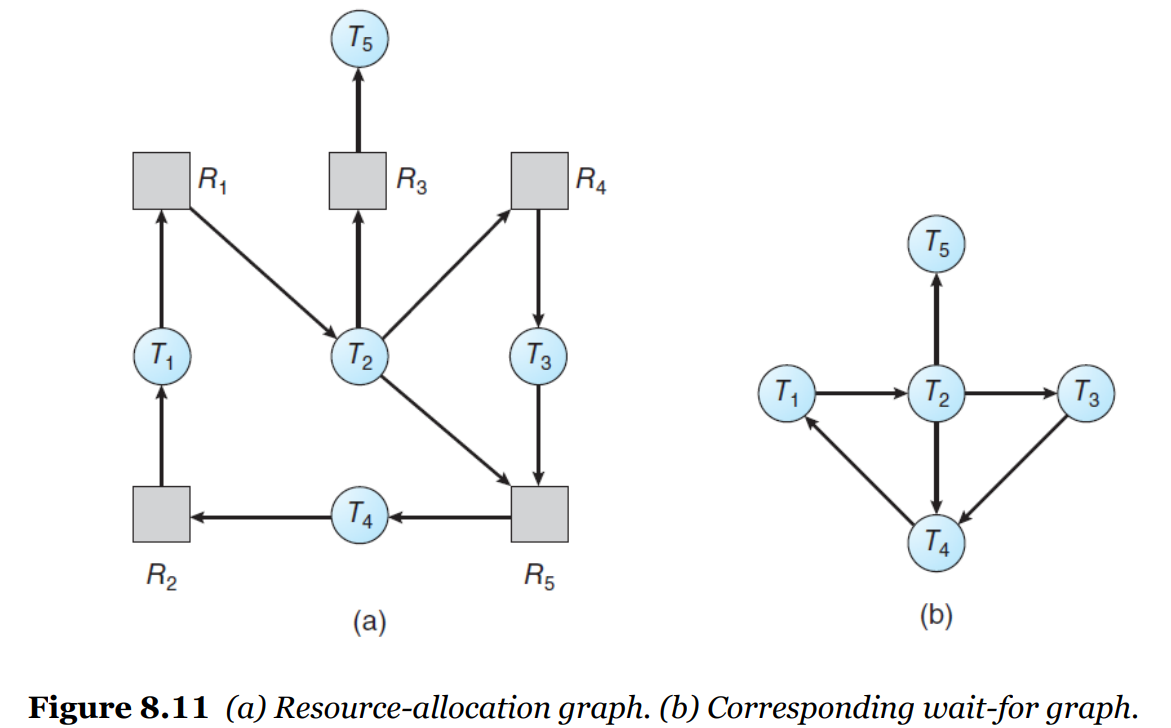
- 자원을 제외한 스레드간의 관계만 확인(dependency graph)
→ cycle detection
✅ multiple instances
- wait-for graph로 해결 x
- bankers-algorithm과 흡사한 알고리즘 적용
📝 자료 구조
- 𝑨𝒗𝒂𝒊𝒍𝒂𝒃𝒍𝒆[𝒎]
- 𝑨𝒍𝒍𝒐𝒄𝒂𝒕𝒊𝒐𝒏[𝒏 × 𝒎]
- 𝑹𝒆𝒒𝒖𝒆𝒔𝒕[𝒏 × 𝒎]
- Bankers-algorithm에서는 데드락 발생 여부와 safety 판별 고민
- 현재는 내버려두자고 한 상태 → 각 스레드의 현재 요청
𝑅𝑒𝑞𝑢𝑒𝑠𝑡[𝑖][𝑗] == 𝑘 → 𝑇𝑖가 𝑅𝑗의 인스턴스를 𝑘개 더 요청
📝 Detection Algorithm
- 몇 가지 부분을 제외하고는 Bankers-algorithm과 똑같이 구현

📖 참고
- [Wikipedia] 교착 상태
- https://www.inflearn.com/course/운영체제-공룡책-전공강의/
- Siberschatz et. al. 「Operating System Concepts」
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=and_lamyland&logNo=221197205167
- Banker's Algorithm
