이전에 배웠던 ResNet, DensNet, GoogleNet 등 이러한 네트워크가 이미지 분류만에만 사용되지 않고, Semantic Segmentation 과 Object Detection 에도 사용되었다.
Semantic Segmentation
-
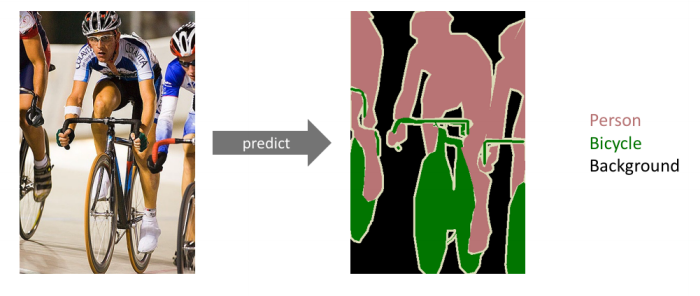
이미지 안의 모든 객체를 탐지해 분류하는 것으로, 이미지의 모든 픽셀이 어떤 label에 들어가는지 보고 싶을 때 사용한다.
-
ex) 자율 주행 자동차에 비유하면 차선을 따라서 가야하고 차 혹은 사람이 앞에 있으면 멈춰야 하는 경우에 사용
-
지금까지의 CNN은 Convolution, pooling 등을 하고 flatten으로 펼쳐서 fc layer를 통해 output을 추출하는 구조였다
-
앞으로 배우는 Fully Convolution Network는 Dense 층을 제거하고, convolution layer로 대체한다.
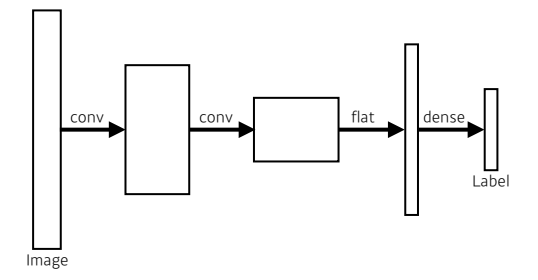
기본적인 CNN 구조
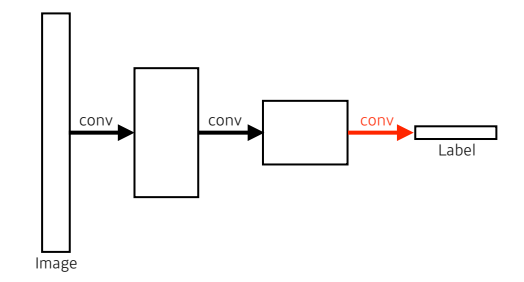
Fully Convolutional Network

-
위의 사진과 같이 Dense layer를 convolution layer로 대체하여도 사용되는 파라미터의 수는 같으며 이러한 구조를 convolutionalization이라 한다.
-
Fully Convolutional Network
- convolution이 가지는 shared parameter성질에 따라 input 이미지에 상관없이 network가 동작하고, output이 커지게 되면 비례해서 뒷단의 network가 커지게 된다.
- 이러한 동작이 마치 heatmap과 같은 효과를 가지며, 해당 이미지에 있는 객체의 추출이 가능해진다.
- 이를 통해 이미지가 커지면 단순히 분류만 했던 네트워크가 Semantic Segmentation 혹은 히트맵을 나타낼 수 있는 가능성을 나타낸다는 것을 알 수 있다.
-
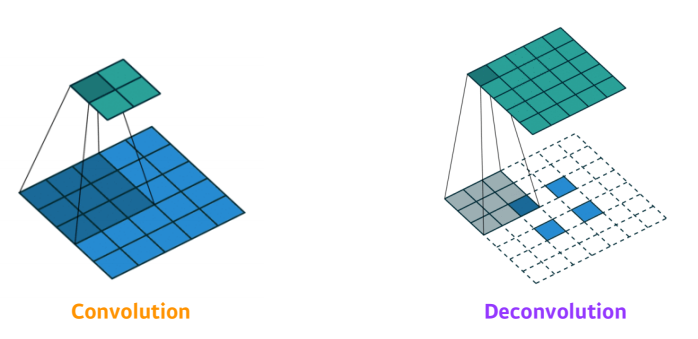
이렇게 10x10 special dimension을 100x100 이미지로 늘리는 방법이 필요해 졌고, Deconvolution 이라는 방법이 나타났다.
