공부 내용
- Latent Variable Models
- Generative Adversarial Network(GAN)
Latent Variable Models
autoencoder == generative model?
- Variational Auto-encoder는 generative model
-> 하지만 autoencoder는 generative model이 아님 - autoencoder는 input이 단순히 latent space를 거쳐서 output으로 나옴
Variational Auto-encoder
Variational Inference(VI)
-
Variational Inference의 목적은 posterior distribution을 찾는 것
-> 이를 통해 variational distribution을 최적화(근사)하는 과정 -
distribution description
- Posterior distribution :
- observation이 주어졌을 때 내가 관심있는 random variable의 확률분포
- z는 latent vector
- Variational distribution :
- Posterior distribution을 계산하는 게 불가능할 때가 많음
-> 학습할 수 있는 분포로 근사시킴
- Posterior distribution을 계산하는 게 불가능할 때가 많음
- Posterior distribution :
-
variational distribution을 최적화하기 위한 loss로는 KL divergence 활용
Variational Auto-Encoder Goal
Encoder를 활용해서 variational distribution 학습
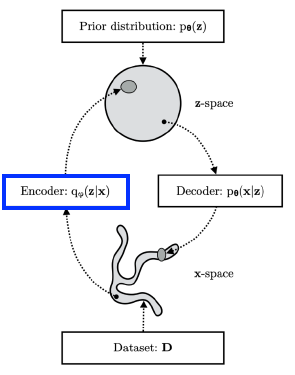
How to optimize
- Posterior를 모르는 상태에서 Posterior를 근사할 수 있는 latent vector를 찾는다?
-> target을 모르면서 target에 근사하기 위한 loss값을 줄이는 꼴 - Variational Inference에 있는 ELBO(Evidence Lower BOund)을 활용하면 가능
-> ELBO를 최대화해서 반대급부로 objective를 최소화
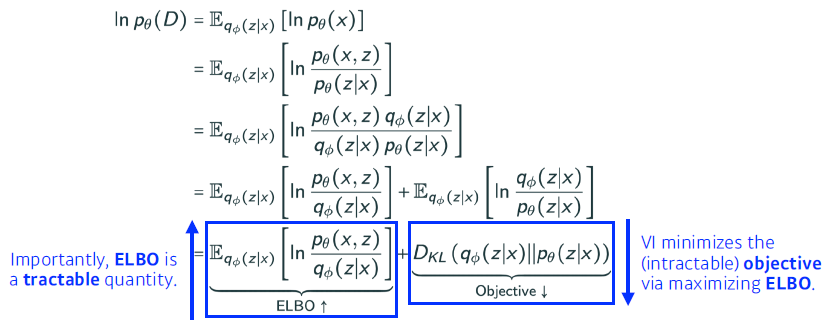
ELBO 구성 요소
- Reconstruction Term : Autoencoder reconstruction loss term
- 입력값 x를 encoder 활용 latent space로 보내고 decoder로 돌아오는 reconstruction loss를 감소시킴
- Prior Fitting Term : Latent Prior term
- x를 latent space로 올려 놨을 때 점들이 이루는 분포가 prior distribution과 비슷하게 만들어 줌
Objective
- x라는 입력에 대해 잘 표현할 수 있는 z라는 latent space를 찾는 것
-> 하지만 z에 대한 posterior distribution을 모르는 상태 - variational distribution이나 encoder로 근사
- ELBO를 최대화하는 것이 Posterior distribution과 variational distribution 사이의 거리를 줄여주는 효과
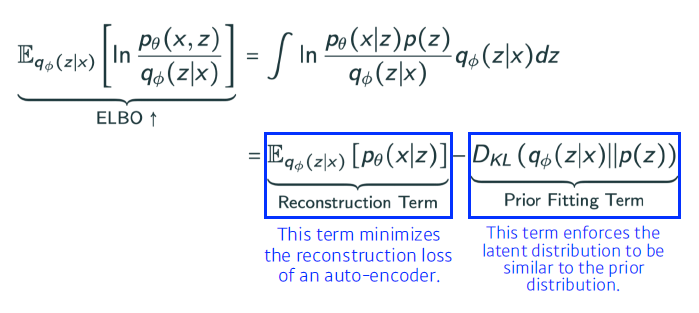
VAE가 Generative Model인 이유
- VAE(Variational Auto-Encoder)는 Reconstruction Term과 Prior Fitting Term을 잘 설명해서 구현까지 진행
-> VAE가 Generative Model이 될 수 있는 이유 - VAE는 Implicit Model
-> 단순히 생성만 할 수 있는 모델 - latent space의 prior distribution으로 z를 sampling 후 decoder를 통해 나오는 이미지가 generation result
VAE의 limitation
- VAE는 explicit model이 아님(interactive model)
-> 입력이 주어졌을 때 likelihood를 평가하기 힘듦 - prior fitting term의 최적화를 위한 미분 계산이 힘들다
-> KL divergence 자체에 적분이 들어가 있음
-> 그래서 VAE는 Gaussian Prior 활용(isotropic Gaussian)
isotropic Gaussian
모든 output dimension이 independent한 Gaussian Distribution
Adversarial Auto-encoder
- prior distribution으로 Gaussian을 활용하고 싶지 않을 때 사용
-> GAN을 사용해서 latent distribution 사이의 분포를 맞춰 줌 - VAE의 Prior Fitting Term의 KL divergence를 GAN objective로 바꿔 버림
-> 다양한 분포를 latent distribution으로 활용 가능 - 성능도 VAE보다 좋을 때가 많음
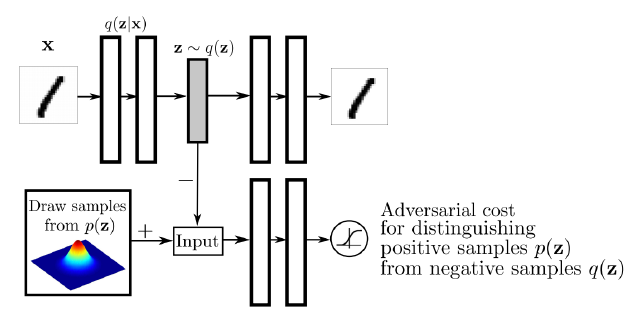
Wasserstein Auto-Encoder
Paper
Adversarial Auto-encoder가 latent distribution 사이의 wasserstein distance를 줄여주는 것과 동일한 효과가 있다고 주장
-> Adversarial Auto-encoder가 Wasserstein Auto-Encoder의 한 종류
Generative Adversarial Network
GAN
- Discriminator(경찰)이 진짜 지폐와 위조지폐 비교해서 분별
- Generator(도둑)은 위조지폐를 만들어 경찰 속임
-> Discriminator의 구별 능력과 Generator의 생성 능력을 극대화하여 궁극적으로 Generator 성능 높임 - Implicit Model

GAN의 장점
- 결과로 나오는 Generator를 학습하는 Discriminator가 점점 좋아짐
-> Generator도 성능이 올라가는 효과(좋은 이미지 생성)
GAN vs VAE
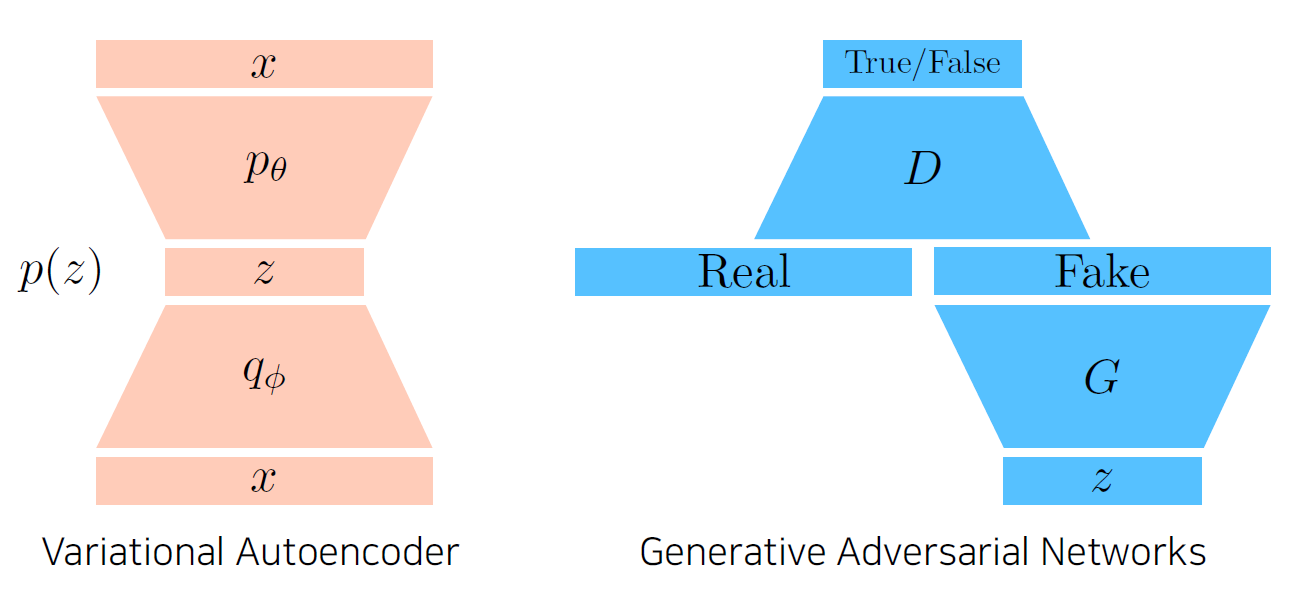
- VAE
- 학습
- x를 이미지를 Encoder를 활용해서 z latent vector로 만듦
- z를 Decoder를 활용해서 x 이미지로 다시 변환
- Generation
- latent distribution에서 z를 sampling(p(z))
- Decoder를 통해 나온 x가 generation 결과
- 학습
- GAN
- Generator
- z라는 latent distribution에서 출발
- G(generator)를 통해서 Fake 이미지 생성
- Discriminator
- Fake 이미지와 Real 이미지를 구분하는 분류기 학습
- Generator, Discriminator Update
- Discriminator의 입장에서 True가 나오도록 Generator 업데이트
- Generator가 생성한 이미지와 실제 이미지가 구별되도록 discriminator 재학습
- Generator, Discriminator 번갈아 가며 학습
- Generator
GAN Objective
generator와 discriminator의 minimax game
-
Discriminator Objective formula
-
discriminator를 최적화시키는 식
-> generator가 fix가 되어있을 때의 optimal discriminator
-
-
Generator Objective formula
-
optimal discriminator 대입하면 다음과 같은 식이 나옴