Deconvolution
- 직관적으로 Convolution의 역 연산이다
- 우리가 convolution을 stride 2로 하면 special dimension이 반정도 줄게 된다
- 반대로 deconvolution을 stride 2로 하면 2배만큼 늘어난다.
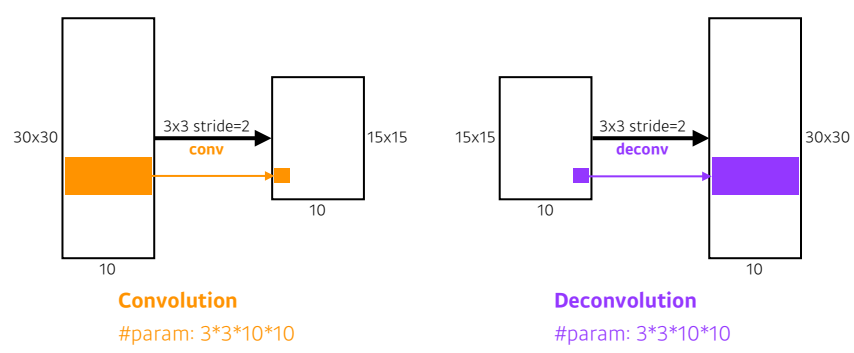
- 하지만, 2 + 8 = 10 이 있을 때 10을 보고 2와 8을 복원할 수 없는 것처럼 엄밀히 말하면 deconvolution은 convolution의 완전한 역은 아니다.
- decomvolution은 convolution의 엄밀한 역은 아니지만 parameter의 숫자와 네트워크의 입력과 출력의 느낌으로 보았을 때는 똑같다고 이해하면 된다.
- input이미지가 들어가고 이 이미지에서 fully covolutional Network를 만들고, per-pixel classification을 만드는 것이 fcn구조이다.
Detection
-
이미지 안에서 어느 물체가 어디에 있는지 bounding box를 찾는 것
-
R-CNN 계열
- R-CNN : https://velog.io/@ysw2946/R-CNN
- Fast R-CNN : https://velog.io/@ysw2946/Fast-R-CNN
- Faster R-CNN : https://velog.io/@ysw2946/Faster-R-CNN
-
YOLO
- 기존의 R-CNN 계열의 모델처럼 region proposal과 detection 부분을 따로 두지 않고 한번에 진행하는 1 stage detector로 faster R-CNN보다 빠르다
- 이미지가 들어오면 SxS grid로 나뉘며, 이 이미지 안에 찾고 싶은 물체의 중앙이 해당 grid안에 들어가면 grid cell이 해당 물체에 대한 bounding box와 해당 물체가 무엇인지 같이 예측해주는 방식
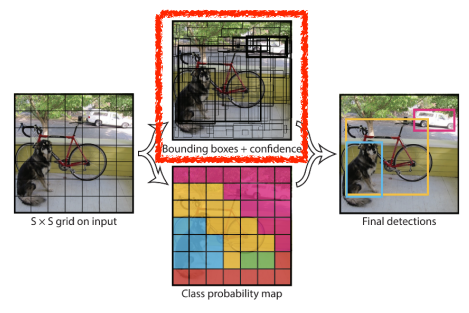
- 따라서, B개의 bounding box를 예측하여, 각 bounding box의 좌표들을 통해 이 box가 쓸모 있는지 없는지 예측한다.
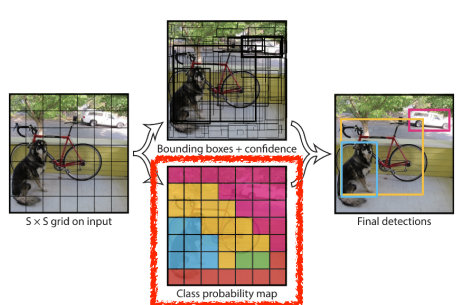
- 동시에, 각각의 S x S grid가 이 bounding box에 속하는 object가 어떤 class 인지 예측한다.
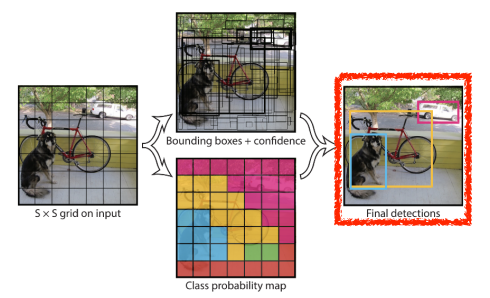
- 최종적으로, 이미지안에서 object에 대한 bounding box와 class가 나타난다.
- tensor로 표현하면 S x S x (B*n +C) size가 나타난다.