-
2개의 Jenson-Shannon Divergence(JSD)가 나옴
-> Generator와 Discriminator 사이의 JSD -
True Generative distribution과 학습하고자 하는 Generator 사이의 JSD를 최소화하는 것이 목적
-
이론적으로는 성립하는 식이지만 현실적으로는 어려운 식
DCGAN
- Dense layer로 만든 GAN -> Image 도메인
- 논문 성능 향상 방법 제시
- leaky-relu
- deconvolution layer 활용
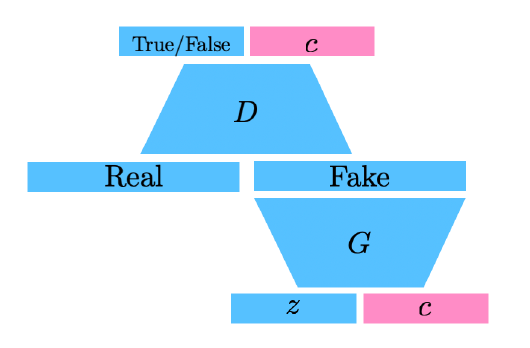
Info-GAN
- 단순히 z를 통해 이미지를 생성하는 것 뿐만 아니라 class c도 활용
-> random한 one-hot vector 대입 - c로 나오는 conditional vector(one-hot vector)에 집중할 수 있게 만듦
-> multi-modal distribution 학습 집중에 c를 이용
Text2Image
문장을 통해 이미지 생성

Puzzle-GAN
subpatch를 활용해 원래 이미지를 복원
CycleGAN
- 두 도메인 데이터를 활용하면 알아서 도메인 변화
-> 두개의 GAN 구조가 들어 있음

- Cycle-consistency loss 활용
- 이미지 사이의 도메인 변화 가능
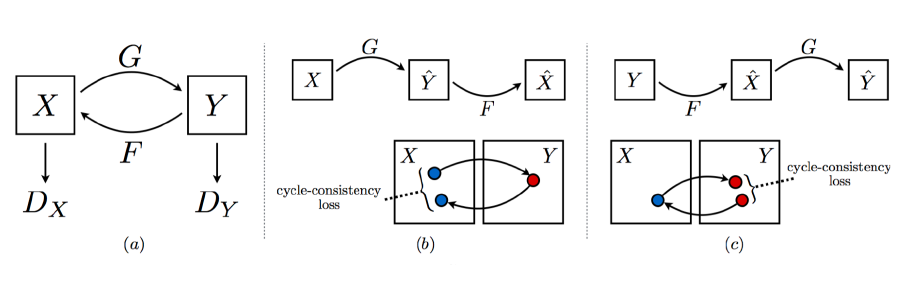
- 이미지 사이의 도메인 변화 가능
Star-GAN
Style transfer 모드를 정해줄 수 있음 -> control 가능

Progressive-GAN
- 고차원의 이미지 생성
-> 이미지를 까지 키움 - 저해상도에서 고해상도로 순차적으로 늘려가며 학습
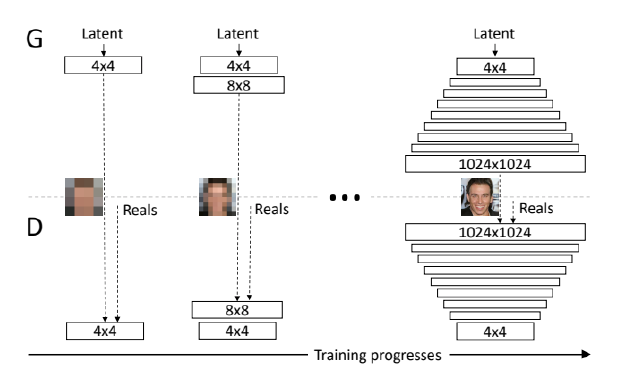
Conclusion
- GAN 논문은 현재 너무 많고 너무 빨리 발전 중이다.
-> 모든 논문을 다 이해하는 것은 불가능 - 공부해야 할 내용
- GAN에 대한 중요한 아이디어 파악
- GAN과 VAE의 차이점
- Implicit model(GAN과 VAE)중 어떤 것을 활용하는 것이 좋은가
